Postgres в ретроспективе
37 мин
Перевод
Предлагаем вашему вниманию перевод статьи Джозефа Хеллерштейна «Looking Back at Postgres», опубликованной в соответствии с международной лицензией Creative Commons «С указанием авторства» версии 4.0 (CC-BY 4.0). Авторы оставляют за собой право распространять эту работу на личных и корпоративных веб-сайтах с надлежащей ссылкой на источник.
Перевод выполнен Еленой Индрупской. От себя добавлю, что «программист, который отчаянно хотел построить систему с многоверсионностью» — судя по всему, Вадим Михеев, ну а «добровольцев из России», переписавших GiST, мы все хорошо знаем.
Это воспоминание о проекте Postgres, выполняемом в Калифорнийском университете в Беркли и возглавляемом Майком Стоунбрейкером (Mike Stonebraker) с середины 1980-х до середины 1990-х годов. В качестве одного из многих личных и исторических воспоминаний, эта статья была запрошена для книги [Bro19], посвященной награждению Стоунбрейкера премией Тьюринга. Поэтому в центре внимания статьи — руководящая роль Стоунбрейкера и его мысли о дизайне. Но Стоунбрейкер никогда не был программистом и не мешал своей команде разработчиков. Кодовая база Postgres была работой команды блестящих студентов и эпизодически—штатных университетских программистов, которые имели немного больше опыта (и только немного большую зарплату), чем студенты. Мне посчастливилось присоединиться к этой команде в качестве студента в последние годы проекта. Я получил полезный материал для этой статьи от некоторых более старших студентов, занятых в проекте, но любые ошибки или упущения являются моими. Если вы заметили какие-либо из них, пожалуйста, свяжитесь со мной, и я постараюсь их исправить.
Перевод выполнен Еленой Индрупской. От себя добавлю, что «программист, который отчаянно хотел построить систему с многоверсионностью» — судя по всему, Вадим Михеев, ну а «добровольцев из России», переписавших GiST, мы все хорошо знаем.
Аннотация
Это воспоминание о проекте Postgres, выполняемом в Калифорнийском университете в Беркли и возглавляемом Майком Стоунбрейкером (Mike Stonebraker) с середины 1980-х до середины 1990-х годов. В качестве одного из многих личных и исторических воспоминаний, эта статья была запрошена для книги [Bro19], посвященной награждению Стоунбрейкера премией Тьюринга. Поэтому в центре внимания статьи — руководящая роль Стоунбрейкера и его мысли о дизайне. Но Стоунбрейкер никогда не был программистом и не мешал своей команде разработчиков. Кодовая база Postgres была работой команды блестящих студентов и эпизодически—штатных университетских программистов, которые имели немного больше опыта (и только немного большую зарплату), чем студенты. Мне посчастливилось присоединиться к этой команде в качестве студента в последние годы проекта. Я получил полезный материал для этой статьи от некоторых более старших студентов, занятых в проекте, но любые ошибки или упущения являются моими. Если вы заметили какие-либо из них, пожалуйста, свяжитесь со мной, и я постараюсь их исправить.
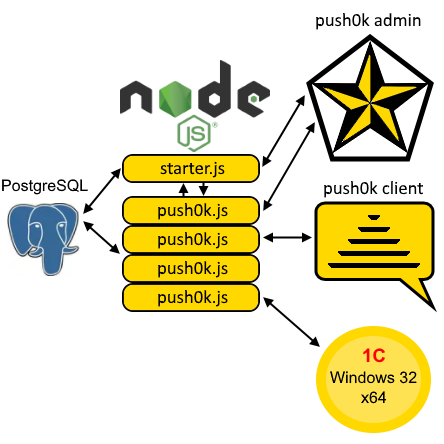




 В PostgreSQL начиная с очень давних времён
В PostgreSQL начиная с очень давних времён