
Данная статья может быть интересна тем, кто уже имеет поверхностное представление о видах и проблематике репликации внутри кластера PostgreSQL, а так же тем, кто решил использовать стриминговую СУБД PipelineDB в качестве реплики в подобном кластере.
PipelineDB — одна из реализаций ныне набирающих популярность стриминговых СУБД. О преимуществах стриминговых СУБД в различных кейсах Вы можете без труда прочитать сегодня на множестве ресурсов. Очень просто принцип их работы визуализирован на сайте www.pipelinedb.com в разделе “How It Works”.
Конкретно PipelineDB это форк PostgreSQL с дополнительной функциональностью, позволяющей хранить только агрегированные данные, рассчитывая дельту из поступающего стрима (отсюда и название этого типа СУБД) на лету. Эти данные хранятся в специальных объектах PipelineDB, называемых continuous views. Сам же стрим в простейшем случае формируется из обычных таблиц, хранимых в этой же БД. Использование данного инструмента позволяет нам избавиться от необходимости создания и поддержки ETL-слоя при подготовке данных для систем отчетности, и может сэкономить Вам кучу времени и нервов. Но я полагаю, что раз Вы это читаете, то Вы уже что-то знаете об этом в объеме достаточном для появления интереса к описываемым здесь событиям.
Мы рассмотрим кейс, в котором на продуктовой среде у нас уже работает СУБД PostgreSQL версии 9.4+, а нам нужно получить ее риалтайм (ну или практически риалтайм) реплику для того, чтобы разгрузить основную базу от множественных и тяжелых SELECT-запросов, получаемых от, например, систем отчетности, DWH или наших витрин данных. И после изучения вопроса Вы можете решить, что именно стриминговая СУБД очень хорошо подходит для такой задачи.
PipelineDB — одна из реализаций ныне набирающих популярность стриминговых СУБД. О преимуществах стриминговых СУБД в различных кейсах Вы можете без труда прочитать сегодня на множестве ресурсов. Очень просто принцип их работы визуализирован на сайте www.pipelinedb.com в разделе “How It Works”.
Конкретно PipelineDB это форк PostgreSQL с дополнительной функциональностью, позволяющей хранить только агрегированные данные, рассчитывая дельту из поступающего стрима (отсюда и название этого типа СУБД) на лету. Эти данные хранятся в специальных объектах PipelineDB, называемых continuous views. Сам же стрим в простейшем случае формируется из обычных таблиц, хранимых в этой же БД. Использование данного инструмента позволяет нам избавиться от необходимости создания и поддержки ETL-слоя при подготовке данных для систем отчетности, и может сэкономить Вам кучу времени и нервов. Но я полагаю, что раз Вы это читаете, то Вы уже что-то знаете об этом в объеме достаточном для появления интереса к описываемым здесь событиям.
Мы рассмотрим кейс, в котором на продуктовой среде у нас уже работает СУБД PostgreSQL версии 9.4+, а нам нужно получить ее риалтайм (ну или практически риалтайм) реплику для того, чтобы разгрузить основную базу от множественных и тяжелых SELECT-запросов, получаемых от, например, систем отчетности, DWH или наших витрин данных. И после изучения вопроса Вы можете решить, что именно стриминговая СУБД очень хорошо подходит для такой задачи.
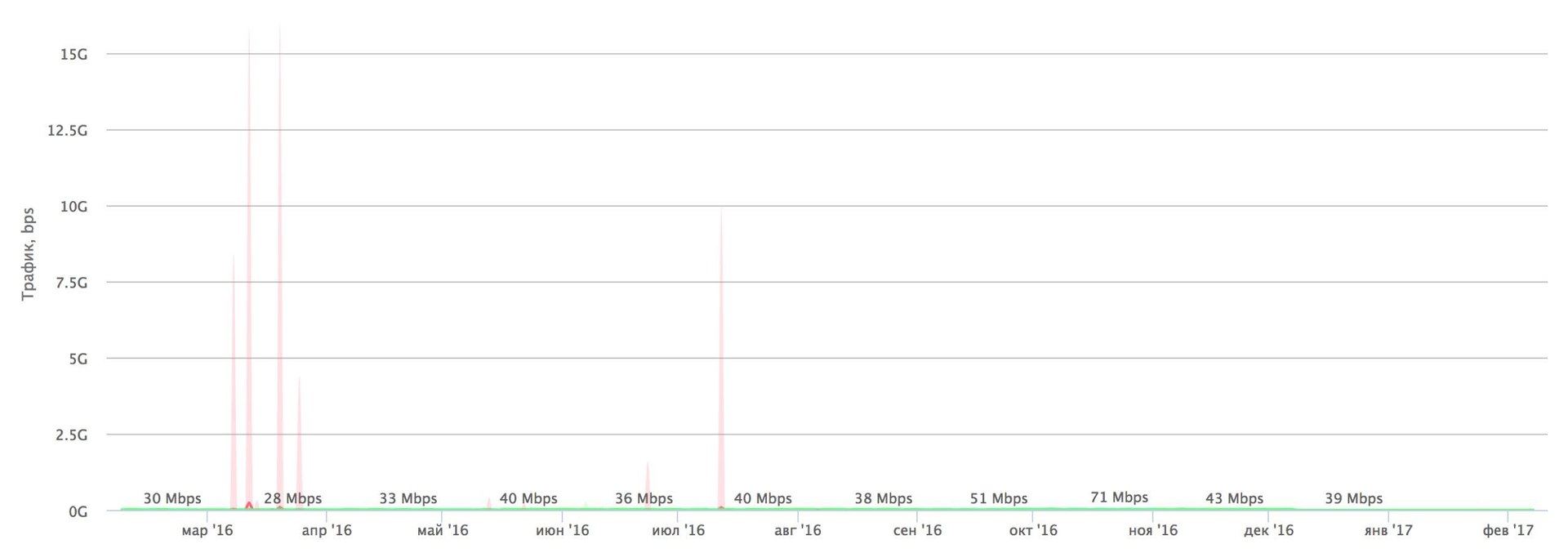
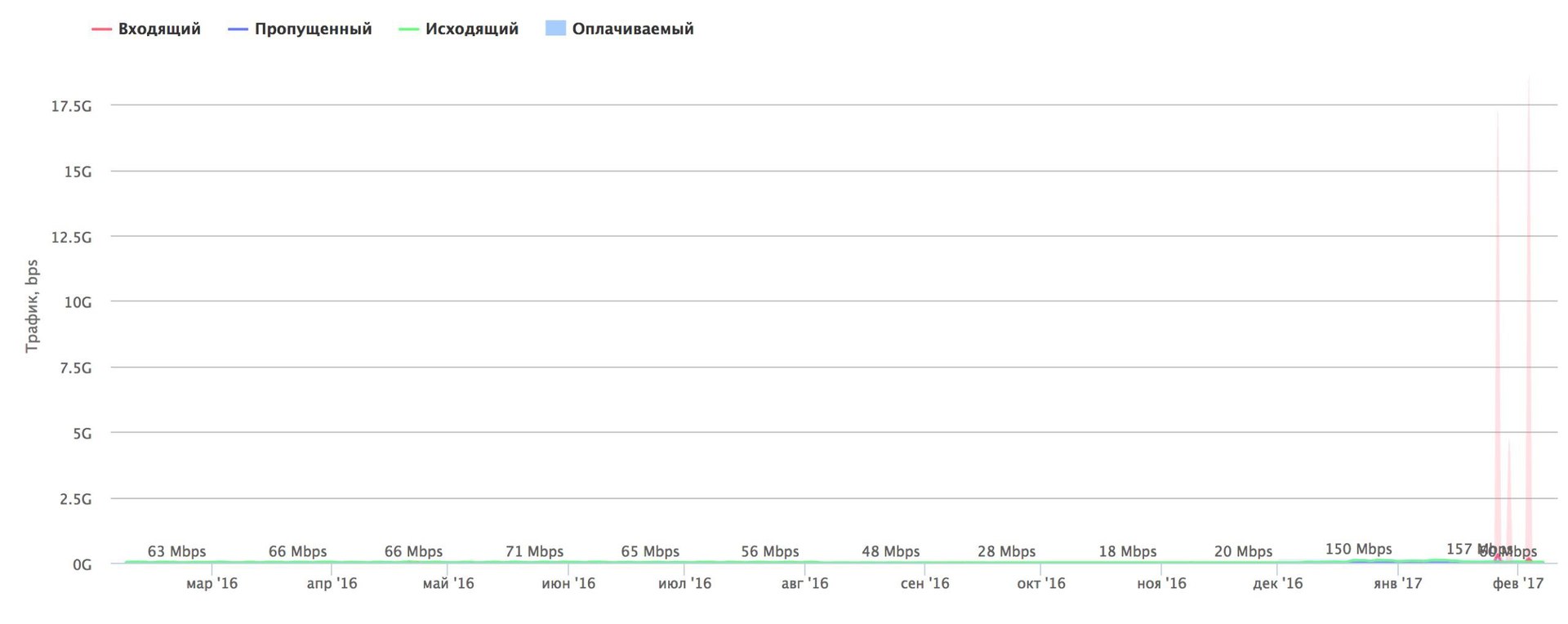


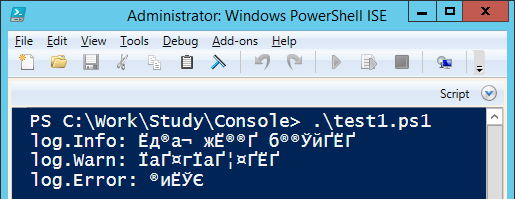
 Вчера, 31 января, сервис Gitlab случайно уничтожил свою продакшн базу данных (сами гит-репозитории не пострадали).
Вчера, 31 января, сервис Gitlab случайно уничтожил свою продакшн базу данных (сами гит-репозитории не пострадали).
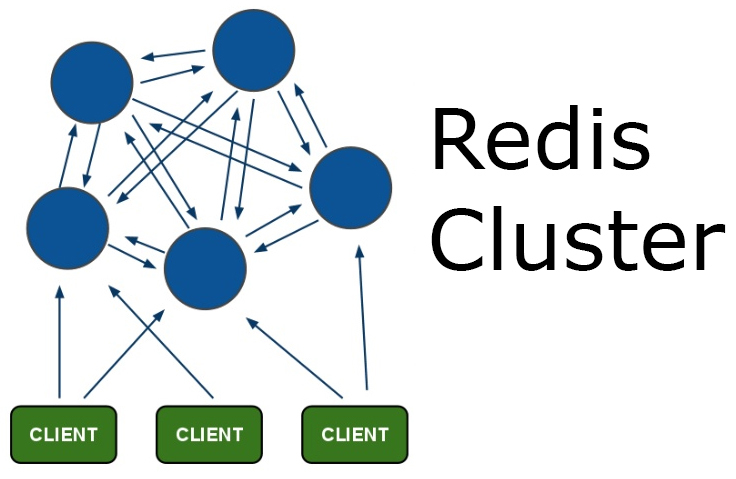
 Docker одна из горячих тем в разработке. Большинство новых проектов строится именно на Docker. Как минимум, он отлично зарекомендовал себя для распространения ПО, например, наша система поиска по документам
Docker одна из горячих тем в разработке. Большинство новых проектов строится именно на Docker. Как минимум, он отлично зарекомендовал себя для распространения ПО, например, наша система поиска по документам 

 Новогодние праздники закончились, на CES анонсировали все что можно и нельзя, Atlassian купила Trello, а все крупные производители смартфонов запатентовали раскладушку из WestWorld. И даже Шерлока слили, посмотрели и обсудили. Все проснулись, приступили к работе, а некоторые даже нашли в себе силы организовать весенние конференции. Под катом я хочу немного рассказать вам про
Новогодние праздники закончились, на CES анонсировали все что можно и нельзя, Atlassian купила Trello, а все крупные производители смартфонов запатентовали раскладушку из WestWorld. И даже Шерлока слили, посмотрели и обсудили. Все проснулись, приступили к работе, а некоторые даже нашли в себе силы организовать весенние конференции. Под катом я хочу немного рассказать вам про 
