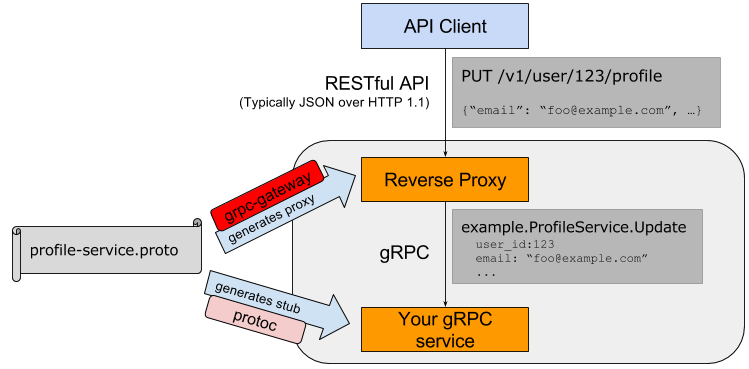
Алгоритм: Как найти следующую лексикографическую перестановку
3 мин

Если кратко описать, что такое лексикографический порядок — это сортировка в алфавитном порядке. Т.е. последовательность символов — AAA → AAB → AAC → AAD → ……… → WWW — является отсортированной в алфавитном (или в нашем случае лексикографическом) порядке.
Представьте, что у Вас есть конечная последовательность символов, например 0, 1, 2, 5, 3, 3, 0 и Вам необходимо найти все возможные перестановки этих символов. Наиболее интуитивным, но и наибольшим по сложности, является рекурсивный алгоритм, когда мы выбираем первый символ из последовательности, далее рекурсивно выбираем второй, третий итд, до тех пор, пока все символы из последовательности не будет выбраны. Понятно, что сложность такого алгоритма — O(n!).
Но оказывается, что наиболее простой алгоритм генерации всех перестановок в лексикографическом порядке — это начать с наименьшей и многократно вычислять следующую перестановку на месте. Давайте посмотрим как это сделать.