
Старт в Vivado 2022 c FPGA-тян
Простой
4 мин
Туториал

Всем снова здравствуйте, с вами Александр и та, кто, наверное, уже не нуждается в представлении.
Сегодня разберём, как создать свой первый проект в САПР Vivado 2022.
Всем снова здравствуйте, с вами Александр и та, кто, наверное, уже не нуждается в представлении.
Сегодня разберём, как создать свой первый проект в САПР Vivado 2022.
В этой статье мы подошли к самому "свежему" поколению ПЛИС фирмы Intel, а именно 10 поколение. И теперь мы будем создавать проект в среде симуляции для Arria 10.
Напомню, что высокоскоростные приёмопередатчики - это пара RX и TX, встроенные в ПЛИС, которые позволяют преобразовать параллельную шину данных на низкой частоте в последовательную на высокой при передаче данных и из последовательной в параллельную при получении данных. Они необходимы для реализации различных протоколов передачи данных. А динамическая реконфигурация в данном случае необходима для "автосогласования" скорости работы интерфейсов, например 1 / 2,5 /10 Gb Ethernet.

Однажды мне прилетела задача реализовать DMR на ПЛИС. Опустившись на дно интернета, я нашел лишь мануал ETSI и пару примеров по генерации кода – с этого начался мой тернистый путь изучения данной тематики. Недавно наткнулся на мем, и тут нахлынули воспоминания...

Давно я ничего не писал про LiteX. Во-первых, очень много работы. Во-вторых, пришлось почитать курс студентам, подготовка тоже дико отвлекала, но наконец семестр подходит к концу. Ну, и в-третьих, в своих опытах я на пару шагов дальше того, что описываю, и вот эти опыты меня затянули. Пока что там всё выглядит достаточно мрачно. Производительность там такая, что плакать хочется. В общем, было трудно прерваться, чтобы описать то, что находится ещё на гарантированно светлой стороне. Но если вы читаете эти строки, то я себя пересилил.
Я уже многократно писал, что рассматриваю LiteX как некий аналог подсистемы Qsys из среды разработки Quartus. То есть, как удобное средство составить шинно-ориентированную систему из множества готовых ядер. Но если Qsys – он только для Альтер, то LiteX – он подходит и для Altera (Intel), и для Xilinx, и для Lattice. А сейчас я по работе плотно вожусь именно с Латтисами. У Латтисов самое узкое место – это параметр FMax. И вот построение базовых систем на базе шины Wishbone у Litex получается очень красиво. Там FMax выходит достаточно высоким. Даже у Латтисов он превышает 100 МГц.
В предыдущих статьях мы уже научились добавлять в систему устройства, доступные по шине через регистры команд-состояний (CSR), а также пассивные (Slave) устройства с шиной Wishbone. Сегодня мы добавим на шину активное (Master) устройство. Поехали!

Ребята из FPGA комунити каждый день делают небольшую подборку новостей из мира FPGA и решили поделиться ею с читателями хаба FPGA. Внимание: возможны повторы!

Знаешь что такое цифровой автомат(FSM)!? Интересуешься цифровой схемотехникой? Если да, то вам будет интересно посмотреть решение одной проблем, которую часто игнорируют. Если нет, то вам придётся потратить дополнительно 5 минут на введение)
Для тех кто хочет загрузить свой мозг новой интересной задачей. Результаты вас удивят.
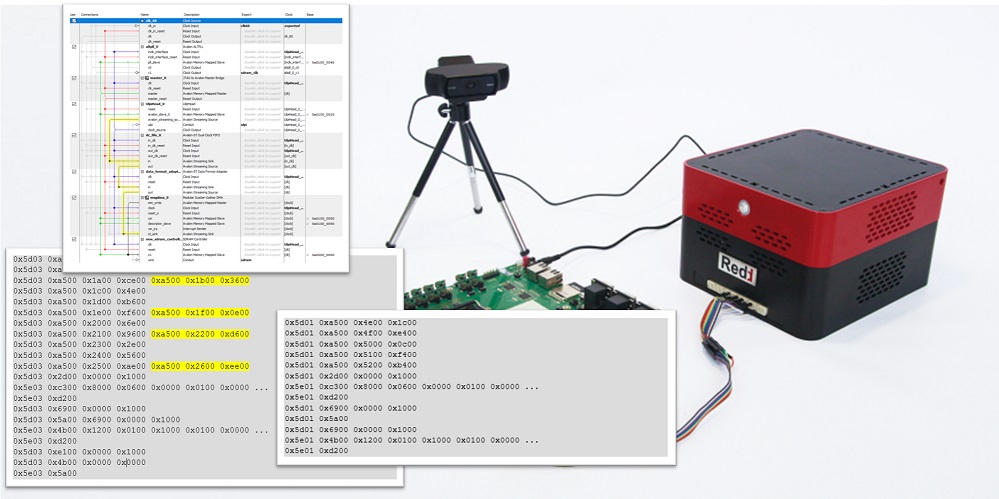




Иногда лучший способ чему-то научиться, будь то ПЛИС, модель ИИ или простейшая логическая задача — это позволить технологии научить саму себя.

При разработке сложно-функциональных блоков (СФБ) цифровой обработки сигналов важным этапом является моделирование алгоритма работы. Этот этап может занимать существенное время, откладывать запуск написания RTL и, как результат, увеличивать общее время разработки. Поэтому в условиях ограниченного времени на разработку многие предпочитают этот этап пропускать. А зря.

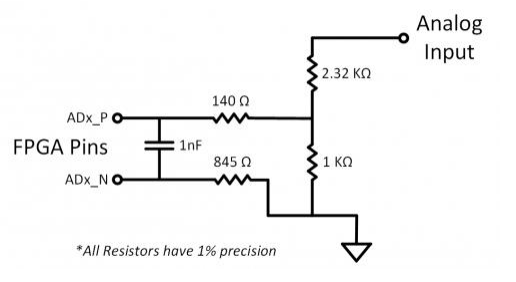
Нет согласующих резисторов в FPGA - что мешает реализовать целый ряд схем, но зато есть чем заменить их для цифрового сигнала внутри таких схем. Пытался найти в сети альтернативу согласующему резистору для применения внутри синтезируемой схемы, поисковик выдал скромный результат поиска, содержанием которого оказалось ничего по существу - категоричное нет на всех форумах, и иногда что-то близкое, но моей задачи не решающее. Да и собственно в схеме развёрнуты две задачи - некоторый кэш нового типа и механизм управления таким кэшем, по сути - часть процессора нового типа.
Тут нужно много вникать. И если Вы не верите IDE Logisim Evolution - можете просто пройти мимо и не принимать тут изложенный материал во что-то нужное и полезное. Тем более что это в общем-то работа новичка, который просто развивает свой проект и взгляды в новых областях, сталкивается с новыми задачами и решает их новыми способами.


