
Адреса памяти: физические, виртуальные, логические, линейные, эффективные, гостевые
6 мин
Туториал
Мне периодически приходится объяснять разным людям некоторые аспекты архитектуры Intel® IA-32, в том числе замысловатость системы адресации данных в памяти, которая, похоже, реализовала почти все когда-то придуманные идеи. Я решил оформить развёрнутый ответ в этой статье. Надеюсь, что он будет полезен ещё кому-нибудь.
При исполнении машинных инструкций считываются и записываются данные, которые могут находиться в нескольких местах: в регистрах самого процессора, в виде констант, закодированных в инструкции, а также в оперативной памяти. Если данные находятся в памяти, то их положение определяется некоторым числом — адресом. По ряду причин, которые, я надеюсь, станут понятными в процессе чтения этой статьи, исходный адрес, закодированный в инструкции, проходит через несколько преобразований.
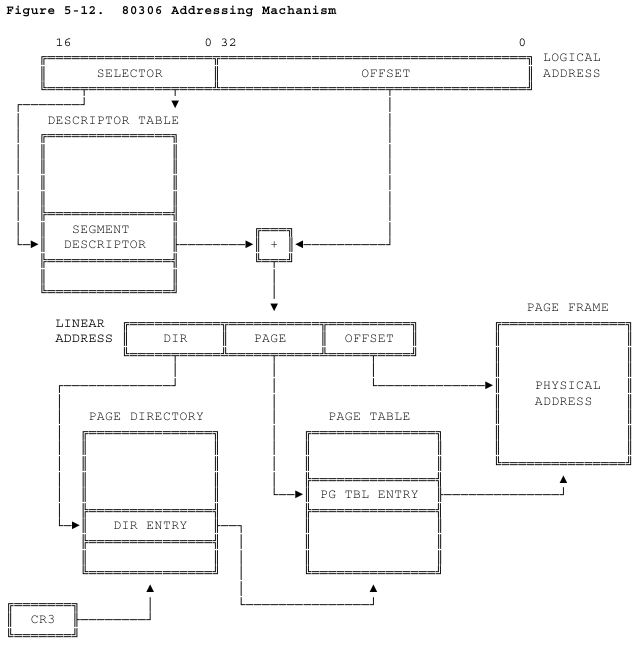
На рисунке — сегментация и страничное преобразование адреса, как они выглядели 27 лет назад. Иллюстрация из Intel 80386 Programmers's Reference Manual 1986 года. Забавно, что в описании рисунка есть аж две опечатки: «80306 Addressing Machanism». В наше время адрес подвергается более сложным преобразованиям, а иллюстрации больше не делают в псевдографике.
При исполнении машинных инструкций считываются и записываются данные, которые могут находиться в нескольких местах: в регистрах самого процессора, в виде констант, закодированных в инструкции, а также в оперативной памяти. Если данные находятся в памяти, то их положение определяется некоторым числом — адресом. По ряду причин, которые, я надеюсь, станут понятными в процессе чтения этой статьи, исходный адрес, закодированный в инструкции, проходит через несколько преобразований.
На рисунке — сегментация и страничное преобразование адреса, как они выглядели 27 лет назад. Иллюстрация из Intel 80386 Programmers's Reference Manual 1986 года. Забавно, что в описании рисунка есть аж две опечатки: «80306 Addressing Machanism». В наше время адрес подвергается более сложным преобразованиям, а иллюстрации больше не делают в псевдографике.
 FizzBuzz предполагается как простое задание для новичка, но в Rust присутствуют несколько подводных камней, о которых лучше знать. Эти подводные камни не являются проблемами Rust, а, скорее, отличиями от того, с чем знакомо большиство программистов, ограничениями, которые на первый взгляд могут показаться очень жёсткими, но в действительности дают громадные преимущества за малой ценой.
FizzBuzz предполагается как простое задание для новичка, но в Rust присутствуют несколько подводных камней, о которых лучше знать. Эти подводные камни не являются проблемами Rust, а, скорее, отличиями от того, с чем знакомо большиство программистов, ограничениями, которые на первый взгляд могут показаться очень жёсткими, но в действительности дают громадные преимущества за малой ценой. 


 Я являюсь участником проекта по разработке
Я являюсь участником проекта по разработке 






{kind=link}