Гибадуллина Д.А Гибадуллина Дарья Анатольевна/ Gibadullina Daria Anatolievna- студент второго курса бакалавриат Уральского филиала Финансового университета направления бизнес-информатика
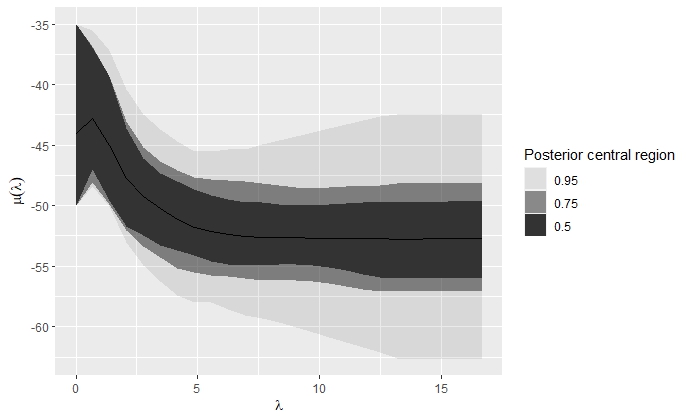
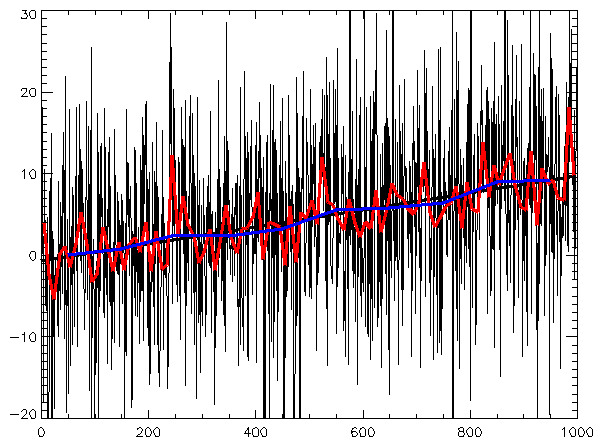
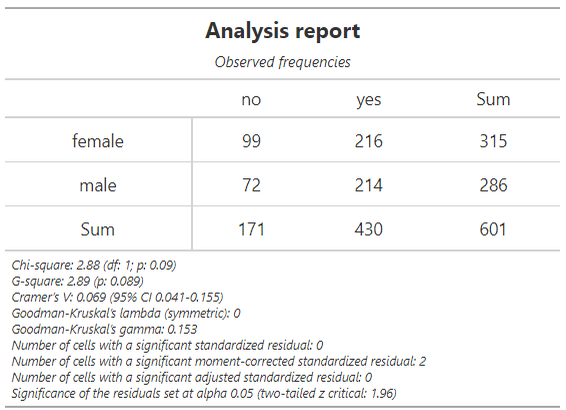
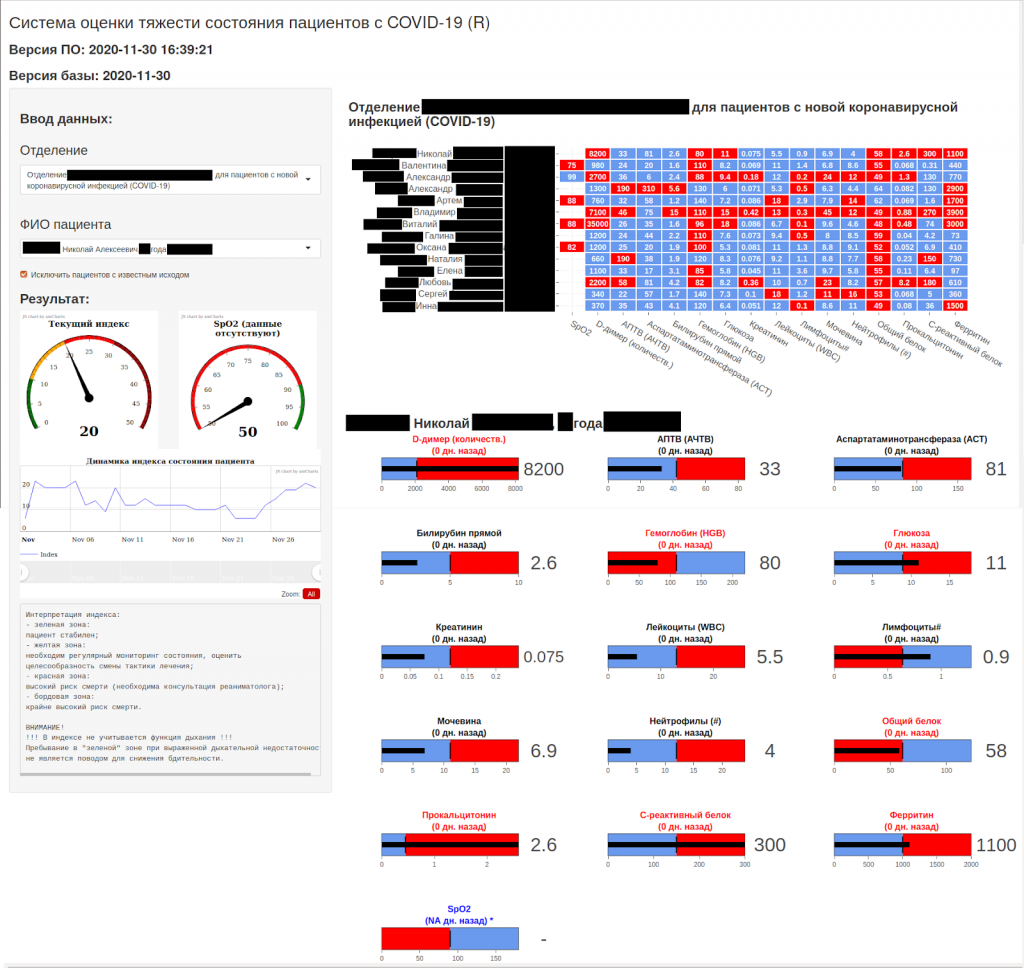
Аннотация: Язык программирования R имеет широкое применение в области статистических вычислений и анализа данных В данной статье мы рассмотрим основные возможности языка R, его синтаксис и особенности, а также примеры использования для решения задач статистического анализа данных. Также мы рассмотрим некоторые популярные пакеты и библиотеки, которые доступны для работы с данными в R. Данная статья поможет читателю ознакомиться с основами языка R и его применением в статистических вычислениях.
Annotation: The R programming language has wide application in the field of statistical computing and data analysis. In this article, we will consider the main features of the R language, its syntax and features, as well as examples of use for solving problems of statistical data analysis. We will also look at some popular packages and libraries that are available for working with data in R. This article will help the reader to familiarize himself with the basics of the R language and its application in statistical computing.
Ключевые слова: язык программирования, язык программирования R, синтаксис R, библиотеки R, анализ данных, статистический анализ, обработка данных на R.
Keywords: programming language, R programming language, R syntax, R libraries, data analysis, statistical analysis, data processing in R.