Визуализация кибератак в реальном времени
1 мин
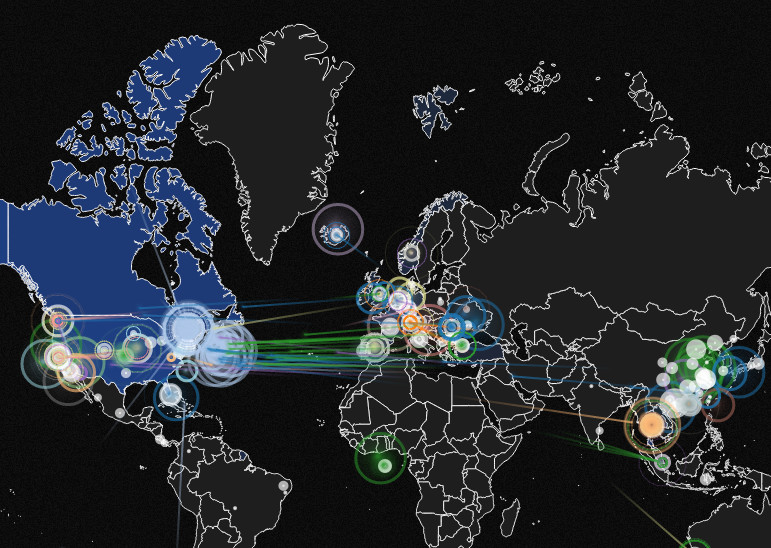
Понаблюдать своими глазами за кибервойной можно с помощью Norse Live Attack Map. На этой карте отображаются данные с оборудования компании Norse, расположенного более чем в 40 странах. Атаки ведутся на специально сформированные небольшие инфраструктуры-приманки с якобы ценными данными. Информация обновляется ежесекундно.
Реальные атаки на этой карте не видны, но с ее помощью можно наблюдать за самыми распространенными видами и источниками атак. В данный момент лидирует атака на 694 порт. Если смотреть некоторое время, то можно увидеть, что большинство угроз исходит из Китая и Канады, а основной целью являются США.
Интересным моментом также является то, что кроме распространенных портов ssh, telnet и т. д. выделяются два неизвестных: 53003 и 21320. Возможно, с помощью этого инструмента можно будет отслеживать использование новых эксплоитов.