Учимся разворачивать микросервисы. Часть 1. Spring Boot и Docker

Привет, Хабр.
В этой статье я хочу рассказать о своем опыте создания учебной среды для экспериментов с микросервисами. При изучении каждого нового инструмента мне всегда хотелось его попробовать не только на локальной машине, но и в более реалистичных условиях. Поэтому я решил создать упрощенное микросервисное приложение, которое впоследствии можно будет "обвешивать" всякими интересными технологиями. Основное требование к проекту — его максимальная функциональная приближенность к реальной системе.
Изначально я разбил создание проекта на несколько шагов:
Создать два сервиса — 'бекенд' (backend) и 'шлюз' (gateway), упаковать их в docker-образы и настроить их совместную работу
Ключевые слова: Java 11, Spring Boot, Docker, image optimization
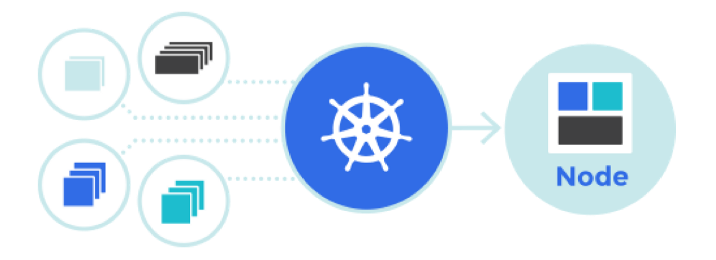
Разработка Kubernetes конфигурации и деплой системы в Google Kubernetes Engine
Ключевые слова: Kubernetes, GKE, resource management, autoscaling, secrets
Создание чарта с помощью Helm 3 для более эффективного управления кластером
Ключевые слова: Helm 3, chart deployment
Настройка Jenkins и пайплайна для автоматической доставки кода в кластер
Ключевые слова: Jenkins configuration, plugins, separate configs repository
Каждому шагу я планирую посвятить отдельную статью.
Направленность этого цикла статей заключается не в том, как написать микросервисы, а как заставить их работать в единой системе.