Записки оптимизатора 1С (часть 1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
Этой статьей мы начинаем цикл разбора нетривиальных случаев в нашей практике оптимизации производительности ИТ‑систем. Возможно, кому‑то они пригодятся, так как решения будут нестандартные. Возможно, кто‑то узнает свою ситуацию и поделится своими решениями или наведет на интересную мысль. Ведь, коллективный разум — это сила!
Не секрет, что самой популярной и массовой платформой в России для создания ИТ‑систем для бизнеса является 1С:Предприятие 8.х. На ней разработано огромное количество отраслевых и самописных решений.
Хочу обратить внимание на одну особенность работы приложений 1С, а именно, очень интенсивную работу с временными таблицами СУБД. Подобной интенсивной работы с tempDB, наверное, нет ни в одном тиражном решении в мире.
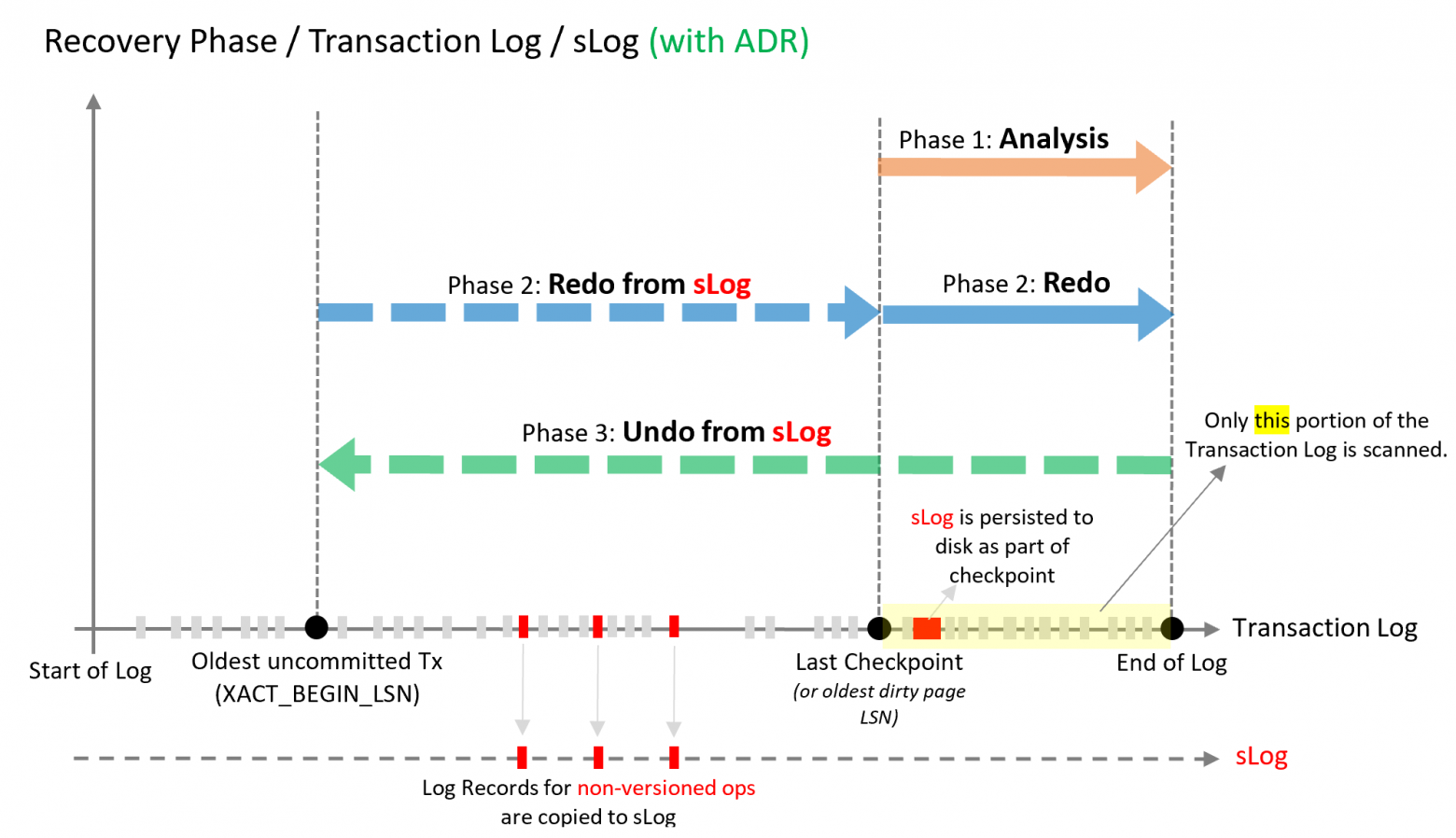
После завершения пакетного запроса платформа автоматически удаляет временную таблицу, отдавая серверу СУБД команду <truncate table>, чтобы освободить ресурсы под следующий запрос.
TRUNCATE — это очень простая и быстрая операция и выполняется мгновенно. Даже для таблиц с миллионами строк она длится миллисекунды. Тем не менее, у некоторых своих клиентов мы столкнулись с очень странной ситуацией, когда производительность системы проседает из‑за того, что запросы с очисткой временных таблиц могут длиться десятки секунд (не миллисекунд, а секунд!). А учитывая количество запросов с временными таблицами в ИТ‑системе на 1С:Предприятие, это время в совокупности становится просто огромным.