Что такое Business Intelligence
4 мин
Существует огромное количество терминов: аналитика, data mining, анализ данных, business intelligence и разница между ними не всегда столь очевидна даже для людей, которые с этим связаны. Сегодня мы расскажем о том, что же такое Business Intelligence (BI) доступным и понятным языком. Тема безусловна огромна и её не покрыть лишь одной короткой статьей, но наша задача — помочь сделать первый шаг и заинтересовать читателя темой. Заинтересованный же читатель также найдет исчерпывающий список для дальнейших шагов.
Структура статьи

Структура статьи
- Зачем всё это нужно: из жизни аналитика
- В чем задача: проблема на уровне компании
- Обобщаем задачу: всё это звенья одной цепи
- Большая инфографика
- С чем можно поэкспериментировать
- Что почитать? Must read по Business Intelligence
Зачем всё это нужно: из жизни аналитика
(кликабельно)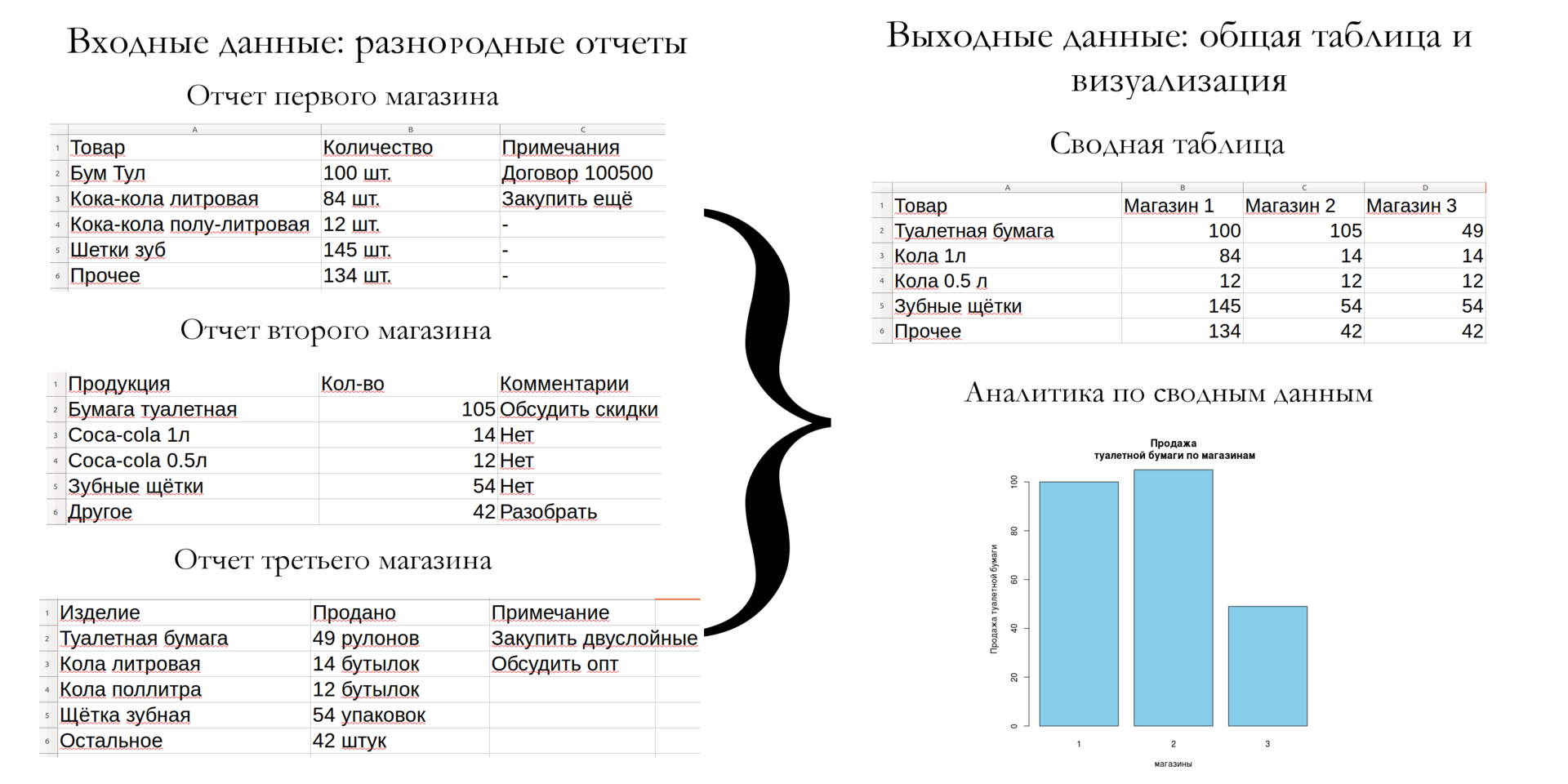



 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как