
Привет, Хабр! Меня зовут Евгений Лукин, я работаю в СберТехе и занимаюсь развитием интеграционных продуктов.
Сегодня поговорим об импортозамещении в банке с миллионами клиентов. Это интересный опыт, который, как мне кажется, будет полезен любому бизнесу. Ниже — мой рассказ о том, как мы заменили корпоративную шину иностранного вендора в Сбере, построив собственную cloud-native децентрализованную интеграционную платформу, и с какими вызовами столкнулись в процессе.

Почему классическое импортозамещение — машина времени в прошлое
Часто компании представляют себе процесс импортозамещения Oracle примерно так:
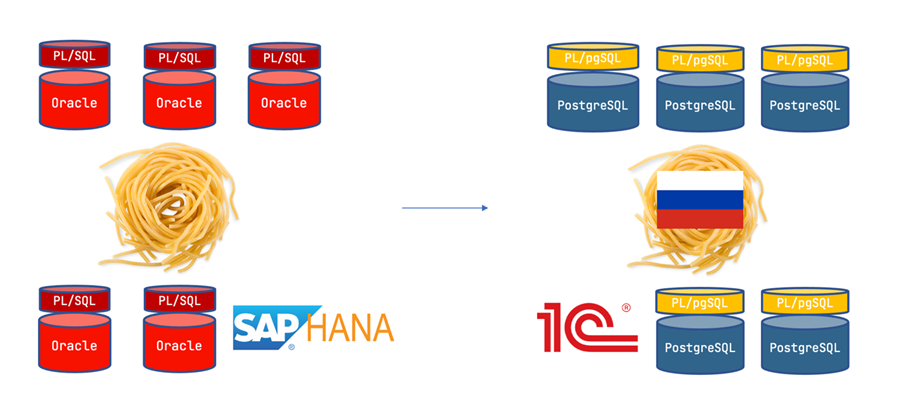
У нас есть набор баз данных Oracle со слоем логики на PL/SQL, есть SAP, есть шина данных. И всё это нужно заменить, желательно один к одному.
Но «просто переезжать» с Oracle на PostgreSQL или любой другой open-source сложно и экономически невыгодно. Придётся останавливать или замедлять бизнес-разработки, переучивать команды, бороться с багами, заниматься миграцией. И всё это только для того, чтобы через год-два все изменения свелись к новому лейблу в архитектуре, а функциональность при этом осталась прежней.
Означает ли это, что импортозамещение невозможно и ничего менять не надо?
Вот пример такого консервативного подхода — крупные ведомства и компании, которые ни разу не сталкивались с необходимостью импортозамещения.
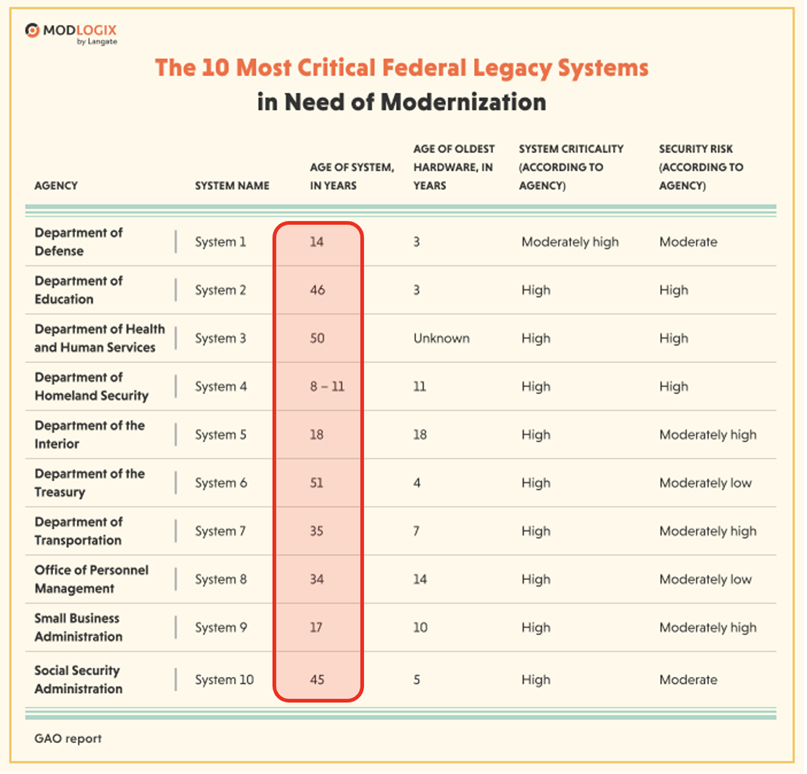
Хотели бы вы заниматься поддержкой или развитием систем, созданных с использованием технологий полувековой давности? Не думаю.
Получается, есть две крайности:
Стабильность — плохо: отсутствие обновлений в архитектуре, устаревший стек, проблемы с развитием и сложности с привлечением разработчиков.
Модернизация — тоже не очень хорошо, потому что дорого и больно.
Рассказываю, как мы решали эту дилемму в Сбере, с какими вызовами столкнулись и к каким выводам пришли.
Кейс с импортозамещением шины данных в Сбере
До цифровой трансформации в Сбере, как и в большинстве enterprise-корпораций, использовался типовой интеграционный паттерн — корпоративная сервисная шина. Его центральным элементом была шина данных. Работало это следующим образом: потребитель отправлял запрос в очередь, сообщения обрабатывались, маршрутизировались и отправлялись в Messages queue поставщику данных. Он в свою очередь обрабатывал и возвращал ответ.
Поставщики и потребители данных отвечали только за подключение к очередям сообщений, а с интеграционной логикой и очередями работали выделенные команды миграции.
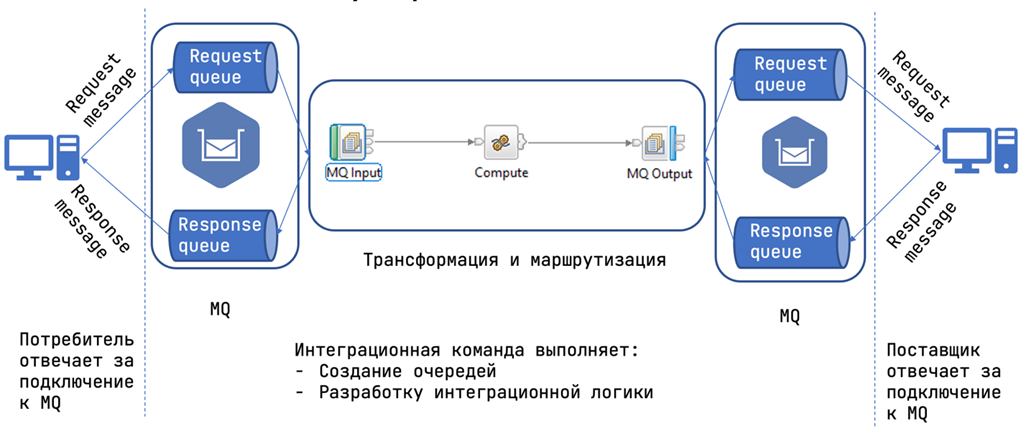
До определённого момента такой подход всех устраивал с точки зрения надёжности и производительности. Но со временем, когда стало появляться больше новых удобных приложений, трафик стал увеличиваться. А вот шина позволяла реализовать только вертикальное масштабирование за счёт покупки новых high-end-серверов. Мы были вынуждены создавать новые инстансы шин данных.
Корпоративная сервисная шина — это всегда некий проприетарный софт со своими особенностями и языком. Поэтому за любые доработки, изменения внутри сервисной шины отвечают одна или несколько выделенных команд специалистов со знанием этого софта. И такие команды неизбежно становятся «бутылочными горлышками»: никакое изменение, доработка не могут пройти мимо них, а значит их бэклог перегружен, а задачи копятся, снижая общий time-to-market.
Нам нужно было найти принципиально новое решение, которое позволило бы реализовать горизонтальное масштабирование: поднимать дополнительные поды в соответствии с ростом и падением нагрузки. При этом сам процесс интеграции должен быть децентрализованным, чтобы работать с ним могли любые команды. А так как в Сбере несколько тысяч различных команд разработки, из этого вытекало ещё одно требование к новой шине: транспортный слой должен быть изолирован от языка и от прикладной логики сервиса.
Platfrom V Synapse — с чего начали
Мы проанализировали возможные варианты и поняли, что паттерн Service Mesh отлично подходит под наши задачи. В Service Mesh за интеграционную обвязку, включая timeouts, retries, circuit breakers и так далее, отвечают конфигурационные файлы. Они поставляются вместе с исходным кодом, подхватываются контрольной панелью и распространяются на все микросервисы, участвующие в миграции через proxy-компонент (в нашем случае — Envoy).
Так как любая миграция — это всегда риск сломать что-то важное, пошли по пути parallel run. Решили оставить старую шину данных, построить рядом новую и добавить «смарт-топоры», которые отслеживают количество ошибок в мониторинге и в нужный момент переключаются на старую шину.
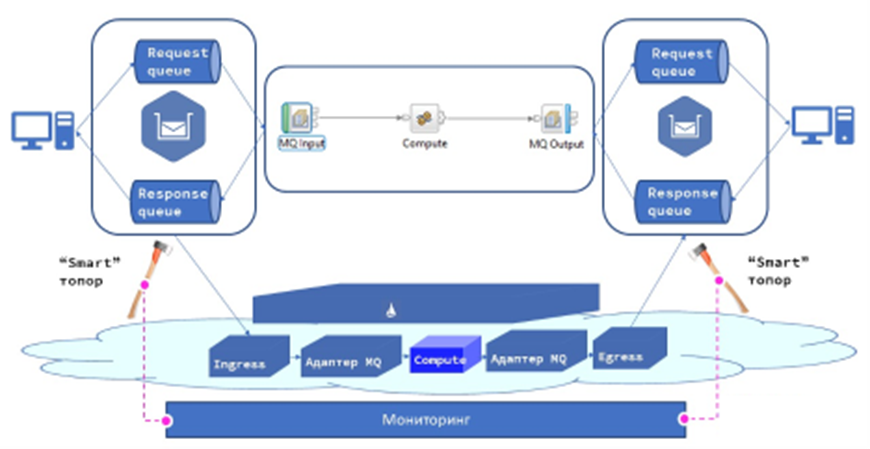
Так выглядела исходная идея. Казалось, мы продумали всё: масштабирование, децентрализацию и даже план отката.
Но нас ждали интересные открытия.
Что мы не предусмотрели
Service Mesh может быть сложным
Важный момент при использовании горизонтального масштабирования — сервисы с волнообразной нагрузкой. У нас есть сервисы, по которым нагрузка меняется волнообразно. Например, пришла зарплата, поэтому многие идут в СберБанк Онлайн делать переводы или производить оплату. И нагрузка на такие сервисы растёт мгновенно. На графике ниже видно, что активность в приложении меняется волнообразно, есть определённые периоды, когда нагрузка может резко подскочить, а потом так же резко упасть.
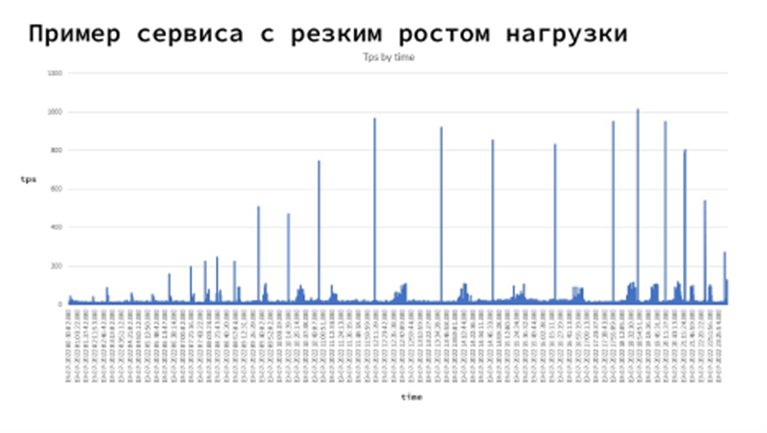
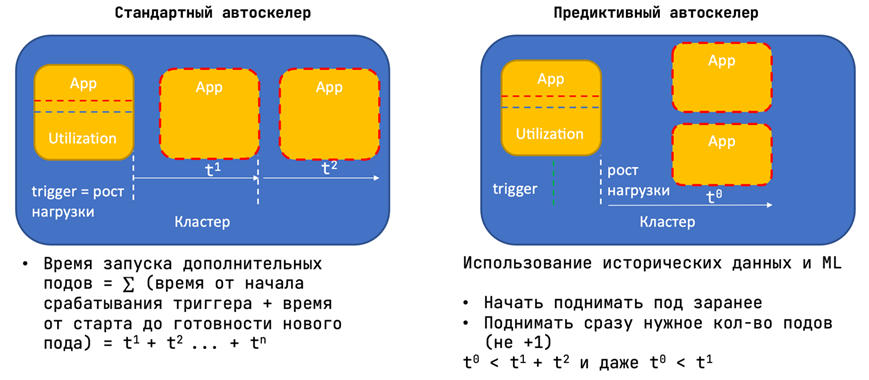
Если мы работаем со стандартной моделью автоскейлинга в Kubernetes или OpenShift, которая ждёт превышения установленного порога по нагрузке и потом начинает последовательно запускать копии приложений, то просто не успеем обработать весь трафик.
Что сделали: вместо того чтобы установить в качестве триггера порог по нагрузке, начали прогонять трафик через наш компонент Platform V SynAI. Это предиктивный автоскейлер, который анализирует исторические тренды поведения трафика и, используя модель Machine Learning, предсказывает возможные скачки заранее. С его помощью можно предугадать рост нагрузки перед очередным скачком и заранее поднять нужное количество подов, а после снижения трафика — сократить.
За надёжность приходится платить ресурсами
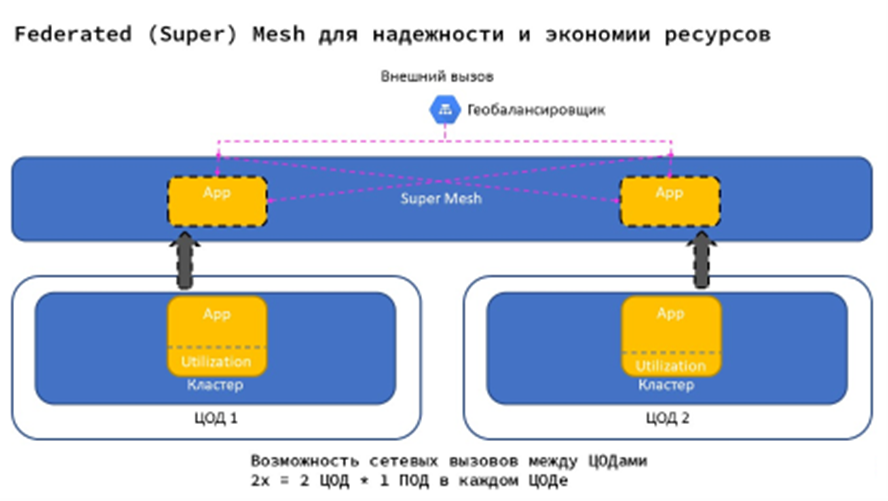
Очевидно, что горизонтальное масштабирование работает, пока у вас достаточно места для того, чтобы скейлиться. Неочевидно другое: из-за того что масштабирование напрямую связано с ресурсами, мы начинаем платить этими ресурсами за надёжность.
Скажем, раньше у нас был один сервер, в котором можно было легко просчитать утилизацию, учесть пики и заложить рост. Теперь — как минимум несколько центров обработки данных (ЦОД). В каждом из них должен быть под, а лучше несколько, потому что нужно гарантировать надёжность: вдруг этот единственный под зайдёт на плохую ноду, которая «зависнет» и погубит весь трафик. В результате в каждом ЦОД есть не меньше 2 подов, которые нагружены только отчасти. Надёжность обеспечена, но ресурсов потребуется минимум в четыре раза больше.
Что мы сделали: создали новый компонент Federated (Super) Mesh, который объединяет несколько кластеров/ЦОД в один единый Service Mesh. С этим компонентом запрос, не нашедший нужного пода в одном ЦОД, может быть перенаправлен в другой ЦОД на другой под. В итоге Federated Mesh позволяет не держать в каждом дата-центре несколько подов одновременно, а запросы маршрутизировать по мере необходимости.
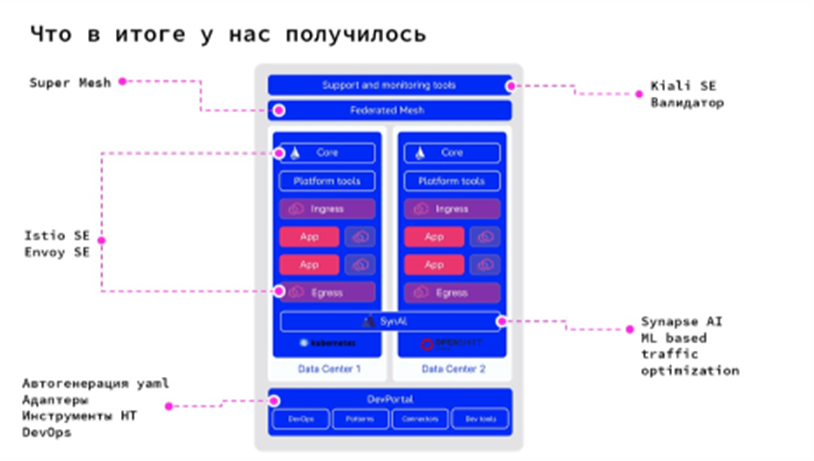
Что у нас получилось: Platform V Synapse спустя 2 года
В Platform V Synapse используются наши собственные сборки open-source-продуктов Istio и Envoy, доработанные до корпоративного уровня, к которым был добавлен большой спектр инструментов:
визуализация трафика;
дополнительные валидаторы, предотвращающие проблемы на стенде из-за возможных пересечений конфигурационных файлов многих команд;
SynAI;
SuperMesh;
DevPortal с набором инструментов для автоматической генерации YAML-конфигов, проведения нагрузочного тестирования, а также с готовыми адаптерами для интеграции с внешними системами, компонентами для реализации логирования и т. д.
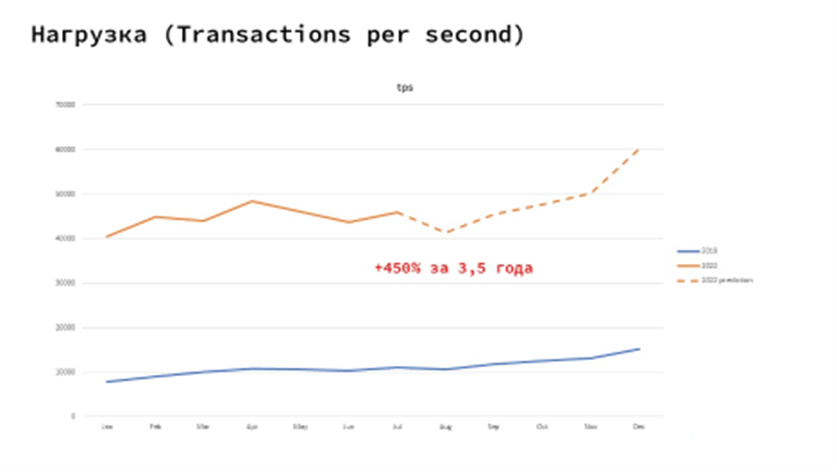
Platform V Synapse находится в промышленной эксплуатации в Сбере уже более трёх лет. Мы смигрировали более 4 тыс. сервисов с нашей старой шины данных, средняя нагрузка — более 50 тыс. запросов в секунду. Отказоустойчивость платформы — 99,99%. Сегодня любое взаимодействие с банком, вне зависимости от того, смотрите ли вы баланс в СберБанке Онлайн, переводите деньги или звоните в поддержку, основывается на обмене данных через Platform V Synapse.
Миграция на наше решение позволила Сберу снизить стоимость разработки, в 6 раз сократить TCO, существенно сократить time-to-market и, самое главное, обеспечить фундамент для дальнейшего роста на несколько лет вперёд.
Вместо заключения
Импортозамещение «в лоб» не работает: замена компонентов «один в один» замедляет развитие бизнес-доработок и не даёт никаких преимуществ, нагружая бюджет компании.
Выход видится таким: использовать текущую ситуацию в IТ как возможность глобально пересмотреть архитектуру. Заменить морально устаревшие legacy-решения на современные технологии, которые могут решить ваши боли.
Важно при этом оставить пути для отступления и продумать, как вы будете действовать, если новая технология сломается. А ещё нужно быть готовым к масштабным доработкам, например к тому, что придётся докручивать функциональность, оптимизировать ресурсы и решать вопросы с поддержкой. Конечно, для этого потребуются силы, время и сильная экспертиза. Поэтому, если вы сомневаетесь в собственных ресурсах, обращайтесь к нам — будем рады поделиться опытом и подробно рассказать о своих решениях.
