Apache Ignite vs Oracle СУБД
3 мин
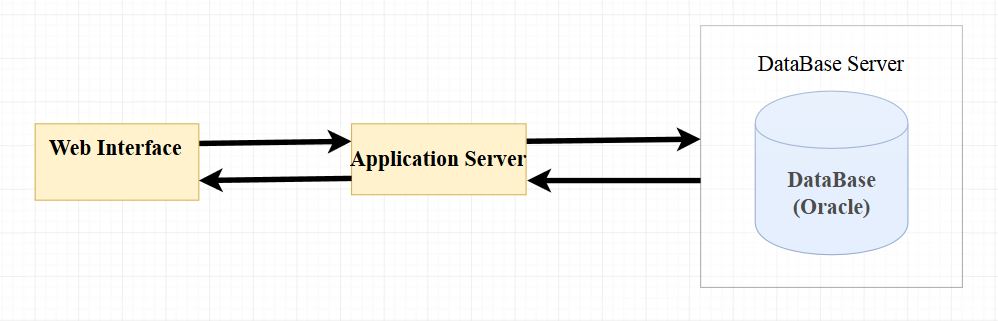
Apache Ignite – распределенная база данных в памяти, подобные БД получают распространение и хочется сравнить с тем что уже есть и зарекомендовало себя, например реляционная СУБД Oracle. Ignite имеет широкие возможности распределенных вычислений, также есть поддержка SQL на уровне ANSI-99, в производительности SQL и хочется сделать некоторое сравнение. Настройка БД будет в обоих случаях во многом по умолчанию, в случае Oracle это XE, а в случае Ignite это два узла(node) на одном компьютере. Компьютер i5 7400 (4-ядра) 3.5Ггц, 8Гб ОЗУ, SSD диск.
В качестве тестовых данных буду использовать данные КЛАДР (~223 тыс. записей) в качестве среды выполнения запросов DBeaver в котором настроены два подключения к Ignite и Oracle. И первое что сделаю импортирую данные в таблицы, Данные КЛАДР из DBF переведу в CSV, а затем средствами DBeaver выполню импорт в таблицы.
В качестве тестовых данных буду использовать данные КЛАДР (~223 тыс. записей) в качестве среды выполнения запросов DBeaver в котором настроены два подключения к Ignite и Oracle. И первое что сделаю импортирую данные в таблицы, Данные КЛАДР из DBF переведу в CSV, а затем средствами DBeaver выполню импорт в таблицы.