 Apache Mesos
Apache Mesos — это централизованная отказоустойчивая система управления кластером. Она разработана для распределенных компьютерных сред c целью обеспечения изоляции ресурсов и удобного управления кластерами подчиненных узлов (mesos slaves). Это новый эффективный способ управления серверной инфраструктурой, но и, как любое техническое решение, не "серебряная пуля".
В некотором смысле суть его работы противоположная уже традиционной виртуализации — вместо деления физической машины на кучу виртуальных, Mesos предлагает их объединять в одно целое, в единый виртуальный ресурс.
Mesos распределяет ресурсы CPU и памяти в кластере для задач в похожей манере, как ядро Linux выделяет ресурсы железа между локальными процессами.
Представим себе, что есть необходимость выполнить различные типы задач. Для этого можно выделить отдельные виртуальные машины (отдельный кластер) для каждого типа. Эти виртуальные машины, вероятно, не будут полностью загруженными и некоторое время будут простаивать, то есть не будут работать с максимальной эффективностью. Если же все виртуальные машины для всех задач объединить в единый кластер, мы можем повысить эффективность использования ресурсов и параллельно с тем повысить скорость их выполнения (в случае если задачи краткосрочные или виртуальные машины не загружены полностью все время). Следующий рисунок, надеюсь, прояснит сказанное:
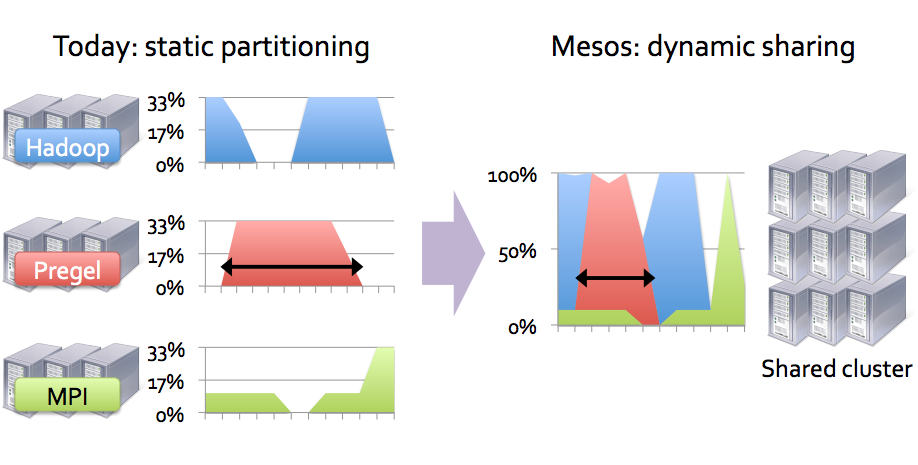
Но это далеко не все. Кластер Mesos (с фреймворком к нему) способен пересоздавать отдельные ресурсы, в случае их падения, масштабировать ресурсы вручную или автоматически при определенных условиях и т.п.
Пройдемся по компонентам Mesos-кластера.










 Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры.
Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры. 
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели 