

Микросервисная архитектура звучит неплохо само по себе, но еще лучше — быстрый микросервис, который эффективно использует ресурсы сервера.
Я покажу, как последовательно применять к простому без затей микросервису методы ускорения его работы, попутно рассматривая плюсы и минусы каждого из них.
Посмотрим, как можно распараллелить работу микросервиса, распределив нагрузку в несколько потоков, увеличить производительность с помощью асинхронного исполнения и ускорить работу при помощи кэша.
Перечисленные способы подходят только для программ, написанных на Python 3 + FastApi, это не универсальные способы ускорения любых микросервисов. И, конечно, здесь описаны основные методы, выбор лучшего варианта — за разработчиком в зависимости от ситуации.
Репозиторий с исходным кодом — на GitHub.
Статья подготовлена командой облачной платформы Mail.ru Cloud Solutions.

Что я буду использовать
Для корректной работы микросервисов, о которых я говорю, нужен только Docker Compose — они уже упакованы в Docker-контейнеры. Благодаря этому любой микросервис можно легко развернуть не только на локальной машине, но и в облаке на VPS/VDS. Клиент для проверки скорости работы написан на Python 3 с использованием asyncio и HTTPX. В качестве данных для примера я использовал прогноз погоды с pogoda.mail.ru.
Примечание: можно было бы не парсить данные, а использовать открытый API, например openweathermap.org. Но тогда бы пришлось проходить регистрацию и получать API-ключ. В текущей реализации это не требуется — все будет работать сразу.
Для проверки скорости работы микросервисов я использую клиент, который асинхронно отправляет запросы для трех различных городов, а в конце выводит общее время работы и среднее время на один запрос. Он будет посылать 18 запросов: сервер pogoda.mail.ru банит на 10-20 секунд, если отправить больше 20 запросов подряд.
Для проверки 18-ти запросов нам хватит. Но даже если бы мы использовали API openweathermap.org, то не смогли бы послать более 60 запросов в минуту (см. Free Subscription). То есть числа вполне сопоставимые.
import asyncio import httpx import time async def get_data_api(city): url = f'http://127.0.0.1:8000/api/weather/{city}' for i in range(6): async with httpx.AsyncClient() as client: response = await client.get(url) response.raise_for_status() data = response.json() print('city: {}, temperature: {}, source: {}'.format( data.get('city'), data.get('temperature'), data.get('source'))) tasks = [ asyncio.ensure_future(get_data_api('moskva')), asyncio.ensure_future(get_data_api('tokyo')), asyncio.ensure_future(get_data_api('london')) ] start = time.time() loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.gather(*tasks)) loop.close() end = time.time() - start print(f'time {end:0.2f} seconds') print(f'mean time for 1 request: {end/18:0.2f} seconds')
Шаг 1. Разворачиваю простой микросервис

Все файлы простого микросервиса находятся в папке 1-simple-microservice. Исходный код микросервиса — в файле simple-microservice.py, он построен на веб-фреймворке FastApi.
На вход микросервис принимает название города, в главном потоке делает запрос на внешний ресурс, парсит температуру в городе и возвращает результат работы. Это базовый микросервис, который мы будем дальше ускорять.
import fastapi import httpx from scrapy.selector import Selector api = fastapi.FastAPI() @api.get('/api/weather/{city}') def weather(city: str): url = f'https://pogoda.mail.ru/prognoz/{city}/' with httpx.Client() as client: response = client.get(url) response.raise_for_status() selector = Selector(text=response.text) t = selector.xpath('//div[@class="information__content__temperature"]/text()').getall()[1].strip() return {'city':city, 'temperature':t, 'source':'pogoda.mail.ru'}
FROM python:3.7 RUN python -m pip install fastapi httpx scrapy gunicorn uvicorn uvloop httptools WORKDIR /app ADD simple-microservice.py simple-microservice.py
version: '3.7' services: microservice: build: context: ./microservice image: simple-microservice container_name: simple-microservice restart: unless-stopped ports: - "8000:8000" command: gunicorn -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker simple-microservice:api
Результат работы клиента:
city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru time 1.22 seconds mean time for 1 request: 0.07 seconds
Итого получаем, что простой микросервис отработал в общей сложности 1.22 секунды, а на один запрос потратил в среднем 0.07 секунд.
Шаг 2. Добавляю в микросервис многопоточность
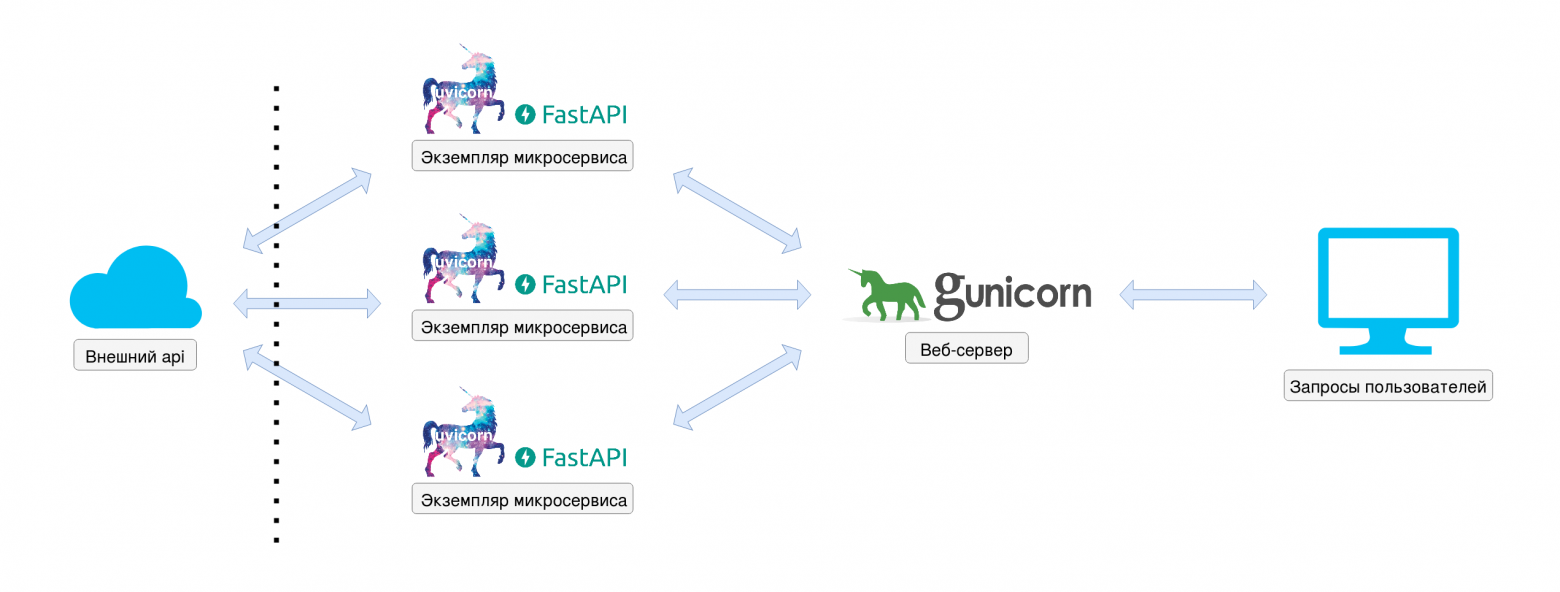
Все файлы — в папке 2-few-threads-microservice. Чтобы не усложнять пример распределением трафика между экземплярами микросервиса, пойдем самым простым путем. Распараллелим процесс с помощью Gunicorn веб-сервера, а именно — добавим в docker-compose.yml в строку command: gunicorn -b 0.0.0.0:8000… параметр --workers=n, чтобы было n процессов, в нашем случае три.
Примечание: еще можно было бы использовать Nginx-балансировщик, пример — здесь.
К плюсам данного подхода можно отнести простое внедрение, к минусам — линейный рост потребления ресурсов. Например, если один микросервис потреблял 100 MB памяти, то, работая в три потока, он задействует не менее 300 MB. Потребление можно снизить, если расшарить ресурсы между потоками, например как показано ниже, использовать общий для всех потоков кэш.
import fastapi import httpx from scrapy.selector import Selector api = fastapi.FastAPI() @api.get('/api/weather/{city}') def weather(city: str): url = f'https://pogoda.mail.ru/prognoz/{city}/' with httpx.Client() as client: response = client.get(url) response.raise_for_status() selector = Selector(text=response.text) t = selector.xpath('//div[@class="information__content__temperature"]/text()').getall()[1].strip() return {'city':city, 'temperature':t, 'source':'pogoda.mail.ru'}
FROM python:3.7 RUN python -m pip install fastapi httpx scrapy gunicorn uvicorn uvloop httptools WORKDIR /app ADD few-threads-microservice.py few-threads-microservice.py
version: '3.7' services: microservice: build: context: ./microservice image: few-threads-microservice container_name: few-threads-microservice restart: unless-stopped ports: - "8000:8000" # work in few threads command: gunicorn --workers=3 -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker few-threads-microservice:api
Результат работы клиента:
city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru time 1.15 seconds mean time for 1 request: 0.06 seconds
Прирост скорости по сравнению с простым микросервисом есть: общее время работы — 1.15 секунд, среднее время одного запроса — 0.06 секунд. Тут нужно уточнить, что на работу балансировщика требуется время, и если микросервис сам по себе быстрый, то выигрыш будет небольшой. Но если микросервис тяжелый, прирост скорости будет заметнее.
Шаг 3. Добавляю асинхронное исполнение

В обычной программе, когда процесс в исполняющем потоке доходит до места, где требуются внешние ресурсы, он блокирует исполнение, ожидая ответа. При асинхронном исполнении программы исполняющий поток занят другим процессом — за счет этого и увеличивается производительность.
Исходные файлы микросервиса — в папке 3-async-few-threads-microservice. Для создания микросервиса мы изначально взяли веб-фреймворк FastApi и веб-сервер Gunicorn, который использует ASGI-воркер Uvicorn. Значит, для асинхронного исполнения достаточно пометить асинхронные методы ключевым словом async и реализовать в них операции, требующие ожидания await.
В нашем случае мы обращаемся за прогнозом погоды — это наша await операция. Основной плюс этого подхода в том, что он позволяет эффективнее использовать ресурсы, к минусам можно было бы отнести бóльшую сложность реализации, но с FastApi это не так.
async-few-threads-microservice.py:
import fastapi import httpx from scrapy.selector import Selector api = fastapi.FastAPI() @api.get('/api/weather/{city}') async def weather(city: str): url = f'https://pogoda.mail.ru/prognoz/{city}/' # asynchronous implementation async with httpx.AsyncClient() as client: response = await client.get(url) response.raise_for_status() selector = Selector(text=response.text) t = selector.xpath('//div[@class="information__content__temperature"]/text()').getall()[1].strip() return {'city':city, 'temperature':t, 'source':'pogoda.mail.ru'}
FROM python:3.7 RUN python -m pip install fastapi httpx scrapy gunicorn uvicorn uvloop httptools WORKDIR /app ADD async-few-threads-microservice.py async-few-threads-microservice.py
version: '3.7' services: microservice: build: context: ./microservice image: async-few-threads-microservice container_name: async-few-threads-microservice restart: unless-stopped ports: - "8000:8000" # work in few threads command: gunicorn --workers=3 -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker async-few-threads-microservice:api
Результат работы клиента:
city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: pogoda.mail.ru time 0.88 seconds mean time for 1 request: 0.05 seconds
Скорость работы снова выросла: общее время выполнения — 0.88 секунд, среднее время выполнения одного запроса — 0.05 секунд. Асинхронное исполнение в связке с FastApi дает хороший прирост производительности при минимальных затратах. Этот подход следует использовать везде, где есть обращение к внешним по отношению к потоку исполнения ресурсам, например к внешним API и базам данных.
Шаг 4. Добавляю к микросервису кэш
При использовании общего ресурса в многопоточном приложении резонно возникает вопрос синхронизации доступа к данным. Начиная с версии 4 Redis стал более многопоточным, не говоря уже о более свежем Redis 6. Из-за этого не сразу понятно, можно ли посылать в кэш несинхронизированные запросы.
На самом деле, интерфейс доступа к данным внутри ядра Redis остался однопоточным (пруфы здесь). Значит, сколько бы команд на запись/чтение мы не послали, они выполнятся строго последовательно.
Redis — in-memory data structure store, он хранит данные в оперативной памяти. И благодаря этому имеет колоссальную производительность (даже на сервере начального уровня от 100 тысяч get/set запросов в секунду, подробнее — здесь) и часто используется для реализации кэша.

Как и все вариации микросервисов, я сконфигурировал Redis для работы в качестве кэша и упаковал его в Docker-контейнер. Рассмотрим подробнее настройки, которые я добавил в файл redis.conf:
- bind 0.0.0.0 — замапил Redis на внутренний localhost Docker-контейнера.
- maxmemory 100mb — ограничил размер кэша.
- maxmemory-policy volatile-ttl — эта политика позволяет удалить наименее актуальные данные при достижении лимита памяти. Подробнее об этом — здесь.
Примечание: скачать дефолтный пример redis.conf можно отсюда, там же есть рекомендации по настройке Redis в качестве кэша.
Далее я запустил Redis со своими конфигами и связал папку ./redis/data с папкой data внутри Docker-контейнера, чтобы данные сохранялись на внешний диск (смотрите в файле docker-compose.yml).
Тут нужна оговорка: хотя кэш может сильно ускорить работу микросервиса, в некоторых случаях его невозможно применять, например если при каждом запросе нужны только актуальные данные. В данном примере реализована схема, при которой прогноз погоды (температура в городе) будет храниться в кэше 1 час. Для подобных данных это нормально, так как они не сильно меняются за это время.
Файлы микросервиса — в папке 4-cache-async-few-threads-microservice. В реализации ничего сложного нет: сперва читаем кэш из памяти, если он есть — отправляем данные, если нет — делаем внешний запрос и обработку ответа. Затем кладем полученные данные в кэш на 1 час и возвращаем ответ. Имплементация запросов на чтение и запись — асинхронная. Как говорилось выше, в данном случае кэш — это внешний ресурс.
cache-async-few-threads-microservice.py:
import fastapi import httpx from scrapy.selector import Selector import aioredis api = fastapi.FastAPI() @api.get('/api/weather/{city}') async def weather(city: str): redis = await aioredis.create_redis(address=('redis', 6379)) # get cache from memory cache = await redis.get(city) # check value from cache, if exists return it if cache is not None: return {'city':city, 'temperature':cache, 'source':'cache'} url = f'https://pogoda.mail.ru/prognoz/{city}/' # asynchronous implementation async with httpx.AsyncClient() as client: response = await client.get(url) response.raise_for_status() selector = Selector(text=response.text) t = selector.xpath('//div[@class="information__content__temperature"]/text()').getall()[1].strip() # save cache in memory for 1 hour await redis.set(city, t, expire=3600) return {'city':city, 'temperature':t, 'source':'pogoda.mail.ru'}
Dockerfile (добавил только aioredis для асинхронного чтения/записи в Redis):
FROM python:3.7 RUN python -m pip install fastapi httpx scrapy gunicorn uvicorn uvloop httptools aioredis WORKDIR /app ADD cache-async-few-threads-microservice.py cache-async-few-threads-microservice.py
version: '3.7' services: microservice: build: context: ./microservice image: cache-async-few-threads-microservice container_name: cache-async-few-threads-microservice restart: unless-stopped ports: - "8000:8000" # work in few threads command: gunicorn --workers=3 -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker cache-async-few-threads-microservice:api redis: image: redis container_name: redis restart: unless-stopped volumes: - ./redis/data:/data - ./redis/redis.conf:/usr/local/etc/redis/redis.conf expose: - 6379 command: redis-server /usr/local/etc/redis/redis.conf
Результат работы клиента:
city: moskva, temperature: +16°, source: pogoda.mail.ru city: moskva, temperature: +16°, source: cache city: moskva, temperature: +16°, source: cache city: moskva, temperature: +16°, source: cache city: moskva, temperature: +16°, source: cache city: moskva, temperature: +16°, source: cache city: tokyo, temperature: +11°, source: pogoda.mail.ru city: london, temperature: +8°, source: pogoda.mail.ru city: tokyo, temperature: +11°, source: cache city: london, temperature: +8°, source: cache city: tokyo, temperature: +11°, source: cache city: london, temperature: +8°, source: cache city: tokyo, temperature: +11°, source: cache city: london, temperature: +8°, source: cache city: tokyo, temperature: +11°, source: cache city: london, temperature: +8°, source: cache city: tokyo, temperature: +11°, source: cache city: london, temperature: +8°, source: cache time 0.48 seconds mean time for 1 request: 0.03 seconds
Как видно из результатов, кэш сработал отлично. Было всего три реальных запроса — остальные использовали кэш. Скорость работы возросла значительно: общее время выполнения — 0.48 секунд, среднее время выполнения одного запроса — 0.03 секунды.
Заключение
Различные методы для ускорения микросервисов позволяют эффективнее использовать доступные ресурсы. В таблице ниже — результаты тестов скорости работы для каждого из рассмотренных микросервисов.
Конечно, на практике далеко не всегда получается применять все методы ускорения. Но можно добиться вполне существенных результатов, реализовав даже некоторые из них. В нашем случае скорость работы увеличилась более чем в два раза.
| Микросервис | Общее время | Среднее время на один запрос |
|---|---|---|
| простой | 1.22 | 0.07 |
| + многопоточность | 1.15 | 0.06 |
| + асинхронность | 0.88 | 0.05 |
| + кэш | 0.48 | 0.03 |
Полезные ссылки:
Redis можно получить в виде управляемого сервиса (DBaaS) на платформе Mail.ru Cloud Solutions. Новым пользователям платформы мы дарим 3000 бонусов после полной верификации аккаунта. Вы сможете повторить сценарий из статьи или попробовать другие наши сервисы.
Что еще почитать:
