Начал писать комментарий к собственному
переводу статьи о приватности пользовательских данных и неожиданно понял, что он выливается в нечто большее.
Дело в том, что я занимаюсь технологиями data mining и text mining последние лет пятнадцать. И поэтому все недавние скандалы, связанные с делом Сноудена и PRISM, XKeyScore, Muscular, СОРМ, чтением почты Гуглом, передачей конфиденциальных и гео данных с мобильников, и множество прочих оставили меня абсолютно равнодушным.
По очень простой причине – я уже знаю, что Большой Брат давно существует.

Если точнее, я абсолютно в этом уверен – так же, как не могу знать, что Солнце завтра взойдет, но весьма и весьма в этом убежден. И все новые доказательства существования Большого Брата полезны, но уже не обязательны.
А объяснение уверенности очень простое: при наличии необходимых ресурсов я сам мог бы его построить.

 При решении такой задачи классифицируемые элементы (далее образцы) представляются в виде элементов векторного пространства размерности n. На практике в таких задачах n может быть чрезвычайно большим, например для задачи классификации генов оно может исчисляться десятками тысяч. Большая размерность влечёт, по-мимо высокого времени вычисления, потенциально высокую погрешность численных рассчётов. Кроме того использование большой размерности может требовать больших финансовых затрат (на проведение опытов). Постановка вопроса такова: можно ли и как уменьшить n отбрасыванием незначимых компонент образцов так, чтобы образцы разделялись «не хуже» в новом пространстве (оставались линейно разделимы) или «не сильно хуже».
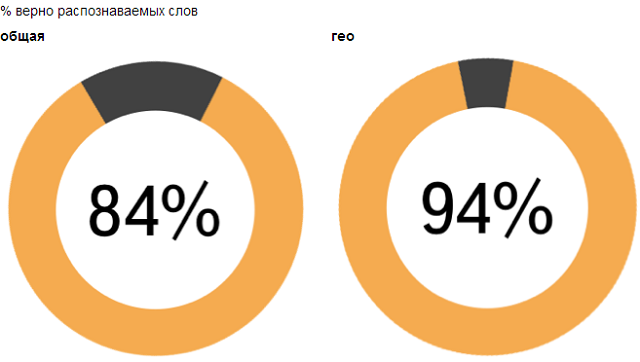
При решении такой задачи классифицируемые элементы (далее образцы) представляются в виде элементов векторного пространства размерности n. На практике в таких задачах n может быть чрезвычайно большим, например для задачи классификации генов оно может исчисляться десятками тысяч. Большая размерность влечёт, по-мимо высокого времени вычисления, потенциально высокую погрешность численных рассчётов. Кроме того использование большой размерности может требовать больших финансовых затрат (на проведение опытов). Постановка вопроса такова: можно ли и как уменьшить n отбрасыванием незначимых компонент образцов так, чтобы образцы разделялись «не хуже» в новом пространстве (оставались линейно разделимы) или «не сильно хуже». Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен 


 Доброго времени суток. В процессе разработки одного из методов кластеризации, возникла у меня потребность визуализировать
Доброго времени суток. В процессе разработки одного из методов кластеризации, возникла у меня потребность визуализировать