Начало работы с Petals
Этот блокнот познакомит вас с основами Petals — системы логического вывода и точной настройки языковых моделей с сотнями миллиардов параметров без необходимости использования высокопроизводительных GPU. С помощью Petals вы можете объединять вычислительные ресурсы с другими людьми и запускать большие языковые модели с миллиардами параметров, например BLOOM-196B или BLOOMZ того же размера, что и GPT-3.
Если при запуске этого блокнота возникнут проблемы, сообщите нам об этом на канале #running-a-client нашего Discord!
Установим Petals:
# Магия IPython закомментирована для совместимости с Python. # %pip install -q petals
Шаг 1. Простейший способ сгенерировать текст
Начнем с модели __DistributedBloom__ и ее применения для генерации текста.
Эта машина загрузит небольшую часть веса модели (~ 8 ГБ из 352 ГБ) и будет полагаться на другие компьютеры в сети для запуска всей модели. Загрузка локальной части весов обычно занимает ~3 минуты.
Мы предлагаем начать с обычного BLOOM, но можно воспользоваться BLOOMZ — версию BLOOM, оптимизированную для выполнения инструкций человека в режиме обучения без попыток. Чтобы загрузить эту модель, установите имя модели: MODEL_NAME = "bigscience/bloomz-petals".import torch from transformers import BloomTokenizerFast from petals import DistributedBloomForCausalLM MODEL_NAME = "bigscience/bloom-petals" tokenizer = BloomTokenizerFast.from_pretrained(MODEL_NAME) model = DistributedBloomForCausalLM.from_pretrained(MODEL_NAME) model = model.cuda()
Теперь попробуем сгенерировать что-нибудь методом model.generate().
Первый вызов занимает около 5 секунд для подключения к рою petals. После подключения можно ожидать скорость генерации 1–1,5 секунды на токен. Если у вас недостаточно графических процессоров для размещения всей модели, это намного быстрее, чем то, что получится с помощью других методов, таких как разгрузка, которая занимает не менее 10–20 секунд на токен.
inputs = tokenizer('A cat in French is "', return_tensors="pt")["input_ids"].cuda() outputs = model.generate(inputs, max_new_tokens=3) print(tokenizer.decode(outputs[0]))
Метод model.generate() по умолчанию запускает жадную генерацию. Можно выбрать и другие методы, такие как выборку top-p/top-k или лучевой поиск, передав соответствующие параметры. Можно даже написать пользовательские методы генерации, об этом подробнее ниже.
Ваши данные обрабатываются другими людьми из общего роя. О конфиденциальности — здесь. Для конфиденциальных данных вы можете создать приватный рой в кругу людей, которым доверяете.
Шаг 2. Чат-боты и интерактивная генерация
Если хотите общаться с моделью в интерактивном режиме, можно воспользоваться интерфейсом сеанса логического вывода, который предоставляет простой способ вывести сгенерированные токены на лету или создать чат-бота, реагирующего на фразы человека.
Сеанс логического вывода ищет цепочку серверов, которые будут выполнять последовательные шаги логического вывода и сохранять прошлые кэши внимания. Так для генерации фразы не нужно повторно запускать предыдущие токены через преобразователь. Если один из удаленных серверов выйдет из строя, Petals самостоятельно найдет замену и восстановит небольшую часть кэшей.
Давайте посмотрим, как использовать Petals для написания простого чат-бота, который показывает токены сразу после их создания:
with model.inference_session(max_length=512) as sess: while True: prompt = input('Human: ') if prompt == "": break prefix = f"Human: {prompt}\nFriendly AI:" prefix = tokenizer(prefix, return_tensors="pt")["input_ids"].cuda() print("Friendly AI:", end="", flush=True) while True: outputs = model.generate( prefix, max_new_tokens=1, do_sample=True, top_p=0.9, temperature=0.75, session=sess ) outputs = tokenizer.decode(outputs[0, -1:]) print(outputs, end="", flush=True) if "\n" in outputs: break prefix = None # Prefix is passed only for the 1st token of the bot's response
Создание приложений с Petals
Если вы разрабатываете инструмент для других людей, то с помощью Petals можете превратить код в удобное веб-приложение, такое как chat.petals.ml. Под капотом это приложение может подключаться к облегченной конечной точке HTTP для вывода, перенаправляющего все запросы в рой Petals.
Если вы создаете приложение с BLOOM с помощью Petals, убедитесь, что оно соответствует условиям использования BLOOM.
Шаг 3. Как это работает?
Ваша модель — настоящий BLOOM-176B, но в GPU компьютера загружена только ее часть. Заглянем под капот:
model.transformer
DistributedBloomModel( (word_embeddings): Embedding(250880, 14336) (word_embeddings_layernorm): LayerNorm((14336,), eps=1e-05, elementwise_affine=True) (h): RemoteSequential(modules=bigscience/bloom-petals.0..bigscience/bloom-petals.69) (ln_f): LayerNorm((14336,), eps=1e-05, elementwise_affine=True) )
Векторное представление слов и некоторые другие слои — обычные модулями PyTorch, размещенными на вашем компьютере, но остальная часть модели (например, блоки трансформаторов) заключена в класс RemoteSequential. Это расширенный модуль PyTorch, который работает на распределенном множестве других машин.
Тем не менее, вы можете получить доступ к отдельным слоям и их выводам, а еще пробежаться по ним вперед и назад:
first_five_layers = model.transformer.h[0:5] first_five_layers dummy_inputs = torch.randn(1, 3, 14336, dtype=torch.bfloat16, requires_grad=True) outputs = first_five_layers(dummy_inputs) outputs loss = torch.mean((outputs - torch.ones_like(outputs)) ** 2) loss.backward() # backpropagate through the internet print("Grad w.r.t. inputs:", dummy_inputs.grad.flatten())
Grad w.r.t. inputs: tensor([ 0.0265, -0.0212, 0.0121, ..., 0.0019, -0.0002, 0.0012], dtype=torch.bfloat16)
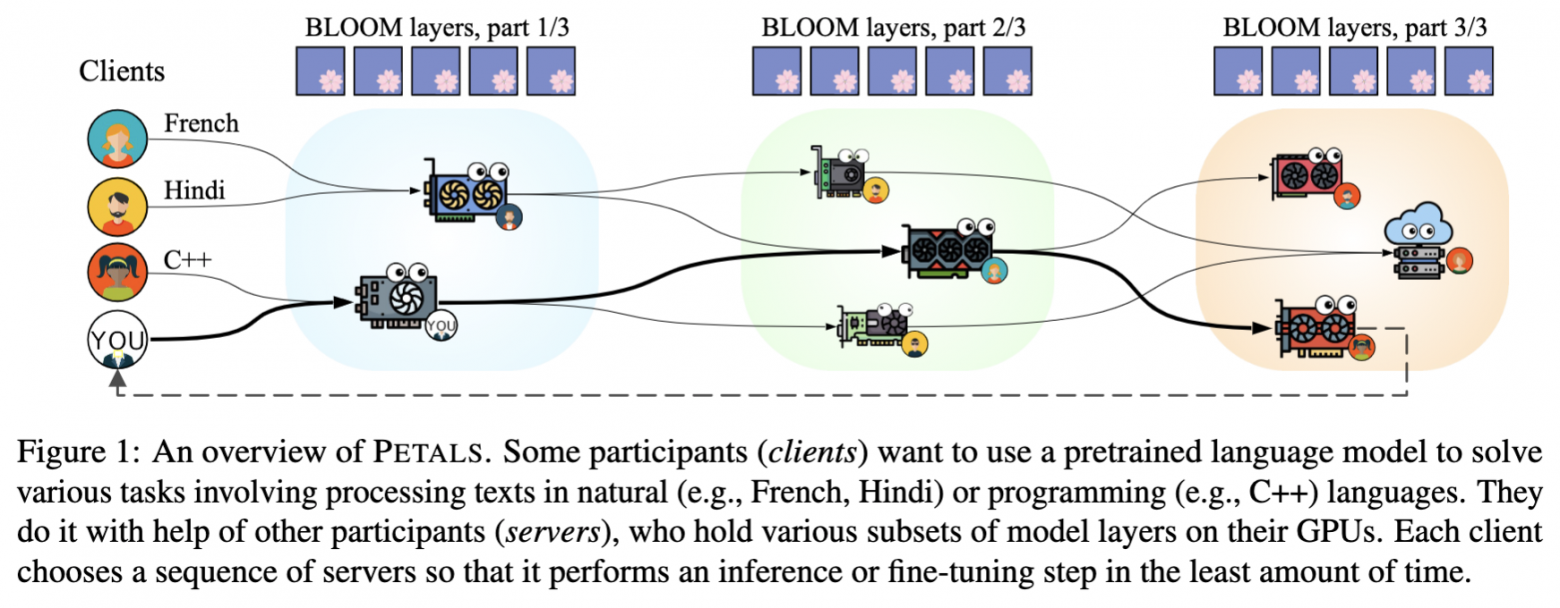
В целом вы можете смешивать и сопоставлять распределенные слои, как в обычном PyTorch, и даже вставлять и обучать собственные слои (например, адаптеры) между предварительно обученными слоями.
Читайте подробности в нашей статье
Шаг 4. Добавление обучаемого адаптера
Хотя удаленно размещенные блоки трансформаторов заморожены, для сохранения предварительно обученной модели одинаковой для всех пользователей, чтобы BLOOM решал разнообразные последующие задачи, обычно достаточно параметрически эффективных адаптеров (малых обучаемых слоев между предварительно обученными блоками модели, например, LoRA) или обучаемых входов, добавляемых перед входами модели, например, в P-Tuning v2.
Ниже пример добавления простого обучаемого линейного слоя между 5-м и 6-м трансформаторными блоками предварительно обученной модели. Веса слоя и соответствующая статистика оптимизатора будут храниться локально:
import torch.nn as nn import torch.nn.functional as F class BloomBasedClassifier(nn.Module): def __init__(self, model): super().__init__() self.distributed_layers = model.transformer.h self.adapter = nn.Sequential(nn.Linear(14336, 32), nn.Linear(32, 14336)) self.head = nn.Sequential(nn.LayerNorm(14336), nn.Linear(14336, 2)) def forward(self, embeddings): hidden_states = self.distributed_layers[0:6](embeddings) hidden_states = self.adapter(hidden_states) hidden_states = self.distributed_layers[6:10](hidden_states) pooled_states = torch.mean(hidden_states, dim=1) return self.head(pooled_states) classifier = BloomBasedClassifier(model).cuda() opt = torch.optim.Adam(classifier.parameters(), 3e-5) inputs = torch.randn(3, 2, 14336, device='cuda') labels = torch.tensor([1, 0, 1], device='cuda') for i in range(5): loss = F.cross_entropy(classifier(inputs), labels) print(f"loss[{i}] = {loss.item():.3f}") opt.zero_grad() loss.backward() opt.step() print('predicted:', classifier(inputs).argmax(-1)) # l, o, l
Шаг 5. Пользовательские методы выборки
Интерфейс __model.inference_session()__ в Petals позволяет писать пользовательский код выводов. Вы можете использовать это для реализации любых необходимых алгоритмов выборки, или написать алгоритм лучевого поиска, запрещающий ругательства.
Ниже рассмотрим, как можно повторно реализовать стандартный интерфейс model.generate() с прямыми проходами по всем слоям вручную:
text = "What is a good chatbot? Answer:" token_ids = tokenizer(text, return_tensors="pt")["input_ids"].cuda() max_length = 100 with torch.inference_mode(): with model.inference_session(max_length=max_length) as sess: while len(text) < max_length: embs = model.transformer.word_embeddings(token_ids) embs = model.transformer.word_embeddings_layernorm(embs) h = sess.step(embs) h_last = model.transformer.ln_f(h[:, -1]) logits = model.lm_head(h_last) next_token = logits.argmax(dim=-1) text += tokenizer.decode(next_token) token_ids = next_token.reshape(1, 1) print(text)
What is a good chatbot? Answer: A What is a good chatbot? Answer: A chat What is a good chatbot? Answer: A chatbot What is a good chatbot? Answer: A chatbot that What is a good chatbot? Answer: A chatbot that is What is a good chatbot? Answer: A chatbot that is able What is a good chatbot? Answer: A chatbot that is able to What is a good chatbot? Answer: A chatbot that is able to answer What is a good chatbot? Answer: A chatbot that is able to answer the What is a good chatbot? Answer: A chatbot that is able to answer the most What is a good chatbot? Answer: A chatbot that is able to answer the most common What is a good chatbot? Answer: A chatbot that is able to answer the most common questions What is a good chatbot? Answer: A chatbot that is able to answer the most common questions of What is a good chatbot? Answer: A chatbot that is able to answer the most common questions of your What is a good chatbot? Answer: A chatbot that is able to answer the most common questions of your customers
Шаг 6. Делиться — значит заботиться
Мы разработали Petals как систему, управляемую сообществом, поэтому полагаемся на то, что люди будут предоставлять свои графические процессоры для увеличения мощности роя. Если у вас есть GPU, которые не всегда заняты, пожалуйста, подумайте о запуске сервера Petals.
Остановите его в любое время, если хотите использовать GPU для чего-то другого. Те, кто работает на сервере, бонусом получают определенное ускорение при использовании Petals, ведь локально размещается часть модели больше.
А если у вас GPU-машина со статическим публичным IP, запустить сервер можно в среде Anaconda:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia pip install -U petals python -m petals.cli.run_server bigscience/bloom-petals
Или через наш образ Docker с поддержкой GPU:
sudo docker run --net host --ipc host --gpus all --volume petals-cache:/cache --rm \ learningathome/petals:main python -m petals.cli.run_server bigscience/bloom-petals
Это не позволит другим людям запускать пользовательский код на вашем компьютере. Больше о безопасности — здесь.
Если ваш компьютер находится за NAT или брандмауэром, установка общедоступного сервера может оказаться сложнее, но она возможна. Пожалуйста, опишите ваши настройки в канале #running-a-server нашего Discord, мы вам поможем.
Шаг 7. Другие методы тонкой и быстрой настройки
Хотя вы можете написать адаптеры, Petals реализует несколько стандартных методов эффективной тонкой настройки параметров. В нашем репозитории на GitHub мы приводим примеры посложнее:
- Обучение персонифицированного чат-бота: блокнот
- Тонкая настройка BLOOM для семантической классификации текста: блокнот
Что еще?
Теперь вы знакомы с тем, как использовать Petals для разных задач, как он работает внутри и как увеличить его мощность.
Вот несколько полезных ресурсов:
- Подробнее о Petals. Файл README в нашем репозитории GitHub содержит ссылки на дополнительные материалы, связанные с Petals, включая инструкции по запуску собственного роя (возможно, с моделью кроме BLOOM).
- Сервер Discord. Если у вас есть отзывы, вопросы или технические проблемы, присоединяйтесь к серверу Discord и сообщите нам об этом. Если вы хотите создать что-то на основе Petals, будем рады услышать, что вы задумали.
- Научная статья. Мы выпустили статью, в которой подробно рассказывается о нашем исследовании и о том, что происходит в Petals под капотом.
А еще больше практики и полезная теория — на наших курсах:

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также

