
Проверяем IronPython и IronRuby с помощью PVS-Studio
9 мин
Совсем недавно мы выпустили новую версию нашего анализатора PVS-Studio с поддержкой проверки C# проектов. Пока на время релиза дальнейшая разработка продукта была приостановлена, я занимался тестированием анализатора. В качестве проектов для своих экспериментов я взял IronPython и IronRuby. А раз эти проекты были проверены, я решил написать небольшую статью-отчёт.

IronPython и IronRuby представляют собой реализацию языков программирования Python и Ruby на платформе .NET. Исходный код этих проектов доступен на GitHub по этой ссылке. Также в комплекте идёт исходный код DLR. Начиная с .NET Framework 4.0 DLR является его частью, и IronPython и IronRuby используют её. Тем не менее я всё равно проверил старую версию DLR, раз уж она там оказалась.
IronPython и IronRuby
IronPython и IronRuby представляют собой реализацию языков программирования Python и Ruby на платформе .NET. Исходный код этих проектов доступен на GitHub по этой ссылке. Также в комплекте идёт исходный код DLR. Начиная с .NET Framework 4.0 DLR является его частью, и IronPython и IronRuby используют её. Тем не менее я всё равно проверил старую версию DLR, раз уж она там оказалась.

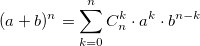 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 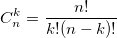 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: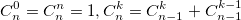 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.







 СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.
СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.