
Предсказание курса акций с использованием больших данных и машинного обучения
9 мин
Перевод
Примечание переводчика: В нашем блоге мы уже рассказывали об инструментах для создания торговых роботов и даже анализировали зависимости между названием биржевого тикера компании и успешностью ее акций. Сегодня мы представляем вашему вниманию перевод интересной статьи, авторой которой разрабатывал систему, которая анализирует изменения цен на акций в прошлом и с помощью машинного обучения пытается предсказать будущий курс акций.
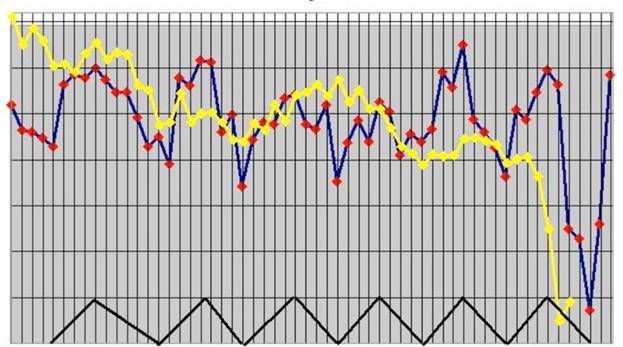
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.
Краткий обзор
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.





 С 27 по 30 мая в Российском государственном гуманитарном университете (РГГУ) пройдет международная научная конференция по компьютерной лингвистике
С 27 по 30 мая в Российском государственном гуманитарном университете (РГГУ) пройдет международная научная конференция по компьютерной лингвистике 



{kind=link}