Как приручить дракона или Сказочка о том, как разработчик впервые встретился с Unit-тестами
19 мин

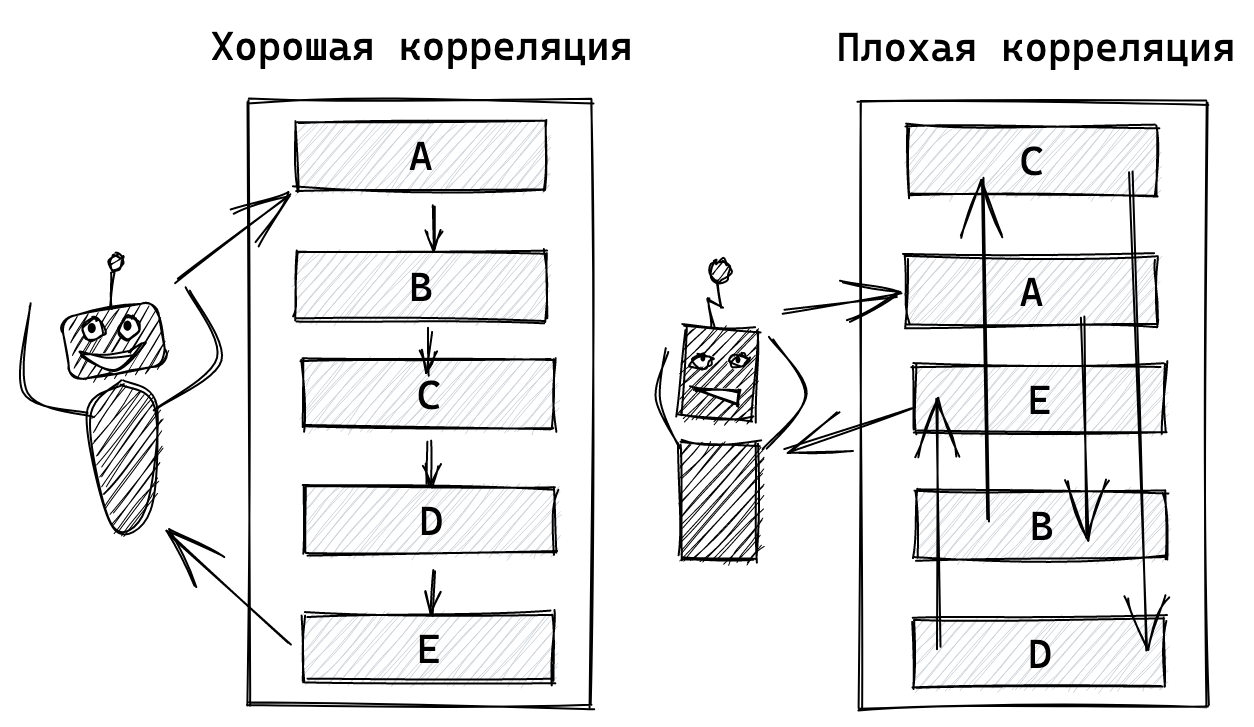
Disclaimer.
Статья не содержит описание новомодных технологий или прорывы на поприще разработки. Рассматривайте её как рассказ об опыте открытия для себя мира unit тестирования.
Если вы раньше не писали unit-тесты, но хотите начать, не уверены как тестировать вашу БД и нужно ли это, не знаете как использовать моки, и для чего они, то эта статья может стать началом вашего пути.
А ещё здесь есть драконы - и это нормально.