VM или Docker?
5 мин
Как понять, что вам нужен Docker, а не VM? Давайте попытаемся разобраться в основных отличиях изоляции виртуальных машин (VM) и Docker-контейнеров, могут ли они быть взаимозаменяемы и как мы можем их использовать.

Пользователь
Как понять, что вам нужен Docker, а не VM? Давайте попытаемся разобраться в основных отличиях изоляции виртуальных машин (VM) и Docker-контейнеров, могут ли они быть взаимозаменяемы и как мы можем их использовать.

Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.
 Пару недель назад разработчики Google Chromium опубликовали новость о поддержке технологии WebSocket. В айтишном буржунете новость произвела эффект разорвавшейся бомбы. В тот же день различные очень известные айтишники опробовали новинку и оставили восторженные отзывы в своих блогах. Моментально разработчики самых разных серверов/библиотек/фреймворков (в их числе Apache, EventMachine, Twisted, MochiWeb и т.д.) объявили о том, что поддержка ВебСокетов будет реализована в их продуктах в ближайшее время.
Пару недель назад разработчики Google Chromium опубликовали новость о поддержке технологии WebSocket. В айтишном буржунете новость произвела эффект разорвавшейся бомбы. В тот же день различные очень известные айтишники опробовали новинку и оставили восторженные отзывы в своих блогах. Моментально разработчики самых разных серверов/библиотек/фреймворков (в их числе Apache, EventMachine, Twisted, MochiWeb и т.д.) объявили о том, что поддержка ВебСокетов будет реализована в их продуктах в ближайшее время.

Вы решили заняться разработкой мобильных игр. С чего начать? Большинство программистов в геймдеве не ходили в учебные заведения, специализирующие только на играх. Скорее, это был какой-нибудь аналог GeekUniversity с видеоуроками или самостоятельный путь, начавшийся с огромного количества любимых игр, разбора механики, курсов в целом по мобильной разработке, оттачивания найденных алгоритмов в простых игрушках, создаваемых для первого портфолио.
Вне зависимости от выбранного пути, рано или поздно появится необходимость подключить еще один источник знаний, и тут вы можете задуматься о книгах. Учитывайте, что ни одна книга по мобильной разработке не заменит практику. В больших статьях по геймдеву вы слово «книга» можете вообще не встретить. Однако книги имеют определенное преимущество по сравнению со статьями — легко отсортировать их по рейтингу и выбрать лучшие.
Итак, книги не заменят вам реальные боевые курсы, но они могут стать хорошим подспорьем и дополнительным источником знаний. Из книг выбираем лучшие, а далее сортируем по вашему языку и области применения.
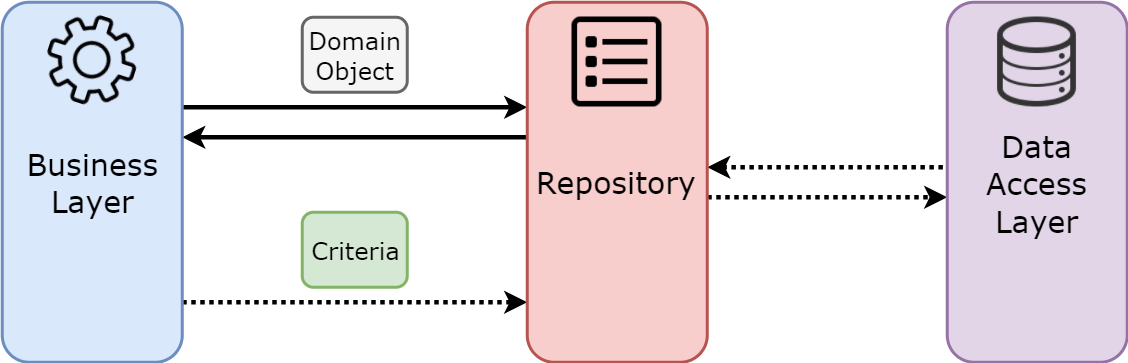
Репозиторий является посредником между слоем доступа к данным и доменным слоем,
работая как in-memory коллекция доменных обектов. Клиенты создают декларативные
описания запросов и передают их в репозиторий для выполнения.
— свободный перевод Мартина Фаулера
EntityFraemwork предоставляет нам готовую реализацию паттернов Repository: DbSet<T> и UnitOfWork: DbContext. Но мне часто приходится видеть, как коллеги используют в своих проектах собственную реализацию репозиториев поверх существующих в EntityFraemwork.
Чаще всего используется один из двух подходов:
И каждый из этих подходов содержит недостатки.
Это перевод статьи автора Samuel Debruyn. Статья понравилась настолько, что появилось спонтанное желание поделится с хабра сообществом :)
Xamarin удивителен тем, что позволяет .NET разработчикам писать приложения для Android, iOS, macOS на… С#. Но эта удивительная возможность имеет свою цену и даже простейшее приложение может запросто потреблять неприлично много памяти. Давайте посмотрим как это происходит и что мы можем сделать с этим. Большинство моих примеров основываются на Xamarin.Android, но вы быстро заметите, что это также применимо и к Xamarin.iOS.
На самом деле в Xamarin приложениях используется несколько типов объектов. Каждое Xamarin приложение имеет объекты, которые живут в двух отдельных мирах:
System.ObjectNSObject (iOS) или Java.Lang.Object (Android)Из этого также следует что существуют и работают 2 сборщика мусора:




Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.

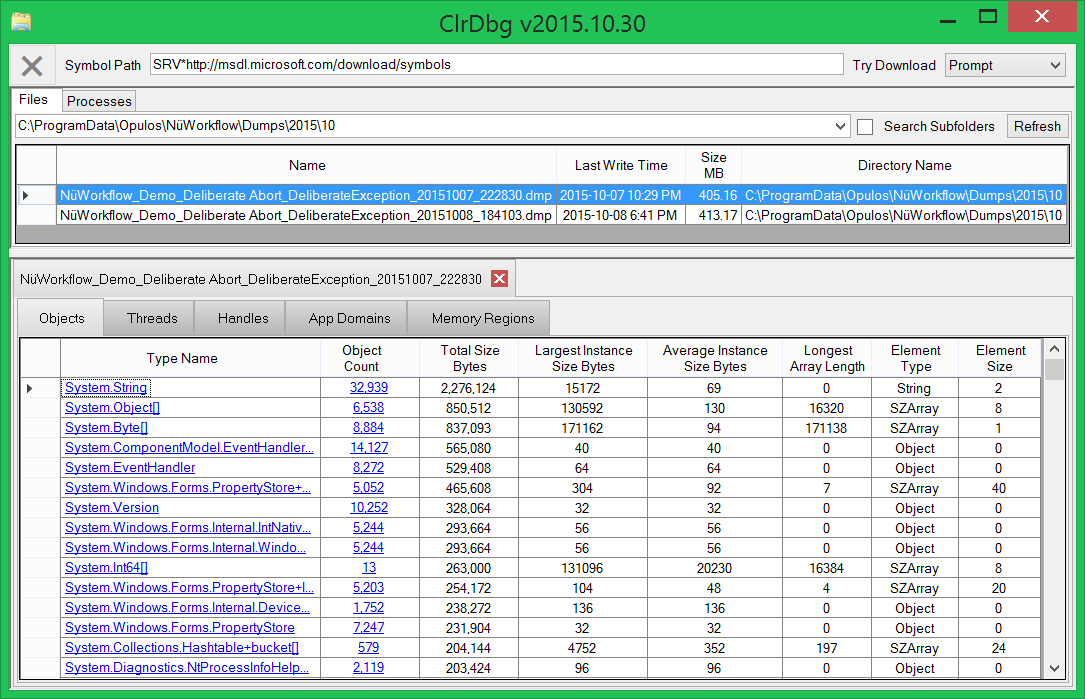
 Не всегда разрабатываемое решение работает с приемлемой производительностью. Особенно для заказчика. И если предложение докупить памяти и поднять системные требования не срабатывает (у меня ни разу не получалось), приходится браться за оптимизацию. И для этого у нас есть не только StopWatch: об инструментах, которые позволяют понять, где искать, куда лезть в первую очередь, каких результатов ждать, работая над перфомансом приложения, поговорили с прекрасной девушкой, отличным специалистом и докладчиком конференции DotNext 2016 Moscow — Диной Гольдштейн.
Не всегда разрабатываемое решение работает с приемлемой производительностью. Особенно для заказчика. И если предложение докупить памяти и поднять системные требования не срабатывает (у меня ни разу не получалось), приходится браться за оптимизацию. И для этого у нас есть не только StopWatch: об инструментах, которые позволяют понять, где искать, куда лезть в первую очередь, каких результатов ждать, работая над перфомансом приложения, поговорили с прекрасной девушкой, отличным специалистом и докладчиком конференции DotNext 2016 Moscow — Диной Гольдштейн.