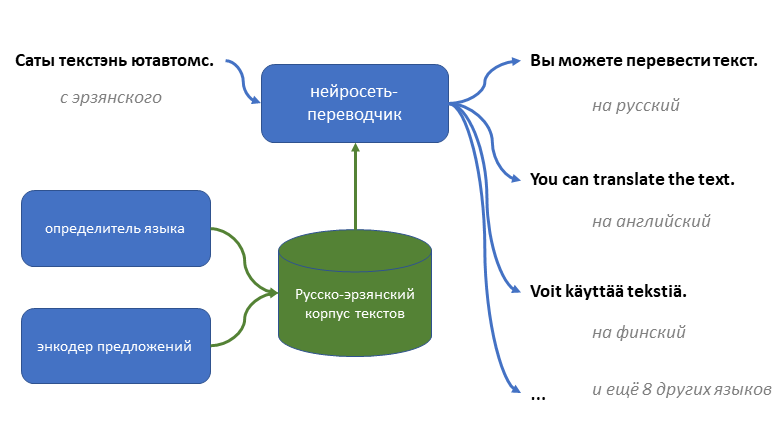
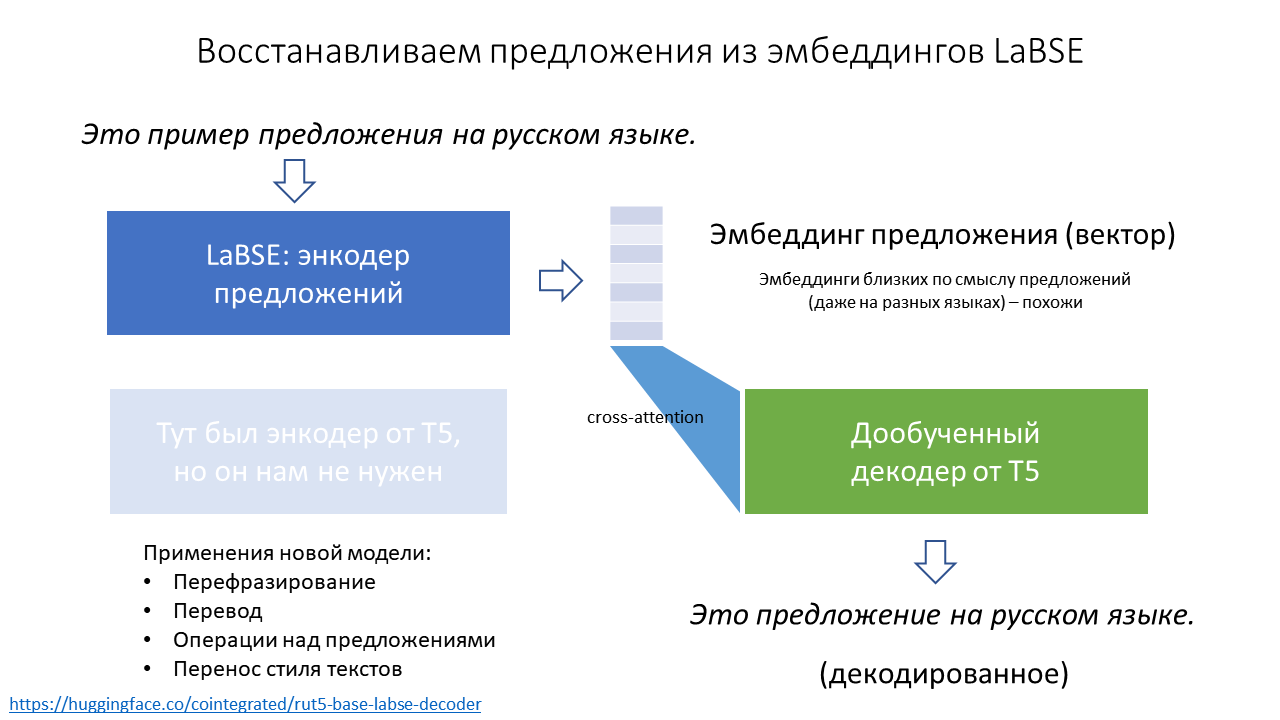
В общем случае (вне и до информационных технологий), произнося слово «семантика», предлагают обсудить смысловой уровень языка – значения знаков и структур знаков (текстов). При этом семантика противопоставляется синтаксису, то есть формальным правилам соединения знаков в текст. Когда же речь о семантике заводится в сфере IT, то имеют в виду особые технологии, архитектуры приложений и языки описания данных, ориентированные на знаковое представление объектов и их свойств в компьютерных моделях предметных областей. В качестве основной цели семантического подхода видится «научение» компьютера распознавать смысл данных, описывающих деятельность и ее элементы, то есть реализовать переход от оперирования безликими данными к работе со значениями и знаниями. Предполагается, что широкое использование семантического подхода к моделированию предметных областей позволит унифицировать обмен информацией между независимыми поставщиками данных и приложениями, а также обеспечит возможность модифицировать структуру данных и бизнес-логику приложений не путем переписывания кода, а только через преобразование семантически определенных данных. К основным методам семантического подхода следует отнести: унификацию формата записи, уникальную идентификацию записей, включение метаданных в данные, стандартизацию словарей.
Традиционно семантическое описание предметной области называют онтологией этой области. При этом выражения «онтологическое описание», «онтологическая модель», «онтология предметной области» используют как синонимы. Онтология или онтологическая модель предметной области – это, по сути, структура из сущностей (концептов, понятий, типов объектов), их свойств и правил установления отношений между ними. Обычно онтологию представляют в виде графа, вершинами которого являются объекты, а ребрами – свойства. Часто такую структуру из объектов и значений их свойств, построенную для определенной предметной области, называют графом знаний (Knowledge Graph).