Нередко бывает так, что в большом проекте в силу тех или иных причин — зачастую исторических, хотя бывает по-всякому — его части могут использовать различные СУБД для хранения и поиска критически важных данных. В числе прочего, этому разнообразию способствует конкуренция и развитие технологий, но, так или иначе, взаимодействие между СУБД описывает стандарт SQL/MED 2003 (Management of External Data), который вводит определение Foreign Data Wrappers (FDW) и Datalink.
Первая часть стандарта предлагает средства для чтения данных как набора реляционных таблиц под управлением одного или нескольких внешних источников; FDW также может представлять возможность использовать SQL-интерфейс для доступа к не SQL данным, таким, как файлы или, например, список писем в почтовом ящике. Вторая часть, Datalink, позволяет управлять удаленным SQL-сервером.
Эти две части были реализованы еще в PostgreSQL 9.1 и называются FDW и dblink соответственно. FDW в PostgreSQL сделан максимально гибко, что позволяет разрабатывать wrapper'ы для большого количества внешних источников. В настоящее время мне известны такие FDW, как PostgreSQL, Oracle, SQL Server, MySQL, Cassandra, Redis, RethinkDB, Ldap, а также FDW к файлам типа CSV, JSON, XML и т.п.
В нашей статье мы поговорим о том, как настроить подключение PostgreSQL к MySQL и эффективно выполнять получающиеся запросы.



 При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от
При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от 
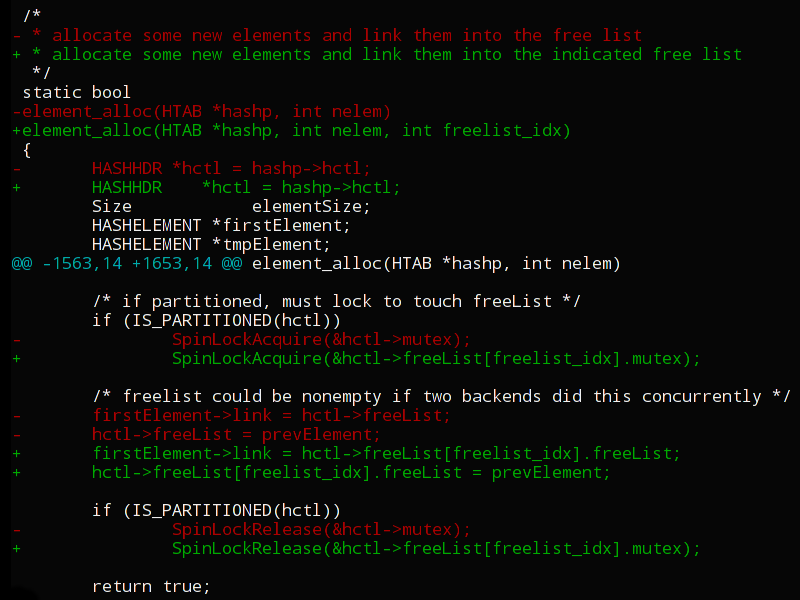

 Многие пользуются
Многие пользуются 
 В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.
В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.


