
Введение
В прошлой статье («Часть 2: Использование блоков UDB контроллеров PSoC фирмы Cypress для уменьшения числа прерываний в 3D-принтере») я отметил один очень интересный факт: если автомат в UDB изымал данные из FIFO слишком быстро, он успевал заметить состояние, что новых данных в FIFO нет, после чего переходил в ложное состояние Idle. Разумеется, меня заинтересовал этот факт. Вскрывшиеся результаты я показал группе знакомых. Один человек ответил, что это всё вполне очевидно, и даже назвал причины. Остальные были удивлены не менее, чем я в начале исследований. Так что некоторые специалисты не найдут здесь ничего нового, но неплохо бы донести эту информацию до широкой общественности, чтобы её имели в виду все программисты для микроконтроллеров.
Не то чтобы это был срыв каких-то покровов. Оказалось, что всё это отлично задокументировано, но беда в том, что не в основных, а в дополнительных документах. И лично я пребывал в счастливом неведении, считая, что DMA — это очень шустрая подсистема, которая позволяет резко повысить эффективность программ, так как там идёт планомерная перекачка данных без отвлечения на те же команды инкремента регистров и организации цикла. Насчёт повышения эффективности – всё верно, но за счёт чуть иных вещей.
Но обо всём по порядку.
Эксперименты с Cypress PSoC
Сделаем простейший автомат. У него будет условно два состояния: состояние покоя и состояние, в которое он будет попадать, когда в FIFO имеется хотя бы один байт данных. Войдя в такое состояние, он просто изымет эти данные, после чего снова провалится в состояние покоя. Слово «условно» я привёл не случайно. У нас два FIFO, поэтому я сделаю два таких состояния, по одному на каждое FIFO, чтобы убедиться в том, что они полностью идентичны по поведению. Граф переходов у автомата получился таким:
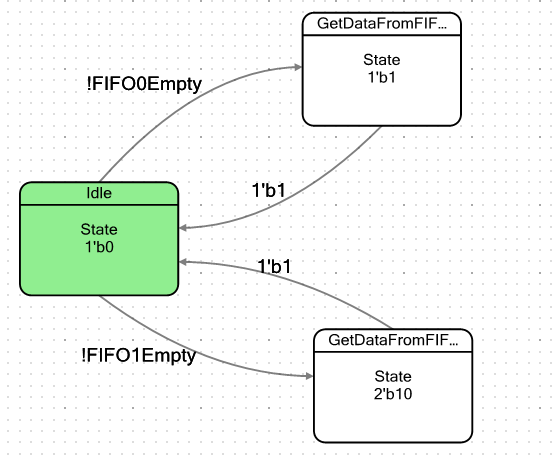
Флаги для выхода из состояния Idle определяем так:
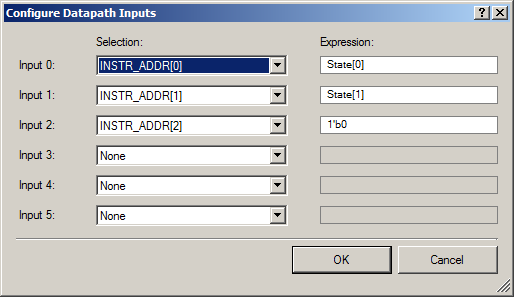
Не забываем на входы Datapath подать биты номера состояния:
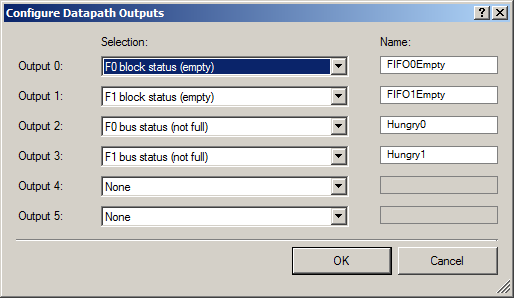
Наружу мы выводим две группы сигналов: пару сигналов, что в FIFO имеется свободное место (для того чтобы DMA могли начать закачивать в них данные), и пару сигналов, что FIFO пусты (чтобы отображать этот факт на осциллографе).
АЛУ будет просто фиктивно забирать данные из FIFO:
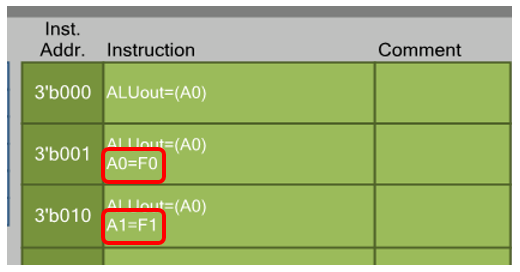
Давайте я покажу детализацию для состояния «0001»:
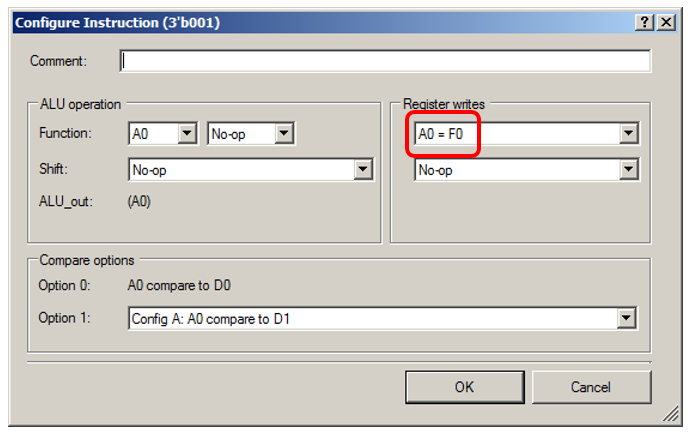
Ещё я поставил разрядность шины, какая была в проекте, на котором я заметил данный эффект, 16 бит:

Переходим к схеме самого проекта. Наружу я выдаю не только сигналы о том, что FIFO опустошилось, но и тактовые импульсы. Это позволит мне обойтись без курсорных измерений на осциллографе. Я могу просто считать такты пальцем.
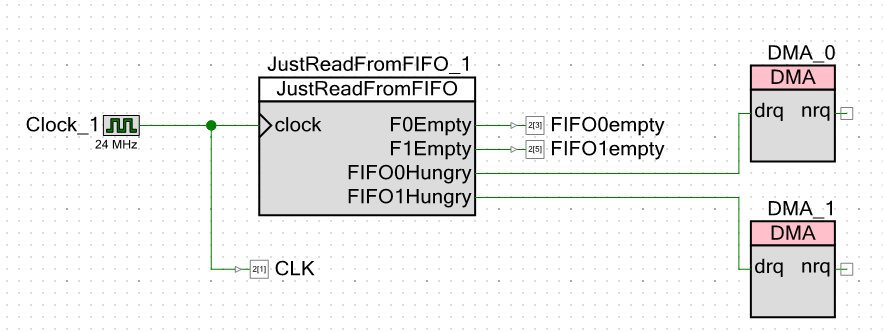
Как видно, тактовую частоту я сделал 24 мегагерца. У процессорного ядра частота точно такая же. Чем ниже частота, тем меньше помех на китайском осциллографе (официально у него полоса 250 МГц, но то китайские мегагерцы), а замеры все будут вестись относительно тактовых импульсов. Какая бы частота ни была, система всё равно отработает относительно них. Я бы и один мегагерц поставил, но среда разработки запретила мне вводить значение частоты процессорного ядра менее, чем 24 МГц.
Теперь тестовые вещи. Для записи в FIFO0 я сделал такую функцию:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // Инициализировали DMA прямо здесь, так как массив живёт здесь uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // Так как мы всё делаем для опытов, выделили дескриптор для задачи тоже здесь uint8 td = CyDmaTdAllocate(); // Задали параметры дескриптора и длину в байтах. Также сказали, что следующего дескриптора нет. CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // Теперь задали начальные адреса для дескриптора CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // Подключили этот дескриптор к каналу CyDmaChSetInitialTd(channel, td); // Запустили процесс с возвратом дескриптора к исходному виду CyDmaChEnable(channel, 1); }
Слово ROM в имени функции связано с тем, что отправляемый массив хранится в области ПЗУ, а Cortex M3 имеет Гарвардскую архитектуру. Скорость доступа к шине ОЗУ и шине ПЗУ может различаться, хотелось это проверить, поэтому меня есть аналогичная функция для отправки массива из ОЗУ (у массива steps в её теле отсутствует модификатор static const). Ну, и есть такая же пара функций для посылки в FIFO1, там отличается регистр приёмника: не F0, а F1. В остальном все функции идентичны. Так как особой разницы в результатах я не заметил, рассматривать буду результаты вызова именно приведённой выше функции. Жёлтый луч — тактовые импульсы, голубой — выход FIFO0empty.
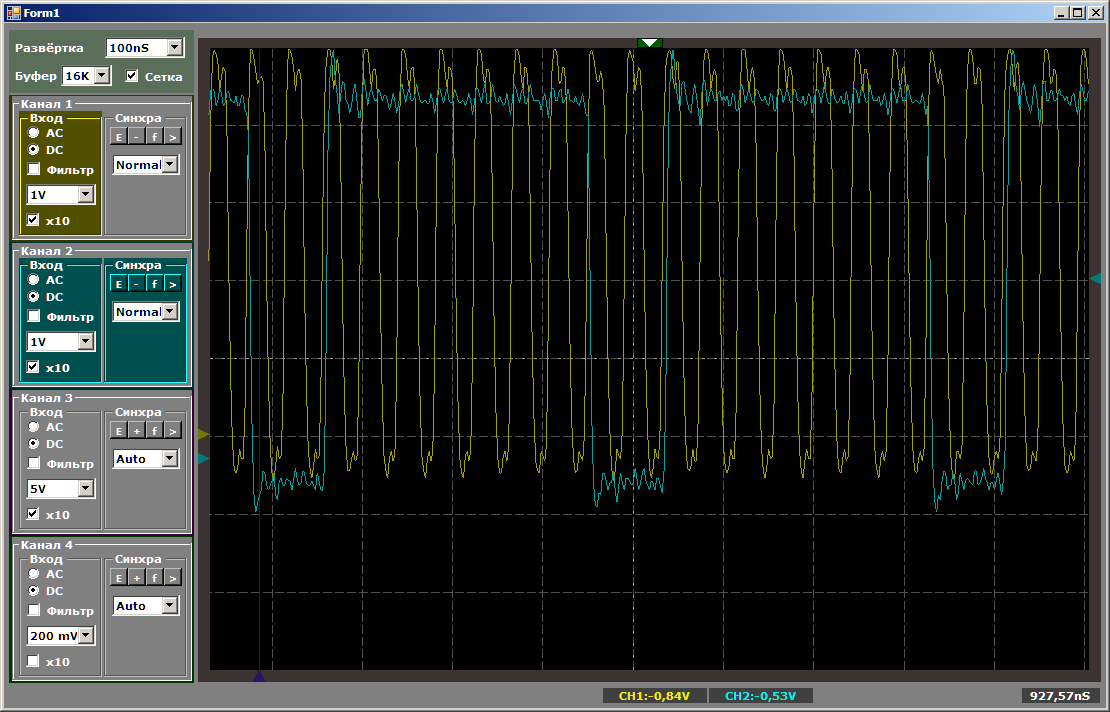
Сначала проверим правдоподобность, почему FIFO заполнено на протяжении двух тактов. Посмотрим этот участок поподробнее:

По фронту 1 данные попадают в FIFO, флаг FIFO0enmpty падает. По фронту 2 автомат переходит в состояние GetDataFromFifo1. По фронту 3 в этом состоянии происходит копирование данных из FIFO в регистр АЛУ, FIFO опустошается, флаг FIFO0empty вновь взводится. То есть осциллограмма ведёт себя правдоподобно, можно считать на ней такты на цикл. Получаем 9 штук.
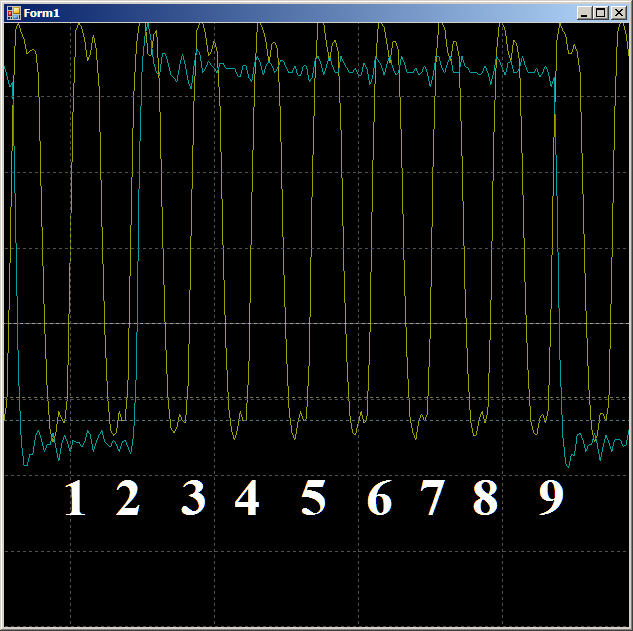
Итого, на осмотренном участке, на копирование одного слова данных из ОЗУ в UDB силами DMA требуется 9 тактов.
А теперь то же самое, но силами процессорного ядра. Сначала — идеальный код, слабо достижимый в реальной жизни:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
что превратится в ассемблерный код:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] b.n 8e <main+0xa> .word 0x40006898
Никаких разрывов, никаких лишних тактов. Две пары тактов подряд…
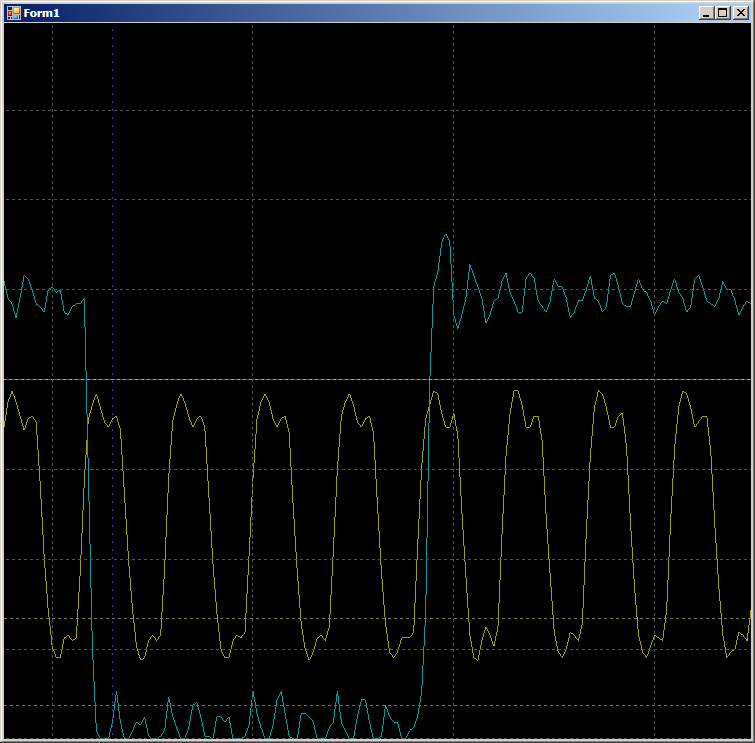
Сделаем код чуть более реальным (с накладными расходами на организацию цикла выборку данных и инкремент указателей):
void SoftWriteTo0FromROM() { // В этом тесте просто шлём массив из двадцати шагов. // Хитрый алгоритм с упаковкой будем проверять чуть позже static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
полученный ассемблерный код:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
На осциллограмме видим всего 7 тактов на цикл против девяти в случае DMA:
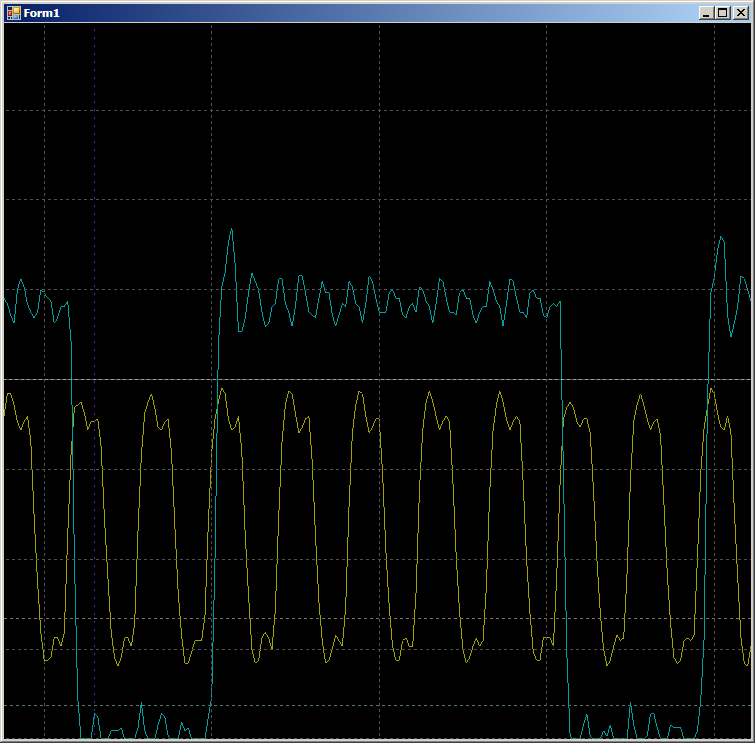
Немного о мифе
Если честно, для меня первоначально это было шоком. Я как-то привык считать, что механизм DMA позволяет быстро и эффективно переносить данные. 1/9 от частоты шины — это не то, чтобы очень быстро. Но оказалось, что никто этого и не скрывает. В документе TRM для PSoC 5LP даже имеется ряд теоретических выкладок, а документ «AN84810 — PSoC 3 and PSoC 5LP Advanced DMA Topics» детально расписывает процесс обращения к DMA. Виной всему латентность. Цикл обмена с шиной занимает некоторое количество тактов. Собственно, именно эти такты и играют решающую роль в возникновении задержки. В общем, никто ничего не скрывает, но это надо знать.
Если знаменитый GPIF, используемый в FX2LP (другой архитектуре, выпускаемой фирмой Cypress), скорость ничем не ограничивает, то здесь ограничение скорости обусловлено латентностями, возникающими при обращениях к шине.
Проверка DMA на STM32
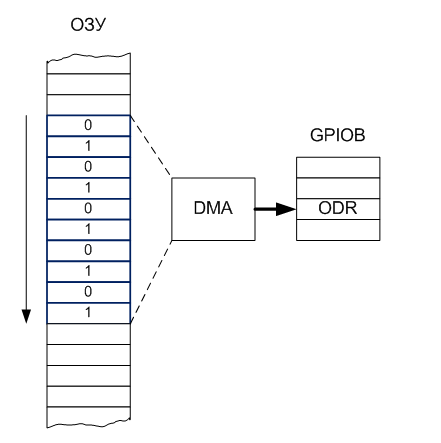
Я был под таким впечатлением, что решил провести эксперимент на STM32. В качестве подопытного кролика был взят STM32F103, имеющий такое же процессорное ядро Cortex M3. У него нет UDB, из которого можно было бы вывести служебные сигналы, но проверить DMA вполне можно. Что такое GPIO? Это набор регистров в общем адресном пространстве. Вот и прекрасно. Настроим DMA в режим копирования «память-память», указав в качестве источника реальную память (ПЗУ или ОЗУ), а в качестве приёмника — регистр данных GPIO без инкремента адреса. Будем слать туда поочерёдно то 0, то 1, а результат фиксировать осциллографом. Для начала я выбрал порт B, к нему было проще подключиться на макетке.
Мне очень понравилось считать такты пальцем, а не курсорами. Можно ли сделать так же на данном контроллере? Вполне! Опорную тактовую частоту для осциллографа возьмём с ножки MCO, которая у STM32F10C8T6 связана с портом PA8. Выбор источников для этого дешёвого кристалла не велик (тот же STM32F103, но посолиднее, даёт гораздо больше вариантов), подадим на этот выход сигнал SYSCLK. Так как частота на MCO не может быть выше 50 МГц, уменьшим общую тактовую частоту системы до 48 МГц. Будем умножать частоту кварца 8 МГц не на 9, а на 6 (так как 6 * 8 = 48):
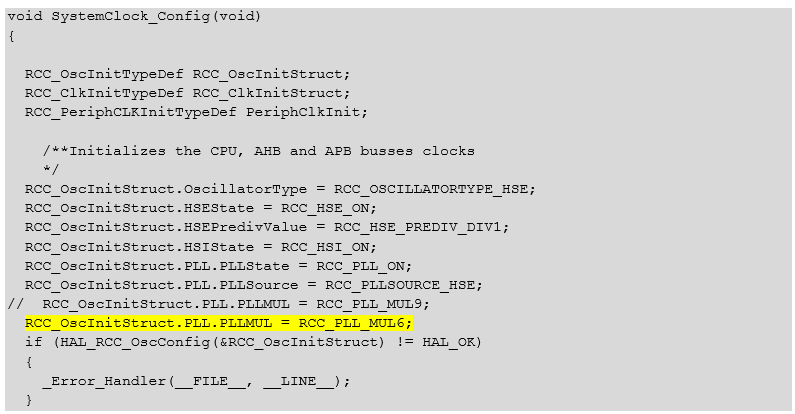
То же самое текстом:
void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
MCO запрограммируем средствами библиотеки mcucpp Константина Чижова (дальше я все обращения к аппаратуре буду вести через эту замечательную библиотеку):
// Настраиваем MCO Mcucpp::Clock::McoBitField::Set (0x4); // Подключаем ногу MCO к альтернативному порту Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Программируем скорость выходного каскада Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Ну, и теперь задаём вывод массива данных в GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // Запускаем GPIOB и настраиваем биты на выход dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // Передёргиваем голубой луч dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // Всё, настроили и запустили DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
Полученная осциллограмма очень похожа на ту, что была на PSoC.
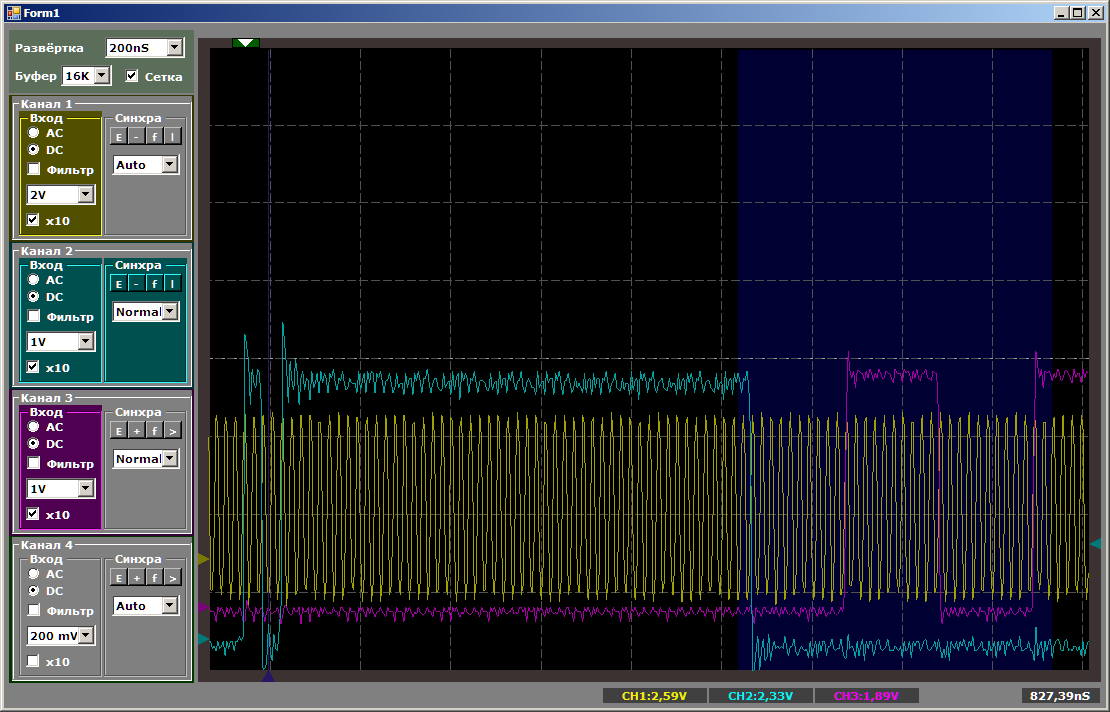
В середине большой голубой горб. Это идёт процесс инициализации DMA. Голубые импульсы слева получены чисто программным путём на PB1. Растянем их пошире:
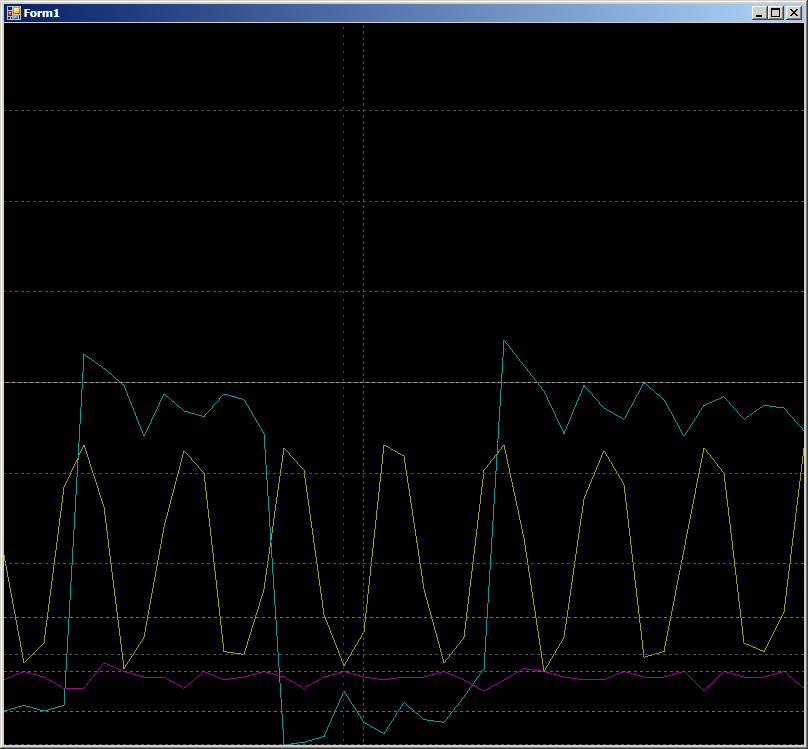
2 такта на импульс. Работа системы соответствует ожидаемой. Но теперь посмотрим покрупнее область, отмеченную на основной осциллограмме тёмно-синим фоном. В этом месте уже работает блок DMA.
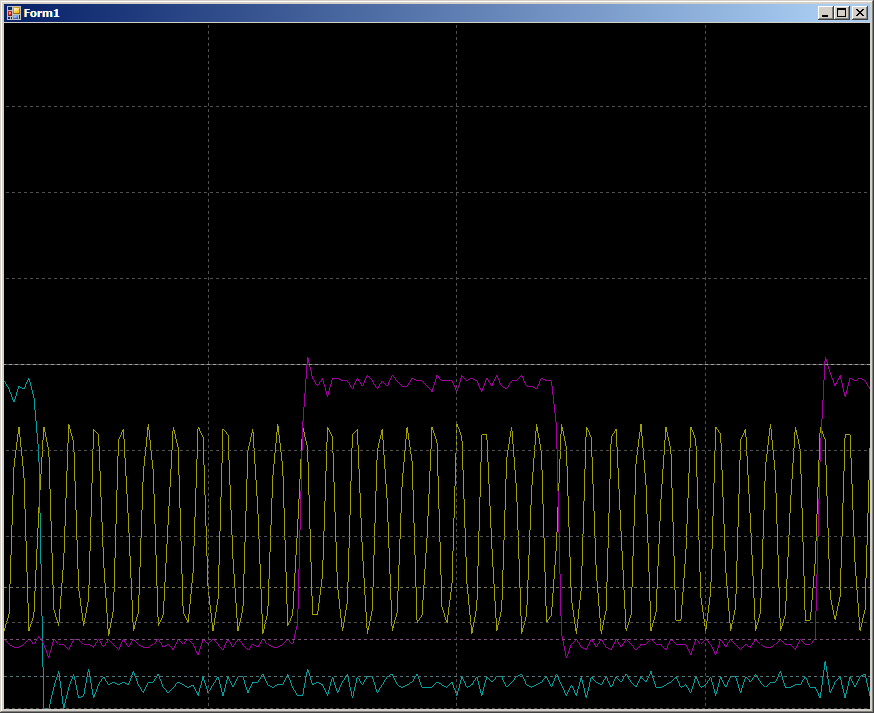
10 тактов на одно изменение линии GPIO. Вообще-то, работа идёт с ОЗУ, а программа зациклена в постоянном цикле. Обращений к ОЗУ от процессорного ядра нет. Шина полностью в распоряжении блока DMA, но 10 тактов. Но на самом деле, результаты не сильно отличаются от увиденных на PSoC, поэтому просто начинаем искать Application Notes, относящийся к DMA на STM32. Их оказалось несколько. Есть AN2548 на F0/F1, есть AN3117 на L0/L1/L3, есть AN4031 на F2/F4/F77. Возможно, есть ещё какие-то…
Но, тем не менее, из них мы видим, что и здесь во всём виновата латентность. Причём у F103 пакетные обращения к шине у DMA невозможны. Они возможны для F4, но не более, чем для четырёх слов. Дальше снова возникнет проблема латентности.
Попробуем выполнить те же действия, но при помощи программной записи. Выше мы видели, что прямая запись в порты идёт моментально. Но там была скорее идеальная запись. Строки:
// Передёргиваем голубой луч dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
при условии таких настроек оптимизации (обязательно следует указать оптимизацию для времени):
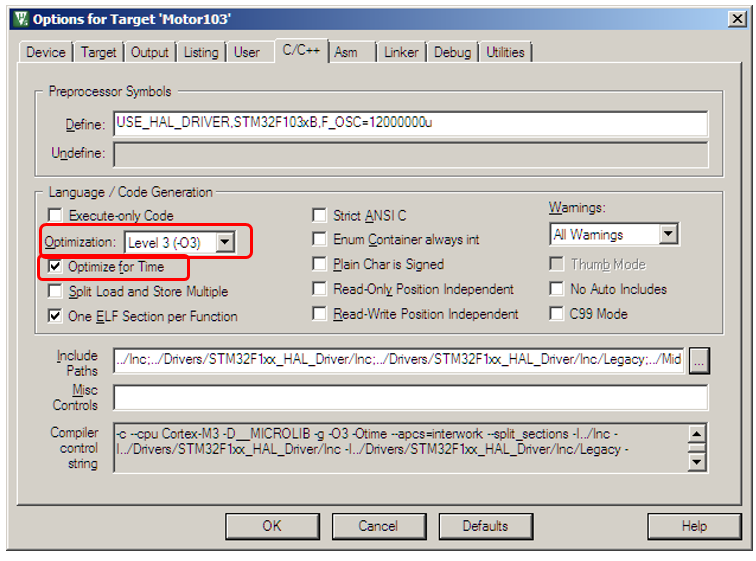
превратились в следующий ассемблерный код:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
В реальном копировании будет обращение к источнику, к приёмнику, изменение переменной цикла, ветвление… В общем, масса накладных расходов (от которых, как считается, как раз и избавляет DMA). Какая будет скорость изменений в порту? Итак, пишем:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Этот код на C++ превращается в такой ассемблерный код:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
И получаем:
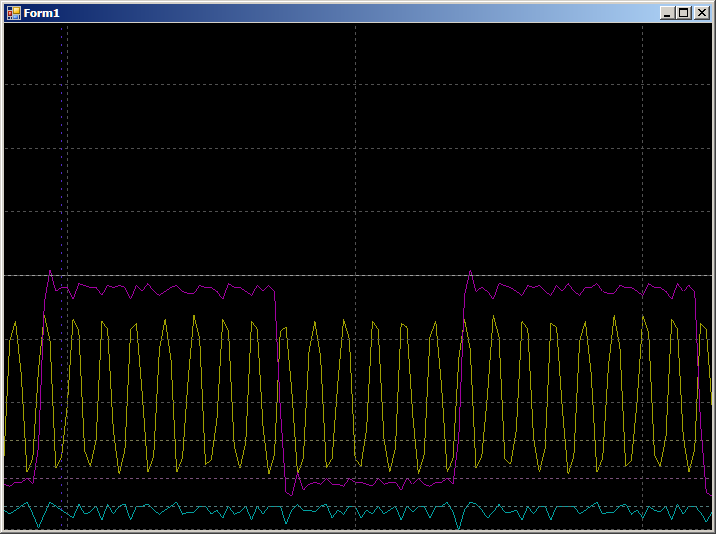
8 тактов в верхнем полупериоде и 6 — в нижнем (я проверил, результат повторяется для всех полупериодов). Разница возникла потому, что оптимизатор сделал 2 копирования на каждую итерацию. Поэтому 2 такта в одном из полупериодов добавляются на операцию ветвления.
Грубо говоря, при программном копировании тратится 14 тактов на копирование двух слов против 20 тактов на то же самое, но силами DMA. Результат вполне документированный, но весьма неожиданный для тех, кто ещё не читал расширенную литературу.
Хорошо. А что будет, если начать писать данные сразу в два потока DMA? Насколько упадёт скорость? Подключим голубой луч к PA0 и перепишем программу следующим образом:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // Всё, настроили и запустили DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Сначала осмотрим характер импульсов:
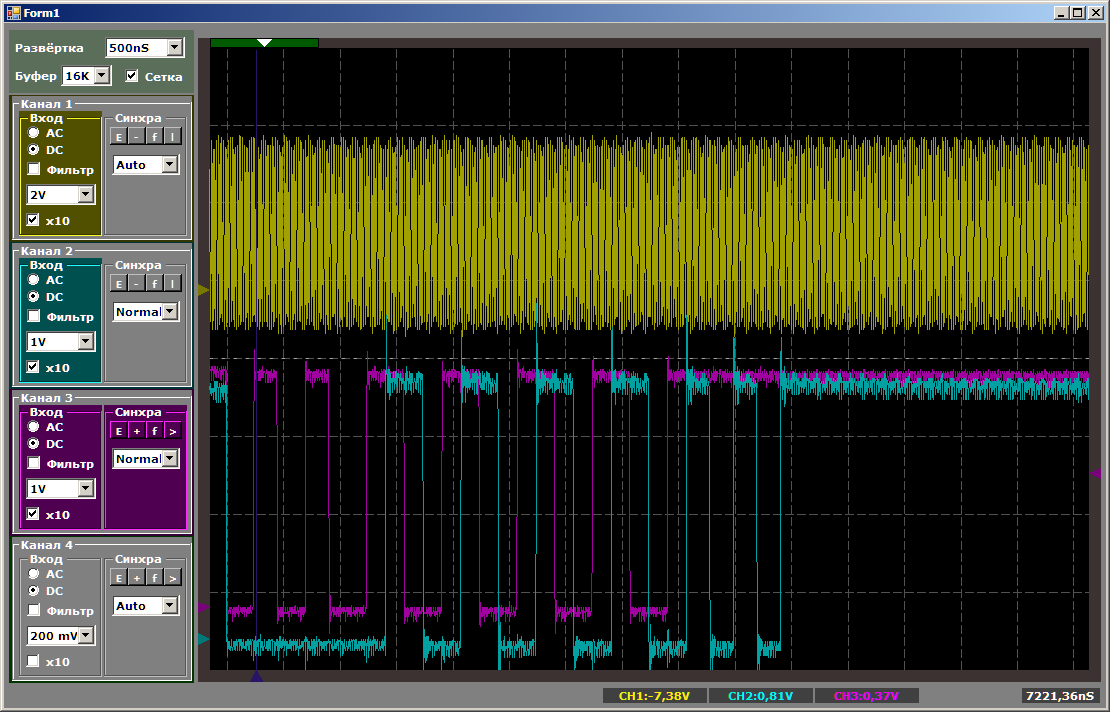
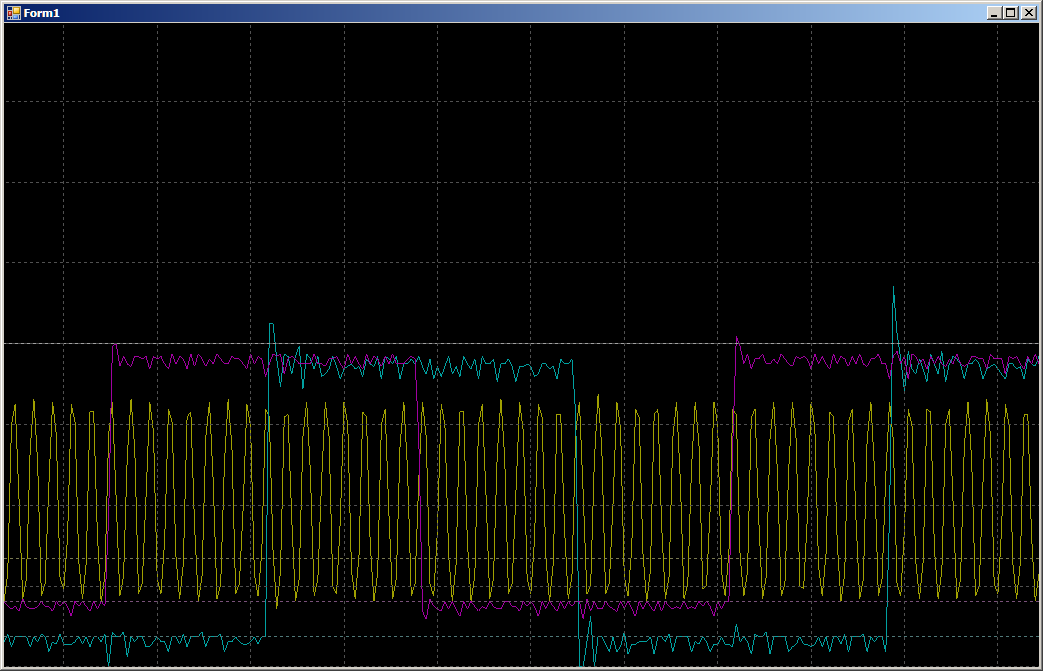
Пока идёт настройка второго канала, скорость копирования для первого выше. Затем, когда идёт копирование в паре, скорость падает. Когда первый канал закончил работу, второй начинает работать быстрее. Всё логично, осталось только выяснить, насколько именно падает скорость.
Пока канал один, запись занимает от 10 до 12 тактов (цифры плавают).
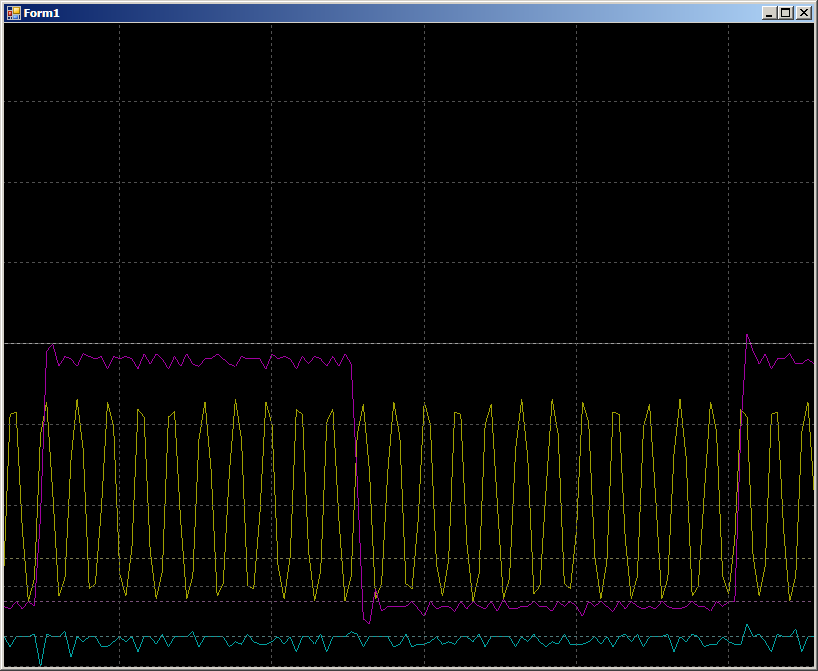
Во время совместной работы получаем 16 тактов на одну запись в каждый порт:
То есть, скорость падает не вдвое. А что если начать писать сразу в три потока? Добавляем работу с PC15, так как PC0 не выведен (именно поэтому в массиве выдаётся не 0, 1, 0, 1..., а 0x0000,0x8001, 0x0000, 0x8001...).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // Всё, настроили и запустили DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Здесь результат настолько неожиданный, что я отключу луч, отображающий тактовую частоту. Нам не до измерений. Смотрим на логику работы.
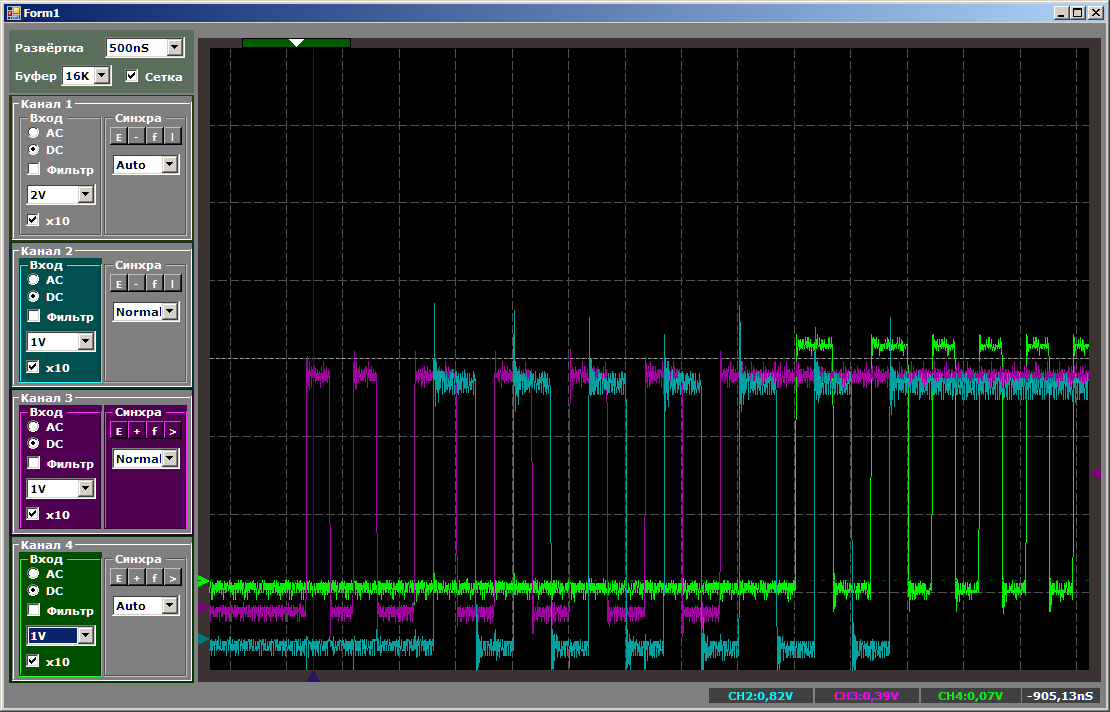
Пока не закончил работу первый канал, третий не начал работы. Три канала одновременно не работают! Что-то на эту тему можно вывести из AppNote на DMA, там говорится, что у F103 всего две Engine в одном блоке (а мы копирует средствами одного блока DMA, второй сейчас простаивает, и объём статьи уже такой, что его я в ход пускать не стану). Перепишем на пробу программу так, чтобы третий канал запустился раньше всех:
То же самое текстом:
// Всё, настроили и запустили DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Картинка изменится следующим образом:
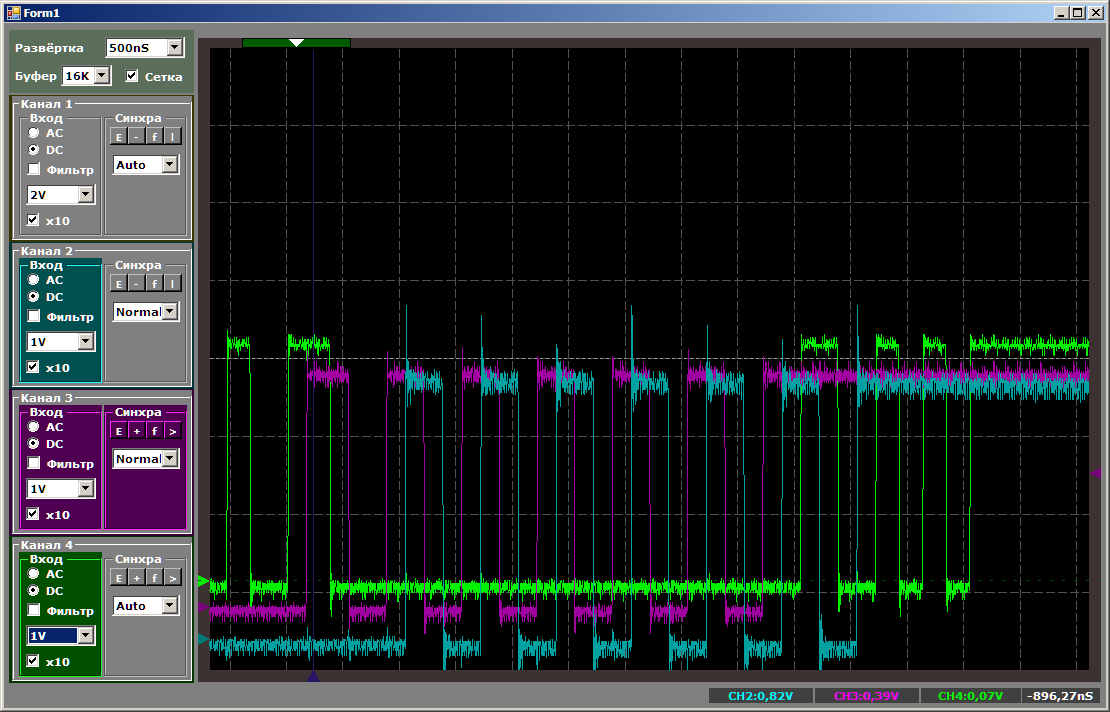
Третий канал запустился, он даже работал вместе с первым, но как в дело вступил второй, третьего вытеснили до тех пор, пока не закончил работу первый канал.
Немного о приоритетах
Собственно, предыдущая картинка связана с приоритетами DMA, есть и такие. Если у всех работающих каналов указан один и тот же приоритет, в дело вступают их номера. В пределах одного заданного приоритета, у кого номер меньше, тот и приоритетней. Попробуем третьему каналу указать иной глобальный приоритет, возвысив его над всеми остальными (попутно повысим приоритет и второму каналу):

То же самое текстом:
channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Теперь ущемлённым станет первый, который раньше был самым крутым.
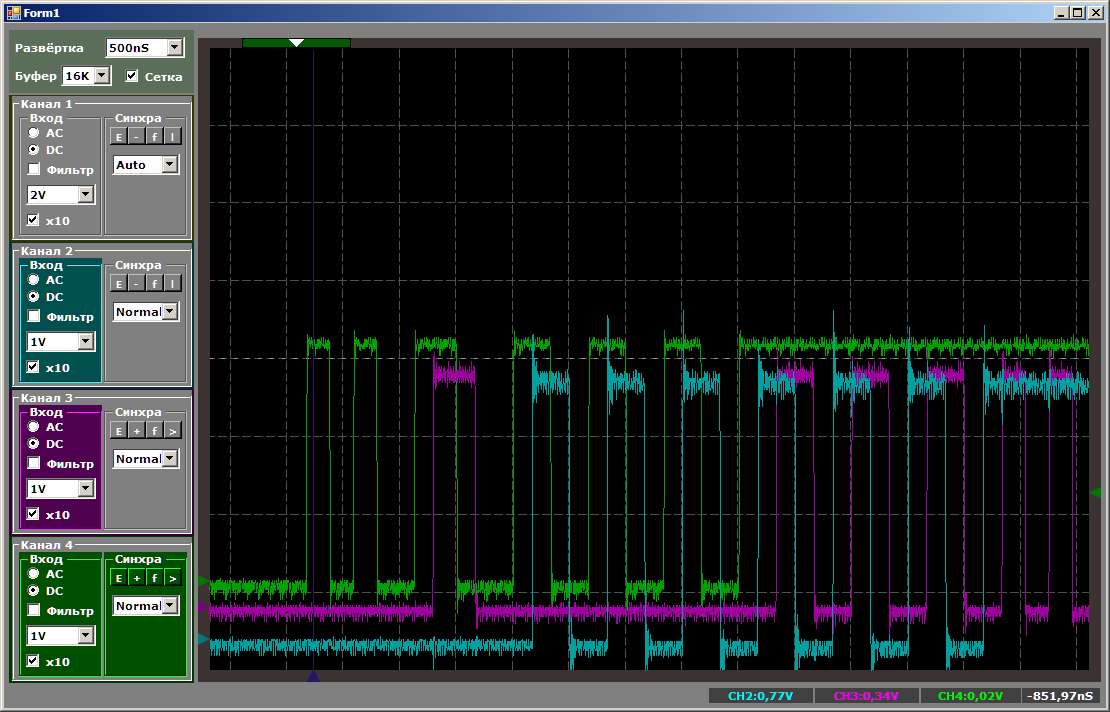
Итого, мы видим, что даже играя в приоритеты, больше двух потоков на одном блоке DMA у STM32F103 запустить не получится. В принципе, третий поток можно запустить на процессорном ядре. Это нам позволит сравнить производительность.
// Всё, настроили и запустили DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
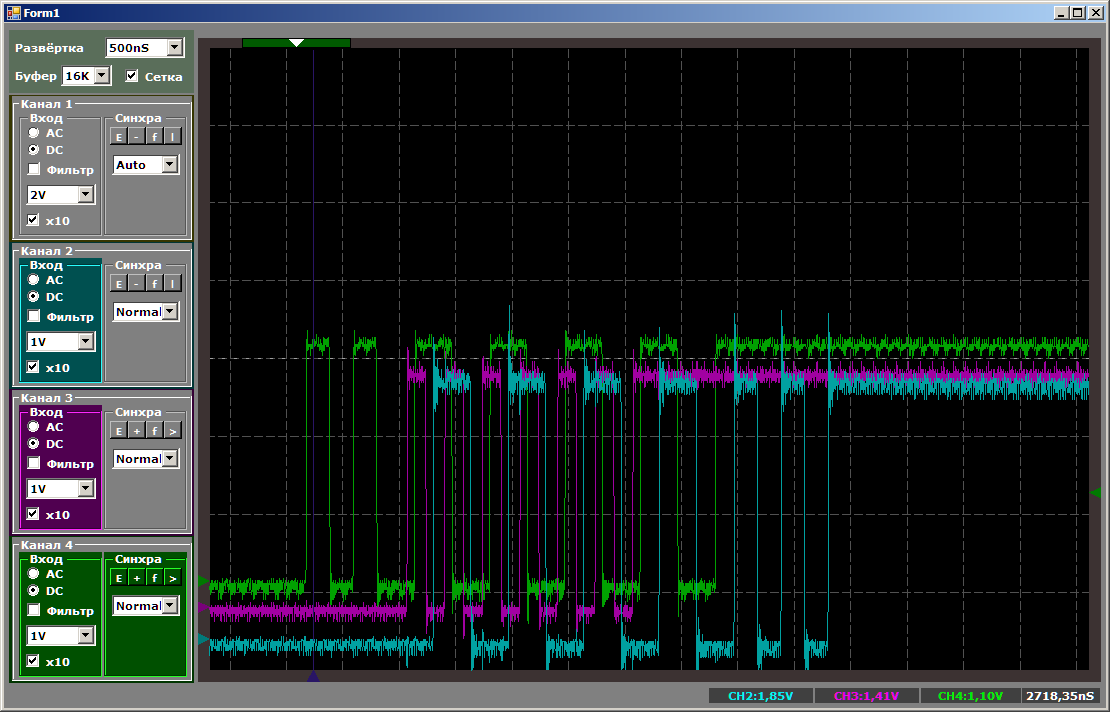
Сначала общая картинка, на которой видно, что всё работает в параллель и у процессорного ядра скорость копирования выше всех:
А теперь я дам возможность всем желающим посчитать такты в то время, когда все потоки копирования активны:
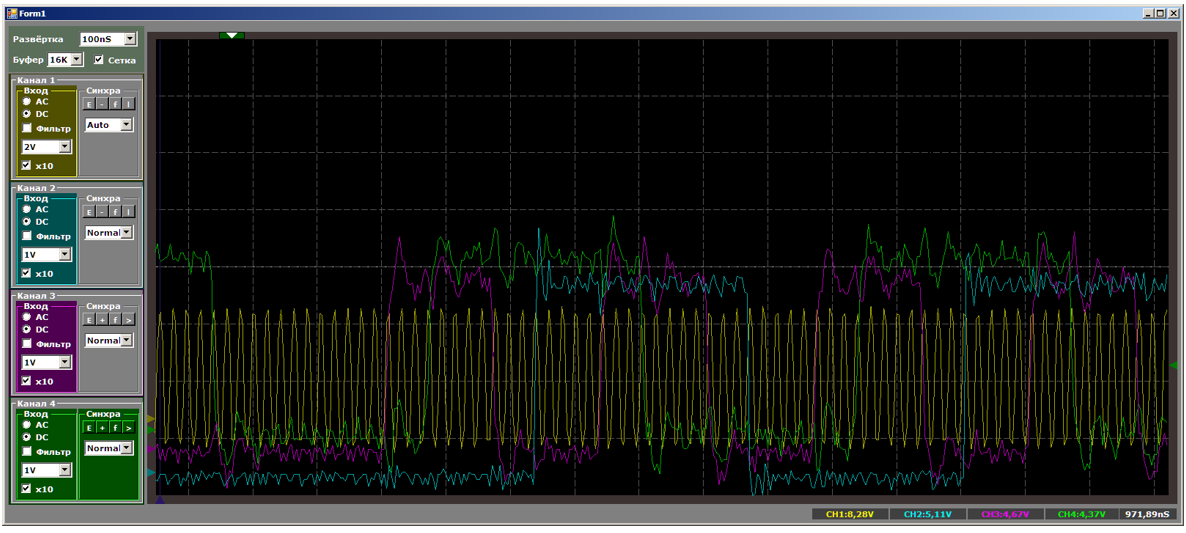
Процессорное ядро приоритетней всех
Теперь вернёмся к тому факту, что при двухпоточной работе, пока настраивался второй канал, первый выдавал данные за различное число тактов. Этот факт также хорошо документирован в AppNote на DMA. Дело в том, что во время настройки второго канала, периодически шли запросы к ОЗУ, а процессорное ядро имеет при обращении к ОЗУ больший приоритет, чем ядро DMA. Когда процессор запрашивал какие-то данные, у DMA отнимались такты, оно получало данные с задержкой, поэтому производило копирование медленней. Давайте сделаем последний на сегодня эксперимент. Приблизим работу к более реальной. После запуска DMA будем не уходить в пустой цикл (когда обращений к ОЗУ точно нет), а выполнять операцию копирования из ОЗУ в ОЗУ, но эта операция не будет относиться к работе DMA ядер:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

Местами цикл растянулся с 16 до 17 тактов. Я боялся, что будет хуже.
Начинаем делать выводы
Собственно, переходим к тому, что я вообще хотел сказать.
Начну издалека. Несколько лет назад, начиная изучать STM32, я изучал существовавшие на тот момент версии MiddleWare для USB и недоумевал, зачем разработчики убрали прокачку данных через DMA. Видно было, что исходно такой вариант имелся на виду, затем был убран на задворки, а под конец остались только рудименты от него. Теперь я начинаю подозревать, что понимаю разработчиков.
В первой статье про UDB я говорил, что хоть UDB и может работать с параллельными данными, заменить собой GPIF он вряд ли сможет, так как у PSoC шина USB работает на скорости Full Speed против High Speed у FX2LP. Оказывается, есть более серьёзный ограничивающий фактор. DMA просто не успеет доставлять данные с той же скоростью, с какой доставляет их GPIF даже в пределах контроллера, не принимая во внимание шину USB.
Как видим, нет единой сущности DMA. Во-первых, каждый производитель делает его по-своему. Мало того, даже один производитель для разных семейств может варьировать подход к построению DMA. Если планируется серьёзная нагрузка на этот блок, следует внимательно проанализировать, будут ли удовлетворены потребности.
Наверное, надо разбавить пессимистический поток одной оптимистической репликой. Я даже выделю ее.
DMA у контроллеров Cortex M позволяют повысить производительность системы по принципу знаменитых Джавелинов: «Запустил и забыл». Да, программное копирование данных идёт чуть быстрее. Но если надо копировать несколько потоков, никакой оптимизатор не сможет сделать так, чтобы процессор всех их гнал без накладных расходов на перезагрузку регистров и закручивание циклов. Кроме того, для медленных портов процессор должен ещё ждать готовности, а DMA делает это на аппаратном уровне.
Но даже тут возможны различные нюансы. Если порт всего лишь условно медленный… Ну, скажем, SPI, работающий на максимально возможной частоте, то теоретически возможны ситуации, когда DMA не успеет забрать данные из буфера, и произойдёт переполнение. Или наоборот — поместить данные в буферный регистр. Когда поток данных один, вряд ли это произойдёт, но когда их много, мы видели, какие удивительные накладки могут возникать. Чтобы бороться с этим, следует разрабатывать задачи не обособленно, а в комплексе. А тестерам стараться спровоцировать подобные проблемы (такая у тестеров деструктивная работа).
Ещё раз повторю, что эти данные никто не скрывает. Но почему-то всё это обычно содержится не в основном документе, а в Application Notes. Так что моя задача была именно обратить внимание программистов на то, что DMA — это не панацея, а всего лишь удобный инструмент.
Но, разумеется, не только программистов, а ещё и разработчиков аппаратуры. Скажем, у нас в организации сейчас разрабатывается большой программно-аппаратный комплекс для удалённой отладки встраиваемых систем. Идея состоит в том, что кто-то разрабатывает некое устройство, а «прошивку» хочет заказать на стороне. И почему-то не может предоставить оборудование на сторону. Оно может быть громоздким, оно может быть дорогим, оно может быть уникальным и быть «нужно самим», с ним могут работать разные группы в разных часовых поясах, обеспечивая этакую многосменную работу, оно может постоянно доводиться до ума… В общем, причин придумать можно много, нашей группе просто спустили эту задачу, как данность.
Соответственно, комплекс для отладки должен уметь имитировать собой как можно большее число внешних устройств, от банальной имитации нажатия кнопок до различных протоколов SPI, I2C, CAN, 4-20 mA и прочего, прочего, прочего, чтобы через них эмуляторы могли воссоздавать различное поведение внешних блоков, подключаемых к разрабатываемому оборудованию (лично я в своё время сделал много имитаторов для наземной отладки навесного оборудования для вертолётов, у нас на сайте соответствующие кейсы ищутся по слову Cassel Aero).
И вот, в ТЗ на разработку спущены определённые требования. Столько-то SPI, столько-то I2C, столько-то GPIO. Они должны работать на таких-то предельных частотах. Кажется, что всё понятно. Ставим STM32F4 и ULPI для работы с USB в режиме HS. Технология отработанная. Но вот наступают длинные выходные с ноябрьскими праздниками, на которых я разобрался с UDB. Увидев неладное, я уже по вечерам получил те практические результаты, что приведены в начале этой статьи. И понял, что всё, конечно, здорово, но не для данного проекта. Как я уже отметил, когда возможная пиковая производительность системы приближается к верхней границе, следует проектировать всё не раздельно, а в комплексе.
А здесь комплексного проектирования задач не может быть в принципе. Сегодня идёт работа с одним сторонним оборудованием, завтра — совсем с другим. Шины будут использоваться программистами под каждый случай эмуляции по их усмотрению. Поэтому вариант был отвергнут, в схему было добавлено некоторое количество различных мостов FTDI. В пределах моста одна-две-четыре функции будут разрулены по жёсткой схеме, а между мостами всё будет разруливать USB хост. Увы. В данной задаче я не могу доверять DMA. Можно, конечно, сказать, что программисты потом выкрутятся, но часы на процесс выкрутасов – это трудозатраты, которых следует избегать.
Но это крайность. Чаще всего следует просто держать ограничения подсистемы DMA в уме (например, вводить поправочный коэффициент 10: если требуется поток 1 миллион транзакций в секунду, учитывать, что это не 1 миллион, а 10 миллионов тактов) и рассматривать производительность в комплексе.

