PostgreSQL Antipatterns: где скаляру в GiST место?
3 мин

В PostgreSQL есть "волшебный" тип индекса GiST, который позволяет быстро искать разные сложные вещи - от интервалов до массивов и даже реализовывать полнотекстовый поиск.
Про его внутреннее устройство и возможности подробно рассказывал Егор Рогов, а я в статье "PostgreSQL Antipatterns: работаем с отрезками в «кровавом энтерпрайзе»" показал, как с помощью расширения btree_gist он позволяет решать типовые бизнес-задачи.
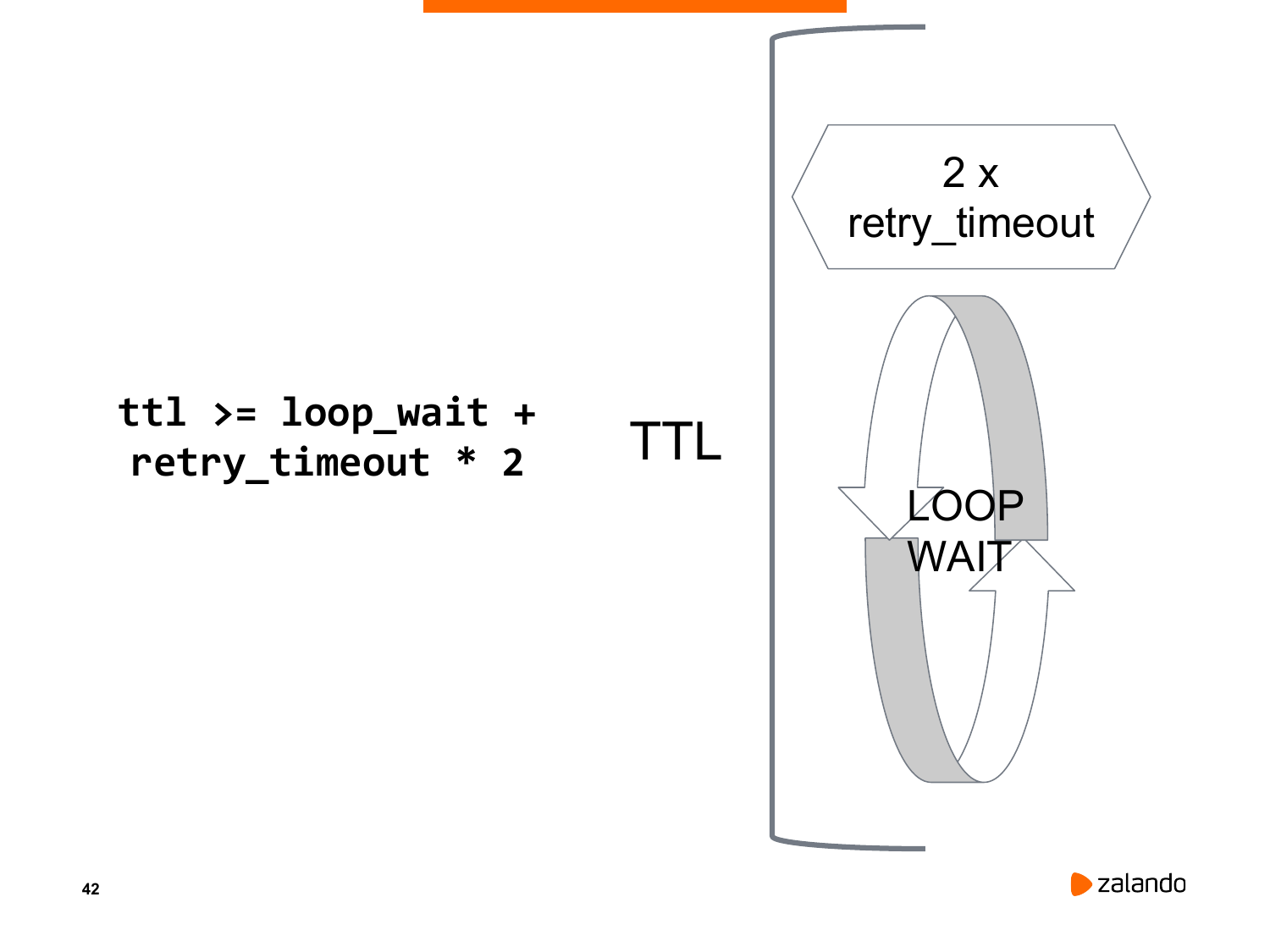
Одной из таких задач является поиск отрезков внутри сегмента со скалярным идентификатором. И если для btree очевидно, что поле с меньшей кардинальностью должно стоять в индексе раньше - индекс от этого и меньше и быстрее (см. "DBA: находим бесполезные индексы"), то так ли это однозначно для btree_gist?