
Резервные копии с WAL-G. Что там в 2019? Андрей Бородин
18 мин
Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Андрея Бородина "Резервные копии с WAL-G. Что там в 2019?"

Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Андрея Бородина "Резервные копии с WAL-G. Что там в 2019?"
Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Алексея Лесовского — «Поиск и устранение проблем в Postgres с помощью pgCenter»
Время от времени при эксплуатации Postgres'а возникают проблемы, и чем быстрее найдены и устранены источники проблемы, тем благодарнее пользователи. pgCenter это набор CLI утилит которые является мощным средством для выявления и устранения проблем в режиме "здесь и сейчас". В этом докладе я расскажу как эффективно использовать pgCenter для поиска и устранения проблем, в каких направлениях осуществлять поиск и как реагировать на те или иные проблемы, в частности, как:




Проекты развиваются, клиентская база увеличивается, базы данных разрастаются, и наступает момент, когда мы начинаем замечать, что некогда простые манипуляции над базами данных требуют более сложных действий, а цена ошибки сильно повышается. Уже нельзя за раз промигрировать данные с одного столбца в другой, индексы лучше накатывать асинхронно, добавлять столбцы с default значениями теперь нельзя.
Одной из команд, с которой надо быть осторожным на таблицах с большим количеством записей, является добавление not null constraint на столбец. При добавлении данного constraint PostgreSQL приобретает access exclusive lock на таблицу, в результате чего другие сессии не могут временно даже читать таблицу; затем БД проверяет, что в столбце действительно ни одного null нет, и только после этого вносятся изменения. Под катом я рассмотрю различные варианты, как можно добавить not null constraint, лоча таблицу на минимально возможное время или даже не лоча ее совсем.
check constraint на таблицу, а затем "преобразовать" его в not null constraint для конкретного столбца.pg_attribute (этот пункт подробно разбирается в статье).

Когда строка изменяется командой UPDATE, фактически выполняются две операции: DELETE и INSERT. В текущей версии строки устанавливается xmax, равный номеру транзакции, выполнившей UPDATE. Затем создается новая версия той же строки; значение xmin у нее совпадает с значением xmax предыдущей версии.Через какое-то время после завершения этой транзакции старая или новая версии, в зависимости от
COMMIT/ROOLBACK, будут признаны «мертвыми» (dead tuples) при проходе VACUUM по таблице и зачищены.
... LIKE '%роза%' — ведь тогда в результат попадают не только 'Розалия' и 'Магазин Роза', но и 'Гроза' и даже 'Дом Деда Мороза'.Привет.
Меня зовут Ваня, и я Java-разработчик. Так получилось, что я много работаю с PostgreSQL – занимаюсь настройкой БД, оптимизацией структуры, производительностью и немного играю в DBA по выходным.
За последнее время я привёл в порядок несколько баз данных в наших микросервисах и написал java-библиотеку pg-index-health, которая облегчает эту работу, экономит моё время и помогает избежать некоторых типовых ошибок, допускаемых разработчиками. Именно об этой библиотеке сегодня и пойдёт речь.

Основная версия PostgreSQL, с которой я работаю, это 10-ка. Все используемые мною SQL-запросы также проверены на 11-й версии. Минимальная поддерживаемая версия — это 9.6.
Началось всё почти год назад со странной для меня ситуации: конкурентное создание индекса на ровном месте завершилось с ошибкой. Сам индекс, как водится, в невалидном состоянии остался в базе. Анализ логов показал нехватку temp_file_limit. И понеслось… Копнув поглубже, я обнаружил целый ворох проблем в конфигурации БД и, засучив рукава, с блеском в глазах принялся их чинить.
ON UPDATE, переносящий все изменения в какие-нибудь агрегаты. А вам надо все пообновлять (новое поле проинициализировать, например) так аккуратно, чтобы эти агрегаты не затронулись.BEGIN;
ALTER TABLE ... DISABLE TRIGGER ...;
UPDATE ...; -- тут долго-долго
ALTER TABLE ... ENABLE TRIGGER ...;
COMMIT;ALTER TABLE накладывает AccessExclusive-блокировку, под которой никто параллельно выполняющийся, даже простой SELECT, ничего из таблицы прочитать не сможет. То есть пока эта транзакция не закончится, все желающие даже «просто почитать» будут ждать. А мы помним, что UPDATE у нас до-о-олгий…
SELECT count(*)
FROM /* сложный запрос */;SELECT count(*) FROM large_table;
Buffer в Node.js, знание которых может сильно сэкономить ваше время и серверные ресурсы.ERROR: index row size… exceeds maximum… for index ...То есть даже в простейшем случае индекса из единственной строки — можно наступить на грабли. Как с ними бороться?
 Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
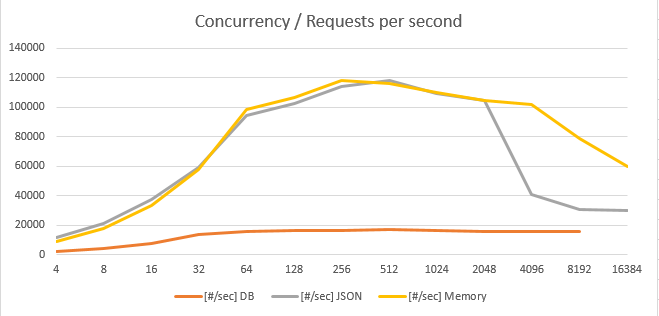
На глаза попалась не особо позитивное сравнение Java vs GO. Тестирование большим числом пользователей.
Решил проверить, действительно ли так все не радужно с Go.
Забегая вперед скажу, что при кэшировании в памяти и формировании JSON "на лету" удалось получить до 120 000 [#/sec] на 8 физических ядра.
Базовый сценарий GET запроса:
Под катом результаты тестирования, и код тестового стенда GitHub
Повилась возможность протестировать в облаке Oracle.

{kind=link}