
Всем привет! Меня зовут Валерия Дымбицкая, я технический руководитель команды дата-инженеров в oneFactor. В этой статье я расскажу о том, как мы научились автоматически подбирать параметры для Spark-приложений на основе логов.
Проблема, которую мы решали, может встретиться при регулярном, предсказуемом, интенсивном использовании Hadoop-кластера. Я расскажу, как мы простыми средствами сделали рабочую автономную систему тюнинга, сэкономив в итоге 15-16% ресурсов кластера. Вас ждут детали с примерами кода.
В первой половине статьи я расскажу про то, какая перед нами стояла задача, и разберу ключевые пункты для её решения. Во второй половине будет рассказ о том, как это решение подготовить к работе на продуктиве, и что мы из этого всего получили.
Зачем нам вообще понадобился автоматический тюнинг?
Начнём с инфраструктуры. Сетап у нас "классический": ограниченный Hadoop-кластер из купленных серверов. В нём на тот момент, когда мы начали всё это делать, было около 30Тб RAM и 5к CPU. В этом кластере запускается множество разноплановых приложений на Apache Spark и в какой-то момент им стало тесновато. Всё больше приложений висели в PENDING значительное время, потребление памяти утроилось за последние 4 месяца. Сохранять такую тенденцию не хотелось.
Довольно много приложений были от продукта Лидогенерация. Базово он устроен так: есть список номеров телефонов (база) и есть Spark ML Pipeline, который каким-то образом отбирает из этой базы лидов абонентов для некоего целевого действия, например, для предложения продукта клиенту. База может меняться от раза к разу. Вот такую пару из меняющейся базы и пайплайна мы называем триггером.

Триггер делается для клиента и ставится на расписание. У него есть свой SLA. Таким образом, каждый день, каждый час и т.д. для клиента запускается соответствующее Spark-приложение.
Главное здесь вот что: ни одну часть этого процесса мы как дата-инженеры не контролируем. Дата-саентисты сами делают пайплайн (пусть и на наших инструментах). Он автоматически выводится в продуктив, а подключается к тем или иным базам руками бизнеса. Пайплайны уникальны, а предсказать, какой объём данных он будет обрабатывать, нельзя. Если в день происходит порядка 600 разных запусков, а каждые два-три дня добавляется новый триггер, очень сложно бегать за каждым приложением и тюнить его руками. Поэтому мы сразу целились в автоматизацию.
Технически же проблема была следующая. Чтобы не бегать за каждым триггерам, всем им выставлялись одинаковые настройки, в том числе по ресурсам. Выставляли с запасом, чтобы гарантированно прошло. Единственное, что мы разделяли - это два типа запусков: дневной и часовой. Дневные запуски происходят раз в день, часовые – раз в час. В них обычно пайплайны разной тяжести, часовые, как правило, полегче. На каждый триггер есть свой SLA, и если раз в час запускать тяжёлый пайплайн, то вряд ли получится уложиться. Поэтому часовым мы выделяли меньше ресурсов: если говорить о spark.executor.memory, то дневным мы ставили по 16 Гб, часовым – 7 Гб. Но сам паттерн не менялся: разным расчётам выдаются одинаковые ресурсы.
В чём минус такого подхода? Например, у нас есть два триггера, пусть даже с одинаковым пайплайном. Только у одного база в 10 тысяч строк, а у другого – в 250 миллионов строк. При этом контейнеры мы им выделяем одинаковые. Значит такие маленькие триггеры могут забрать себе все оставшиеся контейнеры и большому просто не хватит ресурсов, он будет в списке ожидания.
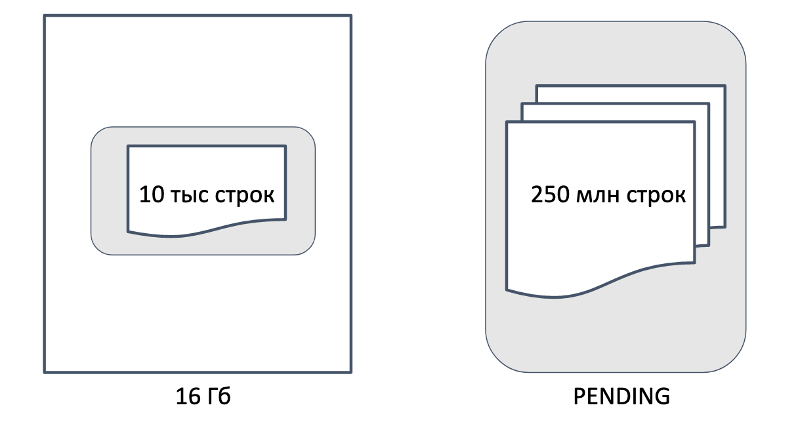
Если таких приложений много, то и список ожидания растёт. А SLA при этом никуда не девается. Очевидно, что если бы мы выделили маленькому триггеру контейнеры меньшего размера, то ресурсов могло бы хватить на большой контейнер для большого триггера, и они могли бы рассчитываться параллельно.
Итак, задача: научиться автоматически определять оптимальный размер контейнеров для расчёта. Эту задачу сам Spark не решает: он умеет динамически аллоцировать контейнеры, то есть менять количество, но не размер.
Мечта о классификаторе
Как мы думали вначале? Пайплайны, может, и уникальные, а реальные кейсы – вряд ли. Если развить наш инсайт про дневные и часовые пайплайны, то правильным шагом было бы найти классы триггеров, подобрать для них параметры и построить классификатор для пар пайплайн-база. А так как у нас есть сервис пакетной обработки ML-Batch, который эти триггеры и запускает, то этот классификатор можно было бы встроить в него. Тогда перед каждым запуском мы определяем класс триггера и связанные с ним параметры запуска.
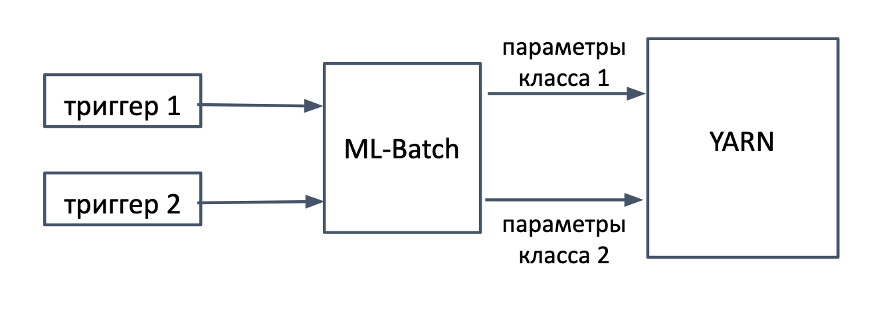
С этим решением связаны сразу две проблемы:
Как лучше классифицировать триггеры, если признаковое пространство, которое они используют, велико и постоянно пополняется новыми признаками?
Как подобрать параметры для классов и не убить прод в процессе экспериментов?
Если первую проблему ещё можно было бы решить (хотя сходу это не так просто), то вторая фактически перекрывала нам возможность такой реализации. В самом деле, у нас ведь нет данных, как поведут себя расчёты на других настройках. Значит, нам нужно много экспериментов. Проводить их лучше на среде близкой к продовой. А у нас и так с железом туго. То есть такое решение делать долго и дорого.
Мечту о классификаторе пришлось отложить, и мы пошли другим путём.
Historical Tuning
Если первый подход я про себя называю "априорным", то второй – "апостериорным". В такой реализации мы сначала даём приложению пройти, а потом смотрим на его метрики и корректируем параметры для следующего запуска.

Основную роль здесь играет регулярность запусков. Это даёт нам возможность менять параметры постепенно с течением времени. Такой подход называется historicaltuning или тюнинг на основе истории. Есть несколько выступлений от зарубежных компаний на эту тему (не все из этих компаний сейчас легальны в РФ). Нигде, однако, не было ответа на вопрос, а как же это всё сделать.
Лог событий Spark
Откуда брать метрики? Для этого мы обратились к логам событий Spark. Spark пишет очень много статистики, на основе которой строится Spark UI. Их можно собирать через REST, через SparkListener, а можно включить запись этого лога на HDFS – это то, что читает History Server.
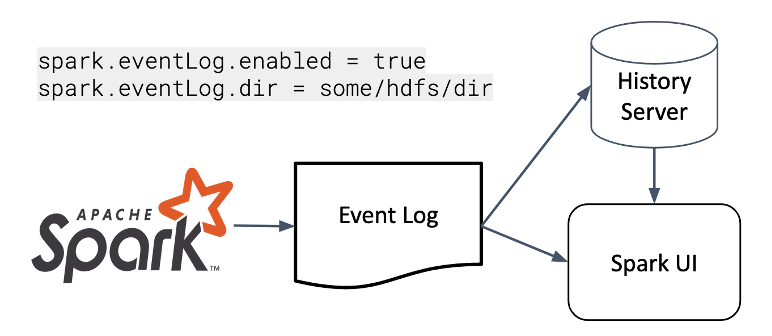
В таком случае это файл в формате JSON Lines, то есть он может быть прочитан в том числе через сам Spark. Мы читаем этот файл: это в том числе позволяет обрабатывать логи от многих приложений.
Чтобы получить нужные метрики, нужно отфильтровать датасет по нужному типу события – иначе может неправильно разрешиться схема:
val events = spark.read .json("/user/spark/applicationHistory/application_1502789566015_25541") .withColumn("application_attempt", "application_1502789566015_25541_1") val taskEndMetrics = events.filter("Event='SparkListenerTaskEnd'") taskEndMetrics.printSchema()
Каждому файлу логов мы также добавляем после чтения поле application_attempt для идентификации.
Наиболее интересны здесь подструктуры Task Info и Task Metrics:
taskEndMetrics .select("Stage ID", "Task Info.*", "Task Metrics.*") .printSchema()
Здесь находится море полезной информации, например:
... |-- Task ID: long (nullable = true) |-- Disk Bytes Spilled: long (nullable = true) |-- Executor CPU Time: long (nullable = true) |-- Executor Deserialize CPU Time: long (nullable = true) |-- Executor Deserialize Time: long (nullable = true) |-- Executor Run Time: long (nullable = true) |-- Input Metrics: struct (nullable = true) | |-- Bytes Read: long (nullable = true) | |-- Records Read: long (nullable = true) |-- JVM GC Time: long (nullable = true) ...
Это далеко не полный список. И это та же самая информация, которую мы используем, когда тюним приложение руками. То есть на основе экспертизы мы можем сформировать некие правила, которые покажут, хорошо приложение проходит или плохо, можно ему менять ресурсы или нет.
Тюним spark.executor.memory: три правила
Тюнинг памяти экзекьютеров был нашей первоочередной задачей. Поэтому здесь будут рассматриваться правила именно для неё, хотя общий подход универсален.
Мы хотим найти для каждого приложения минимальный порог памяти, при котором оно успешно завершается и укладывается в SLA. Также наше базовое предположение – что мы выделяем слишком много ресурсов, поэтому мы скорее ищем не признаки того, что снижать можно, а признаки того, что снижать уже нельзя.
Мы можем рассматривать приложение с разных сторон, например: по использованию GC, по количеству spill'а в память и на диск, по количеству читаемых данных, по размеру шаффлов. Для каждого случая можно построить некий числовой показатель, который предскажет, насколько можно изменить целевой параметр. На основе совокупности таких показателей мы можем принять решение, снижать ли память и насколько.
Рассмотрим подробно правила построения таких показателей, к которым мы пришли.
Правило 1: Время сборки мусора не должно превышать 10% от времени работы.
Если приложение начинает слишком много времени проводить в GC, это негативно сказывается на времени его выполнения, так что здесь мы работаем на SLA. Падения из-за этого также возможны, но до этого уже не хотелось бы доходить. 10% – это эмпирическая цифра, порог, когда приложению становится "плоховато".
Здесь нам помогает Task Metrics:
taskEndMetrics .selectExpr("application_attempt", "Task Metrics.*") .selectExpr("Finish Time - Launch Time as duration", "JVM GC Time") .groupBy("application_attempt") .agg(sum("duration").alias("total_duration"), sum("JVM GC Time").alias("total_gc")) .withColumn("prediction1", expr("(total_gc / total_duration - 0.1) * <current spark.executor.memory>")) .show()
Правило 2: Spill – плохо, по возможности избегайте этого.
Если записи перестают помещаться в память экзекьютора, Spark начинает сбрасывать их на диск, что сильно замедляет процесс. Мы хотим такой ситуации избежать, поэтому показатель будет иметь неотрицательное значение, амортизированное относительно объёма собственно сброшенных данных. Мы считаем среднее между объёмом непосредственно в памяти и объёмом со сжатием на диске, и находим максимум по таскам.
taskEndMetrics .selectExpr("application_attempt", "Task Metrics.*") .groupBy("application_attempt") .agg(max("Memory Bytes Spilled").alias("mem_spill"), max("Disk Bytes Spilled").alias("disk_spill")) .withColumn("prediction2", expr("(mem_spill + disk_spill) / 2")) .show()
Правило 3: чтения, шаффлы, временные объекты и результаты должны помещаться в половину от spark.memory.fraction
Здесь уместно вспомнить о модели памяти Spark. Heap-память экзекьютора поделена на несколько областей, размер которых управляется несколькими параметрами:

Упомянутые "статьи расхода" (чтения, шаффлы, и т.д.) вписываются в раздел Spark Memory. Помимо этого есть ещё кэшируемые данные и результаты бродкастов, которые, увы, в истории не остаются (по крайней мере, у нас). Поэтому мы сознательно уменьшаем лимит используемой памяти по тем параметрам, что мы можем отследить, до половины.
Большую часть данных мы можем получить из Task Metrics:
val metrics1 = taskEndMetrics .selectExpr("application_attempt", "Task Metrics.*") .select((col("`Input Metrics`.`Bytes Read`") + col("`Shuffle Read Metrics`.`Remote Bytes Read`") + col("`Result Size`") + col("`Shuffle Write Metrics`.`Shuffle Bytes Written`") + col("`Shuffle Read Metrics`.`Local Bytes Read`") + col("`Shuffle Read Metrics`.`Remote Bytes Read To Disk`") + col("`Output Metrics`.`Bytes Written`")).as("bytes_all") .groupBy("application_attempt") .agg(max("bytes_all").alias("max_bytes_all")) .cache()
Однако там нет важного параметра – пиковой памяти исполнения (peak execution memory). Она как раз относится ко временным объектам, например, таблицам, создаваемым во время джойнов. Без этого параметра мы не могли добиться хорошей точности и получали ошибки, пока не увидели, что он прячется в истории аккумуляторов в Task Info:
val metrics2 = taskEndMetrics .selectExpr("application_attempt", "explode(Task Info.Accumulables) as acc") .selectExpr("acc.*") .where("Name = 'internal.metrics.peakExecutionMemory'") .groupBy("application_attempt") .agg(max(col("Update").cast(LongType())).alias("max_peak_mem")) .withColumn("application_attempt", <app attempt>) .cache()
Только вместе они дают нужную формулу для нашего правила:
metrics1 .join(metrics2, "application_attempt") .withColumn("prediction3", expr("(max_bytes_all + max_peak_mem) / <current spark.executor.memory>") - (<spark.memory.fraction> / 2) * <current spark.executor.memory>) .show()
Итак, из логов событий Spark можно вытащить много полезной информации. Применяя идущие из экспертизы эвристики, можно посмотреть на завершившееся приложение с разных сторон и предсказать различные дельты подбираемого параметра. Эти дельты могут масштабироваться вместе с параметром: в нашем случае по мере уменьшения памяти уменьшается и потенциальный шаг изменения.
Но как теперь собрать эти дельты в единое целое и превратить в автономно работающую систему? Об этом поговорим во второй части.
