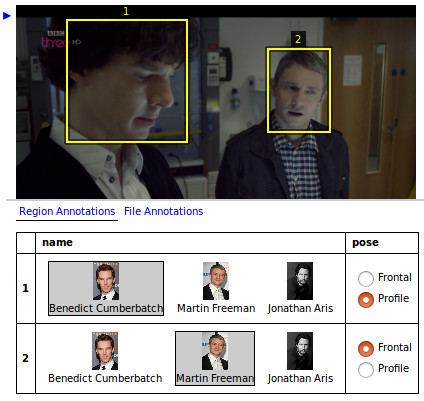
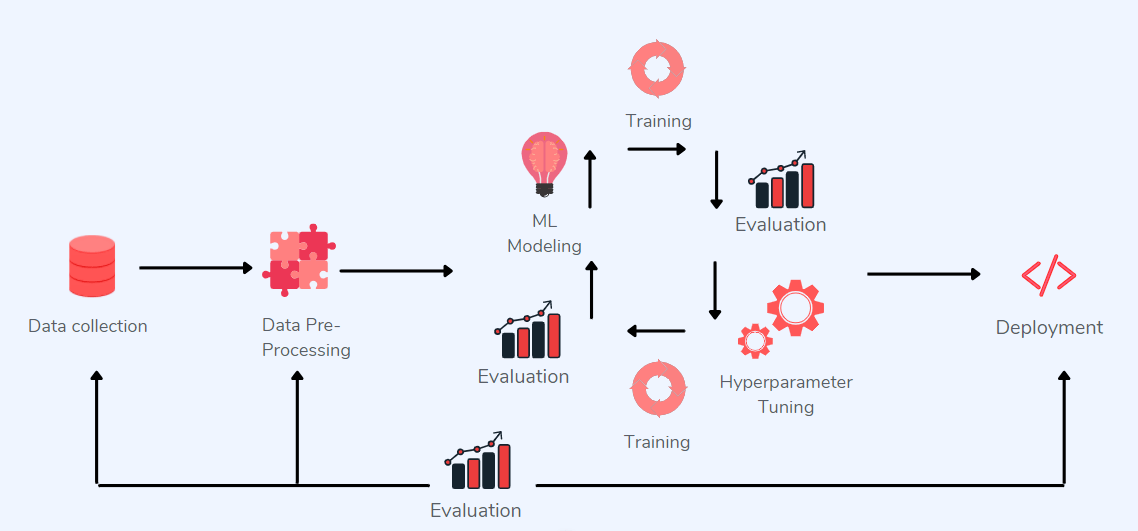
На саммите iMerit ML Data Ops глава отдела искусственного интеллекта Cruise
Хуссейн Мехенна провёл с
Рагаваном Сринивасаном из Facebook AI беседу, озаглавленную
Emerging AI Companies are Driving a Paradigm Shift.
В беседе они обсудили важность объединения цикла обработки данных ИИ с циклом обработки данных людьми, а также поговорили о том, что люди играют критическую роль в выявлении и разрешении пограничных случаев. Сочетание лучших практик
human-in-the-loop, бесперебойного сотрудничества в цикле обработки данных и образ мышления, ставящий на первое место безопасность, в конечном итоге позволят достичь высочайшей степени успеха в сфере ИИ и ML.
Успех таких ИИ-продуктов, как беспилотные автомобили, зависит от усложнения цикла обработки данных, на которых они построены. Надёжные циклы работы с данными одновременно генерируют, аннотируют и непрерывно применяют новые данные в продакшене. Однако для улучшения циклов работы с данными, например, в компании Cruise, интегрируется участие человека.
Благодаря участию человека в циклах обработки данных гарантируется безопасное и эффективное выполнение высокоуровневых действий в ИИ-системах. Humans-in-the-loop непрерывно оценивают характеристики автомобиля, и обеспечивают выполнение всех связанных с автомобилем действий так, как это делал бы человек.