
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Переходи на Linux, в частности я работаю на xUbuntu 20.04. Там намного экономней расходуются ресурсы. Проблему, что вы описываете не так ощущается. На простеньком целерончике данная система работает вероятно быстрее и отзывчивее, чем Винда на мощном железе с внешней видеокартой!
Вполне проявляется, достаточно попробовать собрать любой опенсоурс проект, он тут же потянет к себе миллиарды таких же опенсорсных библиотек. Из которых многие нужны только ради одной двух функций.
А та же винда 10 у меня работает на 12 летнем деле и ей нормально )
Зачем собрать опенсорс проект, если все можно поставить из готовых пакетов?
"он тут же потянет к себе миллиарды таких же опенсорсных библиотек" давайте на примере разберем, что именно вы собираете, и что у вас там подтягиватся под Linux?
А в готовом пакете бинарники, простите, собраны из чего? Не из такого же сонма инклюдов, на уровне исходников, а в скомпилированном виде всё равно тянущие зависимости от внешних бинарников от прочих библиотек? И всё это прыгает по экспоненте сall-ов. Если бы не SSD, доступная оперативка, и аппаратные инструкции в процессорах и их многопоточность, работа компьютеров под управлением любой современной ОС была бы печальным зрелищем.
По крайней мере в deb-пакете можно поставить зависимость, и эта библиотека не будет дублироваться для всех, кому она нужна.
На других системах тот же ICU системный так просто не заиспользуешь, и люди тянут свой, а это 30 МиБ только ресурсов (можно собрать урезанные для части локалей, но всё же), не считая мегабайтов самого кода. Потом curl (полмегабайта), openssl (более мегабайта), libpng и прочие аналогичные, zlib, OpenAL...
И ведь всё это не будешь самостоятельно писать (и лучше и не надо, без того же ICU почти наверняка локализация будет неправильной).
По крайней мере в deb-пакете можно поставить зависимость, и эта библиотека не будет дублироваться для всех, кому она нужна.
И сразу получаем DLL Hell в полный рост.
DLL hell — это всё же windows-специфичная проблема. Ад зависимостей может существовать и в linux'е, но для библиотек как правило всё хорошо. Да и разные мажорные версии утилит обычно могут быть установлены одновременно (тот же python).
для библиотек как правило всё хорошо
2 разные версии openssl, или libjpeg без танцев с бубном я бы не ставил.
Прямо сейчас:
dev-libs/openssl-1.1.1o - для современных приложений
dev-libs/openssl-compat-1.0.2u-r2 для старья. после окончательного перехода старья на новые либы (или выпиливания оного в пользу более нового функционального аналога) compat версия с очередным обновлением будет выпилена из системы. C libjpeg чуть иначе, но в целом ровно то же самое.
Установка штатная, танцев с бубном не наблюдается, обновление централизованное и штатное. Посчитаем сколько версий libjpeg в венде, проследим как, когда и чем они обновляются?
Поясняю. Прямо сейчас (на тот момент) в системе стояли две библиотеки, старая и новая. С которыми слинкован прочий установленный софт. Ну собственно старую я поставил не из любви к искусству, её притащил по зависимостям слинкованный с ней софт. Т.е. ответ на ваш вопрос "Что будет" таков: софт стоит и работает.
А что с ними должно быть, если это разные файлы?
Этот давно не погружался в особенности сишной сборки, но разве пространство экспорта не индивидуальное у каждой библиотеки, и разве в момент динамического связывания lib1.echo() и lib2.echo() — не разные функции и не будут подгружены по разным адресам в пространстве импорта?
Не говоря уже о том, что библиотеки и не должны экспортировать все свои импорты.
DLL hell — это всё же windows-специфичная проблема
Только из-за аббревиатуры DLL, а не из-за принципа работы.
не нужно далеко ходить, посмотрите на NPM и Composer зависимости любого сайта.
Раньше из всего JS было достаточно JQuery, а сейчас ? npm папка запросто может достигать гигабайтов, а потом от слишком большого количества файлов глючить и падать сборщик, прекрасно.
По крайней мере в deb-пакете можно поставить зависимость, и эта библиотека не будет дублироваться для всех, кому она нужнаНу да, если бы…
Если вам не нравится Snap. Дело буквально двух команд.
Вот статья.
https://losst.ru/kak-udalit-snap-paket
Лично я сам удаляю на слабых машинах.
В snap насамом деле есть и плюсы и минусы. С одной стороны это контейнеризация, примерно как в docker. С другой стороны большее потребление ресурсов в совокупности с накладными расходами.
Самое главное, что это как опция, хочешь пользушься, хочешь отключаешь.
Ну а что разработчики должны, вместо того чтобы использовать, например, libpng, писать свою собственную альтернативу этой библиотеки и юзать её? Так проблему это тоже не решит, просто вместо libpng будет свой велосипед.
Только у автора скорее проблема с bloated приложениями на фреймворках типа Electron, а не из-за dll'ок. Так-то это нормально использовать для определённой функции какую-то библиотеку, реализующую конкретную функцию.
Хе-хе, PNG стандарт, пишите сколько хотите реализаций, а вот этот libpng для ленивых. Что, не хотите писать? Так может и PNG этот не особо нужен? Векторная графика покрасивше будет. Хотя нет, ASCII графика ещё лучше! И проще! И поддерживать не надо! Хотя нет, семисегментный индикатор куда больше полезной информации показывает! Зачем усложнять когда можно упростить?
Про PNG как раз случай был. Надо по png-картинке было понять её размер, да ещё всё мультиплатформенно сделать. Разработчик начал было искать библиотеки для парсинга PNG (ImageMagick отлично справляется с задачей), но оказалось - что по стандарту - надо прочитать несколько байтиков из заголовка файла.
Вот что лучше - тянуть огромную библиотеку, следить за ней, обновлять, или написать свой велосипед на 3 строчки кода?
Вот что лучше
Ну, если речь шла исключительно о png, никакие другие форматы обрабатывать не потребуется никогда в жизни, и ничего кроме размера этой пнгшки никогда не понадобится — то выбор очевиден.
Кто даст такие гарантии?
А в реальности нужно извлекать информацию из полдюжины форматов и в перспективе добавить к ним поддержку еще нескольких, иметь дело с экзотическими (вплоть до невалидности по спекам, но читаемости реальным железом/софтом) вариациями, поврежденными файлами и прочим.
А, тем временем, в соседнем отделе другой такой же гений пишет в соседний модуль того же приложения свою реализацию ресайзера с самописными вариациями бикубического фильтра и lancroz. На чистом lua.
Никто.
И будет в итоге развесистая петрушка из либы для апскейла, либы для даунскейла, либы для загрузки/сохранения (этот не слишком оптимистичен, не? одной же хватит на все случаи жизни? ладно, возьмем по одной на формат) и кучка костылей для жонглирования байтами.
Потому что задача никогда не появляется одна, но если кушайц слона по слишком маленьким частям, то выйдет monkey patching в виде годовых колец.
И когда дойдет, что надо было сразу прикручивать imagemack — придется рефакторить вообще все.
Ну, если речь шла исключительно о png, никакие другие форматы обрабатывать не потребуется никогда в жизни, и ничего кроме размера этой пнгшки никогда не понадобится — то выбор очевиден.
Ну, задача была именно для png и других форматов не планировалось. И даже для вас "очевидный" вариант напрямую взять размер из png, для большинства разработчиков - как раз совсем неочевидный (картинки - это какая-то магия, там что-то сложно и алгоритмы какие-то) и им гораздо проще затащить внешнюю библиотеку.
А, тем временем, в соседнем отделе другой такой же гений пишет в соседний модуль того же приложения свою реализацию ресайзера с самописными вариациями
Было дело, был у меня алгоритм SuperOboyeUlutshatel, который пытался убрать шакаленные артефакты джпега (зная, что он использует квадраты 8x8 и обрабатывая только эти участки). Хотя это больше по фану было и не продакшен, просто вспомнилось в рамках обсуждения.
Ну, про сверхузкоспециализированный случай, когда ничего никуда никогда не растет и не дорабатывается, каджит, собственно, там же и написал.
Но такой случай — пекулярный, из выборки такие выбрасываются для повышения репрезентативности.
Это значит, что он не подходит ни как мерило, ни даже как пример.
Но узнать о таком курьезе забавно и поучительно, спасибо, что поделились.
Хотя это больше по фану было и не продакшен
Для себя исследовать какую-то область — всегда полезно ) Даже если получившееся решение непрактично, оно дает опыт.
lua разный бывает. На 4-ом пишет, или на 5-ом, который до сих пор не закончен?
А еще с jit'ом или без.
Но simd все равно быстрее в разы, а знание математики помогает дополнительно оптимизировать задачу. Одиночке будет крайне сложно переплюнуть труд сотен.
Особенно если настолько некопенгаен, что пилит свой велосипед, вместо того, чтобы взять готовую и отлаженную библиотеку, не имея против того серьезных возражений.
Вы так говорите "следить за ней, обновлять" как будто это задача вашего приложения. И как будто свой велосипед на три строчки кода освобождает от этой проблемы. Вы же со своими тремя строчками кода будете следить за форматом PNG? И обновлять планируете?
Миллиарды опенсорс библиотек это хорошо. Главное чтобы LTO работало.
Пусть в мире будет одна Идеальная Быстрая сортировка, Идеальный способ открыть файл, Идеальный способ отправить емейл через SMTP. И пусть этот идеальный способ экспортируется и распространяется как библиотека. Это приводит к тысячам библиотек? Да, и что плохого? Это неприятие велосипедов возведенное в абсолют. Это прекрасное будущее где ты создаешь только код который никто до тебя в мире ещё не написал, а потом им пользуются миллионы других разработчиков по всему миру.
Немного утопично, но это куда ближе к хорошему чем "если это реализовывать меньше 80 часов то напишем свой велосипед".
Для этого в опенсорсе должна быть модерация и голосование, какой пакет принять за основной. А потом основная библиотека перестаёт поддерживаться, появляются форки, и… ну вы поняли, было 11 стандартов, решили стандартизировать их все - теперь 12 стандартов.
А ещё основные библиотеки точно так же жиреют со временем в попытках сохранить обратную совместимость и вообще в экономии времени на оптимизацию, так что легковесные аналоги появляются и есть буквально для всего. И это не плохо, это, своего рода, конкуренция (хотя в опенсорсе… конкуренция?), но ни о каком "едином стандарте" речи быть не может.
А ещё мейнтейнерское "я так вижу, хотите свою фичу в моём пакете - делайте форк".
А ещё… продолжать можно долго.
Для этого в опенсорсе должна быть модерация и голосование, какой пакет принять за основной.
И тут же возникает проблема на уровне, где система для опенсорса с голосованием за форки порождает альтернативную площадку с «легковесной» подачей и быстрой доставкой фич без голосования. И вот у нас и тут становится минимум 2 стандарта «правильной» разработки опенсорса.
Идеальная Быстрая сортировка?
У вас может быть задача отсортировать данные, которые помещаются в память, а может быть задача про данные, которые не помещаются в память, надо тогда работать с диском или ещё с каким-то хранилищем. И вот у нас уже две Идеальные Быстрые сортировки.
Данные которые не помещаются в паять не надо сортировать Быстрой, для этого есть другие способы. Так что это не проблема, да — кубики лего должны быть одинаковыми и хорошо сделанными.
Быстрая сортировка без обмена элементов существовать не может — это заложенно в её основе. Сравнение с несравнимых элементов — это так же не быстрая сортировка а видимо что-то типа NullQuickSort которая сначала выполняет некоторую логику (сдвигает нуллы куда-то), а потом уже сортирует оставшуюся часть нашей Идеальной Быстрой Сортировкой.
Так что как раз получается, что по опредлению такой алгоритм будет единственным, и уже поверх него можно городить доп. логику. Это и есть задача программиста. Взять готовый кубик (рабочую сортировку на множестве с определенным сравнением), и навесить на него сортировку флоатов.
Для разминки ума, кому интересно, может подумать об отвлеченной и более материальной задаче: сколько человечеству нужно узлов. Их ведь очень, очень много. И я, как простой "пользователь веревки", имею простые задачи вроде "привязать веревку к столбу прочно" или "привязать веревку к столбу и обеспечить сильный натяг". Но узлов - дохрена, и я так понимаю, что каждый из них иногда по своему хорош.
Вот мне, как человеку достаточно далекому от дел флота, альпинизма и строительства, даже полторы сотни кажутся невероятно избыточным количеством. Проблема в узости нашего кругозора. Пока мы очень узко видим задачу (узлы нужны чтобы натягивать веревку сушить белье!) - нам кажется, что нужен всего один узел, и все прочее - от лукавого. Чуть погружаемся в тему, и оказывается, нам нужен еще узел, чтобы можно было очень туго подтянуть веревку, и предыдущий тут не подходит. Погружаемся еще ниже, оказывается, нужен еще узел, который будет легко развязываться. А потом - чтобы он еще развязывался удаленно (просто дернув за конец). Потом узел, который можно завязать на середине веревки, не имея доступных концов.
Наверное, если я подумаю еще - то еще 3-4 потребности в узлах напишу, а про остальные даже и вообразить не смогу, зачем они нужны.
Ой вы навыдумывали. Узел вам нужен один - шнурки завязать.
Всю жизнь завязываю одним узлом, хоть в темноте за 2 секунды завязываю, а как они там называются мне без разницы. А у вас в голове много мусора, на простые действия десяток вариантов, и никаких действий в итоге, вся энергия в сотрясание и нагрев воздуха идёт.
Ну так будьте проще. У меня всё просто, у вас в том же месте какие-то сложности. Я помню как меня родители учили шнурки завязывать, потом сам друга научил, и вас могу научить. А ещё вы удивитесь сколько народу на велике не умеет ездить. Только я один с десяток людей научил никому ничего не навязывая. И всё это потому что объясняю просто, а не ссылками швыряю и десятки вариантов предлагаю.
Ну и? У меня то никогда не было скользких (: У вас тоже врядли, нагуглили небось какую-то дурость. Я себе скользкими шнурками скорее пальцы порежу чем завяжу их, и избавлюсь незамедлительно от такого счастья.
Это значит только то что вам продали обувь без шнурков, а на место шнурков какую-то леску натянули под видом шнурков, и вы зачем-то мучаетесь полумерами. Я бывает в магазине лечу людей, покупающих масло, мол это такое название продукта, "Масло 60%", если перевернуть и состав посмотреть то там будет уже молочный продукт или ещё какая гадость, а 60% масла просто не существует.
Если посмотреть контекст, то как раз ровно в этом и суть: нам, не-специалистам, нужен только один узел, а вообще их придумали несколько десятков для разных нужд. Аналогично и с алгоритмами: нам достаточно одного условного QuickSort, а вообще - совсем не факт.
Сортировки нужно две - устойчивая и не устойчивая, разумеется это можно добавить аргументом по умолчанию в библиотечную сортировку, тогда да, будет всего одна, и не сильно разбирающийся будет всегда устойчивую пользовать, как более универсальную но и более медленную, а профи поднастроит под свои данные. И старый код не ляснется от внезапно возникшего аргумента функции. Но появится новая проблема - этих аргументов по умолчанию возникнет 100500 на все случаи жизни. Хоть это и не такая существенная проблема но всё же возникнет в виде комбинаторного взрыва числа возможных состояний библиотечной функции.
Сортировки нужно две - устойчивая и не устойчивая
Умножьте на 2 для начала;). Массивы и связанные списки сортируются по разному.
Ну тогда нужна некая абстрактная перестановка местами двух элементов и абстрактное сравнение этих двух элементов в некоей абстрактной структуре данных. Каждой из этих абстракций автор библиотеки может докинуть аргументы по умолчанию. Так и совместимость с не абстрактным не потеряется, если первая реализация только для массивов, и чуть поправить можно. Но суть в том что всё это должно быть реализовано автором первоначального алгоритма, а не кем-нибудь относледовано и переделано. Т.е. Первоначальная задумка должна сохраняться, и при необходимости дополняться.
А потом библиотека, подтягивающая другие библиотеки вместе с другой многоколенной библиотекой подтягиваются в сто пятую библиотеку. И вот уже экспоненциальный рост пожирания ресурсов обгоняет технологический прогресс, а еще чуть позже на неописуемой скорости врезается своей огромной массой в нерушимый потолок физических ограничений. Все, закон Мура не действует, производители больше не могут наращивать производительность на единицу процессорной площади. И придётся все переписывать заново, зато не изобретали велосипед
Для удаленки взял свой старый медиацентр. Что бы не занимать ноутбук. Athlon x4 640. Добил до 8гб + ssd. Поставил, windows 10 и lubuntu lts последнюю. Все же lubuntu побыстрее и меньший жор ОЗУ. И не так часто вижу в top'e загрузку проца под 100%. Серфинг одинаков на обоих осях.
Я бы разбил проблему на части
Разделяемые библиотеки
Разделяемые библиотеки как раз и созданы для того чтобы избежать дублицирования кода, поэтому ничего плохого в их использовании нет. Но для того чтобы этот потенциал был реализован более полно, нужно чтобы (1) их лицензия позволяла программам в системе их использование и (2) программы были собраны именно с установленными в системе версиями библиотек, а не требовали другие версии. В случае дистрибутивов Линукса, казалось бы, эти условия выполняются чаще и лучше.
Но это преимущество имеет, правда, и свои негативные стороны. Например, когда в дистрибутиве десятки тысяч программных пакетов, обновление программы имеющей сотни зависимостей становится достаточно сложным, особенно для программ с несвободной лицензией. И чтобы решить эту проблему придумали всякие snap и flatpak, что полностью нивелирует преимущества разделяемых библиотек, то есть как раз в области, в которой дистрибутивы Линукс могут проявить себя лучше.
Умножение системных процессов.
В системах на основе Линукс, как и в Виндосе множатся и плодятся системные процессы. Причём почему-то с каждой новой версией они становятся всё более прожорливыми, пожирая память и процессор. Я уже смирился, что даже в Линуксе какой-то демон, ответственный за вывод звука иногда может есть процессорное время даже когда никакого звука в системе не проигрывается. Конечно, это пока это не дошло до крайностей, описанных в статье, но надо признать, тенденция в Линуксе такая же как и в Виндос.
Раздутые приложения-монстры
Некоторые приложения со временем растут, пока не превращаются в монстров которые содержат в себе ещё одну собственную операционную систему (иногда две или больше). Кажется что в конце-концов они должны погибнуть под тоннами собственного неподдерживаемого кода. Но они почему-то никак не погибают. Яркий пример - браузеры.
Приложения на электроне
Эта беда проникла как в Виндос, так и в Линукс и здесь Линукс ничем не отличается от Виндос. Это просто фабрика монстров.
Список можно продолжать. Но ясно что беда затронула и Виндос и Линукс.
Я не программист, потому интересуюсь, а зачем скачивать всю библиотеку? Почему бы не скачать те самые 1-2 функции с меткой к какой библиотеке они принадлежат?
Потому что библиотека — минимальный уровень деления законченного и готового к распространению кода.
Функция может использовать другие функции, которые даже не будут экспортироваться. Портянка констант может составлять существенную часть библиотеки. Имена функций в разных библиотеках могут совпадать. Она может экспортировать вообще не функции, а интерфейсы.
Библиотека объединяет это все в одну логическую единицу, уменьшая сложность управления.
Не правильно выразился, так не делается потому что это технически сложно или потому что так просто никто не делает и нет готовых решений? Исключая описанные вами случаи когда действительно придется качать всю библиотеку. Условно говоря чтоб с готовым продуктом шли не все библиотеки целиком, а только нужные в данном случае части, чтоб не было такого чтоб из библиотеки идущей с продуктом используется процентов 10. Тот файл с тем же именем, но облегченная версия, внутри которого есть список того что было вырезано. В таком случае это не решит проблему , но облегчит ее.
В компилируемых языках при статической линковке библиотеки из неё выбираются только нужные элементы. При динамической линковке библиотека (.so, .dll) одна для всех и ничего из неё удалить невозможно.
В интерпретируемых языках также бывают сборщики проектов (например, gulp или webpack для JS). Они также умеют выбирать только используемые элементы модулей и библиотек.
Господин не прав. Днесь пытался найти на ноутбук HP6110 с 32-разрядным процессором вменяемое ПО, при наличии 2-х гигов памяти. К удивлению своему - НИЧЕГО! Ничего, что бы вменяемо работало с Интернетом. Даже маленький Alpine - и тот уже не торт.
Пробовал множество линуксов.
Однако старая версия Runtu движется быстро и хорошо - прекрасна во всех отношениях - но не открывает современные сайты, и поэтому бесполезна...
при наличии 2-х гигов памяти
Мне кажется тут дело немножко в другом.
Попробуйте firefox + umatrix.
Вы про Alpine, а я про хUbuntu. У xUbuntu сообщество в сотни раз больше.
"Пробовал множество линуксов." Зачем пробовать, поставьте один вроде xUbuntu, и работайте. Хватит пробовать. Я вот запустил и работаю, уже лет 10
А чем Вам ОСь поможет то? Проблема в том, что сами сайты состоят из говнокода чуть более чем полностью и одна страница "весит" сотню мегабайт. Это на стороне сервера оптимизировать надо, иначе никак.
Потому что ОС, это основа всего. Если сама ОС вроде Виндовс, жрет памяти немеряно, то что останется на все остальное?
В Linux есть дистрибутивы например xUbuntu, которые очень легкие, и работают одинакого быстро и на простом железе и на хорошем.
Еще раз. Если с сервера в браузер приезжает жирный js-код, который выполняется на вашем процессоре, то не очень принципиально, сколько ест система, обычно это единицы процентов ресурсов процессора.
XUbuntu жрёт 600-1000 МБ просто загрузившись, для хоть какой-то работы ей надо 2 ГБ. WinNT Workstation запускалась и работала на 64 МБ, Win2K на 128, WinXP на 256. Ну, ОК, это не совсем честно, потому что NT/2K/XP были 32-битные, банально для CALL по полному адресу надо адрес 64-битный, но разница даже с WinXP в 8 раз. Справедливости ради - рабочая станция на Linux всё-таки больше условных 1-2 ГБ "сразу после загрузки" не съедает (тайловые ВМ - 0,5, голый KDE/xfce - 0,7-0,9, гном с навесами 1,2), а Win10/11 - запросто 3-4.
Ну и, да, согласен с @hyperwolf- основные ресурсы съедаются не голой машиной, а приложениями на ней. Браузер, IDEA, VSCode и куча других приложений съедают примерно одинаково (много) почти независимо от ОС. Да вот пример прямо в углу монитора у меня: Jetbrains Toolbox. Ёлы-палы, это же приложеньице для загрузки и обновления IDE. Оно съедает 200-500 МБ оперативной памяти. Штоа? Как это? Зачем? Ладно, у меня 48 ГБ в одной машине и 128 ГБ в другой и я почти смирился с тулбоксом, но всё-таки, я всё еще помню время, когда на сервере СУБД (СУБД, Карл!) в моей организации было меньше памяти, чем жрёт эта иконка в трее (то, что у тулбокса нет CLI раздражает больше).
Win10/11 — запросто 3-4
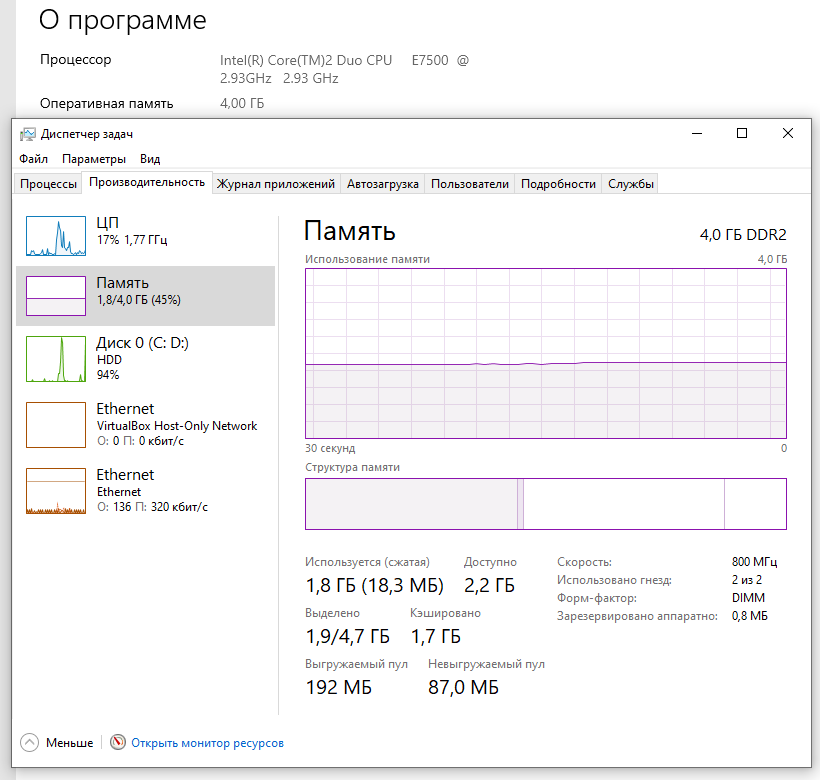
(впрочем, работать на этом компьютере всё равно немножко грустно)
Продукты JetBrains невероятно прожорливы. Ещё пару-тройку лет назад пересадили компанию на Rider при моем же участии. А на днях мне пришлось работать на докрымском ноуте. Райдер не смог. Он сожрал весь проц, разогрел его и дико тормозил на простом вводе текста. Запустил VisualStudio и на том же проекте смог комфортно работать. Был удивлен и много думал о том, стоит ли продлять лицензии.
xUbuntu есть 400 мегабайт после старта!
"600-1000 МБ" Откуда вы такие цифры получили? И где вы нашли WinNT Workstation? Давайте с Windows 10 сравним, или с Windows 11.
"WinNT Workstation" - операционка которой уже больше 10 лет не существует, и на любом железе современном вы даже не запустите.
В таком случае нужен дистр минимально потребляющий ОЗУ. Что бы по серфинг оставить максимальное возможное количество памяти из 2-ух гигов.
У меня mint (xfce) вполне норм работает на eeePC c 2 Gb и 900 МГц "целероне", тянет офис и браузер, даже ютубчик в низком качестве при желании можно посмотреть. Разумеется я им не пользуюсь в повседневной практике, нет смысла никакого. Но как читалка, компактная печатная машинка, аудиоплеер, вполне норм.
Пробовал множество линуксов.
А какой был графический интерфейс? Я как-то разбирался, как ускорить работу Linux на старом компьютере, и обнаружил, что очень много ресурсов забирал на себя tracker, программа для индексации файлов. Причём вроде он работал даже если я использовал другое окружение рабочего стола. То есть, по сути компьютер работал бы быстрее, если бы я при установке просто убрал галочку напротив GNOME. Но, повторюсь, это касалось довольно старого компьютера, по логике вещей tracker нужен для того, чтобы ускорить работу (чтобы поиск был быстрее).
Мне кажется в каком-то месте маркетолог у нас сменил и программиста и инженера поэтому размеры приложений выросли в сотни раз когда калькулятор может весить сто мегабайт, а игра больше ста гигабайт. А все потому что медленный софт подгоняет железо и наоборот быстрое железо позволяет забить на оптимизацию, все ради того чтобы продавать, продавать и продавать без учёта ресурсов. Одно потребление так же ведет индустрию в тупик.
Для эксперимента советую antix. Возможно взлетит.
Возможно автору нравится копаться в старом железе. И пытаться их восстановить для текущих задач. Почему нет:)
Не такая уж и рухлядь. Смотрите на производительность одного ядра.
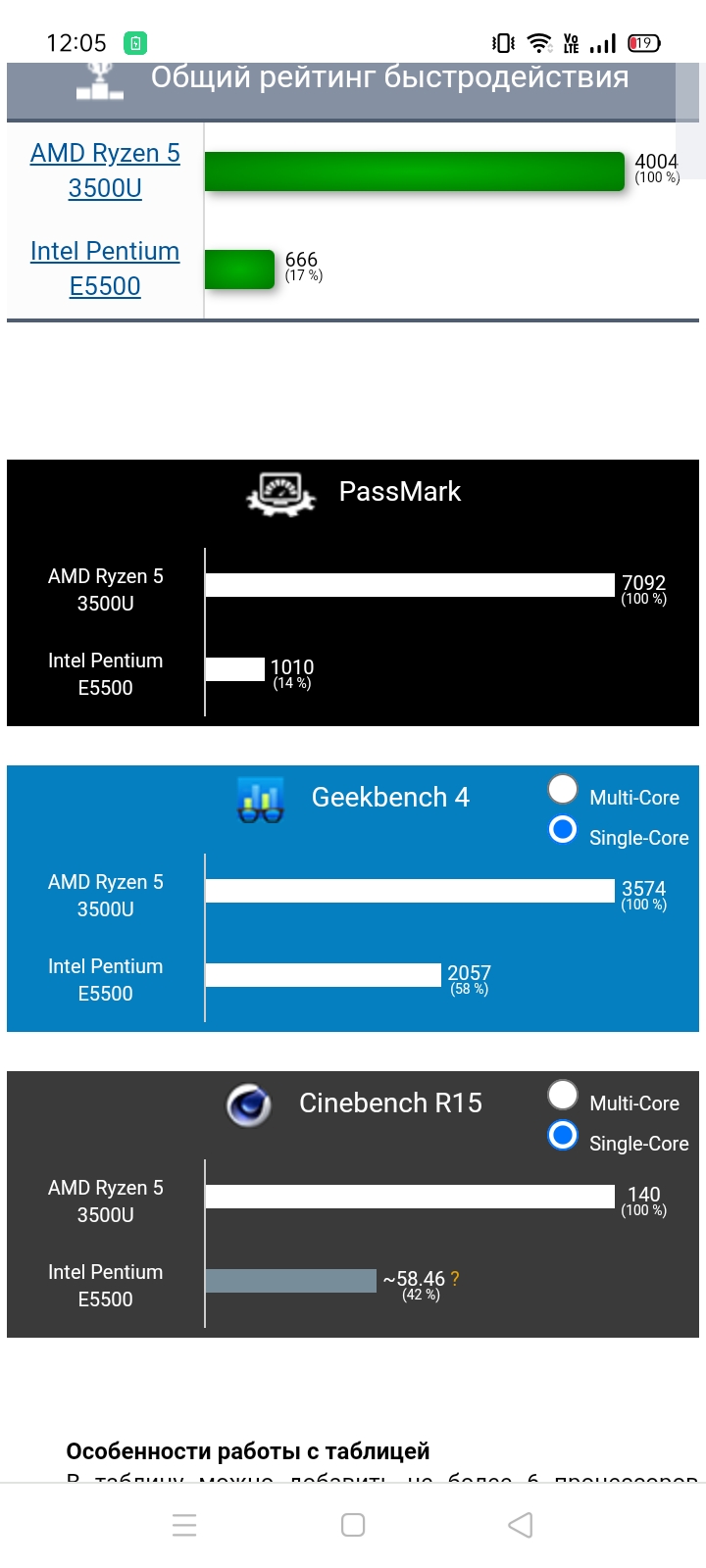
Говорили о проце pentium m. Но если сравнивать с десктопным e5500 производительность вполне себе. Но для серфинга будет боль.
Не соглашусь насчёт экономного расходования ресурсов. Отличие Linux только в том, что там принято ставить зависимости общими пакетами, а не тащить их каждый раз с собой. Ну да, небольшая экономия места на диске, но память всё так же будет забиваться.
Также добавлю тенденцию пихать всё в snap и в docker.
Предлагаю сравнить скрины по количеству забитой и свободной памяти? На реальных примерах.
На примерах чего именно?

Вообще, меня больше напрягает Telegram, который аж больше 1 гига жрёт.
Не знаю, что за дистрибутив а у меня вот так. И это xUbuntu. Сама ОС, практически ничего не ест, и отзывы мгновенные. Причем куча свободной памяти, и работает на Целероне
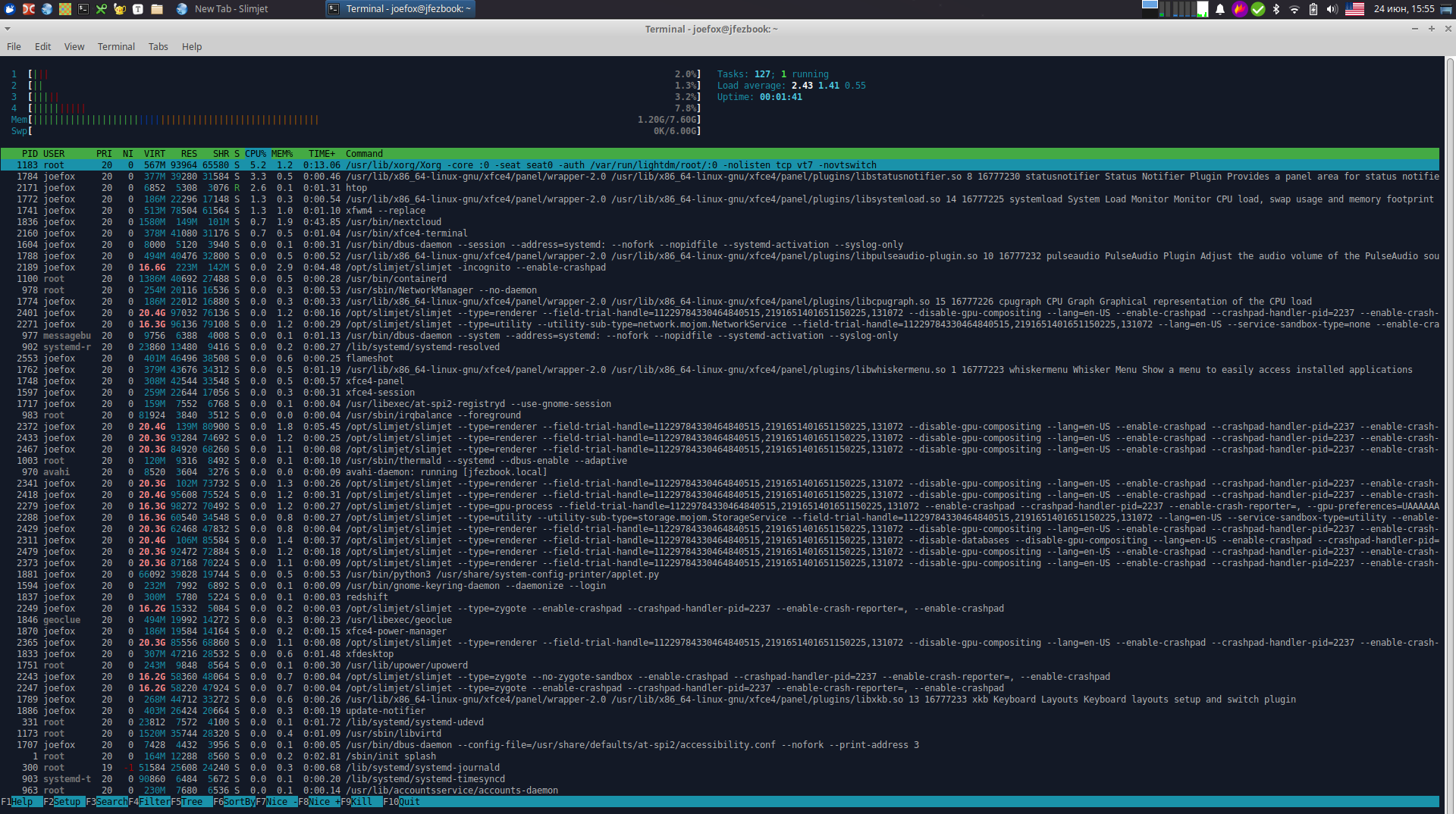
.
Все верно. Легкий дистрибутив и куча свободных ресурсов. Не перегруженность графиков. Вот основа быстрой и оптимальной системы.
У меня i7, 32 оперативы и 2 ssd.На одном стоит минт с синнамоном, на втором в дуалбуте вин 10. Так вот, вин 10 по сравнению с линухом тормозит. Тормозит безбожно. После загрузки в нее минут 5 надо погулять, чтобы она там что-то себе пошуршала и начала, наконец, хоть как-то работать. Но даже после такой паузы работать в винде гораздо менее комфортно. Я даже не могу сказать что конкретно не так, просто какие-то раздражающие микрофризы, которые в целом создают ощущение, что "все тормозит" по сравнению с линухом. Например, запустил простую программу, а она не мгновенно запустилась, а через несколько секунд и т.д, Железо, я напоминаю, одно и тоже и совсем не слабое.
Попробуйте отключить антивирус.
Я от гнома отказался в самом начале перехода на linux. Мне нравится lxqt. Жручесть меньше. Скорость выше.
Согласен. Жирный плюс, что можно поставить любую DE.
Микрофризы в Linux у тех, кто его запускается чтобы посмотреть через виртуальную машину из другой Операционной системы :)
Но даже если так. поставьте в виртулке xUbuntu. Даже в виртуалке думаю фризов вы не заметите. Что говорить, про реальную установку, космос!
У меня i7, 32 оперативы и 2 ssd
На одном стоит минт с синнамоном, на втором в дуалбуте вин 10. Так вот, вин 10 по сравнению с линухом тормозит. Тормозит безбожно. После загрузки в нее минут 5 надо погулять, чтобы она там что-то себе пошуршала и начала, наконец, хоть как-то работать.
У вас какой-то неправильный ssd видимо, или может ОЗУ. Тоже i7, тоже 2ssd, и тоже 32 гига озу. 17 секунд и уже можно пользоваться. Где вы 5 минут умудрились найти? У меня даже виртуальная машина образ которой на HDD стоит, грузится минуты 2.
Скиньте, мы посмотрим.
Там ещё аптайм чуть больше минуты — может, не всё прогрузилось :)
Не, ну если я вместо KDE поставлю Xfce4, памяти тоже побольше свободной будет.
Но смысл?
Смысл примерно тот о чем пишут в статье. Компактный дистрибутив, компактное ПО, вот один из идеальных примеров, того как должен выглядеть софт, и прекрасно работать даже на слабом железе. Не потреблять излишнее количество ресурсов, память ГПУ и т.д.
Ради интереса перегрузился в Xfce. Потребление оперативной памяти снизилось на полгига, потребление видеопамяти же, наоборот, выросло на полгига. Интересно, почему?
Thunderbird = 497 Мб, верните мой 2007 The bat! :)
SSL/TLS.
Без шифрования ничего нынче не работает, хотя оно и нахрен не сдалось, ибо кому надо тевсе равно имеют доступ ко всему что передается и хранится.
Давайте я вам пример приведу, из той же категории. Claws Mail - легковесный почтовик. Не требует ресурсы. До сих пор поддерживается и обновляется, работает под Linux, и не только.
И как вы на нем будете открывать динамические письма с кнопками и анимацией?
Кнопкой "Send to Trash", ибо ничего полезного в таких письмах по определению не приходит :-)
А вообще, он умеет в браузере HTML-письма открывать, что зачастую куда удобнее (и безопаснее), чем в почтовике.
А вы уверены, что браузер поддерживает динамические письма?
А что в них может присутствовать, кроме тройки HTML+CSS+JS? Вопрос без подвоха, я действительно исходил из того, что тело письма - это всегда не более чем веб-страница.
https://developers.google.com/gmail/ampemail/supported-platforms
Ну и, если уж на то пошло, кто может быть уверен, что почтовый клиент будет поддерживать ту или иную проприетарную технологию (если, конечно, это не клиент от владельцев технологии)?
Не туда смотрите, 497М — это только shared mem, а есть ещё resident на 1082М.
И да, Thunderbird — это, по сути, браузер.
Предлагаю обмениваться не на словах, а прямо скринами с монитором ресурсов из вашей операционной системы, где в целом видно сколько памяти всего, сколько ест операционная система, сколько все остальное вроде Оутлуга. и будем сравнивать.
"несущественно, даже Windows 11" - это 3 гигабайта, несущественно? или сколько.
Вот xUbuntu ест 400 мегабайт после старта. А дальше навешиваются приложуши. Давайте сравним кто больше ресурсов ест.
Я предлагаю фактами обмениваться!
Вот xUbuntu ест 400 мегабайт после старта. А дальше навешиваются приложуши.
Я предлагаю фактами обмениваться!
Это видимо ошибка какая-то. Наблюдал как память утекает в телеграм в Arch'е. В винде прямо сейчас - давно уже включенный телеграм 28mb занимает

Виндовый диспетчер задач показывает какую-то странную память, по ощущениям сильно далёкую от «реальности». Возможно, лучше смотреть какой-нибудь «рабочий набор» (но не уверен, там всё сложно)
Действительно, посмотрел в Process Hacker. 160Mb при запуске. Сразу пошёл проверять размер exe - 112Mb)
Диспетчер может и что-то не то показывает, но по процентам стабильно после 85% занятой памяти всё начинает тормозить(Диск hdd, 4Гб RAM)
Хотя конечно понятно было что он что-то не так показывает. Память кончалась быстрее, т.е. занято было всегда больше чем сумма занятой памяти которую он показывал, причём ещё до того как приложение подгружало данные из сети. Т.е. например до токо как в той же телеге я нажимал что-либо вообще
Но в линуксе что-то странное с телеграмом, похоже на утечку памяти. Я там просто листал текстовые сообщения и у меня htop всё больше показывал(прям мегабайтами росло)
Так конечно просто если чат с картинками листать то тоже расти будет. Не удивительно что можно хоть до 1Гб догнать. Не знаю будет ли он со временем их сжимать и/или на диск скидывать
Проверил. Полистал огромный чат в том числе с картинками, рядом поставил Process Hacker. Занятая RAM растёт медленно, временами уменшаясь.
Похоже в линуксе таки у него утечка.
При прокрутке чата вполне ожидаемо появляется нагрузка I/O, так что телега вполне хорошо оптимизирована. Немного печально что ей при запуске тоже надо 160Mb
Ну, вот более подробные сведения:
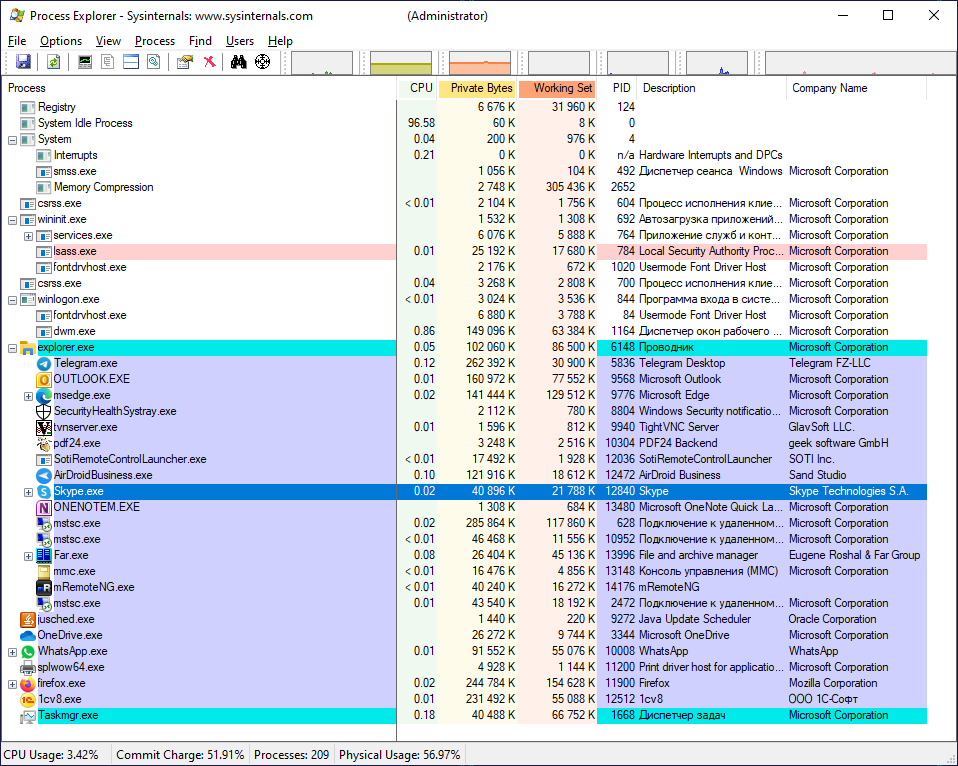
А вы ~~на шкаф~~ залезьте на пару десятков каналов с картинками и видосиками. Он не только памяти нажрётся, но и крашнуться может. ;)
Нет, он не включает страницы из свопа. У меня был случай, когда у процесса был слишком низкий приоритет, поэтому казалось, что мало памяти используется, а на самом деле было много, но всё в свопе (при том, что физическая память была свободна).
Да, поэтому надо смотреть на "Private Bytes".
Да, но PeakWorkingSet64 есть, а PeakPrivateMemorySize64 нет. https://docs.microsoft.com/en-us/dotnet/api/system.diagnostics.process.privatememorysize64?view=net-6.0
меня больше напрягает Telegram, который аж больше 1 гига жрёт.
Специфика аллокатора в glibc, если верить этому. На других ОС такой проблемы нет.
Как Ваш Telegram смог столько сожрать?!?!

Оперативки "итого" 8 ГиБ, занято менее трети, запущено 2 браузера (FF и Edge) с парой десятков вкладок в каждом (в одной из них данный комментарий набираю), почтовый клиент (да, Outlook у меня немолод, но он мне нравится больше более новых), WhatsApp, Telegram, Skype (прости, господи), играет Я.Музыка, 1С, встроенный антивирус и ещё куча всякого хлама...
Проблема с аллокацией памяти в Linux:
https://www.opennet.ru/tips/3184_telegram_memory_debug.shtml
Кажется у нас еще один конкурент Твиттера, хотя по функционалу он не очень далеко ушел от той же аськи. Видимо программисты там создают иллюзию деятельности.

Ну давайте сравним. На 10 летнем десктопе дома win10 сильно меньше кушает. Прекратите верить, что десктопный линукс с гуями - это некое чудо, которое не есть ресурсы.
Это Гном небось 20ГБ отъел? У меня вон KDE Neon с двумя месяцами аптайма гораздо лучше себя чувствует, ресурсы отжирают в основном браузеры и кое какие проги на Electron. Сами кеды при этом потребляют вместе с системой где-то полгига всего.

Мне кажется вы тут, что то под шаманили )) Чтобы нам показать фейк. Список процессов бы показали и отсортировали по потреблению.
Вот как у меня на другой машине.
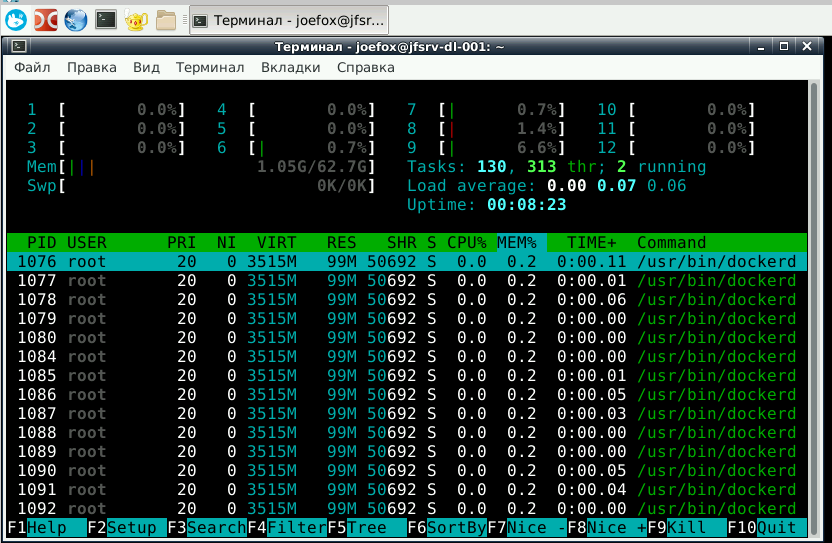
Это еще при условии, что у меня куча докер контейнеров уже запущено и работает.
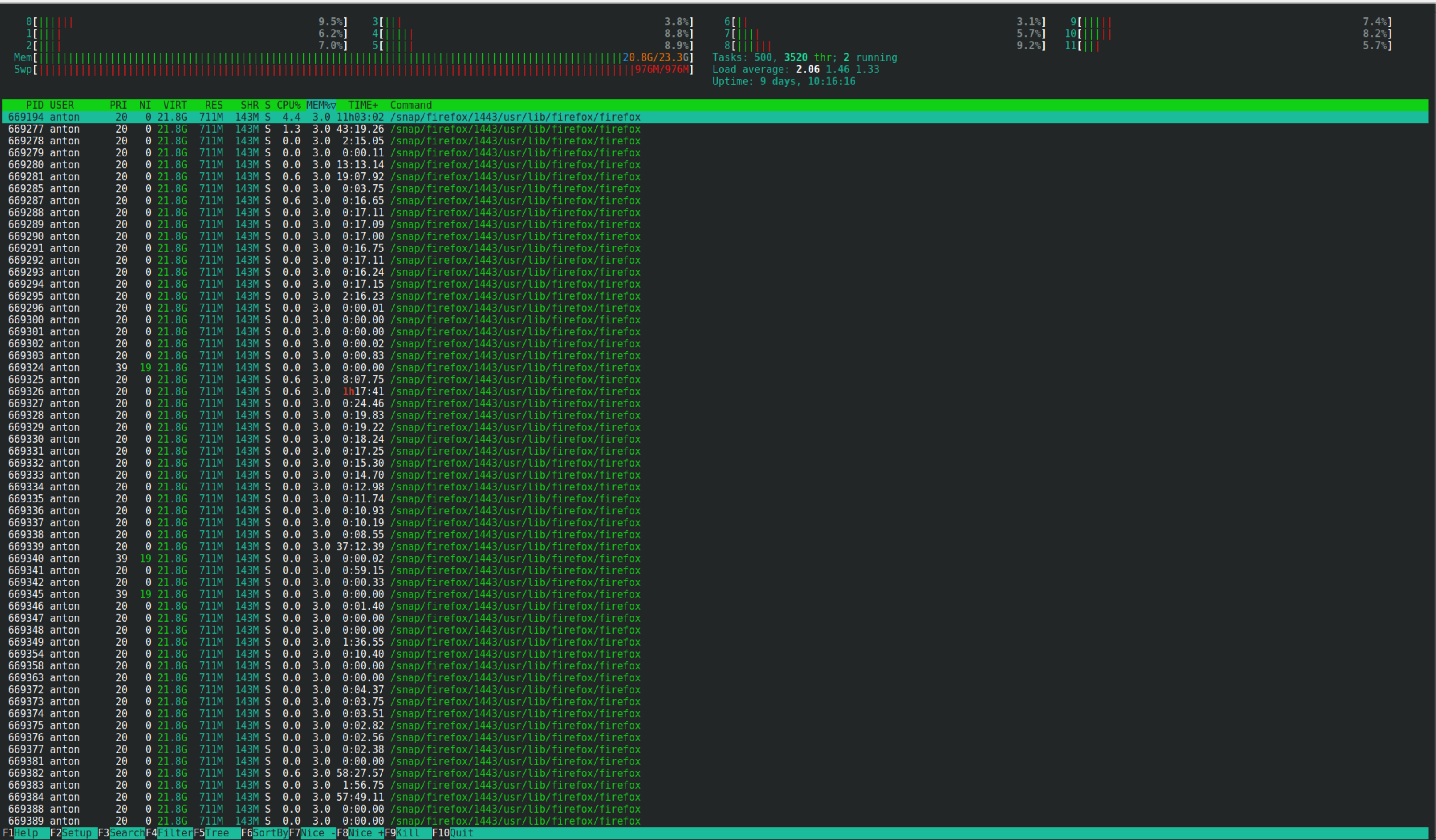
Вот, пожалуйста, старый добрый браузер. Там еще миникуб крутится где-то, докер, постгря, но браузеры нынче жутко жрущие до памяти. И да, тут не 100500 вкладок, но штук 30 будет.
Ну да, небольшая экономия места на диске, но память всё так же будет забиваться.
А можно поподробнее раскрыть идею? Ведь если используется одна и та же разделяемая библиотека, то код ее и все константы будут разделяться между всеми приложениями, использующими эту библиотеку. То есть допустим у нас запущено 20 приложений KDE, каждое из которых используют 50 мегабайтный Qt с кучей плагинов, если бы каждое приложение использовало бы свою копию Qt на полную, то в результате у нас ~1ГБ оперативки ушел бы на всю эту фигню. А за счет того что Qt одна, страницы памяти разделяются и получаем экономию.
Это не совсем так, so (shared objects) на то и shared, что переиспользуются в памяти между всеми процессами их загрузившими. Отсюда и большие значения в колонке SHR.
У меня есть подходящий пример по поводу 'простенького целерончика'. А именно, легендарный (в своё время) asus eeepc 900, с гигабайтом памяти (и апгрейдом до ssd накопителя).
OS - NetBSD, которая сильно легче линукса -- одно ядро раз в 10 меньше.
Сборка GCC -- не хватает гигабайта памяти и вываливается в своп немного.
То же самое, если попытаться ходить по интернету браузером palemoon (разновидность firefox) -- gmail, wiki, google -- уже тоже начинает из гигабайта вываливаться в своп и конечно же жутко тормозит. В остальном -- работает нормально (иксы, без DE и лёгкий WM типа fluxbox).
Так что нет, гигабайта памяти и скорости легких целерончиков уже совсем не хватает.
я на eeepc 1015 веб разработкой занимался, хром + IDE, разумеется что-то свопилось, но в принципе это было весьма комфортно (если не принимать в рассчет не стандартное разрешение)
тогда правда и хром был по легче
Поставьте на вашу убунту простенький Миднайт коммандер. Сколько пакетов он потянет за собой?
Совсем немного пакетов потянет. Midnight Commander - очень легкая, памяти почти не потребляет, регулярно пользуюсь, очень удобно.

А вы проверяли, сколько он пакетов тянет с собой? Они действительно не нужны и не используются, но сколько их? Насколько я помню, он по-дефолту требует Xorg и кучу пакетов из гнома. Консольный файловый менеджер. И именно об этом говорит автор статьи. Неважно, винда у вас, линукс, полуконский полупес... В современных реалиях при установки любого программного пакета вы установите кучу ненужного хлама, который просто будет лежать и занимать место. Под виндой - больше (не факт), под линуксом - меньше, но этого хлама будут тонны.
Сколько занимает сейчас glibc? Вот вы делали 10 лет назад программу, которая использовала этот пакет. Функционал этот программы нисколько не изменился. Но при установке этой программы вы притянете к ней glibc, размер которого увеличился минимум в 10 раз. Вот это - проблема.
А вы проверяли, сколько он пакетов тянет с собой?
andreymal@ubuntu:~$ sudo apt install mc
Следующие НОВЫЕ пакеты будут установлены:
libgpm2 libslang2 libssh2-1 mc mc-data
Обновлено 0 пакетов, установлено 5 новых пакетов, для удаления отмечено 0 пакетов, и 1 пакетов не обновлено.
Необходимо скачать 2 567 kB архивов.
После данной операции объём занятого дискового пространства возрастёт на 9 943 kB.
Хотите продолжить? [Д/н]
это вы пробуете на своей конкретной системе (где уже установлено что-то). А на чисто ОС? Мне правда лень ковыряться в пакете, но раньше там было очень много зависимостей на гноме-окружение.
Это чистый Ubuntu Server, никакого гнома на нём отродясь не было
А чего в нем ковыряться, если можно просто взять и посмотреть зависимости через apt:
~$ apt show mc
<cut/>
Depends: libc6 (>= 2.15), libext2fs2 (>= 1.37), libglib2.0-0 (>= 2.59.2), libgpm2 (>= 1.20.7), libslang2 (>= 2.2.4), libssh2-1 (>= 1.2.8), mc-data (= 3:4.8.24-2ubuntu1)
Recommends: mime-support, perl, unzip
Suggests: arj, bzip2, catdvi | texlive-binaries, dbview, djvulibre-bin, epub-utils, file, genisoimage, gv, imagemagick, libaspell-dev, links | w3m | lynx, odt2txt, poppler-utils, python, python-boto, python-tz, xpdf | pdf-viewer, zip
<cut/>Все, что может потребовать иксов, находится даже не в Recommends.
На самом деле, все проще. Я никогда не пользовался убунтой в повседневной работе, мне генту был ближе. А там все работает интересно - если в системном х.конф прописаны иксы, то миднайт ставит свои иксовые приблуды. При этом его даже не сильно волнует, что у меня настроено xfce - он ставит всякую гномовскую требуху.
ЗЫ. И, опять же, у меня данные сильно устаревшие, я уже лет 7 не пытаюсь использовать линуксы в качестве десктопных систем - корпоративными стандартами они не предусмотрены, а
Там тоже все плохо. Держу вот тут ностальгии ради архивный форум конца нулевых, но нынче с постоянными переездами решил перекинуть на микро-виртуалку с 256мб оперативки. В свое время и побольше вещи крутили, даже на роутерах с 32мб оперативы. Но нынче даже после всех возможных оптимизации все равно с OOM периодически крашится. А все потому что всякая мелкая ерунда раздулась до невероятных мсштабов. systemd-jourald отъедает 2мб на то чтобы просто писать логи в файл, logind 1.65мб на... просто так, snapd под 10мб чтобы засирать диск устаревшими копиями приложений, альпиновский скрипт проверки наличия обновлений системы работает на питоне и выедает под 30мб, вместо курла по крону, который тоже кстать на 800кб раздулся, это уж не говоря про апач и mysql которые в таких ограничениях просто говорят "кря".
К сожалению, на выбор есть лишь центось, федора, дебиан и убунта. Вроде, говорят, можно наживую его выкорчевать, но я пока не рискую. Ну и не особо это спасет от раздувания софта в целом. Если сегодня скрипт проверки обновлений столько отъедает, завтра столько же будет жрать пакетный менеджер, и чтобы обновить пакеты придется выключать бд.
Это можно рассказывать как анекдот: перешёл на убунту ради экономии ресурсов компа
Специальный инструмент загрузки на сервер, которым я пользуюсь сегодня, суммарно имеет 230 МБ клиентских файлов и задействует 2,7 тысяч файлов для управления этим процессом.
Проблема есть, но все вовлечены в процесс раздувания, разворота не видно. Сами работодатели всех заточили на фреймворки, спрашивают и там и тут. Там из этих 230 мб, можно целый CRM наверное сваять.
Ну и условно всех учат собрать Теслу из выданных компонентов, а реальные задачи от работодателя, это собрать из этих компонентов - фонарик.
Всё-таки Вы слишком категоричны в "ничего не поменялось в пользовательском опыте". Поменялось очень многое, начиная от более удобных и интуитивно понятных интерфейсов, не требующих чтения учебных пособий по ним, заканчивая возросшей функциональностью программ.
Я не отрицаю проблему, которую поднял ТС, и сам солидарен с его позицией. Но это цена за то, что разработка становится дешевле, а значит у пользователя появляется намного больший выбор ПО, которое он может использовать. Можно писать программу максимально близко к железу и упарываться по производительности, иногда это оправдано. Но тут приходит какая-нибудь фирма, и говорит "сколько стоит написать сайтик корпоративный? 50 тыс. руб.?? а что так дорого?!" и разрабочик берёт готовый фреймворк (раздутый потому что универсальный) и быстро пишет на нём этот сайт.
разработка точно не становится дешевле, и тем более чем 20 лет назад.
Ох, если всё время придумывать новый способ организации данных (виндовс, машем ручкой всем твоим разновидностям диалогов, некоторые до сих пор из 98/nt4. Кстати, это эталонная помойка, за которую часто любят ругать линуксовые смешивания kde/gnome приложений).
Хороший пример "удорожания" разработки - 20 лет назад приходилось брать 3D модель, делать развёртку и рисовать в каком-нибудь фотошопе текстуру по этой развёртке. Сейчас, в том же блендере можно взять картинку и тупо рисовать частью этой картинки в текстуру, используя проекцию окна. Это просто фантастика для 2000 года. Я уже молчу про перевод из фоток в 3D в каком-нибудь Meshroom. Да, там надо редактировать и делать по сути новую сетку, но! это уже очень легко делается по готовым поверхностям в пространстве. 3D скульптинг - тоже "магия", когда с планшета просто "рисуешь", а не кропотливо решётку с нуля фигачить.
Но смысл изначально был в другом. У вас новый функционал, полезный и разнообразный. Хоть и раздутый код для его реализации. Я не знаю, может быть в фотошопе это оправдано, но калькулятор, который раньше ел меньше мегабайта, а сейчас за раз отъедает за 150 мегабайт оперативной памяти при таком же функционале - это действительно просто неприлично уже. В посте это и рассматривается, что крохотная приложенька делала то же самое, что и 200+ мегабайт и 2700 файлов.
Они же в составе ОС, зачем они отдельно? Да и крайне сомнительно, что поддержка тача увеличит код на 40-50 мегабайт
telegram.ext только ради Updater и CommandHandler. dateutil.parser. Это вместо того, чтобы написать простой regexp. А ради парсинга пары аргументов запуска, юзаете argparse в котором еще тонна ненужного вашему софту функционала.Я понимаю, сторонние пакеты, но чем вам argparse-то не угодил? Он же в стандартной библиотеке, так что по-любому есть всегда и нисколько не увеличивает конечный объём приложения — глупо отказываться от предоставляемого им функционала даже «ради парсинга пары аргументов запуска».
Вот это одна из главных причин (и на мой взгляд - уважаемая причина) неоптимизированного кода. Код нужен не чтобы красиво исполняться, а чтобы решать какие-то задачи, зарабатывать деньги. Если неоптимизированной код есть 4Gb RAM вместо 64Kb, и это стоит лишние 10-20 баксов в месяц (а приносит 10-20 тысяч баксов в месяц) - да и пусть!
Гораздо важнее стоимость разработки. И оплачиваемые человеко-часы, и скорость получения результата. Кривая и немного глючная криптобиржа, которую вы запустите в 2010 году покорит мир и принесет миллиарды долларов. Эталонная, которую вы бы начали в 2010, и допилили к 2022 - была бы мало кому не нужна, потому что рынок уже поделен.
Я для себя решил забивать не ресурсоемкость (хотя и люблю арендовать low-end VPSки за копейки), писать на Python. И для проектов с парой сотен пользователей - это вполне норм! Будет миллион пользователей - тогда, может быть и денег будет достаточно на железо или же перепишу 1% кода (самый ресурсожрущий) на чем-то более шустром.
А разве при распространении дистрибутивом стандартная библиотека режется? По-моему, она просто рядышком вся упаковывается, вот и всё.
Безотносительно потребления памяти - но я отчётливо помню как "новый" калькулятор в вин8 меня поразил в самую пятку, когда при запуске показал крутилочку пока загружался UI. Честно признаюсь, память не замерял
Запустил калькулятор - около 20 мб, потыкал, скачал курсы валют, построил графики - 80 мб. В свернутом состоянии 3,5 мб.
При этом страничка данной статьи в браузере - 2гб.
Поменялось очень многое, начиная от более удобных и интуитивно понятных интерфейсов
По-моему интуитивной понятности стало меньше. Но это, конечно, моя субъективная оценка.
На Делфи не писал. Но самое простое и юзабельно в плане разработки GUI, с чем я сталкивался - это VB6. IDE, маленький бинарь. Потом я перекатился на C#, и там уже все тянет за собой целый .NET, и Qt, который тоже немаленький.
Еще был (есть) C++ Builder, в котором был и редактор форм, и целая хренова туча виджетов, втч всяких сложных. И еще помню были всякие пакеты компонетов для C++ Builder. Эх, времена.
Что касается GUI, то чем более новая технология, тем она сложнее и выше порог входа.
VB6. IDE, маленький бинарь. Потом я перекатился на C#, и там уже все тянет за собой целый .NET
Бинарь маленький, но не самодостаточный. А .NET встраивается в винды начиная с версии XP. Обе технологии используют виртуальные машины (интерпретирующие P-код и CIL, соответственно) и обе же требуют сред исполнения.
Умельцы даже сделали для дельфи библиотеки KOL/MCK, которые реализовывали графический интерфейс на винапи, сохраняя удобство VCL. Такие приложения весили от 12 кб.
VCL действительно тормозил на старом компьютере и жрал память как не в себя.
Чтобы сделать хороший "интуитивно понятный интерфейс", надо уметь делать хорошие интерфейсы. Это почти никак не связано с кодом.
Почему бы не совместить быструю разработку и адекватный по ресурсам фреймворк? Фреймворк это абстракция над ниже лежащим уровнем. Ситуация больше похожа на строительство абстракций над абстракциями. К примеру CMake генерирующий текста для разных билд систем. С каждой версией становится больше и сложнее и не удивлюсь если скоро выйдет новая тулза, которая генерирует текст для CMake, так как это проще, чем юзать сам CMake. Сама по себе задача, по сборке программ не изменилась, собрать программу, ну ок дополнительные телодвижения по интеграции, прогонов тестов(если они есть:))
Поменялось очень многое, начиная от более удобных и интуитивно понятных интерфейсов, не требующих чтения учебных пособий по ним, заканчивая возросшей функциональностью программ.
Вы знаете, вот по поводу более интуитивно понятных интерфейсов - не соглашусь! Взять "простейший" LightRoom или Krita - без чтения учебных пособий там даже файлик открыть не все в состоянии.
И да, лично был свидетелем, как парень лет 18-ти не смог сдать экзамен в ГАИ, где на экзаменационных местах, кажется, был запущен официальный портал с билетами в режиме киоска. Бедолага просто впервые увидел компьютерную мышь - первые пару минут он пытался тыкать пальцем в экран, а на рекомендацию тыкать не пальцем, а мышью, просто погрустнел лицом и вышел из аудитории. Вот такая интуитивная понятность бывает.
Давняя мудрость гласит, что действительно интуитивно-понятный интерфейс только у соски. А все прочие "интуитивные" вещи - уже основаны на каком-то обучении, культуре, традициях...
Бедолага просто впервые увидел компьютерную мышь
whatsapp для компьютера - это электрон
Пользователю глубоко пофигу, на чем написано, лишь бы работало. А с копией ворда есть немало плюсов взаимной интеграции. Можно отправку сообщений из ворда автоматизировать не через гребанный API, а напрямую, например. Можно дорабатывать клиент под требования бизнес-процессов.
тут цепная реакция - новое ПО наращивает объем кода, пользователю приходится наращивать железо, как правило, с излишком от требований ПО. Новое ПО закладывается под излищки - нефиг оптимизировать, если ресурса и так полно, и на какой-то этапе ресурс исчерпывают, пользователь покупает новое железо.
А если не покупает и сидит на старых версиях - то начинают лезть вопросы совместимости форматов, сценариев, обязательно требуют для просмотра/проигрывания файла прикрутить свистоперделку, которую или не поставишь на старое железо\ОС, или жрет ресурс как не в себя.
А на деле даже в 2022 году сам Microsoft продаёт типа современные ноутбуки Surface Go, которые начинаются с 4 ГБ оперативной памяти, ставишь туда такие Slack, Discord и прочие шедевры и всё - приехали.
Меня больше бесит Teams, который суть — обёртка над браузером.
Но если аналогичные сервисы Google прекрасно работают из браузера, в т.ч. и из Firefox, то Teams не работает и требует запуска через приложение. Пусть горят в аду.

В смысле: нельзя устроить аудио/видеоконференцию.
Zoom — нативный клиент, а Teams — Electron, поэтому ограничения кажутся искусственными.
Несмотря на то, что у Zoom нативный клиент, отличий в UX в браузерной версии я не нашел. Допускаю, что они есть, не суть.
Я, видимо, чего-то не понимаю, но... в браузерной версии Teams, точно как в десктопной, назначаю встречу, присоединяюсь и провожу видеоконференцию. С демонстрацией экрана.
Микрософт тупо проверяет User Agent. Если подставить юзер агент от хрома, то звонки магически начинают работать. Я сейчас точно не помню, я так делал примерно 2 года назад, но кажется проблемы были только с расшариванием экрана.
Насколько я помню, клиент электронной почты Outlook до сих пор рендерит html в письмах с помощью движка Word. Такие дела.
Видимо браузер, в итоге, оказался лучшим решениям для построения кроссплатформенных приложений. Что там конкурирует?
Мёртвые Adobe Flash/JavaFX?
Безумно фрагментированные Microsoft'овские штуки, которые появляются и умирают каждый год? Да так, что уже видно что это тенденция и не хочется инвестировать время в то, что через год закопают. Сколько их было и есть? Silverlight, WinForms, XAML, Xamarin, Avalonia, вот сейчас всех на MAUI перетягивают. Ждём следующую MS THE CURRENT THING, которая, конечно, опять будет лучше и на которую надо будет всем переползать, выбросив в мусор инвестиции своего времени в изучение всех предыдущих THING. Уверен, что забыл ещё с десяток "вот теперь точно последних кросс-платформенных фреймворков для создания приложений" от одних только MS. Они там вообще ку-ку?
Qt с их неудобными и дорогими лицензиями? И в целом есть ощущение, что проект перестал развиваться.
Гуггловый Flutter? Похоже, единственный адекватный вариант на замену электрону. Только за чей счёт будут переписываться тонны того, что кодеры сейчас ставят из npm - большой вопрос.
Безумно фрагментированные Microsoft'овские штуки, которые появляются и умирают каждый год?
Вы считаете так. А те, кто платят деньги за разработку, чтобы зацепить как можно больше пользователей и не имеют столько же бабла, сколько Uber или Facebook - считают иначе. :) Заплатить один раз на условном Unity/Flutter/Adaptive Web или заплатить много раз на iOS, Android, Win, Mac, Web - хм, что же выбрать?
WinApi работает. Но работает только на винде. Вопрос "только на винде" не стоит, потому что в мире существует не только винда. И ещё вопрос - зачем тогда Microsoft ТАК мечется? Есть же WinApi.
Вы считаете так
Да нет, все считают так. В мире приложений почти все ходовые приложения - нативные. Уже даже стартапы сразу пишут нативные приложения, потому что их потом при росте не нужно будет переписывать на нативные (а пользователи и разработчики обязательно попросят). Самые известные примеры - AirBnb (выкинули React Native) и Slack (переписали с Electron целиком).
В мире игр вообще кроссплатформенности почти нет. На моем маке могу запустить только 10% библиотеки Steam. Если "все считают", что кроссплатформенность нужна, то где версия под мак? Или под линукс без Proton?
Вы только что привели пример Slack, которые изначально писался как раз на Electron, чтобы писать код только один раз - для Web, а потом использовать его везде. Потом они заработали бабла и смогли себе позволить нативные приложения. Это уже опровергает тезис, что «все считают так». Именно Slack считал, что пока бабла нет, его надо экономить.
Не знаю насчёт AirBnb, они стартовали с React Native, или пытались удешевиться и ускориться за счёт него. Если пытались удешевиться и ускориться - значит всё не так прекрасно с нейтивами? А если же стартовали - это, опять же, опровергает тезис что «все считают так». Именно, что «все» (если не брать уже богатые компании или стартапы с бесконечным финансированием) сначала экономят деньги. А потом, когда денег становится много - пишут нэйтивы. Собственно, пример со слаком именно об этом. Насчёт AirBnb не возьмусь судить, не знаю истории.
Тут ещё вспоминается ClubHouse, который изначально был под iOS только. И много других iOS-only приложений, которые потом заходят на Android. И не пишут сразу на обе платформы, потому что денег делать одно и то же по 2 раза, наступать и исправлять двойные грабли (а в случае когда надо много платформ - многократные) просто нет.
Slack (переписали с Electron целиком).Разве его переписали на натив? Я помню, что читал, что да, они его переписали, но всё на том же чёртовом веб-стеке. Типа, вместо 2 гигов оперативки он теперь жрёт 500 мегабайт. Офигеть достижение для клиента мгновенных сообщений.
Кто будет оплачивать этот банкет?
Это всё прекрасные рассуждения, но ответьте: сколько будет стоить в описанном вами случае разработка одного приложения, которое должно работать как минимум под Linux, MacOS и Windows? А если оно же должно работать ещё и под Android? Как в этом случае помогает факт всегдашней работы WinAPI?
Безумно фрагментированные Microsoft'овские штуки, которые появляются и умирают каждый год? Да так, что уже видно что это тенденция и не хочется инвестировать время в то, что через год закопают. Сколько их было и есть? Silverlight, WinForms, XAML, Xamarin, Avalonia, вот сейчас всех на MAUI перетягивают.Silverlight — не предназначался для разработки настольных приложений, это плагин для браузера, его закопали вместе с другими плагинами для браузеров.
Ну и надо не забывать что WPF жив здоров, хотя и не особенно приятен, но черт возьми, его пережил только winforms.
А зачем MS столько много всего для, по сути, одного и того же?
Спасибо за ликбез! Может есть ещё какие-то кросс-платформенные попытки от MS для десктопа?
В любом случае, судя по всеобщему огорчению, что много софта на электроне, электрон пока лидирует в деле кросс-платформенных десктопов... И на то есть причины, которые не решают другие фреймворки.
Если кому надо было десктопное приложение, брали полноценный WPF или WinForms.
Ну так в том и претензия в комменте yokotoka была, что MS бросает развитие кучи своих продуктов.А смысл развивать объективно ненужные продукты типа Silverlight? Он был изначально мертворожденным. Тут Microsoft сильно просчиталась. 5 лет вливала деньги в совершенно бесперспективную технологию (упорные!), и потом ещё 9 лет латали в ней дыры.
Avalonia
Эцсамое, мы не Microsoft, мы сами по себе. Вот прям совсем отдельно, в порочащих связях с корпорациями замечены не были, беспощадны к врагам опенсорса. Не надо нас в очередь на кладбище проектов со всеми остальными ставить.
Прошу прощения, не знал, что Avalonia без MS. Тут пожелаю проекту только долгой и яркой жизни, развития и всех благ! Разделяю убеждение, что кросс-платформенный инструмент не имеет права быть не опенсорсным и принадлежать корпорациям.
Видимо браузер, в итоге, оказался лучшим решениям для построения кроссплатформенных приложений
Ну и пусть себе будет лучше. Почему это нельзя разделить хотя бы на рантайм и приложения, как у того же Net Framework? Программы вроде редакторов markdown весом за 200Мб, или лаунчер приложений Ueli весом за 400Мб - это не нормально. Собственный код всех этих приложений даже до мегабайта дотягивать не должен.
WebView?
да сейчас почти везде когда что либо пишешь, то подтягиваешь для 1-2 функций еще либу либо модуль либо фреймворк, даже тот же вордпресс автора на лишнего кода 90% никогда не используемого фунционала.
В плане программирования мне нравится подход @MarcusAurelius - пишет чистый код, без кучи хлама. Основная мысль - часто чтобы разобраться с какой либо либой, по времени дольше, чем самому написать 1-2 функции, которые тебе нужны.
Бывают случаи оправданного раздутия, я как реверсер(с написанием оперсорсного аналога) это могу сказать. Оригинал - exe игры на 1мбайт, но там код по сути С, с самодельным ООП. После реверса, переноса частей на С++ и std контейнеры - код в exe раздулся мегабайт до трёх(из-за шаблонов и дублирования кода под реализации). А вот мультиплатформенность добавляет ещё 100+ мб dll'ок, т.к. вместе с портирование добавилась возможность использования ресурсов в различных форматах(ffmpeg, sdl_image), а не только пары как в оригинале, да и уже установлены в систему пользователя(dshow кодеки в системе, d3d/ddraw тоже). Конечно можно было оставить только форматы оригинальных изображений и разделить код - под никсы ffmpeg, opengl, openal, sdl, а под win - d3d, dsound, dshow, но это добавит больше проблем, в виде ещё кода абстракций и возможно тормозных решений по конвертации данных под платформу. Поэтому была ориентация на никс-стек, как более универсальный, а вин-сборки, да, толстые.
В продолжение темы - статья Абстракции и наследование в Си — стреляем по ногам красиво
Согласен, но! Это огромные монолитные библиотеки. К примеру ffmpeg тянет +100500 форматов видео и аудио. А вам нужен один для видео и музыки. SDL_Image та же ситуация. Если это возможно скомпилить статически игру только с нужным функционалом, получится небольшой бинарник, только с тем, что реально юзается.
Такой подход предпочтительнее ещё по одной причине. Притягивая функционал из раздутых фреймворков, программисты вряд ли задумывались о том, что придётся их постоянно обновлять при обнаружении уязвимостей. Тем более если фреймворки с открытым кодом.
Возникает вопрос, действительно ли компания так беспокоиться о безопасности сервиса?
В таком случае, я думаю, стремились бы как-то сократить базу кода. На деле же, как это часто бывает, потребность показать дейтельность и привнести фунционал наверняка решалась кратчайшим способом в лоб
Все верно, но все это жуткое нагромождение абстракций - цена скорости прогресса.
Именно потому, что практически каждому так или иначе доступно написать код, создать какой-то MVP даже и из чужих компонентов, мы и имеем всякие фаанги, приложения для телефона и телевизора, миллиард криптовалют и так далее.
А этот прогресс, как мне кажется, и толкает в свою очередь вперед прочие отрасли, вроде разработки новых лекарств на основе анализа молекул с помощью ИИ.
Волнует ли больного что тот ИИ является нагромождением программного кода и собранных по всем возможным сусекам данных, и не факт что его разработчики до конца понимают как это все работает? Думаю совершенно не волнует.
Все верно, но все это жуткое нагромождение абстракций — цена скорости прогресса.
О том и речь. Талантливых и высокопрофесииональных людей меньше чем вообще людей с идеями.
Но. Весь мусорный код этих кнопочек в библиотеках остался. И есть подозрение, что выполняется -> проверяется что это уже не модно -> перерисовывается как модно.
И очень плохо, что нет. Раньше кнопка выглядела, как кнопка. А теперь тыкаешь во все что можно пытаясь понять, где тут кнопка, а где просто модный прямоугольник..
> осознанно не желают их понимать
Почему осознанно?
Если не копи-пастить, а пользоваться библиотекой, то любое изменение надо отдельно тестировать и адаптировать свой код. А так автор библиотеки развивая проект тестирует и этим обеспечивает работоспособность использующих её программ. Ну или делает это в идеальном мире.
Та же ситуация что и с автомобилем, зачем мне знать что там под капотом я же на нем просто езжу, иногда выходит боком.
И оно бы запускалось на Windows, Linux, macOS, iOS и Android? И на любом железе — ARM, под M1, под x86/64?
Qt - просто дорого, да и спецов мало, итого - ТТМ стремится к бесконечности
Java - может, и хорошо, пока не начинаются пляски с версиями JVM (известно многим разработчикам, сидящим на М1), да и специалисты недешевые...
Electron - осилит любой джун+ на JS, итого - дешево и минимальный ТТМ
Просто миром разработки давно рулит маркетинг, все остальное - лишь следствия
SDL вполне себе кроссплатформенный.
Lazarus + Freepascal
Но виноваты то не программисты, а сам бизнес. Вот чем определяется рыночная ценность сотрудника и его шанс полпасть на денежную вакансию? Эффективностью кода? Да ни разу. Знание списка модных фреймворков и библиотек решает всё. Чем больше модных технологий - тем больше ЗП. Без того же докера Вас и джуном никуда не возьмут. Самые продвинутые ещё на "читабельность" кода смотрят - но и её возвели в ранг культа. Оптимизация и читабельность - зачастую взаимоисключающие явления. Да и "не говнокодить" в наше время нереально - на действительно детальное изучение всего требуемого стека жизни не хватит.
Тогда уж не бизнес, а потребители. Логика бизнеса простая и определяется законами рынка, бизнес делает то, что приводит к продажам и росту.
Здесь должен быть мем (сходу не удалось нагуглить, извините) про двух программистов, один из которых сразу программировал хорошо, а второй наговнокодил, быстро выпустил первую версию, собрал отзывы, выпустил вторую, в итоге заработал денег/получил инвестиции и нанял первого программиста рефакторить его говнокод ;)
Так что я бысказал, что пока пользователям наплевать на качество и подход "быстро загнать тяп-ляп mvp" работает, то ничего не изменится, в конце концов пользователи голосуют рублём за бизнесы, а уже эти бизнесы определяют стиль работы программистов. Программисты тут в конце цепочки и особо ничего не решают.
Ой ли ? 20 лет назад ? Оки, пример разбора строки (математического выражения) на С++ меня удовлетворит :)
Ну и вишенкой на торте ВЕБ разработка где без докера нынче вообще ловить нечего. Любой фреймворк тащит на себе 100500 депенденсов большая часть которых давно устарела и не соберется заново ни при каких условиях...
Это типа музыкант пишет песню, которую можно прослушать только в магнитоле из окна автомобиля определенной модели...
Любой фреймворк тащит на себе 100500 депенденсов большая часть которых давно устарела и не соберется заново ни при каких условиях...
Не любой, $mol не тащит, например.
Как там у вас с bus-factor'ом? Я как-то использовал в продакшене подающий надежды фреймворк famo.us. С громкими презентациями, оффлайн конференциями, светлым будущим. Который закрыли через год. И хотя он был в опенсорсе - последователь пожелающий возродить былое нашёлся аж один (infamous, ныне lume). И хотя проект вроде бы активный - он (меинтейнер) всё ещё один.
Примерно так:
AngularJS: был похоронен не дожив до 6 лет. Всем, кто на него подсел, предложили переписать код на другой фреймворк с похожим названием, в котором лишь через 5 лет вылечили детские болезни.
$mol: почти 7 лет не то устаревать не думает, а наоборот - продолжает внедрять инновации.

А басфактор повышается пользователями, так как разработка фреймворка ничем не отличается от его использования.
Всё просто - в 99.999% программист не несёт ответственности (материальной и юридической) за результат своего труда. Но хочет за свою работу немалых денег.
Не, на самом деле вместо "быстро и качественно" бизнес выбрал "медленно и дорого". Ибо своей экспертизы не хватает, а у исполнителей иная материальная мотивация.
А заказчик готов платить не потому что это 4 поля, а потому что труд разработчика это карнавал масштабирования.
Представляете, если бы у вас был токарный станок, который мог бы обслуживать (почти) неограниченное количество токарей одновременно? Сколько бы вы не посадили за него специалистов - все бы они были заняты, не мешали друг другу и единственное бутылочное горлышко которое в у вас было бы - отгрузка готовых деталей! Сколько бы вы были готовы заплатить за такой станок или за добавление лампочки на нём?
А с программными продуктами такое работает - маленькая CRM написаная на коленке и раскрученная на "Малинке" может занять работой целый стадион продаванов! Только подноси списки телефонных номеров и выгружай лидов из воронки! Гипотетически, убер может прямо завтра открыться в 10 странах сразу! Потому "пара штук евро" действительно "ни на что в бизнесе не влияет"
При этом я не оправдываю то, что творится в разработке. Более того, когда мне попадаются случайные заказы на поддержку старых продуктов - я только радуюсь - они простые и понятные! Да - местами надо добавить очистку пользовательского ввода, да - местами надо перестать хранить пароли в открытом виде, да - с газзлом гораздо удобнее делать запросы к сторонним API чем руками. Но это маленькие поправки - бизнес работает и без них уже очень продолжительное время!
А когда я вижу магию middleware в Laravel я начинаю чесаться в самых нескромных местах!
Вам, возможно, платят так же и за решения не добавлять бесполезный функционал, либо реализовать его в другом виде, либо заполнять поля в базе автоматически, используя какую-нибудь инфу. Клиент заплатил за то, чтобы вы проанализировали все варианты и действительно увидели, мол, ага, без полей никак.
Ещё клиент заплатил за UI/UX, — то, где будут поля находиться, какого цвета, какие валидации (фронт/бек) и так далее и так далее.
Почему -"просить"?. Из этого "просить" и растут проблемы.
Если у вас обнаружится дефект тормозной системы вашего автомобиля - (ошиблись при разработке, с кем не бывает) то вы будете "просить" чтобы починили и ездить с дефектом? Или "требовать" немедленного ремонта?
Ты не учитываешь, что программист ни за что не отвечает, потому что ему никто этой ответственности не даёт - всё решают за него, и до него, ответственность у вышестоящих лиц, сам он лишь мелкий винтик в современной индустрии. Ему дают задачу и время, и главное - уложиться в отведенный срок, а результат не особо важен.
В следующий раз (или в этот — если получится сделать юридически) получите огромный счет. А также — ограничения на то как это можно использовать вида "так, установка ЛЮБОГО обновление не протестированного разработчиком — лишает гарантии, то что какая то там MS орет что это срочный патч и отменить установку невозможно — ваши проблемы. Наличие на компьютере ПО которое меняет стандартный функционал ОС и/или перехватывает системные вызовы — лишает гарантии, то что вы хотите Касперского поставить или там AdGuard или там FRAPS'а — ваши проблемы. Неработа интернет-канала до указанных в приложении №1 сетей и dns-имен с характеристиками не менее таких то — лишает гарантии, роскомнадзоры это ваши проблемы. Поддерживаются процессоры Intel Core 4-го поколения (если хотите другие — с вас отдельные деньги). Для запуска в виртуальной среди разрешается использовать только согласованный с разработчиком гипервизор конкретной версии а иначе лишение гарантии.
Мобильная версия разрабатывалась под Apple iOS 14.5 на iPhone SE 2-го поколения. Использование другого железа или другой версии ОС — лишает гарантии, то что у вас iOS сама обновилась — это ваши проблемы, новую версию приложения выпустим скоро, да — обновление не будет бесплатным если у вас подписки нет"
И так далее.
А то ишь — моду развели — ставят на все начиная с WinXP до Win11 кучи разных версий (это я еще линукса не касаются — flatpak и snap совсем не на пустом месте родились), на черт знает какое железо и требуют чтобы работало.
Уважаемый @Jian
Во-первых, я больше по железу. Если и программирую, то исключительно для себя и друзей.
Во-вторых, для меня программист\программисты - люди которые создали данный программный продукт. И мне пофиг кто за что отвечает и сколько получает при его создании. Если вы покупаете плохой хлеб, то для вас в этом виновата пекарня "Три корочки", а не конкретно пекарь Толя, поленившийся прогреть молоко.
В-третьих, я считаю что любая выполненная работа должна быть оплачена. Именно выполненная. А не та, которую попытались выполнить, но не смогли. У морских (и не только) спасателей есть замечательное правило: "Нет спасения - нет вознаграждения". Абсолютно не имеет значение, сколько ресурсов вы потратили на спасение. Судно утонуло - значит вы работали за свой счёт. Даже если вы при этом утопили весь свой спасательный флот.
А давайте так же всех адвокатов заставим работать?
А то они тоже любят брать деньги и прямо говорят что будут стараться.
А вариант с оплатой за результат не очень любят.
"Нет спасения - нет вознаграждения"
Тогда уж лучше сразу по схеме "сделай мне сайт, а я тебе заплачу как он начнет деньги приносить".
У морских (и не только) спасателей есть замечательное правило: «Нет спасения — нет вознаграждения»
Если сейчас (по консервативным оценкам) 99% ресурсов наших PC тратится впустую, мы впустую тратим и 99% потребляемой компьютером энергии. Это абсолютно преступно. И для чего же эти траты?
Эти траты нужны для понижения порога вхождения в отрасль написания программ, ускорения разработки, обеспечения работоспособности всего написанного и т.п.
Так это и есть снижение порога. Не нужно тратить время на рефакторинг, приписал новую функцию сбоку — и в продакшн
Все верно - порог входа снижается, соответственно снижается квалификация программистов (в среднем), на выходе имеет такой говнокодинг.
О чем собственно и статья.
Кто-то когда-то написал код для библиотеки, потом к нему добавился ещё код, потом ещё, потом ещё. Старый уже легаси, про который все забыли, но он там сидит, а каждый год к нему ещё докидывают, и так далее. Потом библиотека подтягивает к себе зависимости из других, точно так же растущих библиотек… и вот так оно годами наслаивается и растёт в геометрической прогрессии.
Ну так тут описан Open–closed principle. Убрать слои абстракций и выкинуть лишнее - нельзя как можно. Сломается же что-нибудь. Причем, действительно, скорее всего сломается - принцип не на пустом месте возник.
вы думаете, что разобраться в каком-нибудь ангуляре проще чем в php 4?А написать на php4 что-то, что займет пару дней на ангуляре (при нулевых знаниях там и там) сколько дней займет?
что осмысленное можно написать на ангуляре за пару дней при нулевых знаниях в немМного чего можно. С нулевыми знаниями же в ангуляре, а не в программировании как таковом.
Хелло ворд? Ну минут 30 наверное на пхп с перекуром.Мультиплатформенный и симпатично выглядящий хелло-ворлд на пхп4 за 30 минут? Удачи:)
Есть один плюс, который часто упускают из вида. Это требования к кроссплатформенности
То что, к примеру, я пишу на С для одной ОС и потом переписываю для другой не делает конечную библиотеку больше.
Если взять тот же Qt с требованиями "разработать с использованием QML", прицепить базу данных и использовать сервисы ОС (погода, положение, и тд) - это будет гиговый дистрибутив в отдельном каталоге не считая библиотек операционной системы. Но при статической линковке это всего лишь 12 мегабайт. А если взять весь функционал напрямую из ОС то приложение будет не больше метра.
Не будем также забывать про существование KolibriOS.
Всего. Лишь. 12. Мегабайт.
Я может не умею собирать Qt, но у меня получается где-то 16-35 MB занимает один исполняемый файл простенького проекта.
В .NET Core, кстати, при публикации приложения есть опция выбросить из dll заведомо неиспользуемый код. Программа худеет раза в два.
Стоит отметить что при работе с рефлексией могут быть нюансы и такой код нужно дополнительно "помечать", но в целом вы правы. Вот бы еще этой опцией люди начали пользоваться)
Большая часть этих файлов — рантайм, нативный код.
Непосредственно .NET код — 2 мегабайта. Не всё так плохо.
В тред призываются хаскелисты, чтобы рассказать, что в хаскеле система типов выразительная, косвенные эффекты контролируются, и т.о. подобные проблемы давно решены.
Кстати, да. Захотел я поставить утилитку — pandoc, так она с собой весь хаскель потащила. В итоге люди вот так извращаются:
https://aur.archlinux.org/packages/pandoc-bin
по второму вопросу - static linking умел это еще во времена DOS, а вот это вот все - dll
Хороший повод не писать на Java?
Т.е. ради одной фичи переписываем весь проект? Э - эффективность.
Хороший повод сразу писать на нормальных языках?
Неа. У вас уже есть готовый проект. Неважно на чем, хоть на языке Ада или на Фортране.
К счастью в мире больше одного языка программирования.
У меня нет проектов на яве.
А у других - есть. И часто это проект бизнеса, а не ваш. И бизнес не будет менять технологический стек без крайней на то нужды
Хороший повод поменять техдира, что выбрал такой стек.
Почему? Наш условный проект на Java существует, приносит прибыль. Разработчиков найти можно для работы с ним. Все еще не вижу проблемы.
Первое правило ремонтника "Не ремонтируй то, что работает".
Хороший повод сразу писать на нормальных языках?
Например?
Начать можно отсюда: https://llvm.org/ProjectsWithLLVM/#LDC
Тогда почему вы пишите на JS/TS (судя по профилю)?
Я много на чём пишу. Но для браузера толковых альтернатив пока нет.
Ну вот в том и проблема, что далеко не всегда есть возможность выбрать тот язык, который нравится. Зачастую выбор обусловлен ограничениями платформы и/или наличием легаси кода, который никто не будет переписывать ради того, чтобы внедрить одну новую фичу правильным путем.
За пределами браузера ограничений практически нет, кроме инертности мышления.
За пределами браузера ограничений практически нет, кроме инертности мышления.
Вы можете выбрать любой стек, который позволит решить текущую задачу оптимальным способом. Но через N спринтов, когда уже написаны сотни тысяч строк кода, у приложения появилась куча активных пользователей, к вам внезапно прибежит заказчик с горящими глазами и заявит, что ему кровь из носа нужно интегрировать в приложение, ну хотя бы, тот же OpenCV, не суть важно. Тут и возникает два варианта: угробить еще тысячи часов и кучу денег на переписывание кода и миграцию, либо раздуть дистрибутив на лишних 100 Мб. Как думаете, что выберет бизнес?
Ох уж эта выученная беспомощность. Тут мы возвращаемся к исходному тезису. Не берите "любой язык", берите тот, что не создаёт вам проблем на "тысячи часов".
Тогда и я возвращаюсь к исходному вопросу: какой брать?
Потому что любой из известных мне языков, не дает гарантий, что подобной ситуации не произойдет.
Да тут дело не столько в производительности. Вы можете выбрать, скажем, Go или Rust и запросто влететь в такую же проблему через какое-то время. Тут даже не столько в языке дело, сколько в современных методологиях разработки, которые подразумевают работу с очень маленьким горизонтом планирования. Когда вы начинаете создавать MVP, вы имеете весьма расплывчатое представление о том, что с ним будет через год или два.
И тут мы возвращаемся к исходному ответу на исходный вопрос. Так и будем кругами ходить?
Это не ответ. Ни один из перечисленных там языков не решает проблемы.
Какую проблему не решает язык, на который я дал ссылку?
Проблему возникновения требований, которые на этом языке не решаются без возникновения вышеупомянутой дилеммы.
Какую проблему не решает язык, на который я дал ссылку?
Что там подразумевается? D конкретно или LLVM в общем?
Вот потребуется вам, например, в проект интегрировать какую-нибудь существующую Java-библиотеку. Как D решит эту проблему?
Потому что нужная вам библиотека есть только на Java, и времени портировать ее на нужный язык нет. И это пример не с потолка взят. Мне как-то на заре карьеры пришлось интегрировать Scala-библиотеку, реализующую алгоритм PLSA, в C++ проект. Тот кошмар с JNI до сих вспоминается, но это был самый быстрый способ из доступных.
Использование альтернативы на компилируемом языке / Портирование / транспиляция / поднятие JVM в воркере.
Альтернативы есть не всегда. А портировать - это долго и дорого. Никто не будет с ним заморачиваться, если есть возможность сделать пусть немного криво, но быстро и, что важнее всего, дешево. Исключение - достаточно крупные игроки, которые могут себе позволить потратить кучу человеко-часов на качественное решение.
А есть ли вообще такой язык, который при любом изменении требований не создаст "проблем на тысячи часов"? И может ли он существовать хотя бы теоретически, или для любого наперёд заданного языка может найтись требование заказчика, которое поставит разработчиков раком?
Посыл в том, что проблему решить можно. Не всегда и не во всех условиях - но можно. А вы заявили безаппеляционно "это пока невозможно.".
Есть еще и другие варианты - самый простой это OpenSource. И хоть на джаве оно все будет - можно все порезать.
Посыл в том, что проблему решить можно. Не всегда и не во всех условиях — но можно. А вы заявили безаппеляционно «это пока невозможно.».
Есть еще и другие варианты — самый простой это OpenSource. И хоть на джаве оно все будет — можно все порезать.
По поводу кроссплатформенности меня расстраивает вот какая ситуация: много софта, у которой установка по умолчанию через веб-инсталлер. Почему в этот инсталлер не встроить что-то типа CPU-Z/GPU-Z и собрать (если такой сборки ещё нет на сервере компании) со всеми ключами, чтобы шустро работало именно на моей машине? CI/CL уже не диковина, билд-сервера жирные... Скорость растет, размер, в том числе за счет dead code elimination, падает, пользователь доволен, для производителя затраты не очень высокие. Видимо, я чего-то не понимаю.
Вы хотите иметь на своем компьютере сборку, которую производитель никак не тестировал?
(а то, что билд-сервера жирные — ну это когда как, некоторые продукты до сих пор минут 40 собираются, вы готовы добавить это время ко времени установки?)
Вы хотите иметь на своем компьютере сборку, которую производитель никак не тестировал?
Лично мне для развлекательной программы автотестов хватит, для остального телеметрии и крашрепортов хватит, зря их встраивают в таком количестве, что ли? Пусть я не думаю, что -march может что-то сломать, но вдруг, а как падают тесты на разнице -Os, -O0 и -O2 видел, поучительно, кстати. Небольшой оффтоп: в статьях про VLIW пишут, что для того, чтобы шустро работало, надо фактически переписать программу. Дык и чтобы старая программа шустро работала на новых процах, используя их возможности (avx, sse, интрисики) её тоже очень мощно перелопатить нужно, но это игнорируется.
некоторые продукты до сих пор минут 40 собираются, вы готовы добавить это время ко времени установки?
Я - готов. Но вполне разумен сценарий, когда тот же браузер через час-день-неделю вешает попап "Псст, мы собрали версию, идеально подходящую под твоё железо. Хочешь установить?".
Лично мне для развлекательной программы автотестов хватит
Вот только чтобы запустить автотесты, нужно такое же железо, как у вас. Откуда оно у производителя?
И это еще не считая того, что автотесты, вообще-то, легко превращают затраты производителя из "невысоких" в "что-то уже пожалуй не буду".
чтобы запустить автотесты, нужно такое же железо, как у вас. Откуда оно у производителя?
Хотел сказать про QEMU, но так правда получается дорого + баги эмулятора. С другой стороны, разработчики мобильных приложений как-то же тестируют хотя бы на самых популярных моделях смартов?..
автотесты, вообще-то, легко превращают затраты производителя из "невысоких" в "что-то уже пожалуй не буду"
Странно, считал, что иметь автотесты хороший тон, хотя бы под каждую поддерживаемую платформу. Ну не лапками же тыкать, дорого, долго и ненадежно.
С другой стороны, разработчики мобильных приложений как-то же тестируют хотя бы на самых популярных моделях смартов?..
Ну так они тестируют либо общую версию, либо версии, собранные для этих смартов. То есть оно уже собрано.
А вы хотите версию, собранную под ваше железо.
Странно, считал, что иметь автотесты хороший тон, хотя бы под каждую поддерживаемую платформу.
Иметь автотесты — да. А вот прогонять их каждый раз когда пользователь себе что-то устанавливает — уже дороговато.
Мобильщики, которых я видел и знаю, держат парк в 2-3 десятка основных смарфонов и тестируют на них.
Псст, мы собрали версию, идеально подходящую под твоё железо
Удачно сделал Гугл, перейдя с APK на AAB (что позволяет сразу выкинуть неиспользуемые ассеты) и внедрив Android Runtime c компиляцией байт-кода непосредственно под целевую платформу.
Но гугловская модель имеет недостаток - приложения слишком изолированы друг от друга и не могут использовать общий код. Если 10 вашим приложениям нужен OpenCV, то у вас на устройстве окажется 10 копий этой библиотеки, причём самых разных версий и без возможности обновления. Поэтому обязательно необходим менеджер пакетов, как в настольных линуксах.
А менеджер пакетов, как в настольных линуксах, приводит к тому, что требуются мейнтейнеры, которые разруливают зависимости, чтобы всё в репозитории зависело от одних и тех же версий библиотек. Что приводит к хорошо известным проблемам: трудности с обновлением на более новые версии, кучу работы мейнтейнеров и вообще превращение всего дистрибутива и репозиториев под него в огромный монолит.
К сожалению, в 2022 году настольные линуксы плохо умеют в решение DLL hell
Gentoo не использовал, поэтому не знаю, как оно там. У Gentoo там есть еще механизм слотов, возможно, там все совсем хорошо.
Как пользовтаель Arch не испытываю проблем с обновлениями, потому что роллинг и репозиторий оперативно обновляется на свежие версии. Хотя суть остается - использование разных версий зависимостей в системе - боль.
Эти проблемы на мою жизнь особо не влияют, почему нужно о них задумываться?
Это из разряда рассуждений о вечном и прекрасном :)
По второму вопросу можно посмотреть на Unison
как выдернуть отсюда нужную функцию с десятком зависимых, а все остальное не подключать — это нерешенная пока что проблема
Статическая линковка и LTO. Вот вторая проблема куда сложнее, для этого библиотеки надо специально для этого проектировать, а так мало кто делает.
То же нытье, что и 5, 10, 20 и 30 лет назад.
Вспомнились некоторые вещи из фантастики далекого будущего. Насколько мы далеко сможем забраться в высокоуровневых абстракциях? Уже сейчас специалисты, которые помнят-знают-умеют в низкий уровень, являются штучным раритетом в мире.
Потому что они и нужны в штучных экземплярах. Рыночек порешал, как обычно. Когда появится высокий спрос на низкоуровневых программистов, такие специалисты начнут появляться всё больше и больше. Бизнесу, который создаёт спрос и платит разработчику зарплату, не нужно 100500 операционных систем, а вот интернет-магазинов, мобильных приложений и прочего нужно как раз 100500.
Вы можете написать программу, которая загружает файлы на сервер надёжно,
быстро и безопасно, и для этого потребуется двенадцатая часть от этого
количества кода. Это может быть один файл, просто единственный маленький.exe.
Ему не нужны сотни и сотни DLL. Это не только возможно, это легко, и
такое решение будет более надёжным, эффективным и удобным в отладке, к
тому же (подчеркну) оно на самом деле будет работать.
Как же сильно пахнет Delphi. :)
Я бы сказал, тут пахнет старопердунизмом :)
Даже интересно, насколько низко автор предлагает спуститься. Использовать FTP? Упороться и сделать свой более лутший протокол? Там чем ниже, тем больше будет все более и более интересных вопросов возникать, про которые раздуватели кода даже и понятия не имеют.
Но да, зато быстро. Наверное.
Использовать FTP?
А почему нет? Бизнесу надо чтобы быстро, дёшево и работало. FTP работает, все инструменты уже есть (нулевые трудозатраты на их создание) и свободные (нулевая цена). Ну ладно, надо ещё гуй к клиентской части сляпать. Хотя на самом деле надо просто как сетевую папку примонтировать и обойтись без гуя вообще (для ftp такие решения тоже есть). Ой, но тогда негде фирменный логотип показать, вот беда.
Ой, но тогда негде фирменный логотип показать, вот беда.
Команду лепил занять нечем, пускай пилят пока веб морду на новом фреймворке, как до беты дойдет там уже пожирнее фреймворк выйдет, будут сразу на него переписывать.
А почему нет?
Потому что FTP не безопасный, и если вы хотите что бы ваши файлы не перехватил сидящий со сниффером кулхацкер, нужно как минимум SFTP. Сами вы реализацию TLS не напишете (в лучшем случае будет дырявое решето), поэтому придется добавлять OpenSSL.
Реализацитю FTP сами будете писать? Уверены что напишете в соответствии с RFC? А все кейсы учтете или для 5% пользователей ваша реализация не будет работать? Ага, подключаем ftplibpp...
А что там со сжатием, или будет заливать на 30% медленнее чем у конкурента? Ага, подключаем zlib...
И это мы даже не дошли до интерфейса.
Проблема не в том что "разработчики плохие". Проблема в том что задача менеджмента зависимостей и дублирования библиотек сегодня не решена для десктопного да и любого ПО. Мобильные ОС решают чуть-чуть лучше.
Реализации ftp с TLS уже давно написаны, о чём вы?
Сжатие популярным форматам файлов не особо надо.
На самом деле я вот сейчас зашёл в яндекс.диск через webdav. Просто нажал на закладку в файловом менеджере и всё открылось. Без специального гуя, без клиентского софта от яндекса, только используя инструменты общего назначения, реализующие общепринятые стандарты. Это возможно. Никакой проблемы нет. Просто надо делать по-человечески.
Тут выше приводили притчу про двух программистов, но почему-то, когда защищается принцип, что можно делать быстро и экономно, про нее забывают… и все подавай уже сразу
Мы все ещё рассчитываем обойтись без раздутых либ :)?
VPN не обязательно встраивать в приложение, соответственно и библиотеки для этого в самом приложении не нужны.
Как вы считаете, сколько сейчас пользователей хабра сидят через VPN?
Вы будете всем пользователям объяснять что для их безопасности надо использовать VPN? А без VPN как, приложением пользоваться запретите? А объяснять то что бесплатные VPN так же воруют траффик, тоже будете?
А когда у известного блоггера украдут его/ее фотки которые он залил на ваш сервис, будете говорить что "он сам виноват потому что не было VPN, а если был то нет тот"?
Чтобы не усложнять архитектуру добавлением ещё одного элемента, мы добавим в неё ещё один элемент.
Сложность приложения мало кого волнует. Волнует сложность системы. Теперь, чтобы настроить систему, нужно на 1 участника больше. Чтобы диагностировать проблему в системе, нужно на 1 участника больше..
А если допустим тот FTP (или аналог) для решения простой задачи:
есть читалка книг на андроиде, с синхронизаций позиции между разными экземплярами.
Еще и VPN городить с андроида к конкретно нужному серверу?
(кстати есть читалки с таким подходом — Moon+ Reader например, только там вшитая поддержка Dropbox/Google Drive/WebDAV)
Еще и VPN городить с андроида к конкретно нужному серверу?
Поставьте задачу девопсу. Он же всё равно есть ;)
Почему Вы передёргиваете мои слова?
Я разве говорил о конечных приложениях на устройствах пользователей?
Значит, этот подход плохо масштабируется, и вместо раздувания кода требует раздувания штата. К каждому клиентскому устройству должен подойти специальный человек и чего-то настроить. Так себе решение.
Причём здесь масштабирование и клиентские устройства?
Я предложил решение завернуть обращение к FTP в VPN в строго ограниченных условиях: сервисное приложение, которое работает на стороне компании-разработчика и взаимодействует с FTP-сервером в его же собственной инфраструктуре.
Конкретно в таком случае, это будет неплохое решение, позволяющее не усложнять разработку, но сохранить приемлемый уровень безопасности и надёжности.
Я не утверждал, что это универсальное решение. Можете прочитать ветку от начала, чтобы убедиться в этом.
Поворчать, это конечно весело. Но давайте спустимся на землю.
В реальном проекте, если бы я увидел, как кто-то пишет свой обход JS'овсвского объекта, вместо использования lodash - я бы немного РАССТРОИЛСЯ. И да, вроде как те же аргументы: обойти-то просто, из библиотеки нужно 2,5 функции. Только вот ты не один обычно над проектом работаешь. Один написал свой обход так, другой - эдак, третий - придумал еще что-то. В результате, у вас 100500 реализаций обхода объекта, чтобы просто получить значение свойства, причем каждый реализует по своему. А затем приходит еще один человек, он видит эти 100500 этих функций, в результате не понимая, чем они отличаются - делает свою и у вас 100501 функция.
И да, на истории про то, что у вас должны быть ревью, должна быть архитектура, диаграммки UML, четкая документация, чтобы все знали что уже есть, чего нет, как нам с этим работать, кто-то должен следить и т.д. Ну, да. Только вот как-то так получается, что в реальном мире - никто особо не хочет ревьюить чужой код, особенно, когда есть свои задачи; архитектура не успевает за хотелками; диаграмки - устаревают и никто их не поддерживает; документацию пишут недостаточную; вся информация о проекте в несколько миллионов строк не держится в голове; а нанять сертифицированного следителя за порядком - бизнес не хочет. А потому - нужно выбирать решения, которые стандартны, которые проверены и бить по рукам тех, кто будет без острой необходимости свое писать.
А что там в lodash такого небесполезного?
И, кстати, из lodash, вроде, deepEqual можно вытащить условно-отдельно ;)
Только зачем?
Вот, собственно, тут мы и наблюдаем причину всё увеличивающихся тормозов и раздувания. И она не в том, что скорость/размер софта меняется на скорость/надёжность разработки. И даже не в том, что нет времени искать лучшее решение. И даже не в том, что лучше найти не удаётся. А в том, что даже когда тычешь человека носом в тех анализ и бенчмарки, всё, что он может сделать - это дизлайк поставить, и идти говнокодить дальше.
Я lodash привел как пример. Его все знают и понимают что оно делает и зачем нужно.
Если говорить, что нам всегда критична скорость и размер. Ну давайте откатимся к си, откажемся от жутко тормознутого HTTP, который даже с HTTP3 - будет проигрывать кастомному бинарному протоколу под конкретные задачи. Ну а что? Скорость работы и размер - самое важное. Взяли си в зубы и пошли хендлерами обмазываться, да свои алокаторы писать, потом запилили свой очень быстрый клиент на OpenGL. Скорость и размер - главное. Такое вот решение будет пару КБ весить и летать на компьютере 30 летней давности. А то что потом никто поддерживать и развивать не сможет - ну, да и фиг с ними, своего времени не жалко, денег заказчика не жалко, пользователей, которым это все инсталлировать - тоже не жалко, так что напишем еще раз с нуля, желательно, сломав обратную совместимость.
Да, тут я ерничаю. Но вот вы прицепились к lodash, будто суть поста была в его рекламе. Я лишь говорил о том, что чтобы писать свой велосипед - нужны веские основания, потому что свой велосипед это дополнительные траты на поддержку, развитие, введение в курс дела новых разработчиков, и далеко не факт, что ваш велосипед будет лучше чем тот, который уже есть.
И под С/C++ есть свой lodash. И не обязательно откатываться к си. И писать прям с нуля, свой гуй, потом реализацию протокола, потом компилировать вселенную и т.д не ребуется.
Его все знают и понимают что оно делает и зачем нужно.
Ну я вот не знаю его. А глядя в его код, не понимаю зачем оно такое нужно. Это ж груда кода, которая делает простые вещи сложным и медленным способом - квинтессенция современной разработки.
Я лишь говорил о том, что чтобы писать свой велосипед - нужны веские основания
Чтобы использовать низкокачественные решения нужны веские основания, независимо от того кто их автор.
Объясните плиз бэкендеру, что за значения на скриншоте.
Вопрос был не совсем в этом :) Ну да неважно
Так были же и альтернативы. Например, CppCms - быстрая и эффективная CMS, написанная на плюсах. Но проект сейчас заброшен - очевидно, оказался никому не нужным...
Необходимо учитывать ещё непостоянные требования пользователей, которые реализуются в рамках проекта. А когда они становятся не нужны их просто хоронят в коде.
Вот, писали мы одно простое приложение, которое считавало адреса проводов со схемы и, по требованию пользователя, записывало их в таблицу Excel. Раз десять уточнили, точно ли они хотят именно файл Excel. Формат в ТЗ прописали. Дошли до сдачи проекта, а там требуется обычный текстовый файл с разметкой csv. Спрашивается, и на кой, мы обращались к Excel?
Естественно, код обращения к Excel удалять не стали, просто закомментировали. Потому что csv из Excel быстрее выгрузить.
И так, курочка по зернышку клюёт.
Это естественный результат развития аппаратного обеспечения. Пока мы (были) на экспоненциальной части S-кривой ничего не изменится. Когда мы окажемся на логарифмической, вот тогда бережливые программисты будут нарасхват.
<зануда mode> Не могу не отметить, что вообще то "этита" помещалась в 48 Kb памяти, причем ещё около 6 КБ из этих 48 были выделены под "экран", и, таким образом, не использовались для хранения кода.
А вообще - Синклер был прекрасной машинкой, которая - в то время - многому меня научила.
До сих пор проходят (под эгидой Яндекса, если что) соревнования по написанию игр для Синклера. Финал-в декабре! Ещё можно успеть...
А ссылку дадите? На соревнование?
Вероятно имеется в виду вот это: https://rgb.yandex.ru/
Это уже не bloatware и не оверинжиниринг, а абсолютное, совершенное, очевидное, наглядное безумие.
Да, безумие, и всем плевать. Менеджменту плевать, потому что он очень далек от этого всего, а программистам просто западло озвучивать проблемы, потому что в современном мире говорить о проблемах это уже токсичность. А токсичность - это самый страшный современный грех. Пускай прод регулярно падает, пускай юзеры матерятся в техподдержке - главное чтобы внутри команды все было модно/молодежно/позитивно.
Меня поражают намного более приземленные вещи. Возьмем двух программистов:
Один программист пилит фичу 5 дней, потом в ней находят 2 бага, которые исправляются за 2 дня [7 дней суммарно]
Другой программист пилит фичу 2 дня, потом в течении года в ней находят 20 багов, которые он правит за 10 дней [12 дней суммарно]
Казалось бы, с точки зрения логики первый программист лучше - суммарно и времени потрачено меньше, и ошибок меньше - т.е. более довольные клиенты.
Но по факту, в компании за компанией я вижу ситуации, когда в пример ставят программистов второго типа, которые "быстро делают задачи" (как фичи, так и баги) а то, что можно потратить время на написание авто-тестов, и нормальный код, а потом ошибок будет в разы меньше - это вообще находится за гранью понимания.
Это потому, что второй быстрее доносит Value до рынка, и бизнес быстрее начинает зарабатывать деньги на фиче :)
Миром разработки рулит маркетинг, это давно свершившийся факт
Это потому, что второй быстрее доносит Value до рынка, и бизнес быстрее начинает зарабатывать деньги на фиче :)
Неверно :)
Фича выпускается только тогда, когда ее качество достаточно до донесения Value и, соответственно, получения прибыли
Терминальные случаи статистики не делают и быстро из оной выпадают :)
Фича выпускается только тогда, когда ее качество достаточно до донесения Value и, соответственно, получения прибыли
Вы выпустили из внимания последнее предложение в моем предыдущем посте ;)
В целом, процессы планирования и, как следствие, выставления KPI, в частности - обычно, достаточно выстроены в любой нормальной компании
"Ненормальные" же - живут интересно, но недолго :)
Вы выпустили из внимания последнее предложение в моем предыдущем посте ;)
Один программист пилит фичу 5 дней, потом в ней находят 2 бага, которые исправляются за 2 дня [7 дней суммарно]
Другой программист пилит фичу 2 дня, потом в течении года в ней находят 20 багов, которые он правит за 10 дней [12 дней суммарно]
Я ему не придал значения
А напрасно - это ключевой момент :)
Проблемный релиз — это не терминальный случай.
Проблемный релиз в проде - это именно терминальный случай
Это обычный типовой кейс сейчас, на 100% соответствующий вышеописанной ситуации про
Нет, не соответствующий :) Ибо в течение года компания получала профит, который, обычно, порядково превосходит затраты на фиксы
А что касается процессов планирования, ну, я много компаний повидал.
Ну, а я много где участвовал в этих процессах :)
В целом между качеством планирования и жизнью компании особой корреляции не могу проследить.
Мне остается только посочувствовать :)
Рынок ИТ сейчас такой, что прокормит кого угодно, даже полнейших бездарей, лишь бы у них отдел продаж работал.
Вы почти подтверждаете мой тезис :)
Если бездари производят то, что можно продать, а прибыль от продажи покрывает расходы - то это и есть то, о чем я говорю :)
Если бездари производят то, что можно продать, а прибыль от продажи покрывает расходы — то это и есть то, о чем я говорю :)
Продаётся продукт, а не релиз, не фича
Фича - часть продукта
Даже бесплатная - может увеличить продажи
Это, в общем-то, азы, наверно, не надо их объяснять :)
Релиз может быть сколь угодно проблемный, фича может сколь угодно тянуть вниз расходами на поддержку и исправления.
Это те самые терминальные случаи, которые я предлагал не использовать как основу для статистики ;)
Речь про том, что сейчас это в порядке вещей,
Именно
Я ж так и сказал - разработкой рулит маркетинг, как и бизнесом в целом
Это теперь в порядке вещей
менеджер все равно получит свою премию
Не за выпуск релиза же, что вы )
За выполнение роадмапа, например
Или за рост DAU/WAU/MAU
Или за рост retention
Или за выполнение любого другого операционного показателя, который прямо связан с его KPI
расходы на исправление проблем лягут в операционку, и никто там резкость наводить не будет.
Это норма
Техдолг любого коммерческого проекта - история грустная. И, очень часто, весьма объёмная :)
Это, в общем-то, азы, наверно, не надо их объяснять :)
Это те самые терминальные случаи
Это норма
Да, но я думал, для вас очевидно, что ещё фича может никак не повлиять на продажи (это, кстати, очень частый кейс), а может увеличить расходы, а может оттолкнуть пользователей своей реализацией.
Нет, не очевидно :)
Ибо реализация любой фичи - это затраты, которые должны окупаться, прямо или косвенно, а продажи - далеко не единственная метрика :)
Что же до "оттолкнуть пользователей" - это все благородно, но решит все MAU, а не недовольство отделных пользователей
Фичи — они все разные, понимаете ли.
Ваш намек на некую снисходительность в тоне выглядит забавно :)
Особенно, на фоне демонстрируемого понимания процессов, отличных от собственно разработки ;)
Фичи - они разные на вид, о реализация любой фичи имеет ту самую ценность, Value, ради которой и запускается ее разработка. Бизнес рассчитывает на тот или иной профит в результате ее реализации - иначе и быть не может
Терминальные случаи — это нечто, бывающее редко, и служащее надгробием какому-то процессу.
Вы преувеличиваете :)
Нечто весьма обыденное и проходящее бесследно, терминальным случаем не может быть по определению :)
Бесследно? Как легко вы списали затраты на разработку ;)
Да. И это — отстой.
Вообще, нет. "Отстой", как вы выразились, это как раз то, что вы называете отстоем ситуацию, в которой вам платят деньги за работу :)
Понимаете ли, любой наемный программист нанят не для самореализации и креатива, а для выполнения той работы, результат которой нужен заказчику и плательщику - это нормально и закономерно. Кто платит - тот и заказывает музыку :)
Ибо реализация любой фичи — это затраты, которые должны окупаться, прямо или косвенно, а продажи — далеко не единственная метрика :)
Как легко вы списали затраты на разработку ;)
Понимаете ли, любой наемный программист нанят не для самореализации и креатива, а для выполнения той работы, результат которой нужен заказчику и плательщику
Понимаете, я в этой отрасли очень давно, третье десятилетие как.
Ну так и я не первый десяток лет уже :)
Но их как минимум, нет ни в одной из компаний, где я работал, и нет ни в одной партнёрской компании, с которыми я сотрудничал.
У меня совершенно противоположный опыт - везде было именно так :)
у меня нет оснований считать, что моя выборка недостаточно представительна.
Ну, как минимум, есть моя выборка :)
И даже если есть бизнес-план, в нём всегда будет достаточное количество условных цифр, которые помножат на ноль точность планирования.
Как это "даже если есть"? Кто ж без бизнес-планов с роадмапами денег даст на разработку? :)
Это штатная ситуация, возникающая везде и регулярно.
Ну, вообще, это как раз НЕштатная ситуация :)
И, если она возникает регулярно - то гнать надо тех, кто занимается управлением в этой части
Бизнес по определению имеет риски.
Бизнес имеет как риски, так и риск-менеджмент, если он здоровый
Грамотное планирование и следование планам как раз один из инструментов, в частности, минимизации рисков
И если бы всех наказывали за ошибки в бизнесе, никто бы в бизнес не шёл работать.
Очень странный вывод
Во-первых, в бизнесе наказывают за ошибки :)
Во-вторых, причина "пойти в бизнес" - не в безнаказанности
У меня совершенно противоположный опыт — везде было именно так :)
Как это «даже если есть»? Кто ж без бизнес-планов с роадмапами денег даст на разработку? :)
Бизнес имеет как риски, так и риск-менеджмент, если он здоровый
Грамотное планирование и следование планам как раз один из инструментов, в частности, минимизации рисков
Во-первых, в бизнесе наказывают за ошибки :)
Во-вторых, причина «пойти в бизнес» — не в безнаказанности
Ок, я принимаю, но своим глазам все равно верю больше, чем вашему опыту.
Ваше право, конечно :)
… потому что вы не замечаете, что в подавляющем большинстве компаний, которые ведут какую-то ИТ-разработку, «даст денег» и «предлагает реализовать фичи» одно и то же лицо или группа лиц. Слона вы не заметили :)
Эм. Очень интересно про слона :)
Вообще-то, я прямо писал, что деньги дает бизнес :) Соответственно, роадмапы и заказ фич - это именно то, что хочет и за что платит бизнес :)
Так что, еще вопрос, кто что не заметил ;)
В ИТ на одного отлаженного гиганта или вымуштрованного стартапа, который бегает питчить инвесторов, приходится сотня вот таких компаний.
Зачем приводить в пример нежизнеспособное? :)
Процессы продумываются не от излишка времени и денег, а для повышения эффективности и, как следствие, конкурентноспособности бизнеса
Выживет тот, кто эффективнее
Да. И не имеет, если он обычный
Тогда его ждут сюрпризы, чаще - неприятного характера :)
А ещё бизнес может работать в условиях недостатка информации для грамотного планирования
Бизнес - не может, в долгосрочной перспективе
"Бизнес" - возможно, останется жить
Вы забыли добавить слово «иногда», и тогда это не пойдёт в противоречие с моим тезисом.
Нет, не "иногда" :) Для бизнеса
А кавычки надо добавлять только вместе с окавычиванием "бизнеса" - тогда все будет похоже на правду :)
Вообще-то, я прямо писал, что деньги дает бизнес :) Соответственно, роадмапы и заказ фич — это именно то, что хочет и за что платит бизнес :)
Зачем приводить в пример нежизнеспособное? :)
Бизнес — не может, в долгосрочной перспективе
А зачем бизнес будет сам себе писать и защищать бизнес-план, если он, кхм, небольшой, и например, состоит из одного босса и команды разработчиков?
Чтобы стать крупнее, например? :)
Вы правда считаете нежизнеспособными те предприятия, которые вам готовят еду, убирают вашу квартиру, шьют вам одежду и т.д.?
А они являются ИТ-предприятиями? :)
По-моему, речь шла про них
Не надо быть заносчивым в отношении тех компаний, которые работают по более простым бизнес-процессам.
Не надо придумывать за собеседника ;)
Нет никакой заносчивости, вам показалось
например, они намного быстрее адаптируются под изменения рынка, и отсутствие планирования с лихвой компенсируется короткой обратной связью с рынком и быстрым принятием решений.
И у вас есть примеры? :)
Чтобы стать крупнее, например? :)
А они являются ИТ-предприятиями? :)
Не надо придумывать за собеседника ;)
И у вас есть примеры? :)
Бизнес сначала становится крупнее, а потом пишет бизнес-планы.
У вас какое-то бинарное понимание процессов роста :)
Он может стать крупнее - и стремиться стать еще крупнее, это нормально для бизнеса ;)
Часть (бОльшая, к слову) ИТ-предприятий являются таким же мелкими, с точно так же выстроенными бизнес-процессами.
У вас, конечно же, есть статистика, которой вы можете подтвердить свои слова? ;)
«Бизнес» в кавычках — это разве не заносчивость?
Нет :)
Возможно, спутал с пренебрежением.
Совершенно точно перепутали :)
Да. И у вас тоже есть, если по сторонам посмотрите чуть внимательнее :)
То есть, у вас нет примеров, я правильно понимаю? :)
Иначе - что мешает вам обосновать свои слова оными примерами? :)
У вас какое-то бинарное понимание процессов роста :)
У вас, конечно же, есть статистика, которой вы можете подтвердить свои слова? ;)
Совершенно точно перепутали :)
Иначе — что мешает вам обосновать свои слова оными примерами?
Вы нечаянно подменили предмет вопроса, или специально воспользовались известным приёмом? ;)
Вообще-то, это именно вам я указал, что ограничивать понятие "роста" некорректно
Вы правда без меня не сможете нагуглить, что примерно четверть ИТ-работников сейчас работают в компаниях размером 1-9 человек, где в принципе не может быть многоуровневого менеджмента, и четверть — в компаниях 10...49 человек, где максимум два уровня, причём один обычно технический?
Извините, конечно, но в приличных местах принято обосновывать свои утверждения - а вы старательно этого избегаете
Ок, поменяйте в моей исходной фразе «заносчивость» на «пренебрежение».
Про "пренебрежение" я сказал чуть ниже в том же посте
Лень
Это плохо кореллирует с объёмом ваших постов
На это надо намного больше времени, нежели просто написать вам ответ, а переспорить вас мне не настолько важно :)
"Я три дня бежала за вами, чтобы рассказать, насколько вы мне безразличны" (с)? ;)
Увы, пока я вижу много ничем не подтвержденных слов от вас, которые противоречат и здравому смыслу, и общемировой практике
Вообще-то, это именно вам я указал, что ограничивать понятие «роста» некорректно
Извините, конечно, но в приличных местах принято обосновывать свои утверждения — а вы старательно этого избегаете
Это плохо кореллирует с объёмом ваших постов
ничем не подтвержденных слов от вас, которые противоречат и здравому смыслу, и общемировой практике
Ну да, я вообще-то заметил, что именно вы подменили вопрос и указали мне, что после подмены вопроса к нему появились замечания.
Поясните с цитатами, что и на что я, по-вашему, подменил
Это было слишком тривиальное утверждение, чтобы мог допустить мысль, что вы, человек явно не с улицы в ИТ-бизнесе, не смог бы быстро и самостоятельно проверить.
Это было ВАШЕ утверждение, ничем не подтвержденное, увы :)
publications.jrc.ec.europa.eu/repository/bitstream/JRC106589/jrc106589(1).pdf
Интересно, вы смотрели этот документ сами? :)
Про количество занятых - не подскажете, в какой таблички или на каком графике вы смогли найти те процентовки, которые пытаетесь этим документом обосновать?
Я захожу на Хабр потрепаться, а не работать аналитиком.
Это было ожидаемо :)
Странно, а с моей стороны я вижу оппонента, который мне написал множество ничем не подтверждённых заявлений, которые противоречат и здравому смыслу, и общемировой практике.
Например?
Если у вас есть основания полагать, что ваша точка зрения верна, жду от вас ссылок.
Вы знаете, "сам дурак" - это тоже демагогия :)
После прочтения таких статей, ради самоуспокоения всегда напоминаю себе о том, как возросли наши требования как пользователей:
все разучились управлять информацией. Никто больше не ценит простые инструменты, вроде иерархической файловой системы в целях создания порядка. Тех, кто раскладывает музыку во FLAC-е по сотням папочек, считают душными дедами. Все пользуются поиском на стриминговых сервисах.
ладно, не все разучились. Кто-то не умел с самого начала, и вряд ли бы научился. Ведь мы пригласили пользоваться информационными технологиями своих родителей, своих друзей. Им нужны более интуитивные интерфейсы, анимации, подсказки.
теперь мы рассчитываем на информационные технологии ГОРАЗДО сильнее, чем ранее. Многие уже забыли, что такое BSOD и фарш на файловой системе просто при наборе текста в Word. Согласитесь, даже ненавистная Винда сегодня куда более стабильная, чем её древние предки 95/98/Me.
многие вещи, вроде уже упомянутого Юникода, воспринимаются как должное. А за это тоже нужно платить сложностью. Тот же протокол TLS, который по меркам 90-х - супернавороченная вещь уровня дорогущего банковского ПО. А сейчас мы боимся даже картинку скачать по HTTP, вдруг куки/токены угонят.
Ну т.е. если подумать, у софта было достаточно причин стать сложнее.
Конечно, ситуация с JS, вебом и этими вашими Электронами - это другое (c). Это просто одна немаленькая корпорация выиграла битву за программную платформу, и мы пожинаем плоды этой победы. Надеюсь WebAssembly когда-нибудь свергнет JS с должности платформы, "под которую лучше писать по-умолчанию, чтобы дотянуться до максимального числа пользователей". Мне кажется, это самое большое легаси во всём IT на данный момент.
Так винда стояла и стоит на 95% пользовательских машин. Значит то, что было на ней и было нормой.
Всех машин в истории не надо смотреть, надо смотреть "машин, что видели люди в тот конкретный момент". А насколько я помню в те времена мейнфреймные терминалы отошли в прошлое, сервера большинством машин быть не могут, большинство домашних и офисных машин были персоналками. Если еще во времена винды 1-3.11 можно говорить, что под досом больше народу сидело, то 95-Ме уже ой.
В итоге, для массовых пользователей остаются вин, OS/2, НетВарь, никсы, дизайнерская экзотика (саны и маки).
Среди этого зоопарка кажется винда в абсолютном приоритете.
Добавлю что еще все думают об "обработке моего хорошего правильного файла" и совершенно забывают, что файл могут прислать хз какой. Как думаете сколько дыр и ошибок даже не появляется при использовании готовых библиотек? Все же готовые библиотеки раздуты еще и потому, что там стоит 100500 ifelse на проверки всяких условий корректности входящих данных, непропускания абракадабры, обработки всяких граничных условий и т.п.
Я как тестировщик только с какими "глупыми" ошибками не сталкивалась даже у очень опытных программистов. А какое разнообразие эффектов это дает!
Кому доверите написание своего софта: тому кто за год научился пользоваться готовыми библиотеками или тому, кто за два года научился писать что-то низкоуровневое и быстрое? Даже не зависимо от сроков и цены разработки. Главный критерий: программа стабильно корректно работает на среднепользовательском железе.
Вам кажется. Чем больше всяких штук надо учесть, тем больше шансов наделать неочевидных багов. А если вы собрались писать все сами и без либ, то учитывать придётся ну ОЧЕНЬ много всего.
Ну если делать во первых свою, во вторых маленькую задачку - то ОЧЕНЬ много и не надо. Правда при попытке масштабировать или расширить сразу все это вылезает самым неожиданным образом и оказывается, что не все библиотеки были написаны дураками.
Я за технологичную избыточность, где при всем желании трудно наделать критических ошибок. Какой бы области это не касалось.
Я боюсь, в итоге победит не webassembly, а мобилки. Уже сейчас у целой кучи бизнесов нет своего сайта или есть только простейший лендос, но зато в каждом сторе по полнофункциональному мобильному приложению.
Понятно, почему так произошло - веб очень плох и сильно запоздал и со стандартизацией, и с отображением на устройствах, но к чему это приведет, страшно даже гадать. Вместо единого протокола и единой среды, где можно качать/смотреть/делать что угодно, вам придется приседать и качать приложения, над которыми у вас нет никакой власти. Даже банально текст не сможете выделить и скопировать :) А ещё в разы вырастет (да уже выроста) власть владельцев сторов, потому что они на раз могут одним щелчком мышки заруинить любой бизнес просто удалив приложение из своего стора. Всё же с вебом такое было проделать куда сложнее.
Автор так ворчал в 50 лет, а я так ворчал в 31 год https://habr.com/ru/post/379231/
да много кто уже) https://habr.com/ru/post/423889/
Изменения будут только тогда, когда большой размер и тормоза будут вызывать общественное "фи!". Но как этого добиться я не знаю. Возможно, кто-то крупный должен демонстративно это показать. Ну или просто вводить для программистов телесные наказания за неоптимизированный или кривой код. С такими огромными зарплатами можно и требовать много, и наказывать за неисполнение качественно, чтоб неповадно было.
Какими огромными зарплатами? Уже не раз обсуждалось, что в России у всех остальных профессий зарплаты ниже плинтуса, а не у программистов огромные.
Общественное фи будет, если общество будет уметь отличать качественный и быстрый софт от шлака.
Но как бы его научить?
Я раздумываю, что может стоит активнее следить за друзьями/знакомыми и чаще им демонстрировать: "Смотри, программа X, которой ты пользуешься для решения своей задачи, очень толстая и неповоротливая. Программа Y для этого же гораздо шустрее". Чтобы нарабатывался вообще навык, что можно требовать, чего ожидать. Кроме нас объяснить это некому. Что думаете?
Да достаточно просто кому-то популярному это продемонстрировать. К примеру, есть два популярных онлайн-магазина, конкурирующих между собой, у обоих сайты еле ворочаются. Но тут один вкладывается в переработку своего сайта, и его сайт начинает открываться за считанные десятые доли секунды, как обычные HTML-страницы. При примерно равных ценах покупатели подсознательно не захотят идти на тормозной сайт, а пойдут и купят там, где всё быстро. Тогда и конкурент вложится в оптимизацию, не забыв прорекламировать это, а дальше всё само пойдёт.
Рискну предположить, что в 90% случаев ответ будет "да, она тормозит, но я ж, если на Y перейду, буду с ней десять лет учиться работать и не факт что вообще научусь, а X уже вдоль и поперёк знаю".
Если Y решает поставленные задачи и способен корректно открыть уже существующие файлы от X, то перейдут очень быстро.
Но так не решает же. Нет, когда "умный компьютерщик" садится и показывает, то всё решает, конечно, а когда сами - тут кнопочка потерялась, которая в X была вот там, тут сообщение непонятное вылезло, и так далее и тому подобное и так далее. Может, конечно, у меня перекос восприятия из-за собственного опыта с "юзверями", может, это исключение, а не правило.
Идём на официальный сайт DELL, сапорт, драйвера, XPS 15 9520, Realtek Audio Driver, скачать. 428 MB (449,775,856 bytes). 400 всратых мегабайт на драйвер звуковой карты? Какого черта?
Несколько вопросов к вашему коду:
вирусы в файлах искать умеет?
конфигурировать какие типы(размеры) файлов можно какие нельзя умеет?
без проблем масштабируется на несколько дата-центров?
держит нагрузку в 100500 рпс?
поддерживает разграничение доступа?
может предоставить статистику по любым параметрам за любые сроки?
в случае проблем - умеет отсылать нотификации в различные мессенджеры?
тарификационная сетка на оплату есть?
ну и т.д. и т.п
Вы не представляете как около-сервисные навороты способны раздувать кодовую базу...
Все так и есть, уровни абстракции постоянно повышается.
~20 лет назад надо было долго изучать С или, упаси бог, ASM, набить кучу шишек и лет через 5, может быть, получится написать что-то достойное.
А сейчас нет этих 5-и лет, вот нету и все. Пока будешь писать идеальный код на чистом C, чтобы быстро работало и мало весило - школьник на питоне с 20-ю библиотеками решит поставленную задачу за пару дней. Вот и все. А то что варианту на C нужен калькулятор, а варианту школьника core i9 и 32 гига оперативы.. да кого это волнует сегодня? Бизнес, в большинстве случаев, не волнует - купить железо быстрее и дешевле, чем ждать супер-эффективный вариант на С и оплачивать его разработку. А если потом ни дай бог требования меняться начнут? А новые версии? То все, пиши пропало, конкуренция сожрет мгновенно.
Так что по сути, основная причина - сугубо экономическая, все остальное вытекает из этого.
Я не к тому что это все правильно. Меня тоже бесит, что современный софт занимает дохрена места, а электронные таблицы и текстовый редактор и в windows 3.11 не плохо работали, так то.
Но как есть. Какая то логика в текущем варианте развития тоже присутствует.
~20 лет назад надо было долго изучать С или, упаси бог, ASM, набить кучу шишек и лет через 5, может быть, получится написать что-то достойное.
Почему экономика любимая? Я просто описал почему так случилось.
Спрос на разработку сильно вырос, а порог вхождения в профессию снизился.
В том числе за счет всех этих фреймворков, библиотек и прочего барахла которое тащит с собой любое приложение, а использует 1% от всего этого барахла. Но писать стало быстрее. Выигрывается время, а время - деньги, как известно.
С технической же точки зрения - это ппц, конечно.
Не, это крайне простой механизм. Реактивность как раз таки позволяет снизить сложность, так как всё, что надо знать - это только текущее состояние, а не текущее состояние + то, как мы в него попали. А кто инициатор изменения состояния, если что, отслеживается обычный брейкпоинтом.
Это 25 лет практики. Если для БЛ важно "как мы сюда попали", это должно быть отражено в текущем состоянии, а не быть размазано по стеку.
То есть по ссылке вы не ходили, я правильно понимаю? Что именно в обычных объектах с мемоизированными методами нечитабельного и нелогичного?
this.Amount = getSomeAmount();
...
property Amount { set: (value) => { txtAmount.text = value; updateTotals(); } }
state.Amount = getSomeAmount();
state.TotalAmount = calculateTotalAmount();
setState(state);
...
<amount>{Amount}</amount>
<total>{TotalAmount}</total>Вот пример реактивного кода:
@mem Amount( next = 0 ) {
return next
}
@mem Total() {
return this.Amount() * this.Price()
}
@mem view() {
return <>
<amount>{ this.Amount() }</amount>
<total>{ this.Total() }</total>
</>
}Любая IDE умеет в Find Usages, так что искать глазами нет необходимости.
А то, что вы написали - интерактивный код. По мере роста приложения он превращается в тормозное (из-за лишних апдейтов), глючное (из-за забытых апдейтов), нагромождение лапши (из-за условных апдейтов и множественных зависимостей).
Но не мне вас учить, да.
А то, что вы написали — интерактивный код.
тормозное (из-за лишних апдейтов), глючное (из-за забытых апдейтов), нагромождение лапши (из-за условных апдейтов и множественных зависимостей).
Ага, эти ребята тоже всё напутали: https://en.wikipedia.org/wiki/Interactive_computation
И интерактивный код, и реактивный являются императивными, так как описывают алгоритмы, а не результат.
interactive computation is a mathematical model for computation that involves input/output communication with the external world during computation.
Никакого. Это имеет отношение к пробелам в вашем кругозоре, где интерактивным может быть только UI, а ничего другого "с таким названием не изобрели". С пониманием императивности/декларативности у вас тоже беда. Я бы предложил вам почитать, но вы ещё предыдущую статью не осилили. Продолжать терминологические споры мне не интересно.
Но при дебаггинге все-равно надо знать как и почему вы пришли вот в это сломанное состояние. Как иначе его починить?
20 лет назад был 2002 год
Delphi - да, PHP - еще нет, как массовое явление статика на чистом голом HTML. PHP — это еще ~+5 на календаре, вторая половина нулевых
Экономике bloatware пока не вредит так, чтобы это было ощутимо в цифрах (и тезис "вредит" лучше все же доказывать, потому что аксиоматичность его под большим вопросом), потому процесс и продолжается
Уверен, что никто из кодеров не представляет, почему это происходит, а
код в его основе — это просто куча раздутого скопипащенного навоза.
Скорее всего кто-то представляет.
Проблема не в том, что код хреновый. Проблема в том, что на фиксы таких мелочей не выделяется время. Нужно деливерить фичи. Закончили одну фичу, тут же начинается следующая, потому что она была распланирована еще на позапрошлый месяц. Все некритичные проблемы, промахи и т.д. отправляется в категорию тех. долга. Если проблема становится критичной она фиксится. Иначе она существует годами до смерти фичи.
Это типичная история любой крупной компании, любого долгоиграющего проекта.
Это происходит не только потому, что кодеры не пишут низкоуровневого эффективного кода для достижения своей цели: они просто никогда не видели низкоуровневого эффективного, хорошо написанного кода.
Проблема более комплексная. ИМХО она вообще в другой плоскости. Я бы сформулировал так:
Подавляющее большинство программистов пишет тупой процедурный код. Говорят ООП, а на самом деле гоняют тупые ДТО между функциями. В таком коде сложно выделить абстракции, определить границы. Все связано со всем.
При увеличении требований и сложности продукта это приводит к экспоненциальному росту количества кода. Получается порочный круг. Код сложный для понимания - он обрастает костылями. Костыльный код становится сложнее понимать.
В такой системе низкоуровневый код невозможно поддерживать. Потому что он не отделен строгой границей. Его начинают копировать, подгонять под требования. И получаем проблему о которой говорил автор.
Проблема в том, что на фиксы таких мелочей не выделяется время.
Я говорю больше о продуктовых компаниях. Тут свой набор проблем. Можно статью писать. Навскидку:
Фичи планируются на несколько месяцев вперед. Первая фича ломает весь график, и остальные уже делают в режиме "на вчера". И так до бесконечности. Планирование то делают не инженеры. Их только ставят перед фактом дедлайнов.
Даже небольшое изменение кода требует больших ресурсов на анализ и тестирование. Потому что код пишется с учетом существующих проблем. И фикс проблем создает новые проблемы. Гейтинг не панацея.
Промо культура требует импакта. Вот прям так. Получается, что выгодно сделать фичу побыстрее, набрать тех. долга, а другие разберутся. Плюс важно уметь продавать свои заслуги. Можно делать полнейшую фигню и получать повышения. А можно делать важные вещи, но не презентуя их правильно, получать отказы. Очень выгодно заделиверить фичу, набрать тех. долга, а остальные потом разберутся. И каждый разработчик думает "а чем я хуже", и круг продолжается.
Я тоже раньше читал статьи про ужасную культуру разработки в Гугле и прочих, и думал, что это все фигня, и зависит от команды. Попав в Калифорнийскую компанию, я понял, что, к сожалению, все реально так плохо.
1С напомнило
Чем напомнило? БСП не нравится? Про Inversion of Control не слышали?
Это проблема прикладных разработчиков на местах, а не разработчиков БСП и типовых конфигураций. И проблема эта, по большей части, заключается в том, что большинство прикладных разработчиков на платформе 1С ничего, кроме Радченко и Хрусталёвой, не читали.
В мире 1С всё нормально. Для контраста можете пойти поработать в какого-нибудь интегратора на его внутренней самописной платформе на языках общего назначения с возможностями, по сути, такими же, как у платформы 1С, но без документации и с гораздо более низкой скоростью доставки новых фич. Отчёты на каком-нибудь JasperReports после СКД трудно воспринимать как что-то удобное в разработке.
Вот была хорошая статья на тему: https://habr.com/ru/post/480658/
Очень много времени приходится тратить на изучение зависимостей, которые ты хочешь использовать в проекте. Сравнение доступных вариантов, изучение их истории, перспектив, в идеале состояние кода.
Не понятно наличие картинок из Elite. Игра с процедурной генерацией вряд ли предполагает процедурную генерацию требуемого кода по запросу и некоторой экономии таким образом. Тут скорее бы подошёл какой нибудь пример из демосцены, где с ограничением по памяти умещают большой функционал и могут это просто показать.
Когда-то были (а может и сейчас есть) соревнования по программированию в размере 1024 байта. Чего только туда люди не всовывали. Мне запомнился почтовый клиент и уровень от Castle Wolfenstein. Забыл сказать - исполняемый файл - COM, операционка - DOS.
Несть числа раз видел, как много раз упомянутый выше "эффективный и талантливый" код приходилось полностью нах выкидывать и переписывать с нуля, потому что кроме его эффективного и талантливого автора (к тому времени уже свалившего в закат) в этом коде никто нихера не мог понять. Наверное все были просто недостаточно эффективны и талантливы для этого.
Ну, если код работал ка надо, а вы не понимаете "как" значит ваш уровень ниже уровня автора кода. А люди обычно не любят (мягко выражаясь) тех, кто талантливей их.
А равняться по тупейшим - путь в никуда.
Ваш комментарий поднимает старый вопрос: программирование - это искусство или ремесло? Если ремесло и автомобильный конвейер - ближайший аналог, то лучше выстраивать процесс, ориентируясь на добротного середнячка-исполнителя, именно он будет фиксить баги и точить новые фичи. И именно он будет читать код предыдущих программистов. У вас просто не будет столько гениев, чтобы заполнить конвейер (ну, если вы не Google, конечно).
Да нет тут никакого "или". Программирование может быть и искусством, и ремеслом и ими обоими одновременно. Все дело в контексте, и без него рассуждать на эту тему глупо. Программирование - оно про масштабирование процессов за счет автоматизации, и продать миллион раз код, написанный одним гением, может быть проще, чем продать один раз код, написанный миллионом бездарностей за конвеером. В определенном контексте, опять же.
Вовсе не значит.
Понятный код писать сложнее, требуется выше квалификация.
Понятным код делают несколько вещей:
Правильное разбиение на абстракции. Они должны быть максимально похожи на предметную область.
Сокрытие сложности. Инкапсуляция. Чтобы каждый кусок кода был не слишком сложным, и было понятно что происходит с теми обьектами что в нем используются.
Понятные названия. Сделать понятное название всегда более трудоемко, чем назвать x и y.
Плохо написанный код, где смешаны уровни абстракции, где недостаточная инкапсуляция, как попало названные переменные - может отлично работать. Но если там баг то найти его сложно, потому что понять что там вообще делается сложно.
Тут, вот ещё что надо отметить. В такой ситуации ( непонятный, но работающий код) есть два способа поведения с заказчиком:
Первый - честно сказать что создатель кода был очень талантлив, а вы не настолько. Но постараетесь разобраться и помочь.
Второй - сказать что код писал конченный придурок, всё было на грани катастрофы, но вот пришли вы и теперь можно не волноваться - мир спасён.
Лично я думаю, что дальше всё будет только хуже <...> Просто для того, чтобы сложить два числа, понадобится 32 DLL, 16 служб Windows и миллиард строк кода
Проблема (хотя есть те, кто не считает это проблемой) может быть рассмотрена шире. Безудержное потребление - классика современного общества.
Есть большое количество нытиков, про то, что современные программисты уже не те. Однако, эти нытики, почему-то, не заваливают рынок своими сверхэффективными решениями, созданными за кратчайшие сроки... Напишите современную "элитку" в несколько килобайт, от которой глаз не будет дергаться... да вам памятник поставят! Но нет, тишина... К чему бы это? В целом, я согласен, проблема раздутости всего и вся, в современной разработке, имеется. Но причину стоит поискать в чем то еще, кроме вот этого "а я то, в советские времена, уууууууу!" Современное ПО, как и раньше, создается в условиях ограничений. Просто ограничения эти, давно вышли за пределы коротенького списка из процессора и памяти.
640 КБ должно хватить всем
Как правильно заметили выше. Статья автора - сплошное нытье, ничем не отличающееся от нытья других людей до. Мне больше жаль переводчика, что он свое время потратил.
А если говорить ближе к сути, то количество зависимостей растет, а тенденции их отсекать, как садовник ухаживая за розами, - нет. Отсюда все эти многотонные программы, которые под капотом используют "проверенный годами" софт, который используюет старые библиотеки, которые... И так далее, с щепоткой утрирования
Вообще, насколько я знаю, эта проблема давным-давно известна. И имя ей - ООП. ООП - одна из форм добра, которое стало злом. Теперь его суют в каждую дырку без всякой надобности, просто потому, что по неизвестной причине у многих в голове сидит большой таракан с именем "ООП". И эти тараканы множатся с геометрической прогрессией. А любая самая простая процедура, являющаяся методом класса тащит за собой всю иерархию класса. И не понятно, почему компилятор не вырезает из кода всю неиспользуемую часть мусорного ДНК этого класса, оставляя только исполняемый код.
Например, в Дельфи пытались избавиться от дурной наследственности. ООП, создав KOL.
А есть ли "раздувание кода"? Конкретные проблемы, описанные в статье, касаются Windows, которой приходится тащить за собой кучу костылей. Другие системы (macOS/Linux) просто выбросили всё наследие ценой совместимости со старым ПО.
Если же смотреть реально, то мы ушли от якобы "оптимизированных" утилит, которые работали только на одной ОС с однобайтовой кодировкой, да ещё и с ограничением по объёму данных — тот же Outlook когда-то имел ограничение в 2ГБ для PST-файлов, потом оно выросло до 20ГБ, но кто-то всё равно упирался в это ограничение.
Так что объёмы данных растут. Увеличивается и размер самих файлов, так как они хранят больше информации, чтобы отображать содержимое качественно на современных средствах вывода. И не важно что это — текст, изображения, видео, аудио, etc.
Современные ресурсы позволяют получать приложения быстрее, а не ждать их годами. Тот core-функционал, что годами прорабатывали в старых приложениях, теперь обязателен в MVP, на который есть значительно меньше времени. Теперь не надо десятилетиями ждать версии для Linux или macOS, тот же FAR Manager сейчас всё ещё портируют под Linux, вот только кому он теперь нужен? Надо было вместе с версией для Windows выпускать.
А качество кода растёт. Я сейчас смотрю на внутренности старого продукта (который меньше ресурсов требует) и ужасаюсь. Новый требует на порядок больше ресурсов, но его возможности на голову выше, чем у старого, да и кодовая база там теперь приведена в порядок. За счёт этого продукт удалось за два года перевести на Linux (требование настоящего времени), а со старым такое не получится.
Оптимизация всегда имеет свою цену в виде зависимости от архитектуры процессора, версии ОС, библиотек, etc. Но самое главное — ограничения в расширениии функционала. Можете посмотреть на nginx и попытки реализации QUIC в нём. Продукт отличный, но рынок требует новых возможностей, в том числе для оптимизации объёмов трафика.
Как раз в ней и проблема. Делать 100500 верий под разные API или его ревизии никто не будет. Особенно на общем тренде отказа от десктопов. Тот же SDK Apple позволяет быстро сделать версию для нескольких платформ, а теперь уже даже запустить нативную версию с iOS на macOS, поэтому на ней реже встречаются приложения на базе Electron. В основном страдают от этого подхода Windows и Linux. Первый, потому что у пользователей зоопарк версий ОС на устройствах, второй — потому что нет единого графического API. А так, в целом, софт очень даже оптимизируется. Firefox перестал адски жрать память после внедрения компонентов на Rust, да и Chrome'у тоже порезали аппетиты по ресурсам. Чудес, естественно, не будет, чтобы это работало на 2-4ГБ ОЗУ, да и не нужно, когда она достаточно дешёвая. Про 32-бита вообще пора бы забыть окончательно.
Ну и ещё один фактор — финансовый. Тот же Telegram старается, чтобы были нативные приложения, под какие-то платформы даже есть выбор из двух. Но что-то никто не побежал массово оплачивать премиум, чтобы отблагодарить разработчиков. Все хотят всё бесплатно, да ещё и чтобы под их хлам десятилетней давности что-то оптимизировали. Может пора начать платить за софт? Или обновить железо хотя бы?
Так что проблема "раздутости ПО" раздута. Да, есть такие приложения, но прям массовой проблемы нет. Софт сейчас вполне себе оптимизирован, особенно платный.
А почему о 32 битах нужно обязательно забыть? Для огромного количества задач их более чем достаточно.
То что достаточно, не означает, что надо упарываться этим. Поддержка 32-bit-only окружения просто добавит лишней работы. Даст это какие-то плюсы в экономии ресурсов на устройстве? Сомнительно. Да, знаю, что некоторые специально ставили 32-битные ОС на устройства, которые в целом и 64-бит поддерживают, объясняя это фразой "так меньше будет ресурсов жрать". Какой-то технической базы под эти ритуалы предоставить не смогли. И да, мы сейчас не про совсем микро-микроконтроллеры говорим для тех же SIM-карт и прочего. Там уже давно всё написано, да и у ребят свой путь. В остальных системах (в том числе встраиваемых) не вижу смысла в 32-бит, просто очередной повод придумать себе проблему, которую потом будут героически решать.
Если говорить о более приземлённых вещах, тех же Atom'ах, которые тут вспоминали, то им давно пора на помойку. Неудачная попытка Intel вкатиться в мобильные устройства. Сейчас есть ARM64-процессоры, которые лучше во всём. Если же надо что-то на x86, то у Intel и AMD есть целые линейки процессоров с низким потреблением. А стюардессу пора закопать.
Если поставить 32-битный браузер, то он в одно лицо больше 2 GB не скушает. Он конечно лиц запустит по одному на вкладку, но тем не менее.
У меня был опыт с 32-битным браузером в 64-битной системе. В результате он регулярно падал. Да, открыто 100500 вкладок, но это не особо помогло ему экономить память системы. В 32-битной системе мало что изменится, разве что swap будет насиловаться чаще.
Если уж так надо, чтобы приложение не потребляло больше N ГБ, то его надо проектировать исходя из этого. В том числе задавать жёсткие ограничения на объём входных данных. Но никто этого не будет делать, так как память дешёвая, а ухудшать пользовательский опыт — очень плохо.
Нет. Это так не работает. Память не жрёт тот софт, что спроектирован в определённые лимиты. И он одинаково не будет жрать ресурсы как в 32-битном виде, так и в 64-битном, разве что 64-битные регистры могут помочь ему в улучшении быстродействия (больше данных обрабатываем — быстрее завершаем работу и высвобождаем память). В реальности 32-битный браузер просто будет чаще падать, если будет открыто много вкладок, а техподдержка будет отвечать, что "ставьте 64-битную версию". Скорее всего 32-битная версия проходит только автоматические тесты и редко используется пользователями, значит её проблемы будут реже решать. Так что никакого преимущества нет.
Популярные дистрибутивы Linux всё ещё тащят за собой 32-битные библиотеки, в итоге только путаница происходит из-за всего этого. За столько лет можно было всё пересобрать. Так что та же Apple всё правильно сделала, выкинув 32-бита. На примере Linux видно, к чему приводит обратное.
Память дешёвая. 16 ГБ — это современный минимум. Пора перестать мучить устройства с <4 ГБ. Их уже ничего не спасёт.
Ещё раз. От битности не зависит объём памяти выделяемой под структуры данных. Только от разработчика. Он может установить некий лимит их размера, и тогда они в обоих случаях будут занимать один объём памяти, но у нас будут жёсткие ограничения в ПО по каким-то возможностям. Либо он не делает так, тогда объём открываемых данных зависит от имеющихся ресурсов. Тут уже на нём лежит обработка ситуаций, когда их не будет хватать, и что ПО будет делать в таких случаях.
Наоборот. Как мы видим у Apple всё хорошо с обратной совместимостью, они два раза делали транслятор/эмулятор кода при переезде на другую архитектуру. И что-то я не слышу сожалений об "утраченном ПО эпохи PowerPC". Как раз отказ от 32-битных приложений дал пинка разработчикам, чтобы они обновили приложения. А Microsoft так и не достиг успехов в плане своей ARM64-версии Windows. Что более иронично, она лучше всего работает через Parallels на компьютерах Mac с Apple Silicon.
И да, покупка нового устройства — это самый логичный шаг. И суть даже не в том, что память не расширить. Сам процессор уже не справляется. В том числе из-за ограничений шин данных до других компонентов. Сложно требовать от какого-нибудь Core 2 Duo качественного воспроизведения 1080p, ибо очень он стар, да и из архитектур и чипсетов там тоже тот ещё бардак. Срок жизни устройства — 5 лет, в крайних случаях 7, этого вполне достаточно. Технологии всё же развиваются.
От битности не зависит объём памяти выделяемой под структуры данных.
То есть размер указателей, по-вашему, одинаков и в 32-битной, и в 64-битной среде?
В двусвязном списке, например, их два аж три на каждый элемент данных: на сам элемент, на предыдущий и на следующий в цепочке.
А ещё не только указатели, но и выравнивание структур до 8 байт, выравнивание стека (любой аргумент в стеке занимает минимум 8 байт).
Я помню, что в старые времена, когда у подавляющего большинства людей было не более 2 гигабайт памяти и когда 64-битные процессоры только входили в массовое обращение, утверждалось, что 64-битный код потребляет где-то на 25% больше памяти, чем 32-битный. И потому люди даже на 64-битных архитектурах ставили 32-битные системы.
Понятное дело, что 25% — грубая оценка. Те же графические ресурсы занимают одинаково. Но другой оценки у меня нет.
В те времена еще и в разных реализациях x64 работало с разной скоростью в попугаях, разница могла достигать трети на кодировании видео между красными и синими.
А если серьезно, есть где-нибудь статистика какой процент памяти типичного приложения занимают указатели?
никогда не поверю в то, что до 50% драгоценного кеша могут выкинуть на какое-то выравнивание.
Не страницами, а строками
но по вашей логике получается, что если я сделаю 10 интов по 32 бита, то у меня это 80 байт в памяти займёт
Это на каком процессоре так?
Вы как-то слишком упрощаете современные процессоры. О какой именно шине идёт речь?
И разработчики процессоров не дураки: доступ к 32-битным данным в них такой же эффективный, как и к 64-битным.
Медленный же доступ к 8- и 16-битным данным, но это связано с сохранением верхней части регистра.
У вас есть готовая инструкция в наборе, которая выполняет все эти операции за вас, но тем не менее, выполняет
Обычно данные, все-таки, извлекаются мультиплексором. И ему совершенно все равно какой байт из восьми извлечь, это O(1).
Мне кажется, вы не очень знакомы с архитектурой современных процессоров. Да, есть архитектуры, где данные можно читать только 64-битными блокам. Но это не наш случай: и в x86-64, и aarch64 процессоры умеют эффективно работать и с 32-битными, и с 64-битными данными. Чуть менее эффективно — с 8- и 16-битными (поэтому лучше не использовать типы с размером меньше int без веских аргументов).
А вот что эти процессоры умеют не очень хорошо, так это в невыровненный доступ. Некоторые процессоры обрабатывают такие данные медленнее, некоторые же поднимают лапки и бросают исключение. И чтобы такого не было, данные надо выравнивать: значения типа int32 должны иметь адрес, кратный 4 (и на 32-битных, и на 64-битных архитектурах) а значения типа int64 — адрес, кратный 8.
То есть массив из 10 int32 будет занимать 40 байт, но никак не 80. А вот массив из 10 экземпляров структуры, состоящей из int32 и int64, будет занимать 160 байт.
И это прям существенная разница в полтора или два раза, чтобы тратить на это время и силы? Почти всё перешло на 64 бита, но находятся люди, которые выполняют некие шаманские ритуалы, потому что им кажется, что "потребляет меньше". А тебе потом приходится поддерживать 32-битные syscall'ы, потому что это всё выбросить не могут из системы.
Давно пора выбросить сборку 32-битных версий приложений. Надо — собирай сам.
1) Но явно не стоит свеч в плане экономической выгоды. Я тоже занимался подобной фигнёй, но понял, что даже "гипотетические" сотни сохранённых мегабайт не стоят тех трат времени, что на это тратятся. Дешевле докупить памяти. Или вообще сменить устройство. Из всех компаний разве что Apple занимется оптимизацией ПО, лично ощутил на своём iPhone SE. Но в российском ИТ-сообществе принято считать технику оверпрайсом и не покупать её. Зато какой-нибудь ванплас на 100500 ГБ ОЗУ — это нормальное дело. Так что надо определиться, в какую сторону вы воюете. Хотите экономии ресурсов, оптимизации и долгий срок поддержки — придётся заплатить за это. Бесплатно вы не получите ничего.
2) Нет. Windows в плане обратной совместимости — это рандом на рандоме рандомом погоняет. На 10-ке и 11-ой сейчас не запустится приличная часть старого софта, то что ваши 3,5 приложения запустились — просто ошибка выжившего. Лучше тут себя 7-ка чувствует, но есть приложения, которые и на ней не запускаются, в таком случае приходится откатываться на XP или ещё ниже (тут как повезёт). Походите по тому же GoG и почитайте жалобы, что "на 10-ке не работает, или работает криво". То же самое с какими-нибудь визуальными новеллами (особенно времён нулевых). Корпоративный софт вообще отдельная тема, мне хватило плясок с бубном вокруг неподписанного ActiveX.
3) GPU умеет декодировать только определённые профили кодеков. Шаг влево, шаг вправо — и тут он говорит "кря". Про кодирование вообще можно даже не говорить. Именно поэтому нормальные стримеры кодируют на процессоре, иначе на "стандартных" профилях будет каша из пикселей. Ну и да, чтобы поддерживались современные кодеки (в том числе тот же AV1) вам просто придётся купить новое устройство, что опять же перечёркивает некрофилию с устаревшими железками.
И ещё раз. Я прям не вижу засилья ПО на Electron. Только Skype помню и всё. Нативные приложения будут там, где за них платят. в том числе по подписке. Бесплатно вам никто делать не будет.
долгий срок поддержки
На 10-ке и 11-ой сейчас не запустится приличная часть старого софта, то что ваши 3,5 приложения запустились
У меня десятка и коллекция софта с более чем двумя тысячами экземпляров, каждый из который запускался хотя бы раз. Значительная часть коллекции - заброшка и старые версии программ, вплоть до 30-летней давности. Разброс по категориям от десятков браузеров, плееров и офисного софта до всяких инструментов разработчика (например полусотни бейсиков), кучи метрономов, сотен эмуляторов, экранных линеек, и самой экзотичной экзотики. Не считая 16-битного софта, я еще не видел ни единой программы которая не работала бы на десятке.
Я прям не вижу засилья ПО на Electron
Просто ошибка выжившего. Существенная часть нового ПО выпускается на электроне или переводится на него. Взять например редакторы Markdown - 9 из 10 будут на электроне. Самый популярный сегодня редактор кода, VSCode - на электроне. Discord - на электроне. Slack, WhatsApp, Wire, Signal - все на электроне. Новые гит-клиенты GitHub Desktop и GitKraken на электроне. Microsoft Teams на электроне. И огромное множество других программ, в которых собственного кода в лучшем случае на мегабайт, которые почему-то суют в 200-метрового монстра.
Память дешёвая. 16 ГБ — это современный минимум.
И всё же память реально дешёвая (особенно если не бегать за оверклокерскими вариантами) относительно остальных компонентов.
16 ГБ — это реально современный минимум, чтобы запустить пару небольших виртуалок, рабочие приложения и чтобы ещё браузеру осталось. Но кто-то не согласится и скажет, что вообще 32 ГБ надо. Для определённых видов деятельности вполне возможно.
Я помню старую рекламу Windows 7 от российского офиса (скорее всего этот пост тоже ссылался на неё https://habr.com/ru/post/68418/), где представители MS рассказывали, что 7-ке "гига достаточно", но это всё ложь, ложь и ещё раз ложь. 2 ГБ минимум, чтобы что-то вообще делать, а так 4 ГБ — это обязательный минимум, 8 ГБ для ресурсоёмких приложений. С того времени больше 10 лет прошло, так что 16 ГБ — это оправданный минимальный объём памяти для рабочих задач.
Для мобильных уже есть PWA, но популярностью не пользуется, в том числе с подачи Apple и Google. Мобильникам меньше всего надо беспокоиться об отсутствии нативных приложений. Вот у десктопов всё плохо. Если macOS ещё может выиграть за счёт единого SDK и получать нативные приложения, то на ту же Windows забили. Linux тут в двойственном положении — с одной стороны есть независимые разработчики, которые пытаются писать свою реализацию, с другой владельцы сервисов в этой ОС ещё меньше заинтересованы. В целом, я пока только Skype видел, как пример очень плохого Electron приложения.
FAR Manager как и Notepad++ - софт написанный с использованием WinAPI. Поэтому его портирование куда либо настолько затруднено что проще написать новое приложение.
Проект far2l передаёт привет.
Проще вообще не портировать, так как там вся соль в плагинах, которые придётся переписывать с нуля (чем в итоге far2l и занимается). Легче потратить силы на развитие того же Midnight Commander, если уж так нужен двухпанельный файловый менеджер а-ля Norton Commander.
Ну да, решил сейчас курсы пройти к примеру по тому же питону (да и все остальное) так там все "упрощенно" под стандартизацию. Возьмите для простоты понимания и создайте понятно названную переменную и запихните в нее значение и только тогда используйте одноразовую переменную, мол для более легкого понимания чтения вашего когда))) Оно конечно легче, но как представлю если бы на ассемблере все значения в регистры пихали бы да и переменные создавали чтобы один раз использовать))). И так почти во всем. Стараются сделать все настолько простым и универсальным, что оно просто увеличивает код и длительность его выполнения. Помню раньше такты считали и килобайты - сейчас такой фигней уже не страдают. Проще написать что-то новое за что заплатят, чем разобраться во всей этой здоровой мешанине. где никто ничего уже не понимает - ну да понятные переменные и названия функций - но вот логика работы же в них не описана. А описывать все значения, сравнения и прочее комментариями так никакого времени не хватит на код. А так найдут дырку в старом модуле - кое как исправят, а вот все остальное что было завязано на "правильной" работе модуля начинает иногда косячить))) Короче стало быстро писать но долго понимать доскональную работу. Впихнул всего и побольше - там функцию из того, там другую из этого и да получается как и написано в статье.
Раздувание ПО трогает только тех кто привык контролировать внутреннюю работу своих железок, знать что сколько ресурсов занимает, и скрупулезно следить за файлами и процессами.
Типичный современный пользователь об этом может вообще не знать, и когда сталкивается с отсутствием свободного места, проблема решается просто и относительно дешево - стереть лишнее или прикупить диск побольше. И то что новая железка (в купе с новой версией ПО) делает примерно тоже самое и примерно с той-же скоростью, для него не так важно. Зато это новая железка (в рекламе которой производитель показал лучшие цифры чем в прошлой) и новая программа (покрасивее, больше анимации и т. д.).
А с точки зрения бизнеса, все вообще хорошо, продажи растут, и надо продолжать в том же духе.
Типичный современный пользователь об этом может вообще не знать, и когда сталкивается с отсутствием свободного места, проблема решается просто и относительно дешево - стереть лишнее или прикупить диск побольше.
особенно пользователи смартфонов любят стирать лишнее и диски докупать. Особенно те, кто постарше. Так что не соглашусь. Типичный пользователь может не знать, что его трогает эта проблема, но это не значит, что она его не трогает на самом деле.
Собственно это последствия мира команд и менеджмента.
Одиночка имеет больше ответственности, более целеустремлён, имеет контроль над кодом. В командах ответственность размазывается, контроль удержать сложно, как итог в код начинает проникать мусор и ошибки, и ресурсов этого избежать часто нет. Особенно плохо, если в команде есть слабые коллеги: за них их часть работы никто не сделает, ресурсов на это не дают, а их код ужасен, но так навсегда в проекте и останется, будет кое-как работать, порождать сотни ошибок.
С учётом того что современная разработка построена на максимальной экономии и руководит процессом менеджер, который в этом ничего не понимает, приходим к фичегонке: оказывается для проекта важнее наклепать тысячу ненужных фич, чем остановиться и привести в порядок хотя бы одну из уже сделанных. Та же ситуация с техдолгом и качеством кода: на это никогда нет времени, вечное завтра.
Вот и получается, что на выходе у одиночки компактный рабочий код - он его сам писал, один, сам за все в ответе, сам все проверил, и результат прямо соответствует ему опыту: у новичков он плохой, у опытных хороший.
А на выходе у компании - урод, внутрь которого лучше не заглядывать: раздутая смесь из грязного кода, ошибок и костылей, которая каким-то чудом но частично работает. Там тысячи фич, но работает из них лишь часть, и работает не особо хорошо.
Особенно таким грешат крупные компании, где софт для галочки: его просто нужно выпустить, а как - не важно. Менеджер на менеджере сидит и менеджером погоняет, важны только отчёты и расходы, а главное, сам результат, никого не интересует.
Чтобы результат был хорош, нужно давать разработчикам свободу. А это в основном некоторые продуктовые компании, которые сосредоточены на результате, где можно взять и пилить одну фичу до тех пор, пока она действительно не будет готова, или где если заметил ошибку или неоптимальный алгоритм, ты можешь его взять и поправить.
Столкнулся с тем, что на некоторых компьютерах бывает "аппаратно зарезервированной памяти" больше половины оперативной т.е. из 8 Гб половина занята непонятно чем. После удаления драйверов видеокарты Nvidia зарезервированная память уменьшается до 200 с небольшим.
А как без драйверов жить?
Да, столкнулся на ноуте с ryzen. При покупке в ноуте установлено 8 гб. GPU отъедается сразу 2 гб. В биосе поменять или уменьшить, данный объем возможности нет. Только добавлять память. Есть один слот.
Так это не заслуга райзена) т.е не от процессора зависит ,система всегда резервирует под себя озу ,так что это нормально, просто надо добавить озу, вам повезло что у вас есть слот. А одна планка озу на 8 гб не дорого стоить будет, зато получите + озу и двухканалку следом, что отразиться на повышении производительности
На самом деле из текущего положения дел следуют огромные возможности по оптимизации по, ос и самого железа. Если начать всё делать по уму, а не ради прибыли, вращения потребления и накручивания технологий ради технологий. Раз есть среда, в которой живёт такое количество огромных неэффективных разожравшихся технологических динозавров - там же могут обитать куда более оптимальные компактные существа в каких-то неисчислимых количествах.
Как же мне нравятся такие статьи. Да, да, да полностью согласен с автором. Все огромное и тормозит. Справедливости ради, скорее всего в архиве с программой какой нить qt + картинки + локализации и справочная документация. Или вообще электрон засунули.
когда я нажимаю на значок громкости ноутбука Microsoft Surface, то вижу задержку: машина постепенно создаёт новый элемент интерфейса пользователя, разбирается, какие значки отрисовывать, а затем они появляются и становятся интерактивными. На это уходит время. Кажется, около половины секунды, что в масштабах времени процессора близко к миллиарду летКто-то пробовал проверять слова автора?
Думаю, что у вас ssd. А у автора hdd. Я столкнулся с таким поведением на hdd. Особенно это заметно когда переходишь по окнам настроек. Задержки и шуршание винта. Задача без ssd не решаема, раньше как то решалась, на древнем железе, ну к сейчас с 5нм уже проблемы.:)
Возможно до кеширования данного элемента, это происходит. Даже на ПК с ssd. Я это замечаю. Стоит windows 10. Но только один раз при загрузке ПК.
Кроме отрисовки, там ещё же и в реестре где-то обновленные параметры эквалайзера сохраняются. И ОС по всем окнам рассылает уведомление что параметры поменялись. Через слоев 100500 абстракций, конечно же. И где-то в этой цепочке что-то выгружается в swap.
просто взять и подергать эту громкость самому
У вас точно такая же нога но не болит? Рад за вас ;) Чтобы убедиться, что кто-то в интернетах неправ, мне нужно найти такой же комп, взгромоздить на него тот же набор софта (с антивирусниками, кряками и кейгенами).. Воздержусь.
ЗЫ: у меня воще linux лапки. :)
Думаю, что у вас ssd. А у автора hdd.
ноутбук Microsoft Surface с hdd? - такие разве были?
Не знаю, что там у вас за х260, но, у меня Феном 2 х4 с 8 Гб ОЗУ и сразу после загрузки ОС, при первом нажатии правой кнопкой на любой папке на рабочем столе я ожидаю около 10-20 секунд. Да, что там папка? На рабочем столе правой кнопкой - то же самое.
Так что, я согласен с автором на все 100%. Считаю, что для продвинутых юзеров просто необходимо нормальное ПО, без всех вот этих вот наворотов в виде анимации и прочей бесполезной лабуды, с ГПИ на уровне 95 винды - как максимум, а как минимум - вообще без ГПИ, чисто на командной строке. А для остальных 95% юзеров пусть останется "плиточный 2д дизайн десятой винды", который ест ресурсов больше чем любая 3д игра из 2000 года.
Но, такого не будет никогда. Это только мечты.
Не знаю. Вы просили проверить слова автора - я проверил. Но, такая задержка у меня только после включения. После первого нажатия срабатывает быстрее, но не мгновенно. Иногда 1-2 секунды. Громкость работает так же.
Не спорю, система у меня засранная, и винда старая, я её устанавливал ещё году в 2013. То есть она уже лет 10 работает. И софта всякого разного стоит очень много.
Но, тем не менее, софт реально раздут. Например Windows XP требовала 1,5 Гб ПЗУ и 128 Мб ОЗУ, а десятка - уже 20 Гб и 4 Гб соответственно. А прошло всего 15 лет. Куда это годится?
Думаю, сейчас рынку просто необходима небольшая офисная ОС с минимумом функционала. Потому что код винды уже близок к технологической сингулярности.
Как вариант кастомный Linux. К примеру есть Antix на старте где то 128 озу. + libre office 300 мб для запуска. Но юзать его очень неудобно(я особо не копал). Вариант сделать сейчас такой дистр на базе линукс есть. Даже самому. Поставить ubuntu и поменять DE. Правда он включает systemD, который не выпиливается.
Линукс, увы, уже тоже едет в ту же сторону. Если не хочется тратить кучу времени на настройку/подгонку, то берешь что-то мейнстримовое (Fedora/Debian/Ubuntu и т.п.), а там все идет туда же, куда и Windows - дистрибутивы с каждым новый релизом распухают все больше и больше. Нет, все же в FOSS еще много людей, готовых тратить время на оптимизацию, но поскольку основные дистрибутивы уже, по сути, управляются корпорациями, порочный подход постепенно занимает все больше и больше места.
Перезагрузил, на глаз громкость с плавным выездом открывается за 0.5. Повторно примерно за 0.3.(Задержки уже нет) Это ко всем окнам относится. Wifi, настройки и т.д Но загрузка параметров экрана всегда одна секунда. Не мгновенно.

"совершеннейшее, совершеннейшее безумие. Именно из-за этого ничего не работает, всё медленное, нужно покупать новый телефон каждый год и новый телевизор для скачивания этих раздутых приложений для стриминга, в котором тоже прячется столь же плохой код."
А может быть именно это следствие и есть причина? Если код вынуждает каждый год покупать и покупать дорогущие вещи, то может потому он и приветствуется? Безумие для програмиста, но вполне разумно для бизнеса.
Все слои системы , которую я написал занимает порядка 250 кб + одна единственная Библиотека в 1 мб.
Предыдущий код , доставшийся в наследство занимал для этого же функционала около 150 Мб и десяток библиотек.
Вот думаю , а может ещё уменьшить ???
И я честное слово не считаю себя вообще программистом.
Если бы программисты делали программы свои из реальных материалов, из дерева там, или металла, процесс конечно можно было бы замедлить. Посмотрите сколько в прочих отраслях стандартов всего. Дафигалион шурупов, винтов, марок стали, разъемов, сопряжений, оригиналов и аналогов, даже систем измерений две. Возможно в будущем случатся попытки как-то зафиксировать хотя бы часть этого программного зоопарка. Условный список "жизненно важных" (по аналогии с лекарствами) приложений, то есть, один редактор текста, один редактор изображений, базовый (гос) месенджер, стандартный браузер для "госуслуг" и т.д. С ежегодным фиксом багов и некоторым обновлением функционала раз в 10 лет. И все это под такой же стандартный ПК и смартфон. Учитывая торможения прогресса в этих областях, то подобной сборки хватит лет на 50, а следующей, может и на все 100. Мало что ли "древнего железа" до сих в работающего, а то ещё и производящегося? Либо же все само как-то коллапсирует до чего-то подобного. Как-то раз в компании любителей фантастики шутили, что космические просторы будут бороздить корабли, в недрах которых будет оборудование и код возрастом в столетия, а обслуживающий персонал будет, хочет он того или нет, напоминать вархамерровское техножречество :)
Ага, видал я функционал на больших проектах.
Помимо очевидного легаси, которое расширяется, всесто модифицирования, есть ещё один момент.
Аналитика и куча хотелок бизнеса. Вы просто загружаете файлы и понимаете, что они там где-то хранятся. На самом деле вы клиент. И ваши действия отслеживаются. Все возможные и нет. В каждой крупной компании есть десятки метрик для десятка сотрудников из разных сфер. От менеджеров и рекламщиков, до разработчиков и дизайнеров. Эти метрики нужно мониторить. Может быть - в реальном времени. Может, нужна возможность троттлить загрузку файлов в зависимости от загрузки кластера и уровня вашего пакета. Всё это уже многолетнее легаси на каком-нибудь паскале в перемешку с плюсами. И пока оно работает - никто не будет тратить невероятные ресурсы на рефакторинг. Это было и раньше и сейчас и будет в будущем, как бы печально не было.
Ну, это похоже на неконструктивное положение какого-то обиженного ребенка.
Бизнес зарабатывает деньги. Никто не станет тратить деньги на бесполезные метрики. А если они полезные, то никто их не выкинет. На самого клиента им срать, насколько это возможно. Бизнесу, чтобы выжить, нужно быть наглым и цепляться на всё, что возможно. Тут нечего обижаться - вам тоже на них срать, по большому счёту.
Если вы платите деньги и недовольны работой сервиса, есть отличное лекарство - написать им, что ты недоволен вот этим, 1: ..., 2: ... и валишь к конкурентам. И валить к конкурентам...
Да и вообще, какая вам разница, что происходит внутри, как клиент?
Более-менее подкованный пользователь может организовать почти анонимный сёрфинг у себя на домашнем ноуте без особого напряга и абсолютно бесплатно. Я понимаю, когда от перегруза страдает клиент (программа-интерфейс), тут да, но что происходит на серверах вам должно быть совсем по барабану.
Это скорее крик программиста, которому этого монстра поддерживать (откуда тогда известна внутренняя кухня??). Тут да - без вопросов, парню (а скорее всей команде) не повезло)
если молчать — будет ещё меньше
Молчать никогда не нужно. Но ценности и т. д. сходят на нет через два-три уровня бюрократии.
Как вариант (опять же, большой напряг для бизнеса и не подходит в сильно коррумпированных обществах) - законы. Уже есть целая система, которая огораживает народ от кучи неприятностей. Например, одно только обязательство печатать состав съедобной продукции на её упаковке - это уже достижение, которое, без преувеличения, спасло (в прямом смысле) кучу народу.
А по факту как всегда - где-то посередине
Опять очередное нытьё оторванное от реальности. Мальчик в песочнице, которому не понятно почему дом строится так долго в отличии от его песочного замка.
Есть такое суждение, хочешь проверить дуга дай ему денег в займы. Здесь также, хочешь понять почему, дай ему власть взаймы. Если бы данный персонаж имел свою фирму и попытался нанять команду , которая бы была в соответствии с его требованиями, то он бы быстрее поседел. А когда бы он потратил слишком много средств на проект, который в итоге не выстрелил, то его бы вовсе расстреляли.
Хотелось бы поправить автора - первая Elite занимала не 64, а 48 килобайт, первые 16 кб - это было ПЗУ компьютера с неким аналогом операционной системы. И да, в 2004 году был у нас на работе Пентиум-3 533 МГц, и на нём прекрасно работала одна браузерная игрушка на Flash. Энтот самый flash-плейер имел нехорошую привычку обновляться пару-тройку раз в месяц, после каждого обновления он работал всё медленнее и медленнее, лет через 5 эта игра уже с трудом шла на 1700-м целероне.
И до сих пор интересно, как смогли уместить Elite в 48 килобайт?
Сейчас такую традицию андроид соблюдает. С каждым обновление и новой версией жручее становится. Для последней версии обновили спеку, что минимум 6 Гб.
Современные говнокодеры не понимают значения слова "оптимизация". Они считают, что если их божественный код не идёт на компе клиента - клиент должен поменять железо. Они никогда не пробовали что-нибудь написать на мк61. Про элиту отдельный разговор. Вот были программисты.
Вот примерно такая же тема. Я всё удивляюсь ,какие школьники пишут сохранения для игр , что они по 100 Мб занимают. При том что там максимум 1000-2000 параметров. Как-то сам опенсорсную игру писал. Там халтурное всё , и AI и графика и конечно же система сохранения. Но больше чем на 100 Кб всё равно они не занимали даже после нескольких часов игры(а по хорошему можно и в 10 Кб уместить). В общем как пишут сохранялки , чтобы они 100 Мб занимали, для меня так и осталось загадкой. Может быть просто дамп памяти сгружают в файл? Или надо ещё какой-то дзен познать, чтобы такие делать?
Ну если разрушаемый, то да. Но я видел в Master of Orion 3 , там до 300мб сохранения. Хотя там 100 планет. Там максимум жителей 20, для каждого специализация - это байт. Ну ещё зданий 20, тип здания это ещё байт. Ну и всего параметров 100 максимум. Это 10 Кб. Ещё 10 Кб на флоты всех фракций.
В Total war Shogun где-то 15 Мб сохранение. В Thrones of Britania наняли уже студент и стало 7Мб , хотя информация для сохранения примерно такая же.
В шутере Quake 4 тоже 7Мб сохранение, я не помню, чтобы там особо был разрушаемые уровни.
Добавлю в копилку. Недавно был у нас проект, ничего экстра ординарного, несколько сущностей, UI в виде табличек, требований к дизайну особо не было. Совсем недавно всё это делалось одним человеком на Yii2+bootstrap3 за месяц максимум, и работало надёжно как лопата. Сейчас же всё это считается устаревшим, включая подходы к backend/frontend. Так вот, теперь такой проект пилили 4 месяца 2 отдельных front/back - программиста, всё по современному typescript/nestjs на бэке, spa/vue/quasar на фронте. Естественно всё это с кучей зависимостей, в докерах и т. д, напоминает супер-пупер навороченный мото-культиватор.
По итогу картошку лопатой выкопал один человек за день, а с мотокультиватором двое за четыре)
Раньше можно было пойти в лес, поймать лису и сделать шубу бесплатно. А сейчас нужно подключить к созданию шубы кучу специалистов задорого. :)
Раз заказчик платит - значит, для него есть свои соображения, по каким технологиям создавать продукт. Или погонщики программистов таким образом подняли цену продукта. Должно быть рациональное объяснение.
Сегодня оптимизация кода это что-то ругательное. Если уже мигание курсора нагружает цп на и задействует гпу. Потому что тестирование кода не на железе, которым будет пользоваться типичный юзер, а избыточно мощном. Плохо оптимизированный код на таком будет незаметен. https://habr.com/ru/post/402601/?ysclid=l4tq71gzl1147975540
Я вот кино какое-то смотрел, там боевые машины восстали, а центральный взбунтовавшийся компьютер герои-люди так и не нашли. Потому что все было распределено по всем персоналкам в офисах . Вот так оно и есть. И во всех этих тысячах DLL, исходников которых живые люди не касались уже давно, и никто не помнит, кем и как они были написаны, располагается код SkyNet. Скоро бахнет )
Каждый год 31 декабря мы ходим баню. Каждые полгода должна быть статья про нерациональное использование ресурсов: https://habr.com/ru/post/596517/
Сам не кодер, но в универе было программирование. Грустно конечно.
Это тянет за собой такое же нерациональное использование материалов, из которых сделано железо, а многие из них редки и стоят недешево. Следующим вагоном сюда идет нерациональное использование труда по обслуживанию всего этого добра (софт, железо, генерация и поставка энергии). Ужас.
Есть тенденции не только в компьютерной техники. Набирают популярность различные универсальные блоки, функционал которых зависит от модели (лицензии), но при этом с технической стороны абсолютно идентичные.
Это сейчас касается всего мира,код и железо лишь одна из граней. Взять то же автомобилистроение все что предназначено для города у нас тоже идет по пути "смени машину раз в год на новую", хотя вполне можно увеличить ресурс лет на 10 более и под модернизацию устаревших частей. Про пластик и упаковку там вообще беда полнейшая.
Производитель авто и его смежники разорятся.
Что будет если машины будут будут вечными описано в «Кольцо вокруг Солнца» Клиффорда Саймака:
– Знаете, Джей, - произнес он. - Я не стал ремонтировать вашу машину.
– Я собирался в город, - сказал Виккерс, - но раз машина не готова…
– Я подумал, может, она вам больше не понадобится и не стал ничего делать. К чему напрасная трата денег.
– Но старушка совсем неплохо бегает, - обиделся Виккерс. - И хотя у нее потрепанный вид, она мне еще послужит.
– Что говорить, бегать она еще может. Но лучше купить новенький вечмобиль.
– Вечмобиль? Довольно странное название.
– Вовсе нет, - возразил Эб. - Машина на самом деле вечная. Поэтому ее так и называют. Вчера ко мне приходил один тип, все рассказывал о ней и предложил стать агентом по продаже этих вечмобилей. Я, конечно, согласился, а этот тип сказал, что я правильно сделал, потому что скоро в продаже других машин и не будет.
– Минуточку, - сказал Виккерс. - Хотя ее и называют вечмобилем, она не может быть вечной. Ни одна машина не может быть вечной. Она может служить от силы двадцать лет, ну поколение, но не больше.
– Джей, - перебил Эб, - мне этот тип сказал так. Купите машину, и пользуйтесь ею всю жизнь. Завещайте ее своему сыну, он ее завещает своему сыну и так далее. У нее гарантия- навсегда. Если что-то выходит из строя, они ее ремонтируют или дают вам другую. Вечно все, кроме скатов. Скаты придется покупать. Они лысеют, как и обычно. И окраска тоже не вечная. Гарантия на окраску- десять лет. Если она испортится раньше, перекраска производится бесплатно.
– Может, оно и так, - произнес Виккерс, - но я как-то мало во все это верю. Не сомневаюсь, что можно сделать автомобиль гораздо выносливей сегодняшних. Но какой здравомыслящий предприниматель станет создавать вечный автомобиль? Он же разорится. Да и такая машина будет слишком дорого стоить.
Именно поэтому во многом и появился этот комментарий)
Представьте, делается железка с производительностью на 10 функций, но в зависимости от того, куда ее запихнут или от оплаченной лицензии (не суть) будет выполнять меньшее количество функций. Такая практика с большой вероятностью может стать мейнстримом. С точки зрения разработчика такой железки это удобно. Покупатель все равно платит за всю железку + лицензию или внешний обвес. С точки зрения ресурсной базы и всем, что за эти тянется - беда.
Это уже есть. Intel выкатила процы с возможностью разблокировки доп функционала при оплате. Думаю и другие компании со временем возьмут на вооружение.
rigol ds1054z О нем пишете? Полоса пропускания вырастает вдвое после взлома, плюс куча демо обработчиков, доступных сутки, если память не изменяет. Понравился — оплати лицензию.
В целом про ситуация. Можно поискать примеры, но особо смысла нет.
Мне кажется, что могут появится такого плана устройства, которые будут очень массовыми.
Так они уже есть. А если сделать шаг вниз — они есть массово и давно. Как только вы ставите универсальный процессор для того, чтобы "мигать лампочками" вы оказываетесь именно в этой ситуации. Правда цена у производителя обычно фиксированная.
Но это все равно именно то, о чем вы пишете. Просто микросхема очевидно дешевле рассыпухи, а универсальный процессор дешевле специализированной микросхемы. Так что ничего плохого я в этом не вижу.
Отчасти видимо так. Но изначально речь шла все-таки об устройствах, которые могут делать больше того, для чего используются фактически. Универсальность все-таки не совсем то и в где-то более, где-то менее, но эффективна.
Просто на подумать: транзистор гораздо более унверсален ДО включения в схему. Схема радикально ограничивает его возможности, но позволяет извлекать некий полезный эффект.
Более того, произведенный транзистор существенно более ограничен, по сравнению с теоретическим, ради лучшего извлечения полезного эффекта в схеме.
Пример. Я приехал в магазин за трубой, но нужной длины не оказалось. Купил более длинную, лишнее отрезал и выкинул. Но была альтернатива поехать в другой магазин. А вот если производили условных труб перестанут производить их разной длины, а будут штамповать только длинные. Им то все равно заплатят за всю длину, а что с ней дальше будет им без разницы и тогда альтернативы уже не будет.
А с транзисторами какая альтернатива?
Так это же плюс, а не минус, оптимизация.
Более того, произведенный транзистор существенно более ограничен, по сравнению с теоретическим, ради лучшего извлечения полезного эффекта в схеме.
А вот если производили условных труб перестанут производить их разной длины, а будут штамповать только длинные
Так это же плюс, а не минус, оптимизация.
Ну, как оптимизация… были h₂₁э и частотный диапазон равны ∞, стали — конкретным (и довольно малым) числам. Были потери нулевые — стало греться на всю котлету весьма ощутимо, иногда и вода не спасает. Мало того, еще и от температуры параметры плывут.
Раздули, испортили, приделали ненужные функции и вот это вот все
Я за. Больше статей, хороших и разных. Сам писал похожую статью. Потому, что накипело. Проблема есть и ее не скроешь.
Наша ДНК так же накопила избыточный код. Практически все одинаково, сплошные аналогии по всем компетенциям этих проектов. Грех не воспользоваться опытом...
Предлагаю эту проблему назвать "Проблемой французских писарей". Есть легенда объясняющая, почему во французских словах в написании присутствует гораздо больше букв, чем произносится (иногда из 5ти букв произносится всего один звук) - в древности, когда грамотных было крайне мало, а бумажные документы уже были в обороте, писари брали с клиентов мзду за каждую букву. Так и накручивали неплохие суммы за написание простеньких текстов. Хитрожопые надутые индюки))). Это, конечно, лишь домыслы, но вполне логичные.
Кстати, насколько помню, Дюма в д'артаньяне платили за количество строк (как некоторым програмистам) и появился у него Гримо. Слуга который мало говорил, но строчки рожал. А уже в десять лет спустя платить стали по количеству слов - и Гримо заговорил, но, может-быть у него это было возрастное. Так, что французский след подтверждается.
Можно, также, назвать синдромом Дюма.
Если быть точнее, то оригинальная версия Elite занимала всего 22КБ. А вот ее версия для ZX Spectrum потолстела почти в два раза - до 40КБ. Но зато было добавлено множество разных звездолётов противников.
Тема довольно стара, но от этого не менее актуальна и сейчас.
Помнится, в конце 90-х ... начале 2000-х был подслушан разговор на одной из выставок, двух экспертов-программистов. Суть была в том, что в большинстве случаев, что на тот момент в объектах (ООП) не используются все свойства и методы, а именно используются в среднем всего несколько килобайт из тех сотен килобайт, которые есть у экземпляра класса.
У меня есть пример покруче. Чтобы выключить подсветку видеокарты aorus (торговая марка gigabyte) нужно поставить 0.5гб софта. При чём его нельзя удалять т.к. при некорректном выключении компа подсветка опять включается.
Забавно. А сколько весит установщик? И сколько занимает установленная утилита?
Установшик RGBFusion2.0 253мб.
В установке и удалении программ пишет 170мб занимает.
Откуда я взял 0.5 гб не помню, там 2 варианта:
1)возможно оно писало это при установке.
2)На самом деле там нужны 2 утилиты, при чём 2-я раньше как я понял была отдельной, а потом стала плагином к первой. Возможно 0.5гб это с плагином или со 2-й утилитой или это суммарный объём установщиков.
Уже не помню точно, с документацией беда, ставил методом тыка разными способами.
Скачаю утилиту, распакую и посмотрю, что внутри. Отпишусь в тему.
Насколько я помню правильная установка это когда ставишь утилиту, уже в ней пытаешься зайти в управление подсветкой видеокарты, и тогда она сама качает плагин для видеокарт.
Не прогадал, на старте установки
Установил. В каталоге программы, мегов на 100 dll и exe. Еще есть подкаталоги на 5 и 10 мб с dll. На диске занимает 178 мб. Возможно прога идет с UnrealEngine:) Но я не разработчик игр.
Я всё перепутал. Нашёл свой отзыв.
"Надо самому удалить RGB fusion. В противном случае aorus engine не будет ставить RGB fusion. А та, что ставится отдельно почему-то не работает. Конечно тот ещё говнософт... 400 мегабайт чтобы ВЫКЛЮЧИТЬ подсветку. "
Т.е. надо поставить aorus engine, и чтобы он уже поставил RGB fusion.
Вот уж забавно, надо будет у Асус посмотреть как реализовано, на одной видеокарте точно было механически, но при сборе биоса все откатывалось, а вот на второй может и через биос подсветка глушится, а не только софтом, но кнопки уже нет.
Может проблема ещё кроется в том, что бизнес требует работающего решения здесь и сейчас? И разработчику проще подключить готовую библиотеку, в которой нужна только 1 функция из 50, но это позволит уложиться в сроки.
Не 1 из 50, а 1 из 5000. Условия рынка диктуют правила. Ответ, очевиден и возможно, безальтернативен. Если бы не рост производительности, было бы все намного экономичнее. И причем укладывались и в текущие сроки. Выработали инструменты, подходы и т.д
Вот путь разработчик подключает библиотеку статически, а не тянет целиком so/dll в зависимости. И тогда оптимизация во время связывания включит в исполняемый модуль только одну эту функцию, а не всю библиотеку.
А в идеале предлагать оба варианта - со статическим связыванием и с динамическим.
Люблю я эту тему. Господи, эта проблема тянется с 2000х. С чего б начать-то?! Ну, можно просто вспомнить эксель от майкрософта - скоко там уже версий? Следующая версия точно полетит в космос, ха-ха.
Вы совсем недалеко от истины
А все вполне нормально. Разработка всегда идет от состояния А к состоянию Б по пути наименьшей цены на реализацию. И раздувание - один из побочных эффектов. Вот представьте себя владельцем компании с 2 тыс. человек: вам надо платить зарплату, налоги, аренду, рекламу и проч. А заказчики вам платят потому что ваши продукты лучше и дешевле чем у конкурентов. И всякий раз вы оказываетесь на распутье: разориться и кануть в небытие за счет чрезмерных затрат на написание идеального кода либо обойти конкурентов и продолжить работу. Разумеется, выбираете путь продолжения работы. Любыми возможными способами. И если один из способов ведет к увеличению объема кода и исполняемых файлов - то так тому и быть. Лучше так, чем небытие. Если у меня будет выбор между тем, чтоб иметь некачественный пакт тестового редактора, который весит 1 МБ и пакетом, который работает качественно и весит 1 ТБ - я выберу более качественный и докуплю железо.
И всякий раз вы оказываетесь на распутье: разориться и кануть в небытие за счет чрезмерных затрат на написание идеального кода либо обойти конкурентов и продолжить работу
Я бы маленькое уточнение добавил по поводу Elite: на спектурме все адресное пространство было размером в 64кб. Включая 16кб, занятых под ПЗУ (по современному - под операционную систему). И в это же адресное пространство входила и видеопамять размером порядка 6кб. То есть под саму игру было не 64кб, а всего 42кб.
Автор, в это игре весом 64КБ нет текстур. Вся графика закодирована. Накиньте сюда кучу картинок для улучшения графики и вуаля! Весить она уже будет от 1ГБ и выше в зависимости от качества и разнообразия. Добавьте сюда красивые реалистичные эффекты (взрывы, блики, тени и тд), физику (столкновения, скольжения, отскоки и тд) и вам уже потребуется современный комп.
Это как в одной из статей человек недоумевал, что игра Марио весит меньше, чем скриншот экрана с этой игры.
А теперь про раздутый код. Это не вина программистов, это вина бизнеса. Вы говорите, что написать аггрегатор файлов это простая задача. Увы, это не так. Чтобы писать низкоуровневый код, нужно низкоуровневое понимание происходящего внутри вашего компьютера. А для этого надо долго и упорно в этом разбираться. В итоге, разработка всей этой, казалось бы, простой программки выльется в копеечку. Я уж молчу про поддержку и доработки. Намного быстрее и дешевле использовать наработки коллег, собранные десятилетиями.
Если привести аналогию, то для создания молотка нужно отдать чертеж рукояти в столярку и чертеж наконечника в литейную, затем скрепить вместе и все, можно продавать. А по вашей логике человек должен сесть, выточить из чурки рукоять (кстати, а чем он будет вытачивать, неужели придется взять готовый нож?), отлить наконечник, обработать на наковальне (а ее откуда откуда взять?), отшлифовать (чем?)... Это будет золотой молоток, его смогут позволить себе только те, кому он особо то и не нужен. К тому же, пока конкуренты выпустят 1000 молотков, вы осилите лишь один, а значит все вкусные контракты будут у них.
В общем я все это к тому, что пользоваться благами цивилизации - разумно. Главное пользоваться разумно. :)
А насколько разумны те или иные вещи, решает сегодня рынок, а не плотники, кузнецы и программисты.
А насколько разумны те или иные вещи, решает сегодня рынок, а не плотники, кузнецы и программисты.Рынок всегда был и всегда давил на исполнителей, и быть его рабом или оставаться личностью — выбор за нами. Это борьба, которая как раз и формирует личность счастливого человека.
Достижение результата разве не есть цель, которая поощряется особым гормоном в мозгу? Знаете, если я не написал все сам от начала и до конца, я все равно получу удовольствие от того, что умело оркестрирую инструментами. Бизнес быстрее получит выхлоп. Интел быстрее продаст свой новенький процессор. Все в плюсе. Кроме пользователей :)
А вот если вы хотите сделать что-то для людей, это вам благотворительностью надо заниматься (писать приложения в свободное от работы время бесплатно).
Ну и кстати, для справки. Даже если приложение, с которым пользователь работает изо дня в день, откликается на каждый тык по секунде, в день тратит на раздумья около двух часов, это все равно быстрее, чем если бы пользователь делал это все вручную целый месяц вместо дня. Так что в плюсе даже пользователи.
Достижение результата разве не есть цель, которая поощряется особым гормоном в мозгу?Этот гормон вырабатывается не только от результата, но и от процесса. И если человеку платить достаточно много за очевидно (для него) абсурдную деятельность, то через время он впадет в депрессию.
я все равно получу удовольствие от того, что умело оркестрирую инструментамиНу так вот и я про то-же.
А вот если вы хотите сделать что-то для людей, это вам благотворительностью надо заниматьсяНу не знаю… Я не вижу причин, чтобы нельзя было работать за деньги и работать так, чтобы мне это всё нравилось. Просто здесь надо стремиться именно к этому, подводить окружающих к своему образу работы и т.д.
Этот гормон вырабатывается не только от результата, но и от процесса.
Увы, если процесс затягивается, начинается выгорание. К тому же, я бы не назвал обсурдной деятельность по созданию чего то полезного. Помните? Изначально у нас одна цель, просто вы говорите о другом пути.
Ну так вот и я про то-же.
Не знаю как вы, а автор говорит о том, что инструменты надо создать самому. Типа зачем тянуть за собой целую библиотеку math когда из нее нужна только функция sin(a).
Ну не знаю… Я не вижу причин, чтобы нельзя было работать за деньги и работать так, чтобы мне это всё нравилось.
И я не вижу.
Просто здесь надо стремиться именно к этому, подводить окружающих к своему образу работы и т.д.
Вы только помните, что окружающим это тоже должно нравиться. И бизнесу в первую очередь, ведь это они платят и платят не за то, чтобы вам что-то там нравилось ;)
заказчики всегда будут давить быстрее-быстрее, я тебе плачу, и т.д.
Только неадекватный заказчик. Понятное дело, откровенное дерьмо писать не надо, но давайте будем честными, предела совершенству нет :)
Код можно улучшать до бесконечности.
А по поводу библиотек, они должны быть максимально декомпозированы. То есть создатель библиотеки должен позаботиться о том, чтобы можно было подтянуть минимум необходимого.
Мы ещё долго не останемся без работы! ]:->
А что если софт это темная энергия и он разбухает потому же почему постоянно увеличивается Вселенная? Тем более что и там и там рост экспоненциальный?
К сожалению все так. Во главу угла ставится скорость разработки без вникания в суть задачи. В итоге разработчики ради одной простой функции добавляют зависимость от библиотеки огромного размера, большая часть которой вообще не работает в его коде, но жрет память в которую размещается при загрузке.
Мало кто ставит задачу минимизировать требования к ресурсам.
Более того многие разработчики даже не знают какую цену платят за использование тонны стороннего кода и библиотек. Они даже не пытаются разобраться, а зачем? Все же просто как в конструкторе - тяп, ляп и собрал, скотчем замотал и вперед на танки.
https://www.youtube.com/watch?v=TGtaLl--NjU&ab_channel=АлександрНикитин
Графический редактор который прекрасно работает на процессоре 3мгц и занимает 48кб памяти. А почему фотошоп на 1ггц процессоре с гигом оперативы тормозит?
Возможно, фотошоп умеет немного больше, чем редактор от ZX Spectum?
Настолько больше, что требует более чем в 333 раза больше ресурсов процессора? И более чем в 21845 раз больше озу?
Это при том, что ArtStudio имеет довольно хороший функционал, включающий в себя заливку сплошным текстом, заливку текстурой, редактор шрифтов и многое другое.
И все это в приятном оконном интерфейсе
Настолько больше, что требует более чем в 333 раза больше ресурсов процессора? И более чем в 21845 раз больше озу?
Это при том, что ArtStudio имеет довольно хороший функционал,
Давай даже проще. ArtStudio имеет функционал выше, чем у mspaint.
ArtStudio работает на 48кб памяти, но имеет версию под 128кб. 16384 байт памяти спектурма уходит под системные нужды. Прикидываем, что размер самого ArtStudio не более 112кб
mspaint в win10 занимает 965кб
Как тяжко жить. Мама, роди меня обратно. Лет через 20 на Марс полетим. Там не то что в этих Америках. Там воздух чище, границ нет, законов нет, делай что хочешь, живи как хочешь. Там глядишь и код раздутый забудем, всё новое будет, всё своё. А эта планета заражена человеками, её не спасти, эти ничем не выводятся, как клопы. Пусть и дальше пишут тут свой код до посинения.
Так иначе быть и не могло. В сфере изначально не было стандартизации, точнее она была, но потом появлялись люди со своим видением и новыми стандартами (языками, концепциями, осями и вообще), потом появлялись концепции объединения концепций, кроссплатформеннсти всякие и т.д. и т.п. Неуправляемый винегрет лег на благодатную почву бума распространения информационных устройств (благо железячники тоже не отставали в разнообразии подходов) и их пользователей с разношерстными требованиями и программистов с безграничной градацией квалификации. Всё приправилось практически неизбежной необходимостью в back compatiblе. Ну и рыночек - ему надо быстро, хищно и маржинально, а не идеологически правильно. В общем хомячок стал медведем и что с ним делать неясно, хотя в целом он очень даже мил :)
Я думаю лечится это всё только тотальной информационной диктатурой с единым сводом правил и системой оценки. Причем оценка должна быть ресурсно-энергетическая, а не просто субъективный код ревью, любой код внедряется только в том случае, если он укладывается в заданные рамки потребления энергии, материалов . В некоторых отраслях типа военки и космоса и сейчас так, а должно стать повсеместно. Наверно такие порядки настанут после технологического и/или энергетического коллапса. Неизвестно когда, правда.
Кстати всегда было интересно, почему столько разговоров про зеленую энергетику, глобальное потепление и все такое на высших уровнях, но при этом никого не заботит, что какой нибудь паразитный сервис работающий на сотнях миллионах устройств сжигает дохренища энергии. Почему об этом молчит Грета?
Сколько там этот паразитный сервис сожрёт, десяток ватт максимум?
десяток ватт за год на десятке миллионов устройств - это много, вопрос не в том что есть сам факт потребления, а в том что оно паразитное (в отличие например от отопления, которое необходимо). А сколько такого рода паразитов заложено на всех уровнях - никто я думаю вообще не считал.
Потому что это другое, ну вы понимаете. Маркетинг и бизнес не имеет отношения к экологии.
Если взять в пример те же станки с ЧПУ то там удивительным образом нет такой деградации так как есть прямая связь между время=деньги. Поэтому и программы до сих пор легкие и при желании программиста даже читаемые.
Бытовой пример оптимального и эталонного программирования это классическая игра Linage II. Минимальный объём кода при максимальной эффективности графики, производительности, онлайн заполненности игроков и оптимального использования ресурсов оси и железа. Многим современным програмистов до того уровня расти и расти.
Можете пояснить, что вы имеете в виду? Серверная часть, клиент, какого года?
Самые первые релизы 2002-2004 года. Ошибки и баги конечно здесь не учитываю. Сама реализаиця порясающая и для того времения и для нашего как эталон..
Вот не соглашусь. При большом количестве игроков начиналось знатное лагалово, и затыком становился именно клиент, причём проблема была не в отрисовке графики, а в обработке данных процессором и натягивании совы (Unreal engine) на глобус. Такое ощущение, что вместо нормальных коллекций и алгоритмов разработчики использовали простые алгоритмы с неоптимальной асимптотикой. И да, были утечки памяти: после нескольких часов работы клиента он начинал тормозить даже на простых сценах. Например, сервер частенько забывал отправить пакет, что объект пропал и его нужно удалить. В результате при многочасовой прокачки на споте в памяти клиента висели тысячи невидимых объектов, которые он был вынужден обрабатывать.
Я просто раньше занимался написанием бота-радара под Lineage II, видел всю дичь. Ещё я проводил стресс-нагрузку клиента: смотрел, что будет, если постоянно спавнить и удалять объекты. Нормальному клиенту было бы пофигу, но в родном клиенте начиналась утечка памяти.
Подскажите, пожалуйста, почему код, как написанный программистом текст, так сильно связан с кодом, как машинными командами?
Из-за этого все проблема. Почему разработчик не может писать много-много абстракций, а компилятор не будет разворачивать их в что-то простое для вызова?
Собственно ведь такой подход и применяется, только в ограниченном виде. Надо развивать промежуточные слои компиляции, вроде синтаксического дерева.
Грустное чувство возникает, когда видишь, как к Elite 84го ссылаются как к эталону эффективного кода, при этом зная, в каком техническом состоянии находится её наследница, Elite Dangerous.
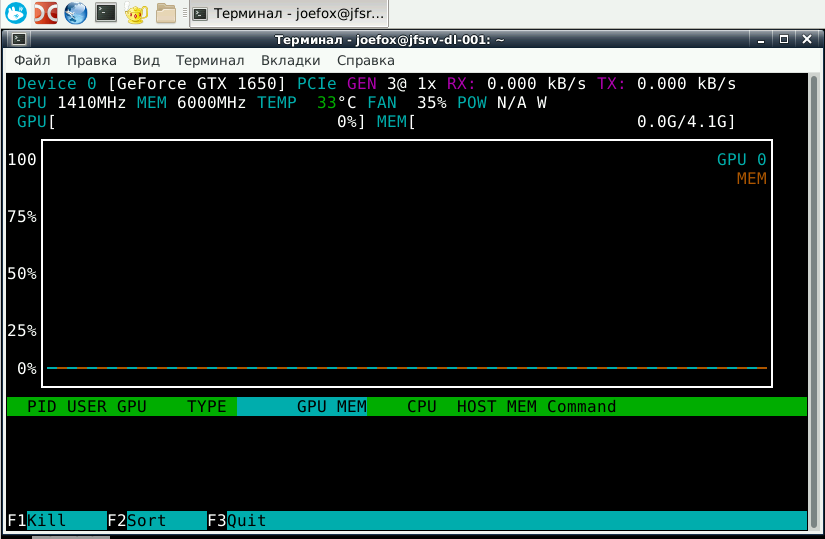

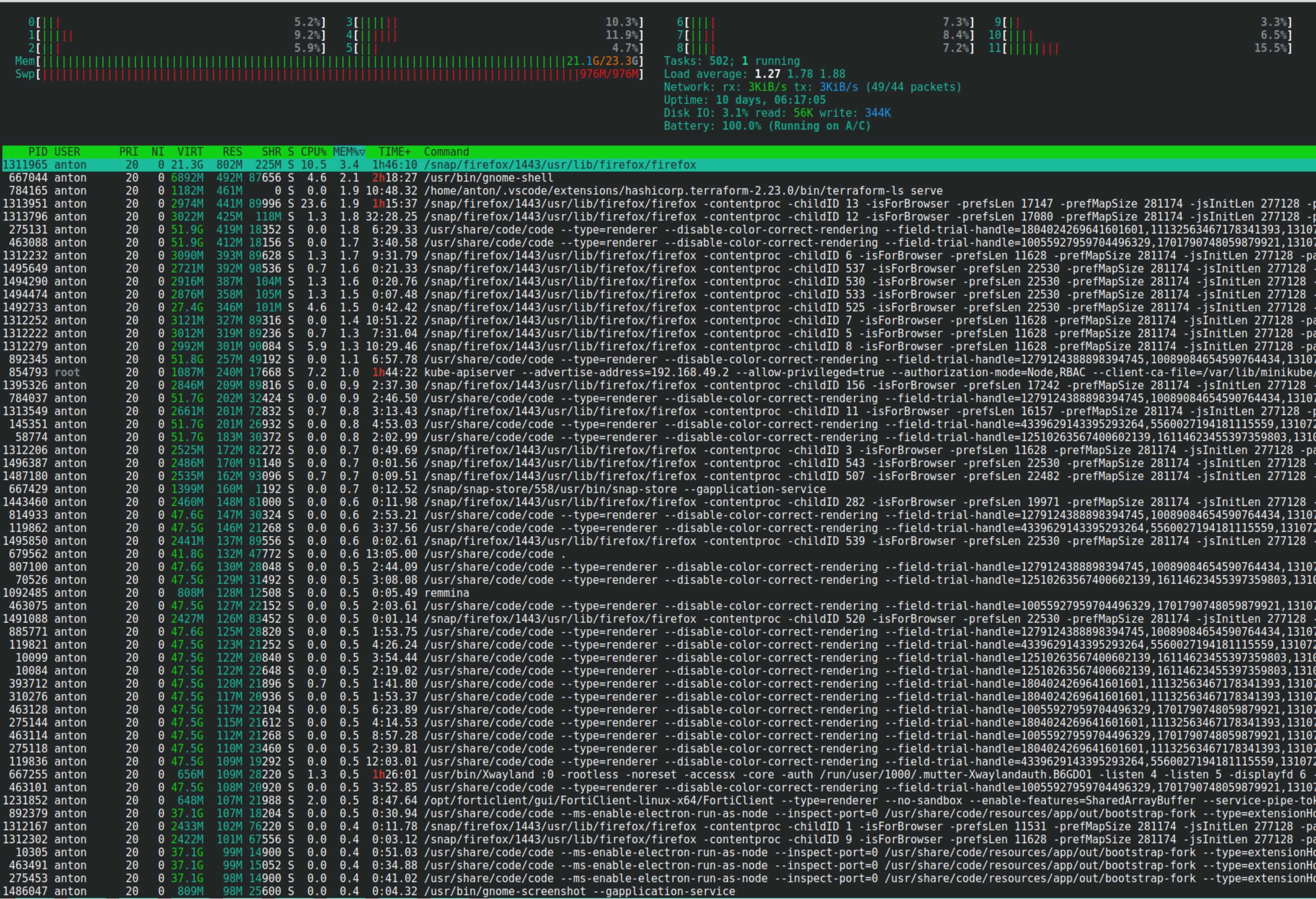

{kind=link}
{kind=link}
Раздувание кода стало астрономическим