Девушка с татуировкой ANSI
2 мин
Специалисты по СУБД с сайта Oracle WTF заинтересовались, что же такое печатает в терминале юный хакер в фильме «Девушка с татуировкой дракона». По сюжету, это были запросы к базе данных полицейского отделения, с помощью которых она раскрыла убийства 40-летней давности.

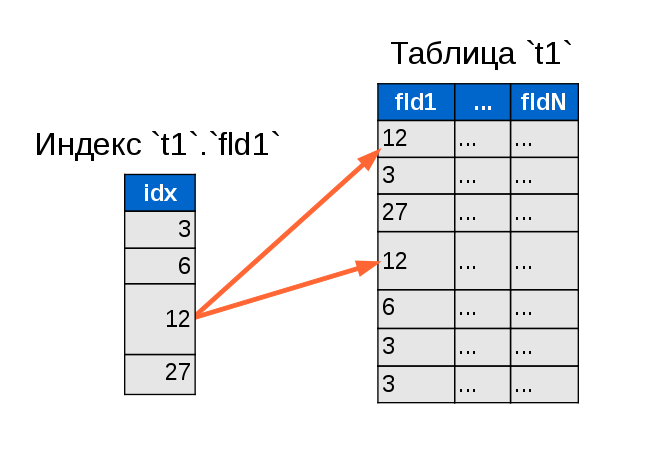
 Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.
Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.