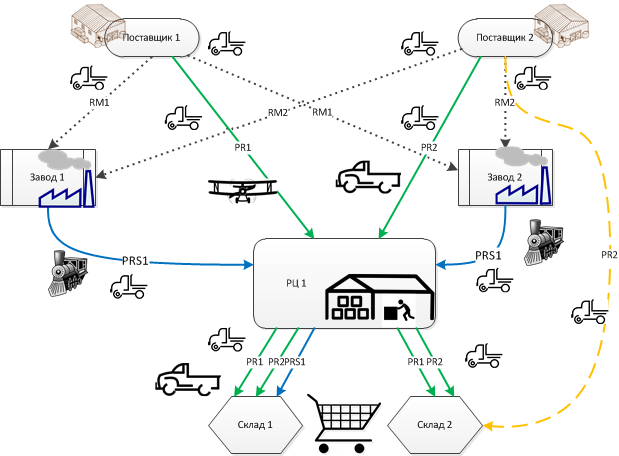
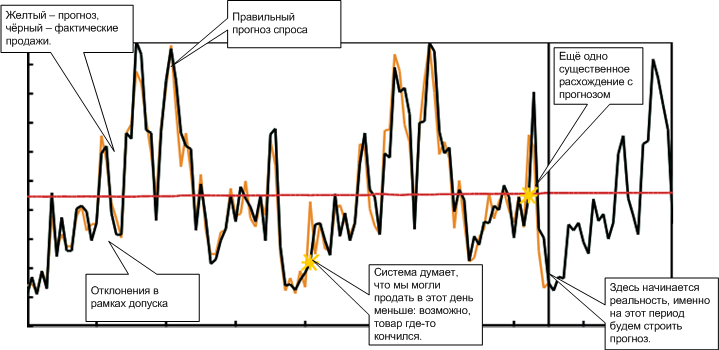
Программа Watson компании IBM пошла учиться в мед. институт
6 мин
Перевод
Эта ИИ программа уже освоила игру “Jeopardy!”. Теперь она приступит к изучению онкологических заболеваний.
 В финале телевикторины Jeopardy, где против ИИ программы Watson компании IBM сражались лучшие игроки, один из участников, признав свое поражение, рядом с ответом на вопрос приписал: «От всей души приветствую наших новых компьютерных правителей»
В финале телевикторины Jeopardy, где против ИИ программы Watson компании IBM сражались лучшие игроки, один из участников, признав свое поражение, рядом с ответом на вопрос приписал: «От всей души приветствую наших новых компьютерных правителей»
Сейчас даже доктора высказываются схожим образом. «Мне хотелось бы пожать Watson руку», говорит Марк Крис, врач-онколог из онкологического центра Слоан-Кеттеринг в Нью-Йорке. Он с воодушевлением говорит о том дне в конце 2013 года, когда Watson, которая сейчас является его студенткой, окончит полный курс обучения и будет готова помогать врачам в онкологическом центре с постановкой верных диагнозов и определением подходящих курсов лечения.
В финале телевикторины Jeopardy, где против ИИ программы Watson компании IBM сражались лучшие игроки, один из участников, признав свое поражение, рядом с ответом на вопрос приписал: «От всей души приветствую наших новых компьютерных правителей»Сейчас даже доктора высказываются схожим образом. «Мне хотелось бы пожать Watson руку», говорит Марк Крис, врач-онколог из онкологического центра Слоан-Кеттеринг в Нью-Йорке. Он с воодушевлением говорит о том дне в конце 2013 года, когда Watson, которая сейчас является его студенткой, окончит полный курс обучения и будет готова помогать врачам в онкологическом центре с постановкой верных диагнозов и определением подходящих курсов лечения.