Добрый день.
Некоторое время назад проект нашей компании по мониторингу серверов и сайтов перешел из категории «сделано для себя» в плоскость привлечения массовых пользователей. Этому частично способствовало получение проектом посевных инвестиций от ФРИИ и плюс, конечно же, наличие желания поделиться с миром нашей технологией, которую мы также используем для мониторинга своих серверов. Но, это не рекламный пост, а практический, поэтому о проекте потом.
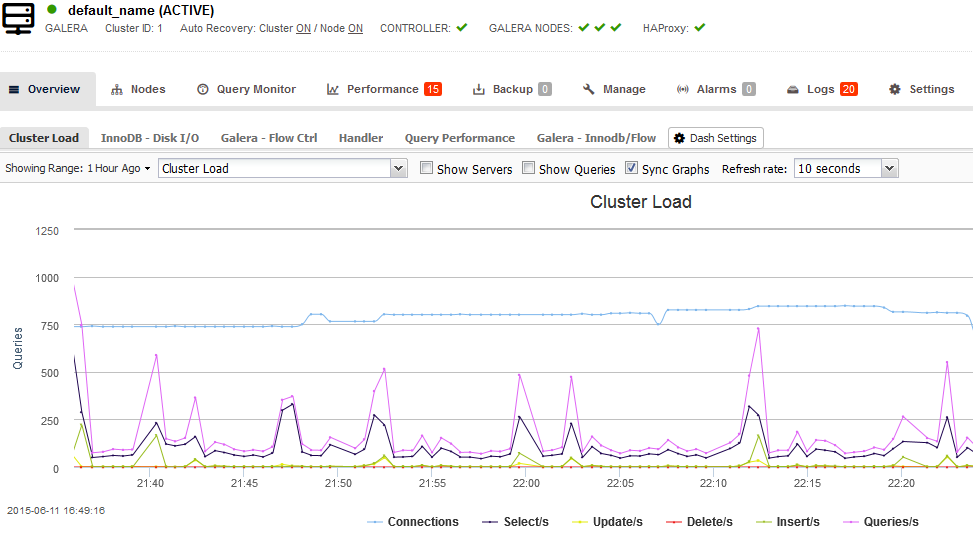
Итак, с ростом нагрузки на базу данных, а наш сервис — это SaaS платформа по сбору метрик с серверов, количество запросов на запись в нашу базу данных (сейчас более 1000 серверов посылают порядка 20 своих метрик в БД каждые 4 минуты) начало приводить к перегрузке БД и нестабильной работе сервиса. Это зачастую происходило из-за превышения установленного максимального количества соединений к MySQL и большой нагрузки на сервер. К сожалению, все попытки оптимизации MySQL, увеличения серверных ресурсов и настройки параметров max_connections, query cache и т.д. не приводили к успеху.
Т.к. у нас нет отдельного человека, отвечающего за базы данных, а программисты и системные администраторы не могут каждый день тратить кучу времени на поддержание стабильности MySQL и реагировать на каждое падение, мы решили перейти на MariaDB Galera кластер с master-master репликацией и балансировкой нагрузки с помощью HaProxy. У нас до этого не было опыта внедрения бд кластера в production environment и поэтому пришлось наступать на все грабли самостоятельно.
К счастью, на Хабре нашлось много полезных статей на тему настройки
Percona XtraDB,
HaProxy и Zabbix для Percona, а также серия статей
«Идеальный Кластер», которые нам очень помогли в начальной установке.






 Давным-давно (кажется, в прошлую среду) попался ко мне в руки дамп базы данных MySQL, который следовало немедленно развернуть на моей машине. Зачем это было нужно и откуда взялся дамп, рассказывать не буду, вряд ли это кому-то интересно. Важно то, что дамп был от MySQL 4.1.22 и снят он был при помощи одного широко известного
Давным-давно (кажется, в прошлую среду) попался ко мне в руки дамп базы данных MySQL, который следовало немедленно развернуть на моей машине. Зачем это было нужно и откуда взялся дамп, рассказывать не буду, вряд ли это кому-то интересно. Важно то, что дамп был от MySQL 4.1.22 и снят он был при помощи одного широко известного 
