
Перед тобой снова задача детектирования объектов. Приоритет — скорость работы при приемлемой точности. Берешь архитектуру YOLOv3 и дообучаешь. Точность(mAp75) больше 0.95. Но скорость прогона всё еще низкая. Черт.
Сегодня обойдём стороной квантизацию. А под катом рассмотрим Model Pruning — обрезание избыточных частей сети для ускорения Inference без потери точности. Наглядно — откуда, сколько и как можно вырезать. Разберем, как сделать это вручную и где можно автоматизировать. В конце — репозиторий на keras.
Введение
На прошлом месте работы, пермском Macroscop, я обрёл одну привычку — всегда следить за временем исполнения алгоритмов. А время прогона сетей всегда проверять через фильтр адекватности. Обычно state-of-the-art в проде не проходят этот фильтр, что и привело меня к Pruning.
Pruning — тема старая, о которой рассказывали в cтэндфордских лекциях в 2017 году. Основная идея — уменьшение размера обученной сети без потери точности путем удаления различных узлов. Звучит клево, но я редко слышу о его применении. Наверное, не хватает имплементаций, нет русскоязычных статей или просто все считают pruning ноу-хау и молчат.
Но го разбирать
Взгляд в биологию
Люблю, когда в Deep Learning заглядывают идеи, пришедшие из биологии. Им, как и эволюции, можно доверять (а ты знал, что ReLU весьма похожа на функцию активации нейронов в мозге?)
Процесс Model Pruning тоже близок к биологии. Реакцию сети здесь можно сравнить с пластичностью мозга. Пара интересных примеров есть в книге Нормана Дойджа:
- Мозг женщины, имевшей от рождения только одну половину, перепрограммировал сам себя для выполнения функций отсутствующей половины
- Парень отстрелил себе часть мозга, отвечающую за зрение. Со временем другие части мозга взяли на себя эти функции. (повторить не пытаемся)
Так и из вашей модели можно вырезать часть слабых свёрток. В крайнем случае, оставшиеся свёртки помогут заменить вырезанные.
Любишь Transfer Learning или учишь с нуля?
Вариант номер один. Ты используешь Transfer Learning на Yolov3. Retina, Mask-RCNN или U-Net. Но чаще всего нам не нужно распознавать 80 классов объектов, как в COCO. В моей практике все ограничивается 1-2 классами. Можно предположить, что архитектура для 80 классов здесь избыточна. Напрашивается мысль, что архитектуру нужно уменьшить. Причем, хотелось бы сделать это без потери имеющихся предобученных весов.
Вариант номер два. Может быть, у тебя много данных и вычислительных ресурсов или просто нужна сверхкастомная архитектура. Неважно. Но ты учишь сеть с нуля. Обычный порядок — смотрим на структуру данных, подбираем ИЗБЫТОЧНУЮ по мощности архитектуру и пушим дропауты от переобучения. Я видел дропауты 0.6, Карл.
В обоих случаях сеть можно уменьшать. Промотивировали. Теперь идем разбираться, что за обрезание pruning
Общий алгоритм
Мы решили, что можем удалять свертки. Выглядит это весьма просто:
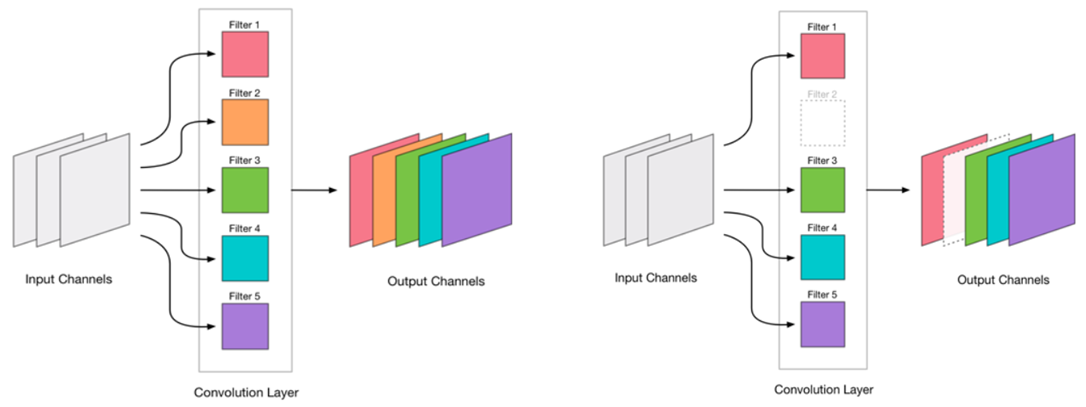
Удаление любой свертки — это стресс для сети, который обычно ведет за собой и некоторый рост ошибки. С одной стороны, этот рост ошибки является показателем того, насколько правильно мы удаляем свертки (например, большой рост говорит о том, что мы делаем что-то не так). Но небольшой рост вполне допустим и зачастую устраняется последующим легким дообучением с небольшим LR. Добавляем шаг дообучения:
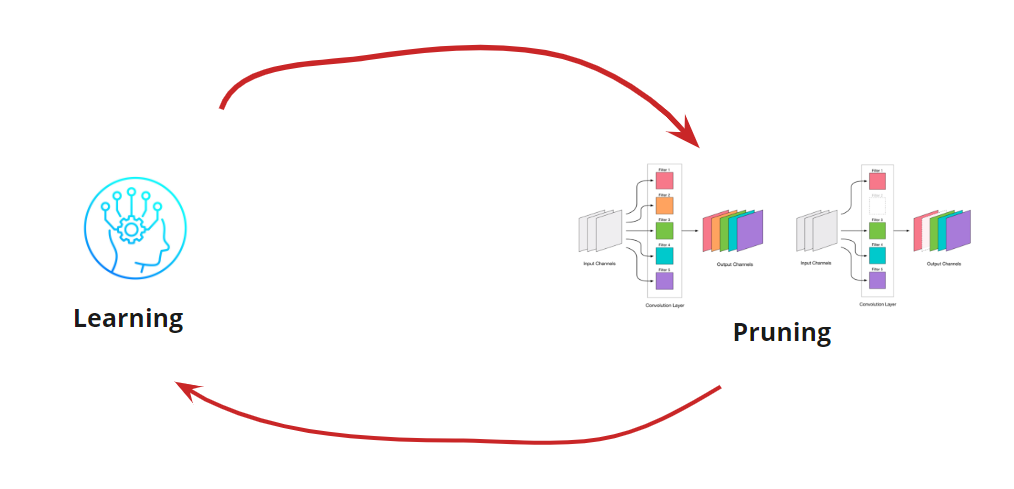
Теперь нам нужно понять, когда же мы хотим остановить наш цикл Learning<->Pruning. Здесь могут быть экзотические варианты, когда нам нужно уменьшать сеть до определенного размера и скорости прогона (например, для мобильных устройств). Однако, самый частый вариант — это продолжение цикла, пока ошибка не станет выше допустимой. Добавляем условие:
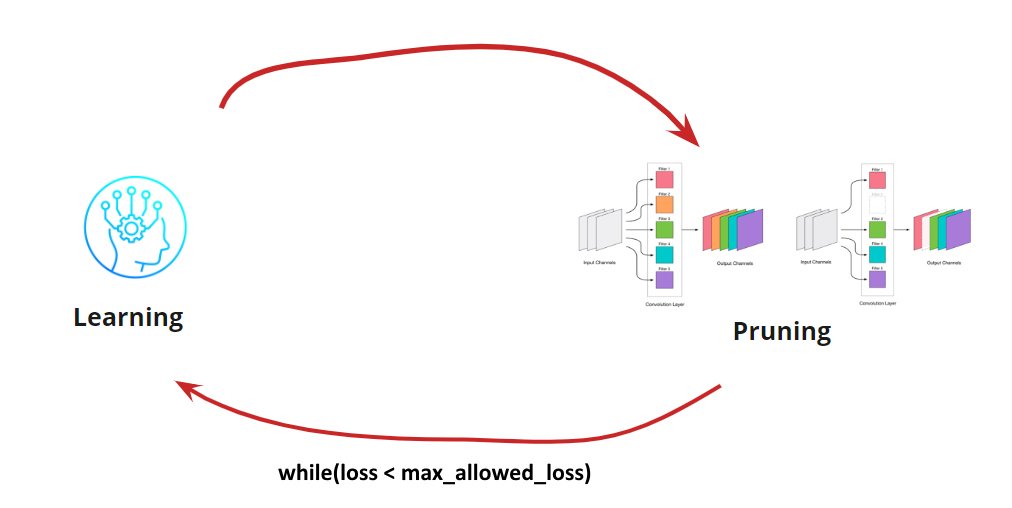
Итак, алгоритм становится понятным. Остается разобрать, как определить удаляемые свертки.
Поиск удаляемых сверток
Нам нужно удалить какие-то свертки. Рваться напролом и "отстреливать" любые — плохая идея, хоть и будет работать. Но раз есть голова, можно подумать и попытаться выделить для удаления "слабые" свертки. Вариантов есть несколько:
- Наименьшая L1-мера или low_magnitude_pruning. Идея, говорящая о том, что свертки с малыми значениями весов, вносят малый вклад в итоговое принятие решения
- Наименьшая L1-мера с учетом среднего и стандартного отклонения. Дополняем оценкой характера распределения.
- Маскирование сверток и исключение наименее влияющих на итоговую точность. Более точное определение малозначимых свёрток, но весьма затратное по времени и ресурсам.
- Другие
Каждый из вариантов имеет право на жизнь и свои особенности реализации. Здесь рассмотрим вариант с наименьшей L1-мерой
Ручной процесс для YOLOv3
В исходной архитектуре содержатся остаточные блоки. Но какими бы крутыми они ни были для глубоких сетей, нам они несколько помешают. Сложность в том, что нельзя удалять сверки с разными индексами в этих слоях:
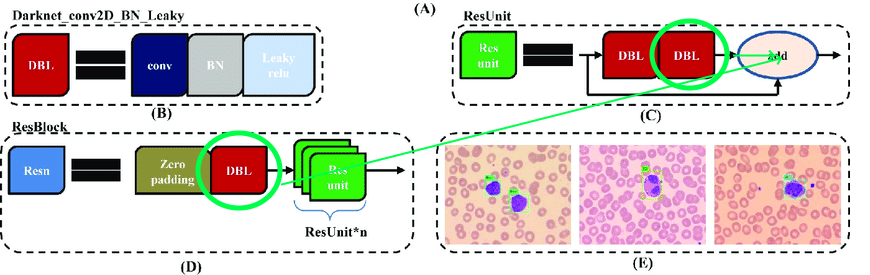
Поэтому выделим слои, из которых мы можем свободно удалять сверки:
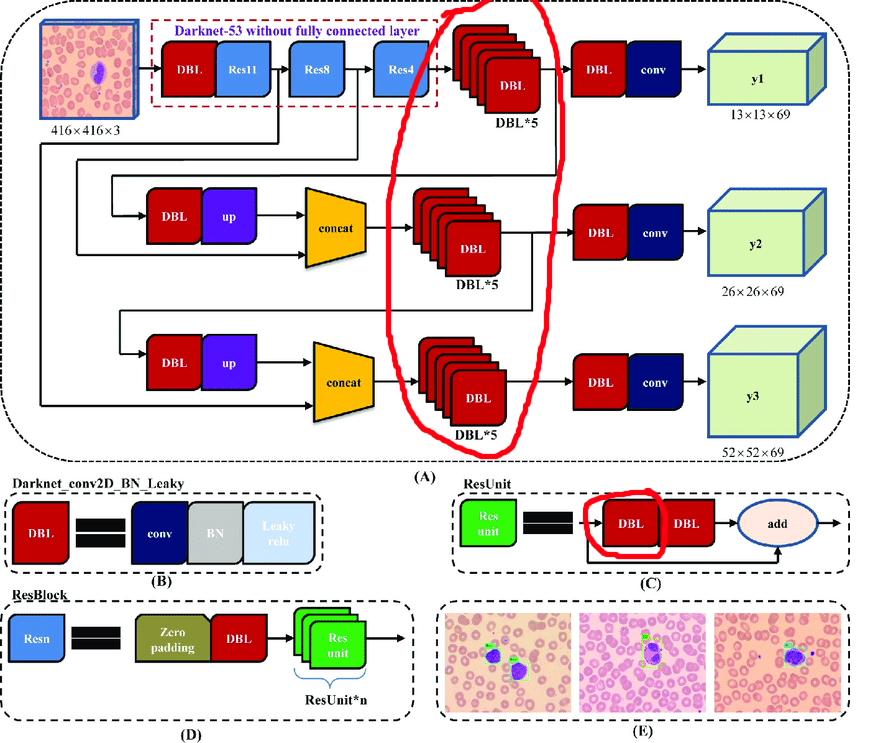
Теперь построим цикл работы:
- Выгружаем активации
- Прикидываем, сколько вырезать
- Вырезаем
- Учим 10 эпох с LR=1e-4
- Тестируем
Выгружать свертки полезно, чтобы оценить, какую часть мы можем удалить на определённом шаге. Примеры выгрузки:
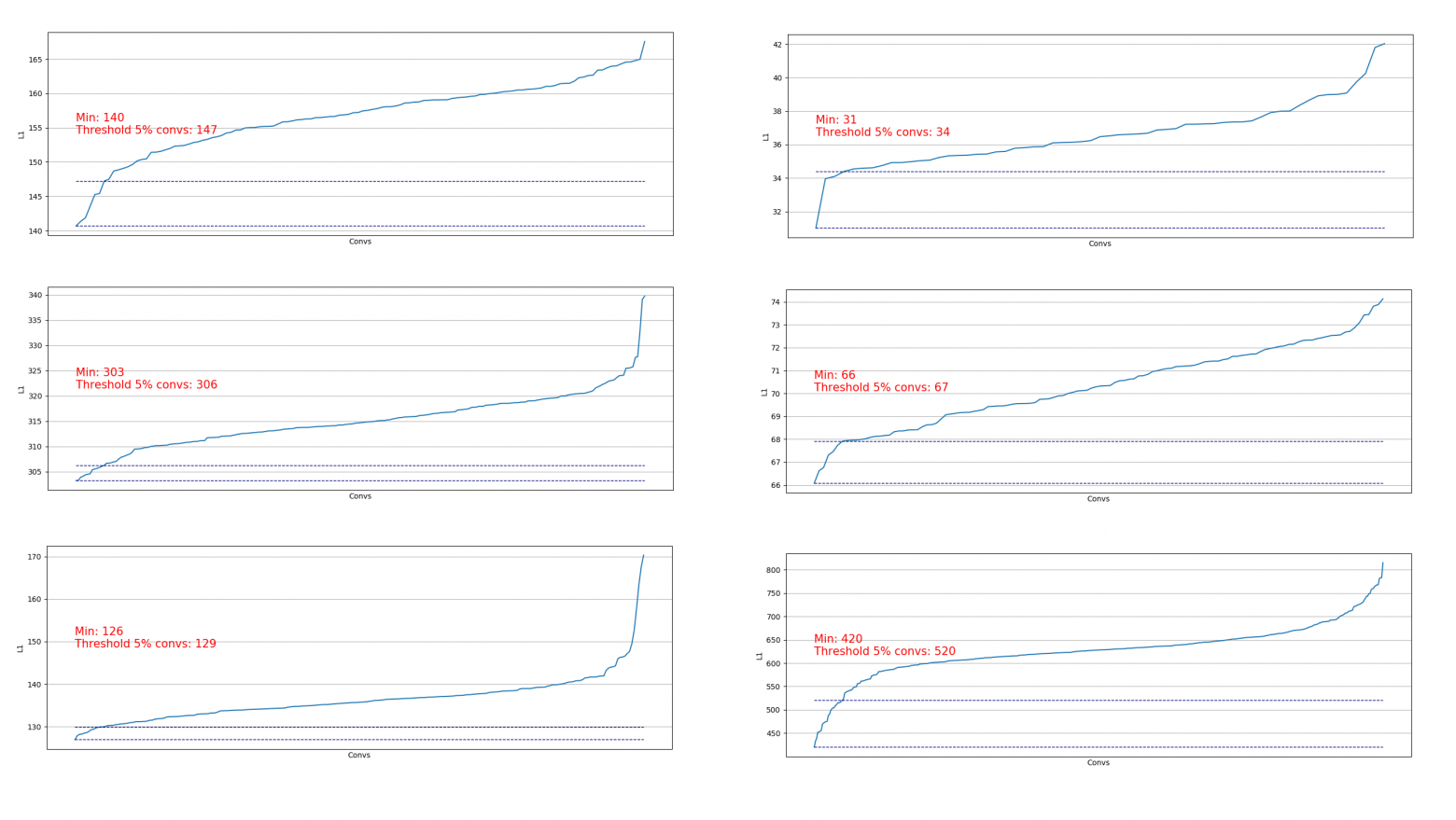
Видим, что практически везде 5% свёрток имеют весьма низкую L1-норму и мы можем их удалить. На каждом шаге такая выгрузка повторялась и производилась оценка, из каких слоев и сколько можно вырезать.
Весь процесс уложился в 4 шага(тут и везде числа для RTX 2060 Super):
| Шаг | mAp75 | Число параметров, млн | Размер сети, мб | От изначальной, % | Время прогона, мс | Условие обрезания |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 5% от всех |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 5% от всех |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15% для слоев с 400+ сверток |
К 2 шагу добавился один положительный эффект — в память влез батч-сайз 4, что весьма ускорило процесс дообучения.
На 4 шаге процесс был остановлен, т.к. даже длительное дообучение не поднимало mAp75 до старых значений.
В итоге удалось ускорить инференс на 15%, уменьшить размер на 35% и не потерять в точности.
Автоматизация для более простых архитектур
Для более простых архитектур сетей(без условных add, concaternate и residual блоков) вполне можно ориентироваться на обработку всех сверточных слоёв и автоматизировать процесс вырезания сверток.
Такой вариант я заимплементировал здесь.
Всё просто: с вас только функция потерь, оптимизатор и батч-генераторы:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
При необходимости можно изменить параметры конфиги:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
Дополнительно реализовано ограничение на основании стандартного отклонения. Цель — ограничить часть удаляемых, исключая свертки с уже "достаточными" L1-мерами:
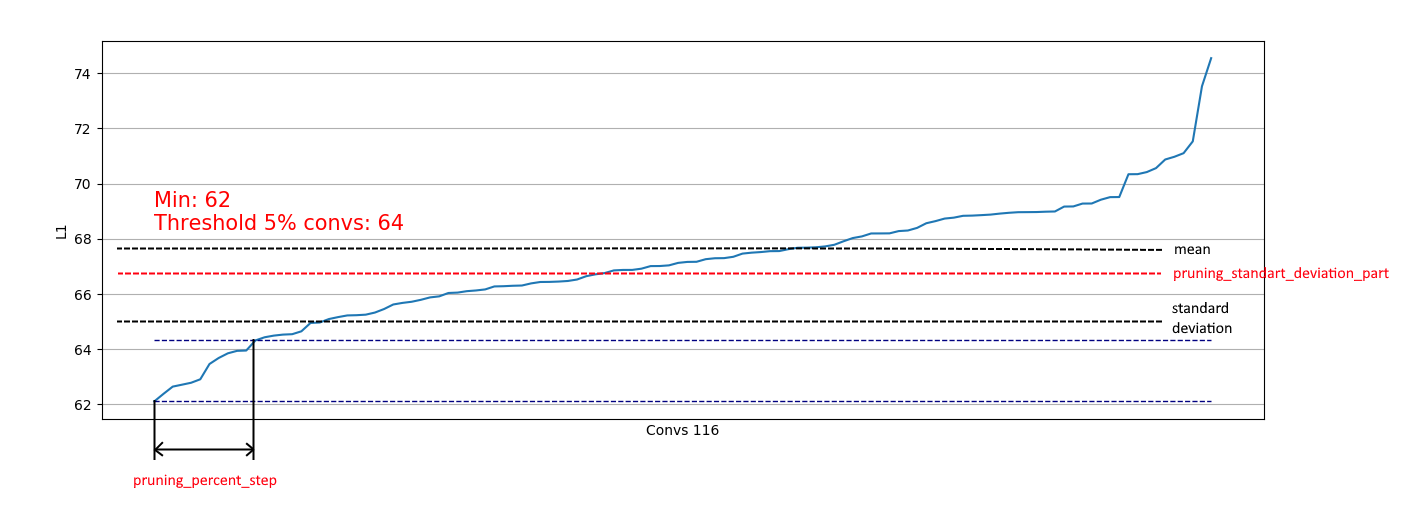
Тем самым, мы позволяем удалить только слабые свертки из распределений подобных правому и не влиять на удаление из распределений подобных левому:

При приближении распределения к нормальному коэффициент pruning_standart_deviation_part можно подобрать из:
Я рекомендую допущение в 2 сигма. Или можно не ориентироваться на эту особенность, оставив значение < 1.0.
На выходе получается график размера сети, потери и времени прогона сети по всему тесту, отнормированные к 1.0. Например, здесь размер сети был уменьшен почти в 2 раза без потери в качестве (небольшая сверточная сеть на 100к весов):
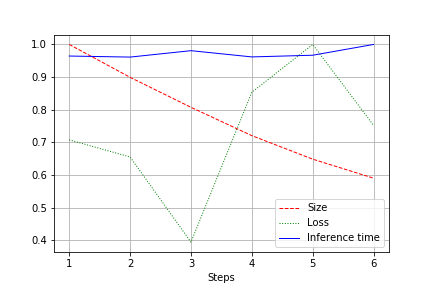
Скорость прогона подвержена нормальным флуктуациям и практически не изменилась. Этому есть объяснение:
- Число сверток меняется с удобного (32, 64, 128) на не самые удобные для видеокарт — 27, 51 и тд. Тут могу ошибиться, но скорее всего это влияет.
- Архитектура не широкая, но последовательная. Уменьшая ширину, мы не трогаем глубину. Тем самым уменьшаем загрузку, но не меняем скорость.
Поэтому улучшение выразилось в уменьшении загрузки CUDA при прогоне на 20-30%, но не в уменьшении времени прогона
Итоги
Порефлексируем. Мы рассмотрели 2 варианта pruning — для YOLOv3(когда приходится работать руками) и для сетей с архитектурами попроще. Видно, что в обоих случаях можно добиться уменьшения размера сети и ускорения без потери точности. Результаты:
- Уменьшение размера
- Ускорение прогона
- Уменьшение загрузки CUDA
- Как следствие, экологичность (Мы оптимизируем будущее использование вычислительных ресурсов. Где-то радуется одна Грета Тунберг)
Appendix
- После шага pruning можно докрутить и квантизацию (например с TensorRT)
- Tensorflow предоставляет возможности для low_magnitude_pruning. Работает.
- Репозиторий хочу развивать и буду рад помощи

