Дайджест новостей из мира PostgreSQL. Выпуск №10
6 мин

Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.
Релизы
PostgreSQL 11 Beta 4
В этом релизе починили баги, выявленные после выхода Beta 3. В том числе:
- теперь отключена по умолчанию
JIT-компиляция. - имена в
constraint-ах должны быть уникальны. - убрали утечку памяти при обращении к XMLTABLE
- исправили ошибки в хранимых процедурах
- доработали секционирование, в том числе выбор секций в момент исполнения (runtime partition pruning)
Подробнее здесь.
PostgreSQL 10.5
В этом релизе несколько десятков исправлений, касающихся WAL, libpq, VACUUM и FREEZE, индексов GIN, распараллеливания запросов, OpenSSL. Вот их список.
Postgres Pro Enterprise 10.5.2.
В этой версии есть следующие нововведения по отношению к Postgres Pro Enterprise 10.5.1, они касаются
pgbench:pgbenchтеперь поддерживает составные команды;- с помощью параметра
--latency-limitтеперь можно ограничить время, отведённое на повторение транзакций. Если при использовании данного параметра значение--max-tries=0, транзакции могут повторяться неограниченное число раз, пока не истечёт время, заданное параметром--latency-limit; - при вычислении количества обработанных транзакций и скорости выполнения (TPS) пропущенные и неуспешные транзакции больше не учитываются.
Напомним, за время между нашими выпусками вышел релиз Postgres Pro Enterprise 10.5.1.. Там есть существенные изменения, о них можно прочитать здесь.





 Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
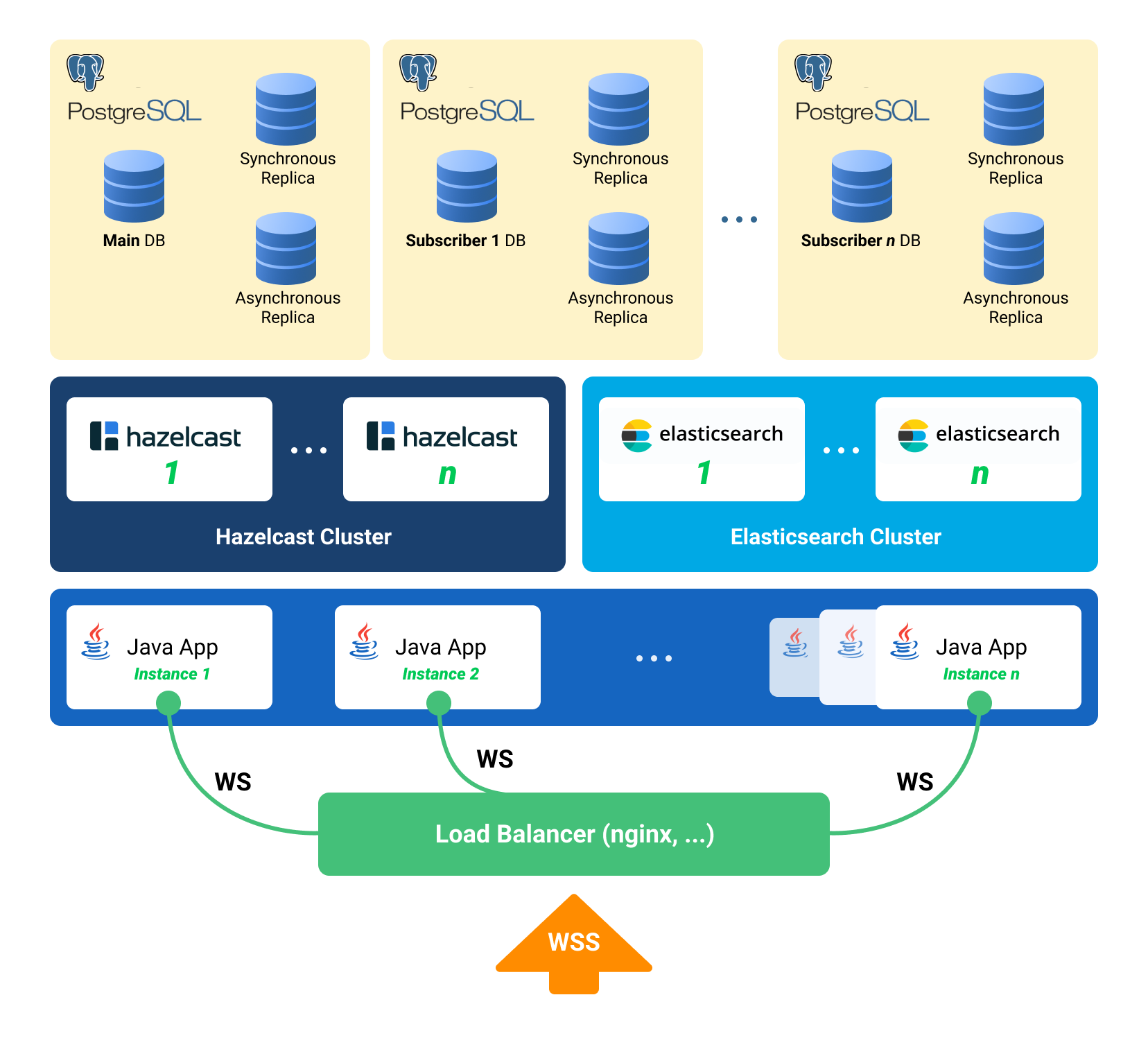
 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.