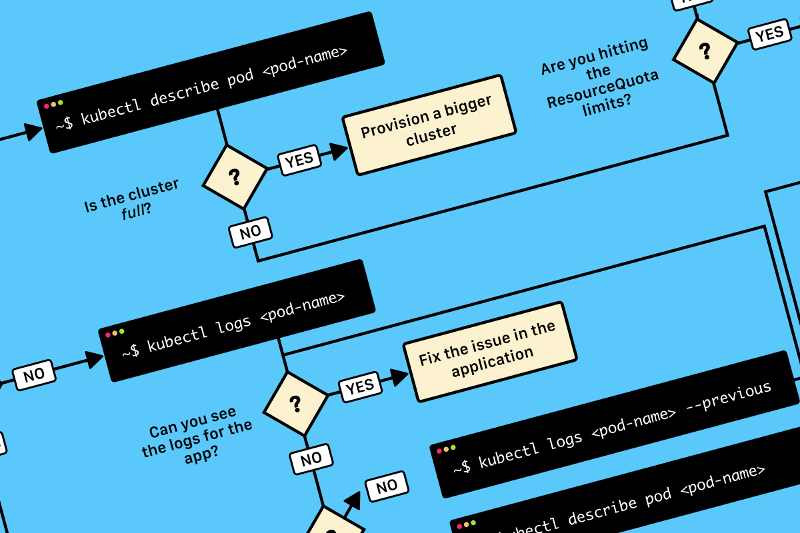
Устройство Helm и его подводные камни
8 мин

Typhon freight hauler concept, Anton Swanepoel
Меня зовут Дмитрий Сугробов, я разработчик в «Леруа Мерлен». В статье расскажу, зачем нужен Helm, как он упрощает работу с Kubernetes, что поменялось в третьей версии и как с его помощью обновлять приложения в продакшене без простоя.
Это конспект по мотивам выступления на конференции @Kubernetes Conference by Mail.ru Cloud Solutions — если не хотите читать, смотрите видео.