В этой статье рассказывается, как писать синтаксические анализаторы с помощью
этой небольшой библиотеки на с++.
Обычно, текст на машинном языке состоит из предложений, те — из подпредложений, а те, в свою очередь, из подподпредложений, и так вплоть до символов.
Например, элемент xml состоит из открывающего тега, содержимого и закрывающего тега. —> Открывающий тег состоит из '<', имени тега, возможно пустого списка атрибутов и '>'. —> Закрывающий тег состоит из '</', имени тега и '>'. —> Атрибут состоит из имени, знаков '=', '"', строки символов и снова '"'. —> Содержимое в свою очередь тоже может содержать элементы. —> И т.д. Таким образом, после разбора получается синтаксическое дерево.
Такие языки удобно описывать формой Бэкуса-Наура (БНФ), где каждый нетерминал соответствует некоторому предложению языка. Когда мы пишем программы, мы обычно разбиваем их на функции и подфункции, и раз мы собрались писать синтаксический анализатор,
пусть каждому нетерминалу БНФ соответствует одна функция нашего анализатора, и пусть каждая такая функция:
- пытается разобрать это предложение с заданной позиции
- возвращает, удалось ли ей это сделать
- возвращает позицию, где закончился разбор или произошла ошибка
- а также, возможно, возвращает некоторые дополнительные данные, которые мы хотим получить в результате разбора
Например для БНФ вида
expr ::= expr1 expr2 expr3 будем писать такую функцию:





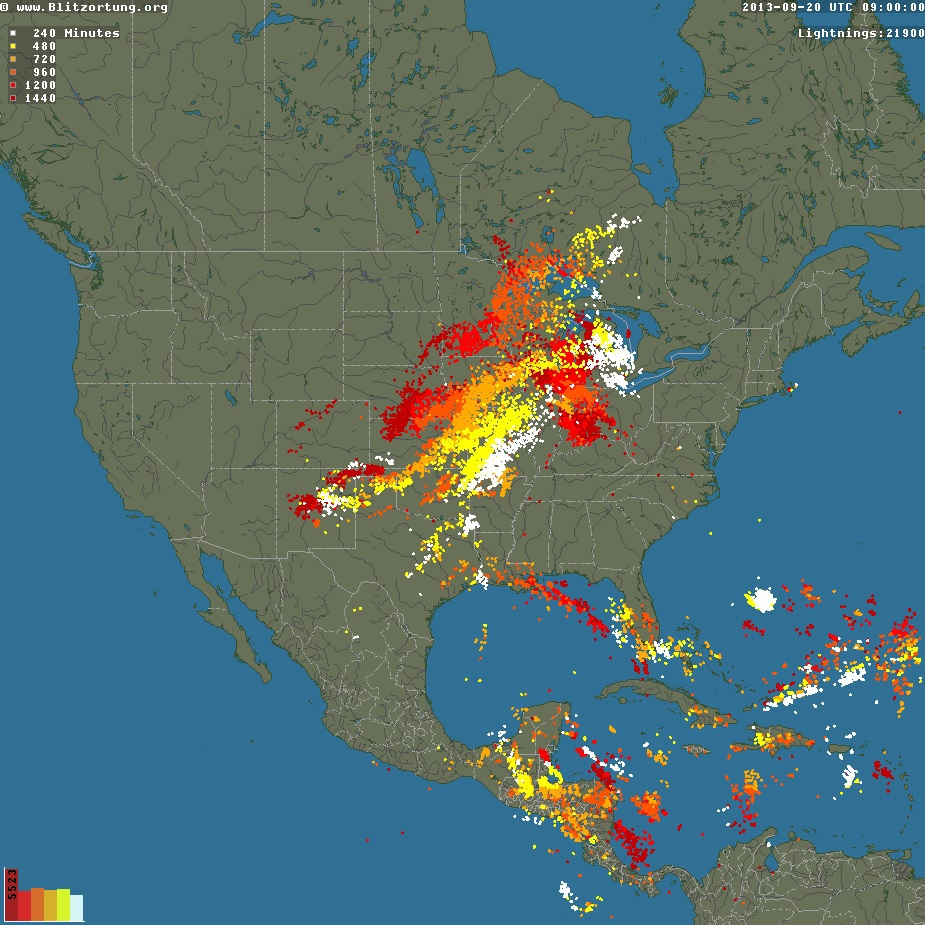
 Да, зима — не лучшее время для статьи о молниях. Но время близится! Сезон дождей и гроз всего через каких-то 4-5 месяцев, а работы – хоть отбавляй.
Да, зима — не лучшее время для статьи о молниях. Но время близится! Сезон дождей и гроз всего через каких-то 4-5 месяцев, а работы – хоть отбавляй.