
Привет! Очередной длинный пост о том, что мы сделали за последние четыре месяца. Как всегда, мы говорим DataGrip, а подразумеваем все остальные наши IDE. В том числе и WebStorm, SQL-плагин к которому теперь можно докупить.

GROUP/DISTINCT и LIMIT вместе с ними.
SELECT DISTINCT
X.*
FROM
X
JOIN
Y
ON Y.fk = X.pk
WHERE
Y.bool_condition;JOIN — получили какие-то значения pk по несколько раз (ровно сколько подходящих записей в Y оказалось). Как убрать? Конечно DISTINCT!WHERE fncondX() AND fncondY()= fncondX() && fncondY()
ON UPDATE, переносящий все изменения в какие-нибудь агрегаты. А вам надо все пообновлять (новое поле проинициализировать, например) так аккуратно, чтобы эти агрегаты не затронулись.BEGIN;
ALTER TABLE ... DISABLE TRIGGER ...;
UPDATE ...; -- тут долго-долго
ALTER TABLE ... ENABLE TRIGGER ...;
COMMIT;ALTER TABLE накладывает AccessExclusive-блокировку, под которой никто параллельно выполняющийся, даже простой SELECT, ничего из таблицы прочитать не сможет. То есть пока эта транзакция не закончится, все желающие даже «просто почитать» будут ждать. А мы помним, что UPDATE у нас до-о-олгий…


Для организации обработки потока задач используются очереди. Они нужны для накопления и распределения задач по исполнителям. Также очереди могут обеспечивать дополнительные требования к обработке задач: гарантия доставки, гарантия однократного исполнения, приоритезация и т. д.
Как правило, используются готовые системы очередей сообщений (MQ — message queue), но иногда нужно организовать ad hoc очередь или какую-нибудь специализированную (например, очередь с приоритетом и отложенным перезапуском не обработанных из-за исключений задач). О создании таких очередей и пойдёт речь ниже.
Предлагаемые решения предназначены для обработки потока однотипных задач. Они не подходят для организации pub/sub или обмена сообщениями между слабо связанными системами и компонентами.
Очередь поверх реляционной БД хорошо работает при малых и средних нагрузках (сотни тысяч задач в сутки, десятки-сотни исполнителей), но для больших потоков лучше использовать специализированное решение.
select ... for update skip locked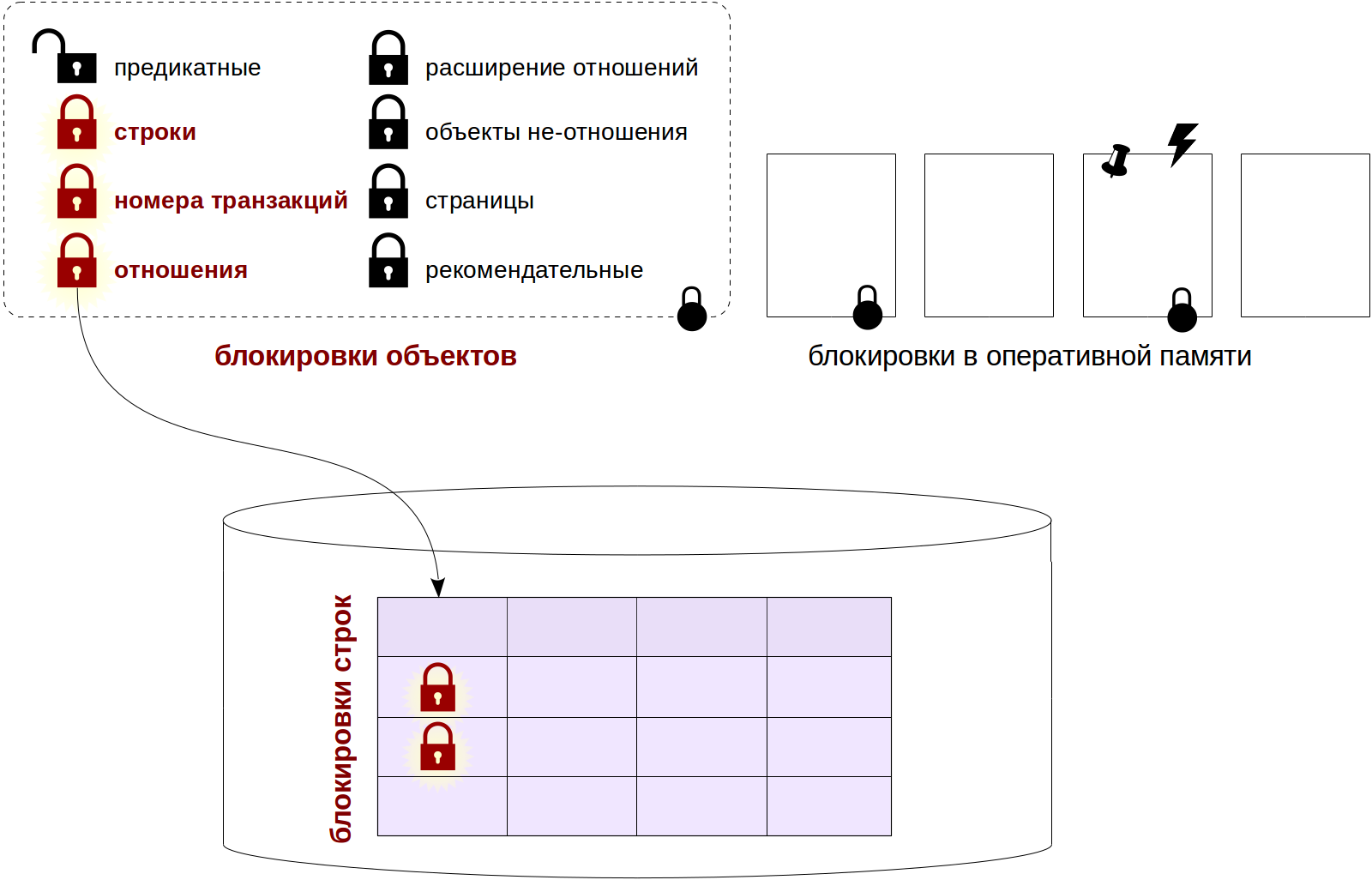


use <имя_БД>;
go
create schema inf;




Привет! Меня зовут Яша Финкельберг, я senior аналитик в Авито. Здесь мы постоянно следим за удовлетворённостью продавцов и покупателей площадки и ищем способы улучшать их взаимодействие с Авито. Чтобы находить более детальные драйверы, сегментировать запросы и ставить предсказуемые цели в работе с обращениями, мы решили разработать собственную метрику для работы с опытом пользователей — weighted contact rate (wCR). В статье я расскажу, почему мы решили дополнить существующие метрики нашей, и дам пайплайн разработки, по которому уже вы сможете внедрить что-то подобное у себя в компании. Текст будет полезен аналитикам крупных компаний.

Некоторые головоломки можно решать на SQL just for fun, а часть получается выразить на этом декларативном языке даже эффективнее других, императивных.
Попробовать сделать более наглядное решение, а заодно познакомить с некоторыми нетривиальными возможностями PostgreSQL меня натолкнул пост о решении на Python задачи Black and White.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В первой части лекции мы узнали, что такое план выполнения запроса, как и зачем его читать (и почему это совсем непросто), и о каких проблемах с производительностью базы он может сигнализировать. В этой - разберем, что такое Seq Scan, Bitmap Heap Scan, Index Scan и почему Index Only Scan бывает нехорош.
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись (часть 1, часть 2) и слайды.

Мем айсберг SQL: погружение в глубины изучения баз данных
Мем айсберг SQL — это вирусное интернет-изображение, изображающее айсберг с несколькими слоями. Вершина айсберга содержит общеизвестные концепции и инструменты SQL, такие как операторы SELECT и JOIN. Однако по мере погружения под воду становятся видны более абсурдные и малоизвестные аспекты SQL.

Вдохновившись прошлогодним опытом, мы продолжили начинание и снова проводим конкурс по SQL на международной олимпиаде «IT-Планета».
Конкурс состоит из трех этапов. Заочный теоретический тест собрал почти 3000 человек, из которых на следующий этап мы отобрали примерно 200. Вопросы для этого этапа были подготовлены моим коллегой, Евгением Давыдовым.
Второй этап — также заочный. Здесь участником было предложено подумать над пятью задачами моего авторства, о которых я сегодня и хочу рассказать.
Третий — очный — этап пройдет в конце мая; постараюсь не затягивать с отчетом, но пока храню интригующее молчание.
Поскольку все вводные слова про мотивацию я уже сказал в прошлый раз, сразу приступим к делу.