Данная статья будет полезна студентам и тем, кто хочет разобраться с тем, как происходит шумоподавление речи (Speech Denoising) с помощью глубокого обучения. На Хабре уже были статьи по данной тематике несколько лет назад (раз, два), но нашей целью является желание дать несколько более глубокое понимание процесса работы со звуком.

Задача шумоподавления с помощью глубокого обучения и OpenVINO попала в руки к студентам ITlab – учебно-исследовательской лаборатории Университета Лобачевского при поддержке компании Intel. Студенты, начиная со 2 курса, под руководством преподавателей работают над интересными инженерными и научными проектами. Создание высокопроизводительного программного обеспечения требует применения специальных инструментов разработчика и технологий параллельного исполнения кода, и в рамках проектов лаборатории студенты с ними знакомятся. Данная статья является результатом работы студентов Вихрева Ивана, Рустамова Азера, Зайцевой Ксении, Кима Никиты, Бурдукова Михаила, Филатова Андрея.
Что есть звук в компьютере
Подавление фонового шума речи беспокоит людей уже очень давно, а с приходом дистанционной работы и обучения значимость проблемы возникла многократно. Разговаривать через интернет приходится все больше, и аудиосообщения встроены во все популярные мессенджеры. Как бы банально не звучало, но хороший, чистый звук человек воспринимает лучше. Однако хороший микрофон стоит денег, да и звукоизоляция в среднестатистической квартире оставляет желать лучшего, и мы слышим всё - от работы кулеров в ноутбуке и заканчивая дрелью надоедливого соседа (шум дрели у преподавателя особо мешает восприятию материала).
Как получить чистый звук, не покупая студийный микрофон и не обивая всю квартиру звукоизолирующими материалами? Над этим вопросом люди думают ещё с конца прошлого века. Решением стали программы, оцифровывающие и редактирующие входящий из микрофона звук.

Записанный звук состоит из множества звуковых волн, одновременно попадающих на датчик микрофона в некоторый промежуток времени, в результате чего мы получаем длинный вектор из чисел - это амплитуды (громкость) сигнала в течение небольшого времени. Частота сигнала проводного телефона 8kHz, это значит что мы за секунду 8000 раз измеряем амплитуду (громкость) суммарного сигнала, звуковые карты как правило используют частоту 44.1 или 48kHz.

Воспроизвести аудиофайл в Python можно с помощью библиотек soundfile и sounddevice.
import sounddevice as sd import soundfile as sf path_wav = 'test_wav.wav' data, fs = sf.read(path_wav) sd.play(data, fs) status = sd.wait()
Запись данных с микрофона тоже происходит очень просто - посмотрите и запустите record.py.
Кстати, важная для нас информация. Наша последовательность является суммой множества звуковых волн, и мы можем вычислить какие волны приняли участи в нашей сумме. Теоретически, любой сложный звук может быть разложен на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду и может быть описан числовыми параметрами (а вы говорили, что матан не нужен). Исследования по данной тематике входят в область цифровой обработки сигналов, на хабре есть информация об открытом курсе «Основы цифровой обработки сигналов».

Чтобы делать с аудио сложные вещи, такие как распознавание человека по голосу, перевод речи речи в текст или удаление шума с помощью глубокого обучения, нам понадобится вычислить вклад различных частот в аудиопоследовательность — спектр. Спектр можно представить в виде спектрограммы — изображения, показывающего зависимость амплитуды сигнала во времени на различных частотах. Один столбец в спектрограмме соответствует спектру короткого участка исходного сигнала, более тёплые тона означают большее значение.

Спектр для спектрограммы можно вычислить с помощью дискретного преобразования Фурье, реализованного в библиотеке Numpy. Рассмотрим пример создания спектрограммы, описанный в сэмпле. Для этого используются две функции из файла features.py:
def calcSpec(y, params, channel=None): """compute complex spectrum from audio file""" fs = int(params["fs"]) # Константа, обозначающая частоту дискредитации # В нашем случае равна 16000 - наш wav файл записан с частотой 16 кГц if channel is not None and (len(y.shape)>1): # Если аудио содержит два канала (стерео) - берем только один канал sig = sig[:,channel] # STFT parameters N_win = int(float(params["winlen"])*fs) # Расчёт размера окна Хэннинга # В нашем случае 320 if 'nfft' in params: N_fft = int(params['nfft']) else: N_fft = int(float(params['winlen'])*fs) # Расчёт ширины окна для преобразования Фурье # В нашем случае 320 N_hop = int(N_win * float(params["hopfrac"])) # Расчёт прыжка для преобразования Фурье # В нашем случае 160 win = np.sqrt(np.hanning(N_win)) # Окно Хэннинга Y = stft(y, N_fft, win, N_hop) return Y
Функция Stft проводит преобразование Фурье. Массив делится на части определённой длины (рассчитанной в calcSpec) и для каждой из частей применяется функция преобразования Фурье, взятая из Numpy возвращает готовую спектрограмму.
def stft(x, N_fft, win, N_hop, nodelay=True): """ short-time Fourier transform x - Входной сигнал N_fft - Количество точек, на которых используется преобразование win - Окно Хэннинга N_hop - Размер прыжка nodelay - Удаление первых точек из конечного массива (В них появляется побочный эффект преобразования) """ # get lengths if x.ndim == 1: x = x[:,np.newaxis] # Если подано несколько файлов, то создаётся дополнительная ось Nx = x.shape[0] # Количество точек во входных данных (в нашем случае 160000) M = x.shape[1] # Количество файлов во входных данных (в нашем случае 1) specsize = int(N_fft/2+1) N_win = len(win) # Размер окна Хэннинга N_frames = int(np.ceil( (Nx+N_win-N_hop)/N_hop )) # На сколько частей делим входной массив Nx = N_frames*N_hop # padded length x = np.vstack([x, np.zeros((Nx-len(x),M))]) # init X_spec = np.zeros((specsize,N_frames,M), dtype=complex) # Заполненная нулями матрица, которая станет спектрограммой win_M = np.outer(win,np.ones((1,M))) # Создаём матрицу, в которой каждый столбец равен окну Хэннинга x_frame = np.zeros((N_win,M)) # Заполненный нулями вектор (вектора в случае если на вход дали несколько файлов) for nn in range(0,N_frames): idx = int(nn*N_hop) x_frame = np.vstack((x_frame[N_hop:,:], x[idx:idx+N_hop,:])) # Разделяем входной массив на куски размера N_hop x_win = win_M * x_frame X = np.fft.rfft(x_win, N_fft, axis=0) # Преобразование возвращает столбец комплексных, где действительная часть - амплитуда, а комплексная - фазовый сдвиг X_spec[:,nn,:] = X # Добавляем полученный столбец в спектрограмму if nodelay: delay = int(N_win/N_hop - 1) X_spec = X_spec[:,delay:,:] # Удаляем лишний столбец из начала if M==1: X_spec = np.squeeze(X_spec) # Удаляем лишнюю ось return X_spec
Также важной функцией является calcFeat, позволяющая нам прологарифмировать спектрограмму, растягивая нижние частоты и сжимая верхние. Голос человека лежит в диапазоне 85-3000Гц, а диапазон звуковых частот в нашей записи 16кГц — маленький промежуток на всем диапазоне, и помощью логарифмирования мы “растягиваем” нужные нам низкие частоты и “поджимаем” ненужные высокие
def calcFeat(Spec, cfg): """compute spectral features""" if cfg['feattype'] == "MagSpec": inpFeat = np.abs(Spec) elif cfg['feattype'] == "LogPow": pmin = 10**(-12) powSpec = np.abs(Spec)**2 # Все значения спектрограммы возводятся в квадрат inpFeat = np.log10(np.maximum(powSpec, pmin)) # и логарифмируются с обрезанием слишком низких значений else: ValueError('Feature not implemented.') return inpFeat
Наша глубокая модель удаления шума обучена на логарифмированных спектрограммах, поэтому предобработка данной функцией обязательна. Чтобы преобразовать спектрограмму, полученную применением фильтра (выход нейросети) на образ-Фурье, полученный с помощью функции calcSpec, в звук используется функция Spec2sig. В ней вычисляются параметры обратного преобразования Фурье и вызывается функция istft (обратное быстрое преобразование Фурье).
def spec2sig(Spec, params): """Конвертирует спектрограмму в звук""" # частота дискретизации fs = int(params["fs"]) # ширина окна N_win = int(float(params["winlen"])*fs) if 'nfft' in params: N_fft = int(params['nfft']) else: # длина быстрого преобразования Фурье N_fft = int(float(params['winlen'])*fs) #длина сегментов окна N_hop = int(N_win * float(params["hopfrac"])) # окно Хеннинга win = np.sqrt(np.hanning(N_win)) # обратное преобразование Фурье x = istft(Spec, N_fft, win, N_hop) return x
В istft обратное преобразование Фурье также выполняется при помощи функции взятой из Numpy.
def istft(X, N_fft, win, N_hop): # get lengths specsize = X.shape[0] # Спектрограмма N_frames = X.shape[1] # кол-во кадров if X.ndim < 3: X = X[:,:,np.newaxis] # Приведение размера до 3 M = X.shape[2] # кол-во каналов N_win = len(win) # длина окна хеннинга Nx = N_hop*(N_frames - 1) + N_win # Умножение матрицы win и единичной матрицы размера 1,M win_M = np.outer(win,np.ones((1, M))) x = np.zeros((Nx,M)) # нулевая матрица Nx,M для сохранения ответа for nn in range(0, N_frames): X_frame = np.squeeze(X[:,nn,:]) # Вектор по данному фрейму # обратное преобразование фурье для X_frame ,N_fft x_win = np.fft.irfft(X_frame, N_fft, axis=0) x_win = x_win.reshape(N_fft,M) # изменяем размер # получаем окно хеннинга нужного размера x_win = win_M * x_win[0:N_win,:] # добавляем результат для данного фрейма idx1 = int(nn*N_hop); idx2 = int(idx1+N_win) x[idx1:idx2,:] = x_win + x[idx1:idx2,:] if M == 1: x = np.squeeze(x) # Убираем лишние измерения если канал один return x
Звуковой сигнал, записываемый в реальных акустических условиях, часто содержит нежелательные шумы, которые могут порождаться окружающей средой или звукозаписывающей аппаратурой. Значит, полученное цифровое описание также будет содержать нежелательные шумы.

Чтобы “очистить” звук, к цифровому описанию необходимо применить фильтр, который убирает нежелательные шумы. Но возникает другая проблема. Каждый из видов шумов требует свой фильтр, который необходимо подбирать вручную или искать в банках данных фильтров. Отфильтровать шум на частотах, отличающихся от человеческой речи, проблем нет, от них избавлялись еще до этих ваших нейросетей. А вот убрать детский плач или стучание клавиш без значительного ухудшения качества голоса было проблематично.
В решении данной проблемы могут помочь модели глубокого обучения. Основное преимущество нейросетей перед заранее подготовленными фильтрами заключается в большем охвате различных видов шумов. Нейросеть можно натренировать, постоянно добавляя всё новые виды шума.
В нашем случае мы воспользуемся моделью NSNet2. Эта нейронная сеть использовалась в Deep Noise Suppression Challenge, проводимом компанией Microsoft. Целью разработки данной сети было создание модели для очистки звука от шума в реальном времени. Данная модель состоит из полносвязного слоя с ReLU, двух рекуррентных GRU (Gated Recurrent Unit) блоков и полносвязных слоев (FF, feed forward) с ReLU и sigmoid активацией.
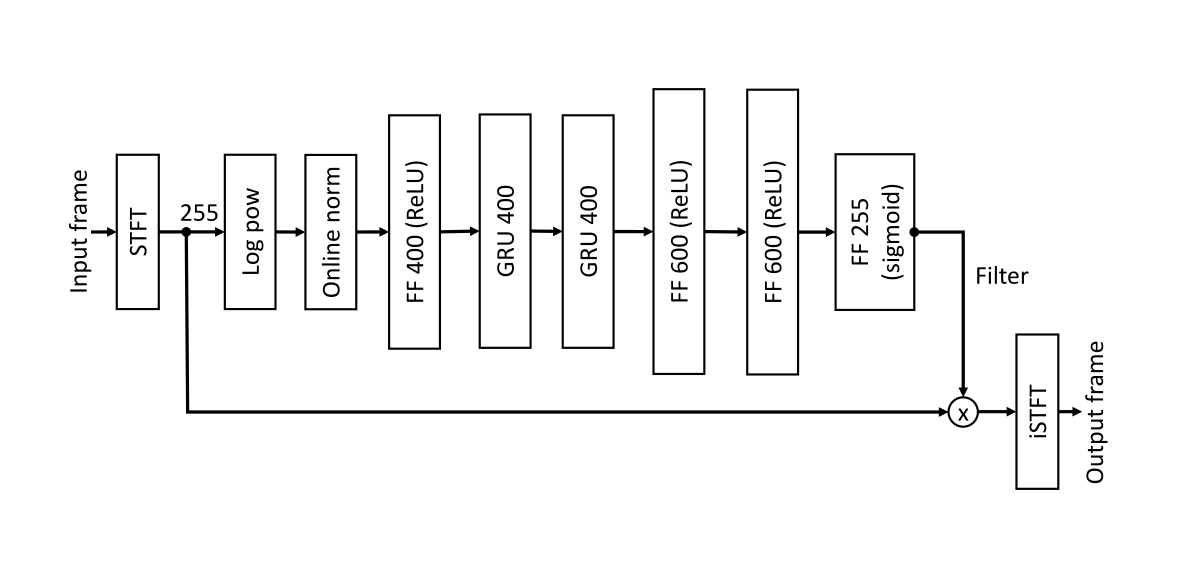
На речь влияет большое количество внешних условий. Человек может говорить громко или тихо, быстро или медленно, говорить он может в большой комнате или в маленькой, далеко от микрофона или близко к нему. Для моделирования этих более сложных условий, были применены аугментации. В частности, в данном случае, для модификации звука использовались случайные биквадратные фильтры. Благодаря применения таких аугментаций, зашумление звука наиболее приближено к реальным условиям.
Представленные результаты по качеству работы можно посмотреть в статье Data augmentation and loss normalization for deep noise suppression. Построенная модель имеет хорошие показатели для различных типов шума.
Конвертация модели в OpenVINO
При работе с нашей моделью мы использовали OpenVINO (Open Visual Inference & Neural Network Optimization) - продукт, разрабатываемый компанией Intel. Как видно из названия, OpenVINO - это набор инструментов для исполнения и оптимизации нейронных сетей.
Существует множество фреймворков для создания и тренировки нейросетей. Для того, чтобы можно было запускать нейросети из различных фреймворков на любом интеловском железе, в составе OpenVINO есть модуль Model Optimizer.

По факту, Model Optimizer - это набор python-скриптов, которые позволяют привести нейронные сети различных форматов к некоторому универсальному представлению, называемому IR (Intermediate Representation). Это позволяет OpenVINO работать с любой нейросетью, независимо от того, из какого фреймворка она взята.
В процессе своей работы Model Optimizer также оптимизирует структуру сверточных нейронных сетей. Например, объединяя результаты сверток, заменяя слои на последовательность линейных операций и т.д.

В последнее время, с появлением API, в Model Optimizer проводится все меньше оптимизаций, и основная его работа сводится к конвертации моделей без каких-либо серьезных изменений.
Конвертация в IR-представление различается для моделей из Open Model Zoo и других моделей. Open Model Zoo – репозиторий глубоких нейросетевых моделей, содержащий большое количество обученных моделей, которые могут исполняться при помощи OpenVINO. Данный репозиторий хранит не только модели, но и параметры для конвертации моделей из разных фреймворков в промежуточный формат OpenVINO.
Для конвертации моделей, загруженных из Open Model Zoo, нужно воспользоваться инструментом Model Optimizer и входящим в него скриптом converter.py. Данный модуль имеет доступ к параметрам конвертации моделей из зоопарка моделей.
Консольная команда для конвертации загруженной модели:
python converter.py --name <имя модели> --download_dir <путь до папки, в которую скачали модель>
Чтобы сконвертировать собственную модель, необходимо использовать скрипт mo.py с дополнительными параметрами:
python mo.py --input_model <путь до модели> --output_dir <путь до папки, в которую поместить конвертированную модель> --input_shape <размеры входа модели>
Для конвертации нашей ONNX модели в формат OpenVINO (в Windows) вышеприведенная команда выглядит так:
python mo.py --input_model <путь до папки с моделью>\nsnet2-20ms-baseline.onnx -output_dir <путь до папки, в которую поместить конвертированную модель> --input_shape [1, 1000, 161]
где 1 - количество каналов, 1000 - временных интервалов, 161 - частот.
Также, можно указать больше дополнительных параметров для удобства. Весь список возможных параметров можно посмотреть командой:
python mo.py --help
Отличие converter.py от mo.py лишь в том, что converter.py использует параметры для конвертации из описания модели в Open Model Zoo и передает их в mo.py
Надо отметить, что проблема шумоподавления до сих пор не решена полностью. Методике улучшения речи с помощью нейронных сетей в последнее время уделяется огромное внимание как в научных исследованиях, так и в коммерческих приложениях. Одним из важнейших преимуществ использования нейронных сетей для подавления шума является то, что они способны очищать звук от нестационарных шумов. Ранее известные подходы не позволяли этого сделать.
Нейросети не идеальны и избавиться абсолютно ото всех шумов не представляется возможным. Однако, представленная модель показала хорошие результаты в очистке речи в “домашних” условиях.

