
Если вы администрируете распределённую сеть, то наверняка периодически сталкиваетесь с задачей оценить фактическую пропускную способность каналов (VPN) между офисами. В общем случае, это можно делать тремя способами. Один очень прост, но непригоден для мониторинга каналов на регулярной основе. Это использование Iperf и т.п. Два других могут использоваться постоянно, но настолько сложны и дороги, что могут себе позволить только крупные и очень крупные компании. К этой категории относятся решения на основе анализа сетевого трафика в реальном времени (network sniffing) и решения, подмешивающие тестовый трафик в пользовательский трафик, и оценивающие прохождение тестового трафика. А что делать всем остальным, тем, кому нужно управлять качеством каналов, но по объективным причинам не относится к ЦА сверхдорогих решений? В этой статье я расскажу о новой технологии управления качеством работы сети. Она несравнимо проще и доступнее решений на основе подмешивания тестового трафика и network sniffing, не требует установки аппаратных зондов, но при этом позволяет управлять качеством распределённой сети на регулярной основе.
Это сугубо прагматическая концепция, разработанная исходя из возникающих на практике задач. Новизна описываемой технологии в том, что метод нагрузочного тестирования (используемый в Iperf, Chariot и т.п.), обычно применяемый для разовых измерений скорости сети, интегрирован в систему сетевого мониторинга. Отсюда и название технологии – Нагрузочный Мониторинг Сети (НМС). Кратко, идея НМС – в автоматическом проведении нагрузочных тестирований в те моменты времени, когда внутренние пользователи сети не активны (эти моменты определяются автоматически). Пропускная способность сети измеряется на уровне TCP. Основная область применения НМС – управление качеством VPN-соединений, например, в рамках Service Level Management.
Сначала несколько слов, что такое качество сети, в частности, качество каналов связи, какие методы для оценки качества чаще всего используются, в чем их достоинства и недостатки. (Здесь и далее термины «сеть» и «канал связи» будем употреблять как синонимы.) Под качеством сети будем понимать её применимость для конкретных целей. Сеть работает хорошо, если обеспечивается требуемое время реакции бизнес-приложений (end-to-end response time), требуемое качество передачи голоса (R-Value, MOS) и т.п. Другими словами, качество сети – это выполнение требований доступности ИТ-Сервисов. Именно ИТ-Сервисов, а не только каналов или оборудования. Высокая доступность сетевого оборудования, низкая утилизация портов, отсутствие ошибок передачи данных и т.п. – это ещё не гарантия того, что сеть обеспечивает требуемую доступность ИТ-Сервисов. Низкая утилизация портов может быть следствием задержек на оборудовании провайдера, вызывающих повторные передачи пакетов после таймаутов, потери пакетов могут не сопровождаться ошибками на портах сетевых устройств и т.п. Это означает, что с помощью обычной системы мониторинга, поддерживающей SNMP и WMI, качество работы сети измерить, как правило, нельзя. Такие системы для этого и не предназначены.
Вообще, когда заходит речь об измерении или оценке качества работы сети, нужно конкретизировать, что именно имеется в виду:
- Мониторинг качества сети, т.е. оценка качества работы сети ВО ВРЕМЯ эксплуатации. Для мониторинга обычно используют две технологии:
- Тестирование сети (нагрузочное тестирование), которые обычно используются ДО начала эксплуатации. Например, на этапе пуско-наладки или во время приёмо-сдаточных испытаний. Тестирование – это обычно сильное воздействие на сеть и оценка реакции сети на это воздействие. Чаще всего воздействием является передача больших массивов данных, о оценкой реакции – измерение затраченного на это времени.
Примечание: В данном случае мы говорим только о технологиях, предназначенных для мониторинга КАЧЕСТВА СЕТИ. Поэтому SNMP, WMI, Transaction Simulation, Application Instrumentation и другие не рассматриваются.
Генерация тестовых пакетов (подмешивание тестовых пакетов в рабочий трафик) – это непрерывная (на фоне работающих приложений) передача в сеть определённых пакетов сетевого или транспортного уровня и измерение возникающих при этом задержек (delay), вариаций задержек (jitter), потерь пакетов (packet loss) и т.п. О качестве работы сети судят по тому, как проходят тестовые пакеты, интенсивность которых обычно невысока (чтобы не мешать работе приложений). По результатам таких измерений синтезируются интегральные показатели качества работы сети: R-Value, MOS и др. На этом методе основана, в частности, технология IP SLA, поддерживаемая оборудованием Cisco Systems.
Преимущества метода генерации тестовых пакетов:
- Высокая точность измерений. Передача тестовых пакетов и все измерения обычно выполняются на аппаратном уровне. Например, IP SLA позволяет измерять one way delay (задержку в одну сторону), а не только round trip delay, как, например, ICMP или дешёвые пробы, мимикрирующие под IP SLA.
- Возможность оценивать качество работы сети при отсутствии пользовательского трафика. Даже если в сети нет активных пользователей, вы всегда будете знать, хорошо или плохо работает сеть.
Есть и ограничения:
- Относительно высокая стоимость, если метод не поддерживается каналообразующим оборудованием. Если вся сеть построена только на базе оборудования, поддерживающего IP SLA, например, на базе Cisco Systems, то всё отлично и аппаратные зонды не нужны. Во всех остальных случаях в сети нужно устанавливать специальные аппаратные зонды, которые надо ещё и обслуживать.
- Сложность оценки потенциальных возможностей сети. Процессор, находящийся на борту сетевого устройства, как правило, не обладает производительностью, достаточной, чтобы полностью загрузить 100 Mbps- или, тем более, 1Gbps- или 10Gbps- канал.
- Сложность интерпретации получаемых результатов и, как следствие, сложность использования для ПРАКТИЧЕСКОГО управления качеством получаемого сервиса (Service Level Management). Предположим, вы хотите оценить качество работы провайдера сетевых услуг (NSP, Network Service Provider). Если это сеть VoIP, то всё просто, т.к. пороговые значения метрик jitter, delay, packet loss для разных типов кодеков хорошо известны. А если, например, в сети ещё используются 1С: Предприятие или SAP CRM? Вы знаете, какие метрики в таком случае нужно измерять и каковы должны быть их пороговые значения для обеспечения требуемых значений Service Level Objectives (SLO), Service Level Targets (SLT)? Конечно, их можно определить – построить базовую линию, провести корреляционный анализ со временем реакции бизнес-приложений и т.п. Но это сложно, дорого, и на практике этим мало кто занимается.
Можно утверждать, что сегодня это стандарт de facto для управления QoS (Quality of Service) IP-сетей. Генерация тестовых пакетов активно используется как крупными телекоммуникационными компаниями, так и крупными корпоративными клиентами. Однако в секторе Enterprise этот метод постепенно сдаёт свои позиции методу network sniffing, в первую очередь, из-за невозможности контролировать QoE (Quality of Experience, качество работы бизнес-приложений глазами пользователей).
Network sniffing – это захват и анализ всех проходящих по сети пакетов и извлечение из них информации канального уровня (ошибки, загрузка и т.п.), транспортного уровня (задержки на клиенте, сети, сервере, потерянные пакеты, нулевой размер окна и т.п.) и прикладного уровня (время реакции, MOS и т.п.).
Преимущества network sniffing:
- Возможность контролировать качество сети с привязкой к QoE.
- Возможность контролировать качество сети (QoS), реально получаемое каждым пользователем сети.
- Высочайшая точность измерений.
- Возможность не только увидеть, но и воспроизвести ситуацию в сети, которая происходила в прошлом, например, когда пользователь жаловался на медленную работу бизнес-приложения (Retrospective Network Analysis, RNA).
Недостатки метода network sniffing практически такие же, как и у метода генерации тестовых пакетов:
- Невозможность оценивать потенциальные возможности сети.
- Высокая стоимость профессионального инструментария. Единственное исключение – бесплатный WireShark, который вряд ли можно отнести к профессиональному инструментарию.
- Сложность интерпретации получаемых результатов и, как следствие, относительная сложность использования для Service Level Management.
- Дополнительное ограничение: невозможность оценивать качество работы сети при отсутствии пользовательского трафика.
Тем не менее, сегодня именно network sniffing сегодня является стандартом de facto для оценки качества работы сети внутри ЦОД, а также для организации мониторинга QoE (Real User Monitoring).
Для тестирования сети обычно используют более простые методы и средства. (Исключение –тестирование сети на пригодность к передаче голоса и видео, например, PESQ (Perceptual Evaluation of Speech Quality), но это отдельная тема.) Основной метод здесь – это передача больших массивов данных и измерение пропускной способности сети. В сети устанавливаются передатчик и приёмник данных, между которыми выполняется пересылка массивов данных известного объёма. Основным измеряемым показателем является пропускная способность сети (throughput), она же скорость, которая вычисляется как отношение объёма переданных данных к затраченному на это времени. Считается, что чем выше пропускная способность сети, тем лучше её качество. Изменяя объем и состав передаваемых данных, TOS, протокол и другие параметры, можно оценивать качество сети под различные бизнес-приложения.
Существует множество различного инструментария, предназначенного для тестирования сети, как бесплатного (Iperf, speedtest и т.п.), так и коммерческого (FTest, Chariot и т.п.). Достоинства и недостатки большинства таких средств прямо противоположны достоинствам и недостаткам систем мониторинга (IP SLA, network sniffing). Если системы мониторинга, как правило, не позволяют оценивать потенциальные возможности сети, то средства тестирования только для этого и предназначены. Системы мониторинга, как правило, сложны в использовании. Средства тестирования, наоборот, просты и понятны. Но главное преимущество средств тестирования – это ПРОСТОТА ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ.
Как уже говорилось выше, определить пороговые значения метрик, измеряемых системами мониторинга, часто бывает очень непросто. При тестировании сети вы всегда точно знаете, какой результат означает хорошее качество сети, а какой – плохое. Например, если вы тестируете 100 МВ – канал на уровне ТСР, передавая для этого большие массивы данных, то накладные расходы (преамбула, заголовки, синхронизация) составят около 10%–12%. Поэтому если пропускная способность сети будет на уровне 88Mbps–90Mbps, то потерь нет и сеть работает хорошо. Чем меньше эти цифры, тем хуже работает сеть. Поэтому, если провайдер говорит, что он дал вам канал 100 Mbps, а эффективная пропускная способность на уровне 88Mbps–90Mbps, он вас не обманывает. Но если эффективная пропускная способность при этом составляет 60 Mbps, то это предмет для разговора.
Основное ограничение большинства средств тестирования (Iperf, Chariot и т.п.) – невозможность их использования в постоянном режиме, в частности, во время эксплуатации сети. Вы можете попросить пользователей не работать, и измерить пропускную способность сети один раз, два раза, десять раз, но вы не можете делать это постоянно. Сеть для работы, а не для тестирования. Если же вы будете тестировать сеть в то время, когда в ней работают пользователи, то, во-первых, вы будете мешать пользователям, во-вторых, результаты тестирования будут не достоверны, т.к. на них будет влиять пользовательский трафик.
Как следует из вышесказанного, тестирование и мониторинг взаимно дополняют друг друга. При этом тестирование проводят при отсутствии работающих пользователей. Мониторинг – наоборот, когда пользователи работают. Но можно действовать и по-другому. Всегда существуют временные интервалы, когда пользователи неактивны. Если такие интервалы определять автоматически и в это время проводить тестирование сети, а результаты тестирования отдавать в систему мониторинга, мы одновременно решим две важные задачи:
- Обеспечим высокую достоверность результатов тестирования. Обычно выводы о качестве сети делают по результатам буквально нескольких измерений, в нашем случае выводы будут делаться на основе десятков тысяч измерений. Это позволит увидеть динамику изменения качества сети, зависимость качества от дней недели, времени суток и т.п.
- Расширим функциональность системы мониторинга. Кроме метрик, характеризующих доступность и здоровья активного сетевого оборудования и серверов, мы получим метрики, характеризующие эффективную пропускную способность сети. Сопоставление здоровья оборудования с пропускной способностью сети упрощает диагностику скрытых дефектов и узких мест сети.
Интеграцию нагрузочного тестирования с системой мониторинга я назвал Нагрузочным Мониторингом Сети.
Нагрузочный Мониторинг Сети (НМС). Как это работает
Таким образом, идея НМС заключается в следующем:
- Автоматически определяются периоды времени, когда сеть не загружена пользовательским трафиком, и в эти периоды автоматически выполняется нагрузочное тестирование сети (измерение эффективную пропускную способность на уровне TCP).
- Пропускная способность сети (throughput), измеряемая при нагрузочном тестировании, добавляется в число метрик, контролируемых системой мониторинга.
НМС может иметь много применений. Но лучше всего он подходит для управления качеством арендуемых каналов связи, например, между ЦОД и удалёнными офисами. Посмотрим, как это работает.
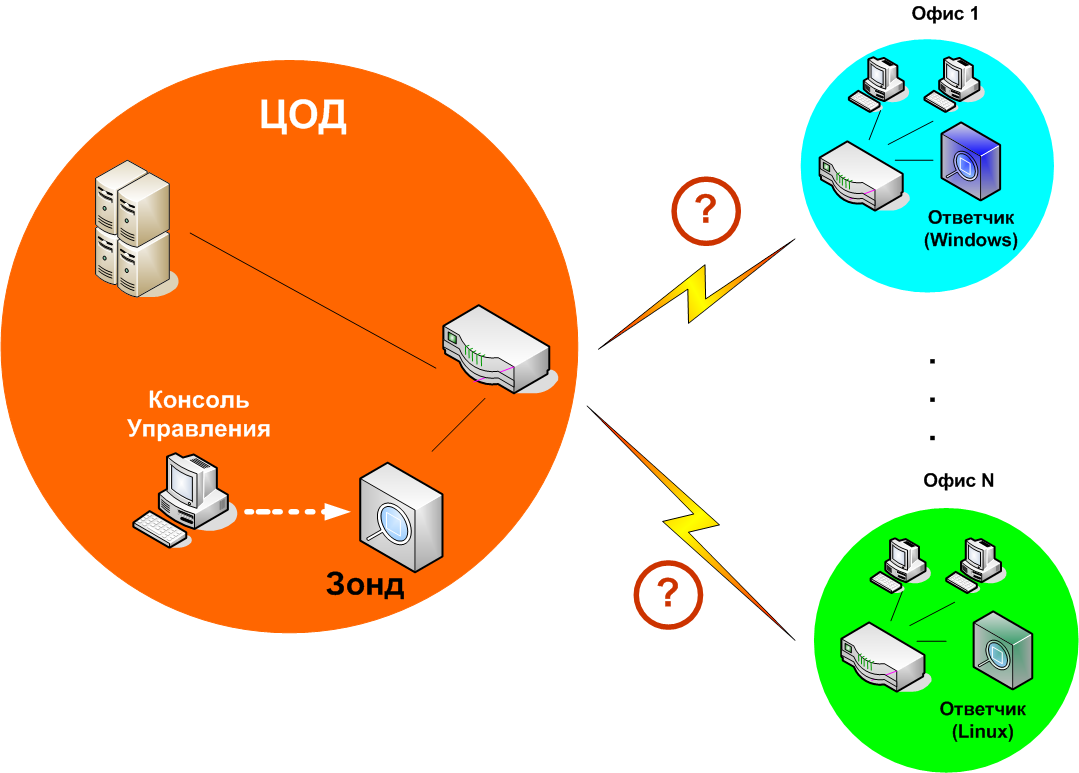
Рисунок 1. Нагрузочный Мониторинг Сети. Архитектура решения.
Для проведения НМС в сети устанавливается система мониторинга, включающая Консоль управления, Зонды и Ответчики. Тестирование сети выполняет специальный Тест, работающий на Зонде. Кроме нагрузочного тестирования, Зонд выполняет мониторинг работы сетевого оборудования (утилизация, ошибки и т.п.), результаты которого передаются на Консоль. На Зонде могут одновременно выполняться множество Тестов. Одни Тесты выполняют мониторинг оборудования. Другие – нагрузочное тестирование сети. С Консоли задаются параметры всех Тестов. Для Тестов, выполняющих нагрузочное тестирование сети, такими параметрами являются:
- Режим генерации трафика:
- Размер блока данных, которыми осуществляется обмен между Зондом и Ответчиками.
- Направление передачи данных:
- Расписание генерации:
- Дополнительные параметры:
В процессе нагрузочного тестирования измеряются следующие метрики:
| № | Характеристика | Описание |
|---|---|---|
| 1 | READ (Mbps, %) | Пропускная способность сети при передаче данных от Ответчика к Зонду. Во всех случаях одновременно измеряется абсолютная и относительная (относительно установленного значения) пропускная способность. |
| 2 | WRITE (Mbps, %) | Пропускная способность сети при передаче данных от Зонда к Ответчику. |
| 3 | RD-WR (Mbps, %) | Пропускная способность сети при встречной передаче данных между Зондом и Ответчиком. |
| 4 | TOTAL (Mbps, %) | Общая пропускная способность сети при одновременной передаче данных между Зондом и несколькими Ответчиками. В зависимости от направления передачи данных может быть: TOTAL READ, TOTAL WRITE, TOTAL RD-WR. |
| 5 | AVERAGE (Mbps, %) | Средняя пропускная способность сети при поочерёдной передаче данных между Зондом и несколькими Ответчиками. В зависимости от направления передачи данных может быть: AVERAGE READ, AVERAGE WRITE, AVERAGE RD-WR. |
| 6 | Responder Availability (%) | Доступность Ответчиков по UDP. Проверка доступности Ответчиков может быть отключена. |
| 7 | TCP Link Availability (%) | Доступность TCP-канала. TCP-канал считается недоступным, когда при доступности Ответчика UDP с ним невозможно установить связь по TCP и во время передачи данных происходит разрыв связи между Ответчиком и Зондом. |
Чтобы тестирование сети проводилось только в то время, когда в сети не работают внутренние пользователи, на Зонде устанавливается программа Регулировщик. Её назначение – постоянно следить, можно или нельзя в данный момент проводить нагрузочное тестирование (выполнять генерацию трафика). Тест начнёт выполнять генерацию трафика только в том случае, если Регулировщик скажет «Можно». Если в процессе генерации Регулировщик скажет «Нельзя», генерация сразу прекращается. Регулировщик использует в своей работе стандартную функциональность системы сетевого мониторинга. В простейшем случае – результаты мониторинга по SNMP загруженности портов каналообразующего оборудования.
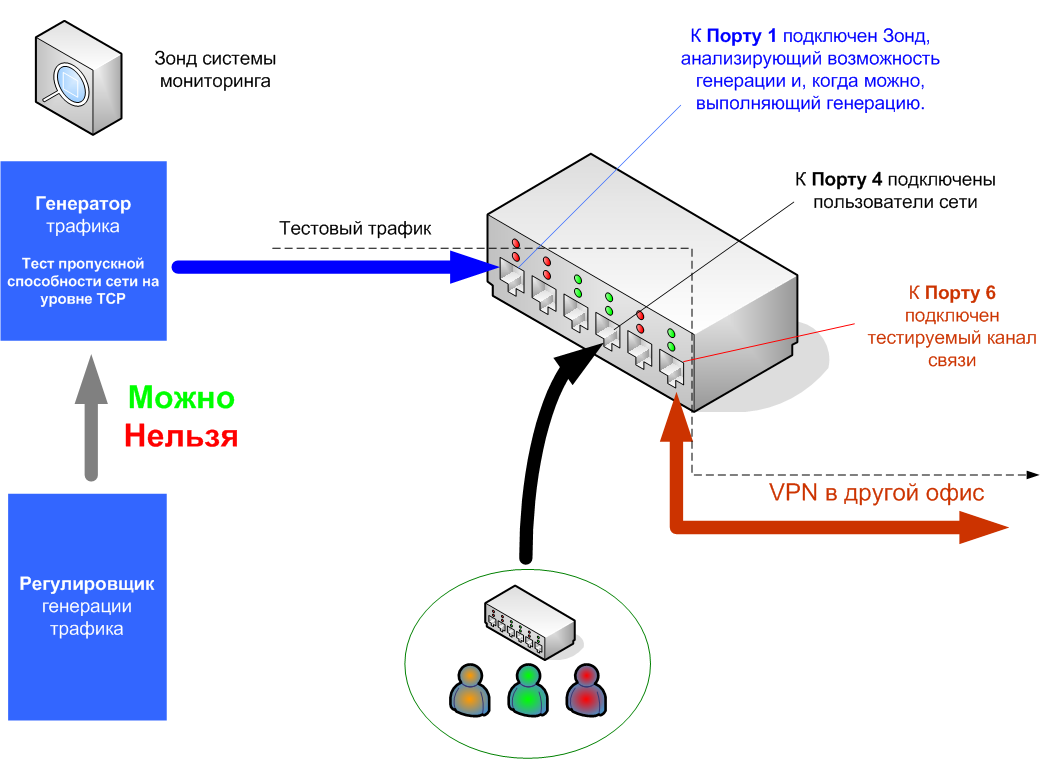
Рисунок 2. Управляемая Генерация Трафика
Предположим, тестируется канал связи, подключённый к 6-му порту маршрутизатора; см. Рис. 2. При этом Зонд подключён к 1-му порту, а пользователи – к 4-му порту. Предположим, Тест должен с 9:00 до 20:00 каждый час передавать 10 Мбайт данных от Ответчика к Зонду.
Тест постоянно следит за сигналом Регулировщика и начнёт генерацию трафика только в том случае, если Регулировщик говорит «Можно». А это произойдёт только в том случае, если утилизация порта 4 будет меньше определённого значения, например, 3%. Если в то время, когда должна начаться генерация трафика, Регулировщик говорит «Нельзя», Тест будет ждать определённое время. Если в течение этого времени он так и не дождётся сигнала «Можно» (снижения утилизации до 3%), то генерация трафика будет отложена до следующего часа. Начав генерацию трафика, Тест продолжает контролировать сигнал Регулировщика, и если он увидит сигнал «Нельзя» (утилизацию порта 4 выше 3%), то сразу прекращает генерацию, фиксирует конфликт и аннулирует результаты данного измерения.
Регулировщик работает в фоне и, таким образом, всегда знает, можно или нельзя в данный момент времени выполнять генерацию трафика (даже если его об этом не спрашивают). Условия выдачи сигналов «Можно» и «Нельзя» могут быть различными (не только утилизация портов). Это может быть, например, число активных подключений к базе данных или число активных пользователей какого-то бизнес-приложения. При работе Теста Регулировщик может быть включён или выключен.
Два применения Нагрузочного Мониторинга Сети
В зависимости от того, включён или выключен Регулировщик, НМС позволяет решить две различные задачи:
- Управление качеством сети, если Регулировщик выключен.
- Аудит качества получаемых услуг, если Регулировщик включён.
Обе задачи могут решаться одновременно, т.к. Зондов может быть несколько и на каждом Зонде может одновременно выполняться несколько Тестов. В одних Тестах Регулировщик может быть включён, в других – выключен.
Регулировщик включён: Аудит качества получаемых услуг
Если Регулировщик включён, то НМС – это инструмент аудита качеством получаемых услуг. Пропускная способность сети, измеренная в то время, когда пользователи не работали, однозначно характеризует качество работы опорной сети провайдера.
Зная номинальную пропускную способность каналов на физическом уровне, и сравнив её с измеренной пропускной способностью на уровне TCP, вы легко опередите, какие каналы работают хорошо, а какие – плохо. Если тестируются каналы Ethernet, то их пропускная способность на уровне TCP не должна более чем на 10%–12% быть ниже их физической скорости. На Рисунке 3 показан пример отчёта в формате MS Excel, из которого сразу видно, что канал Москва-Пермь работает хуже других.
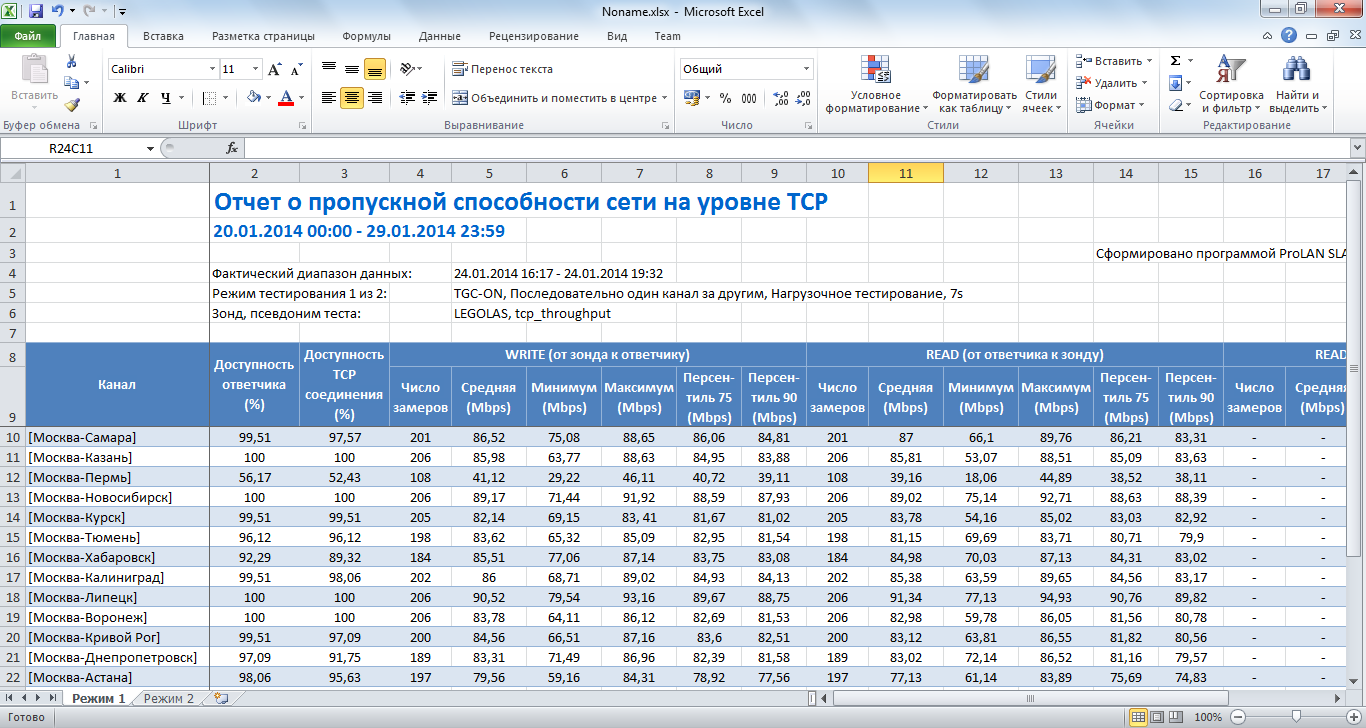
Рисунок 3. Отчёт о пропускной способности каналов связи (создаётся автоматически)
У такого решения есть ещё одно важное преимущество. Оно существенно повышает эффективность диагностики сетевых сбоев, выполняемой другими методами, например, network sniffing. Чтобы быстро определить причину сбоя, нужно видеть, как есть, и знать, как должно быть. Когда вы анализируете сетевой сбой, который возник в период прохождения пользовательского трафика, вы видите как есть, но не всегда знаете, как должно быть. Когда же вы анализируете сбой, произошедший в то время, когда в сети был только тестовый трафик, вы не только видите как есть, но и всегда знаете, как должно быть. Это существенно упрощает процесс диагностики.
Регулировщик выключен: Управление качеством сети
Если Регулировщик выключен, то НМС – это система управления качеством работы сети. Показателем качества работы сети является метрика «Пропускная способность сети на уровне ТСР». Другие метрики (утилизация, число ошибок и т.п.) получают статус дополнительных. Если пропускная способность ухудшится, они помогут определить, с чем это может быть связано. К достоинствам такого решения можно отнести, в первую очередь, простоту управления качеством сети, оборудование которой не поддерживает IP SLA. Если в сети произойдёт сбой, пропускная способность сети неминуемо снизится, и вы узнаете о сбое до того, как пользователи начнут обращаться в Service Desk, и сможете быстро определить причину (если она носит локальный характер).
На приведённом ниже рисунке показан снимок экрана консоли оперативного мониторинга сети. Верхняя диаграмма – оценка пропускной способности сети. Три нижние диаграммы – оценки качества работы оборудования, которое может влиять на пропускную способность сети. Все четыре оценки привязаны к единой временной шкале.
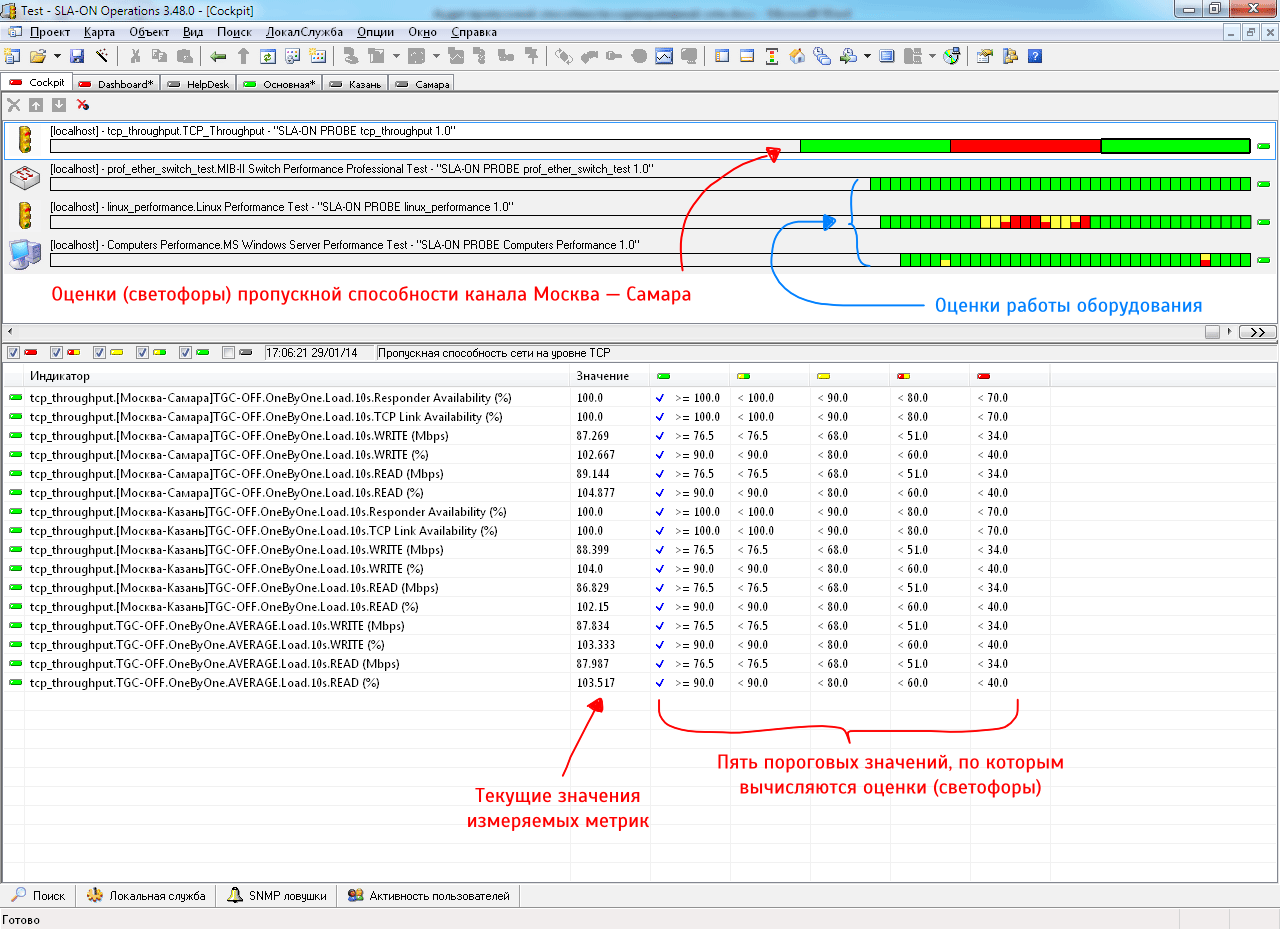
Рисунок 4. Скриншот оперативного мониторинга качества работы канала связи.
В этом случае, чтобы не создавать большой трафик и не мешать работе пользователей, Тест нужно настроить на периодическую (например, каждые 15 мин.) передачу массива данных небольшого размера, например, 2 МВ. Для этого в параметрах Теста следует установить режим «Мониторинг сети».
Заключение
Сегодня много говорят о Service Level Management, но экономичного и эффективного инструментария, с помощью которого можно было бы на постоянной основе оценивать качество работы, например, арендуемых каналов связи, пока не много. Нагрузочный Мониторинг Сети является примером такого инструментария. Надо признать, что полученные с его помощью результаты при разрешении юридических споров правовой силы иметь не будут. Но использовать пропускную способность на уровне TCP в качестве метрики (наряду с доступностью), прописываемой в SLA, было бы правильно.
