
Один из методов получения истории блокировок в PostgreSQL
7 мин
Продолжение статьи "Попытка создать аналог ASH для PostgreSQL ".
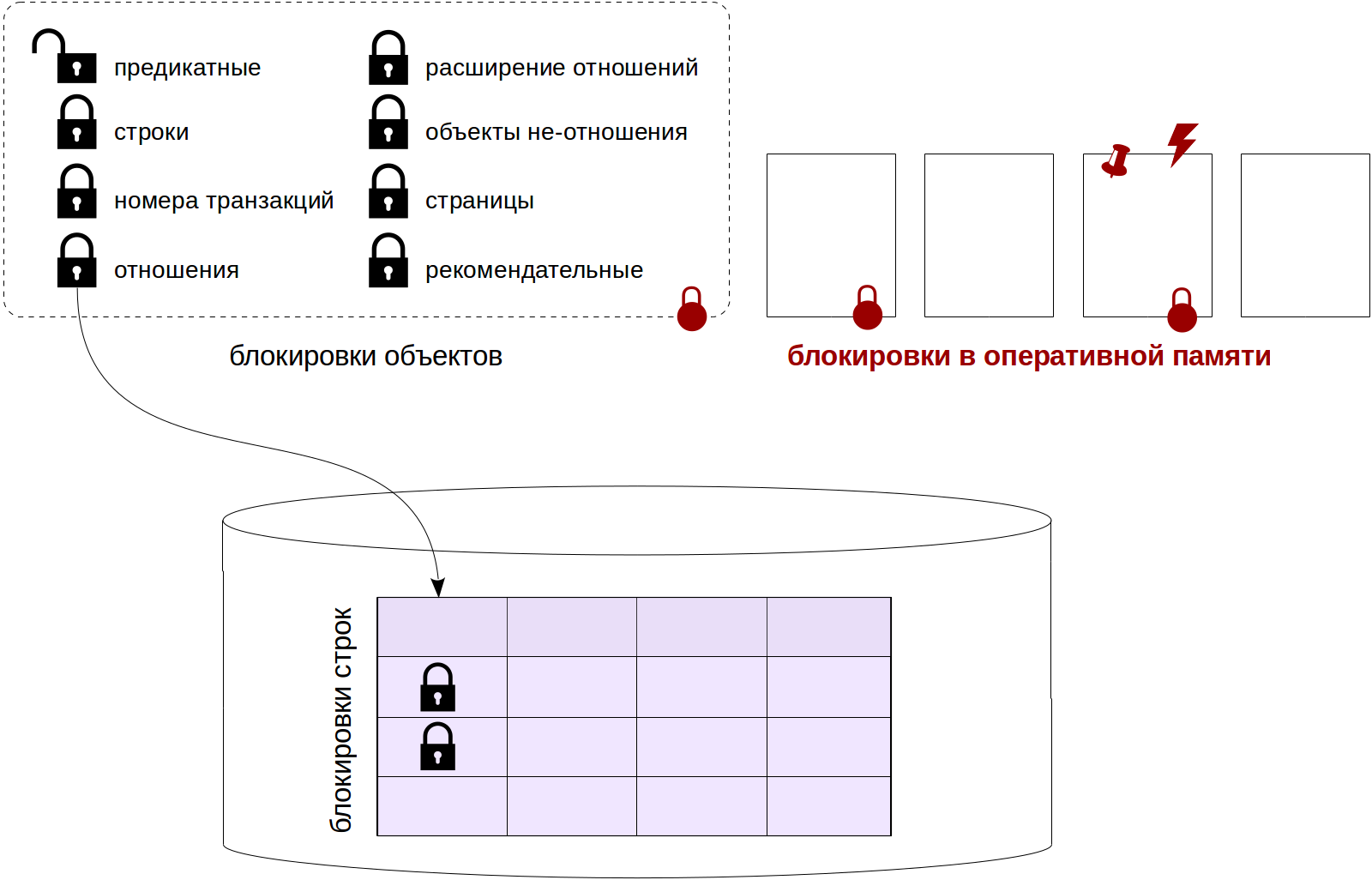
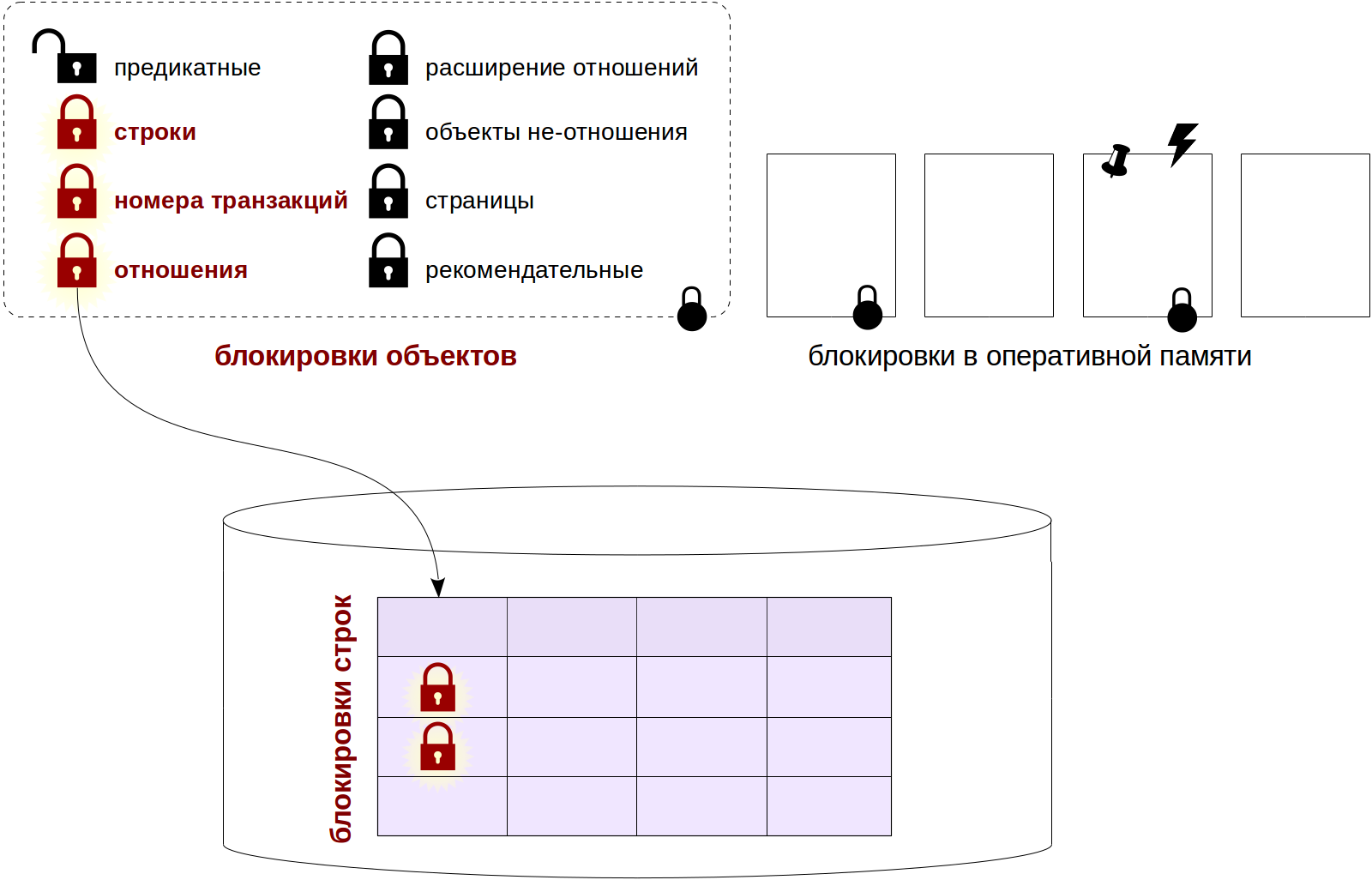
В статье будет рассмотрено и показано на конкретных запросах и примерах — какую же полезную информацию можно получить с помощью истории представления pg_locks.
В статье будет рассмотрено и показано на конкретных запросах и примерах — какую же полезную информацию можно получить с помощью истории представления pg_locks.
Предупреждение.
В связи с новизной темы и незавершением периода тестирования, статья может содержать ошибки. Критика и замечания всячески приветствуются и ожидаются.



 Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.

 По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.
По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.