
sysprg@sysprg
Пользователь

JPEG сжатие картинки с альфа-каналом или SVG masks
5 мин
 Привет, Хабр! Недавняя статья про сжатие в png-8 с сохранение полупрозрачности, напомнила мне об одной технике, которая позволяет применять на сайтах изображения с альфа-каналом, при этом используя алгоритм сжатия с потерями — JPEG, что позволяет существенно сократить их объём.
Привет, Хабр! Недавняя статья про сжатие в png-8 с сохранение полупрозрачности, напомнила мне об одной технике, которая позволяет применять на сайтах изображения с альфа-каналом, при этом используя алгоритм сжатия с потерями — JPEG, что позволяет существенно сократить их объём.Sypex Geo — быстрое определение города по IP
3 мин
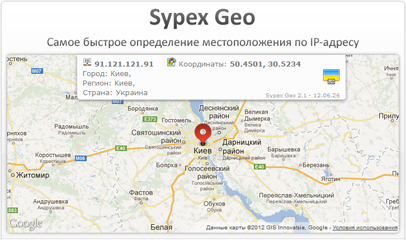 В начале года я публиковал статью Определение страны по IP: тестируем скорость алгоритмов, в которой упоминался мой «велосипед» отличающийся высокой скоростью работы. Одним из популярных вопросов стала возможность определения города по IP.
В начале года я публиковал статью Определение страны по IP: тестируем скорость алгоритмов, в которой упоминался мой «велосипед» отличающийся высокой скоростью работы. Одним из популярных вопросов стала возможность определения города по IP.И вот несколько месяцев спустя, проект начинавшийся, как «for fun» перерос в самостоятельный проект.
Открыт отдельный сайт посвященный проекту Sypex Geo, на котором можно скачать свежие версии API и баз данных, а также ознакомиться с документацией.
Для желающих скорее протестировать правильность определения города по IP — вот ссылка на демо-страницу. А под хабракатом, я опишу некоторые технические подробности и приведу результаты небольшого тестирования.
Реализация алгоритма k-means на c# (с обобщенной метрикой)
6 мин
Всем привет. Продолжая тему того, что Andrew Ng не успел рассказать в курсе по машинному обучению, приведу пример своей реализации алгоритма k-средних. У меня стояла задача реализовать алгоритм кластеризации, но мне необходимо было учитывать степень корреляции между величинами. Я решил использовать в качестве метрики расстояние Махаланобиса, замечу, что размер данных для кластеризации не так велик, и не было необходимости делать кэширование кластеров на диск. За реализацией прошу под кат.
Как сделать программу нетерпеливой?
1 мин

Программы, которые были написаны в прошлых лекциях курса «Сетевое программирование в UNIX», обладали бесконечным запасом терпения, то есть беспрекословно ждали, пока не поступят данные для обработки. В новой лекции вы узнаете, как ограничить терпение программы определенными временными рамками.
Десяток ресурсов, которые помогают быть дизайнером
2 мин
Работать дизайнером очень интересно. Это творческая работа. И как любому творческому человеку, дизайнеру нужна муза или вдохновение.
Я уверен, что у каждого дизайнера есть набор сайтов, на которые они периодически заходят для того что бы черпать это самое вдохновение. У меня так же есть такой список. И я хочу им с вами поделиться.
Естественно, если вы расскажите о своих ресурсах, я буду благодарен.
Хочу сразу предупредить, что практически все ресурсы, собранные мной — англоязычные. Только лишь один на русском. Так же я не очень приветствую узкопрофильные ресурсы (речь о ресурсах, на которых можно скачать только кисти для photoshop и прочее).
Я уверен, что у каждого дизайнера есть набор сайтов, на которые они периодически заходят для того что бы черпать это самое вдохновение. У меня так же есть такой список. И я хочу им с вами поделиться.
Естественно, если вы расскажите о своих ресурсах, я буду благодарен.
Хочу сразу предупредить, что практически все ресурсы, собранные мной — англоязычные. Только лишь один на русском. Так же я не очень приветствую узкопрофильные ресурсы (речь о ресурсах, на которых можно скачать только кисти для photoshop и прочее).
Ресурсы, которые помогают дизайнерам. Часть 2
2 мин
Привет, наверное многие читали мой пост Десяток ресурсов, которые помогают быть дизайнером. Как я понял эта тема интересная (147 плюсов как никак). А раз так, я решил не останавливаться на достигнутом и вот наконец-то закончил работу над своеобразным продолжением первой части. Надеюсь получилось не хуже. Итак, кому интересно, что получилось, прошу под кат.
Мобильные устройства, position: fixed; и во что это выливается
3 мин

По ходу редизайна блога появилось желание создать 'Scroll to Top' функцию не только для десктопа, но и для мобильных устройств. В связи с небольшим свободным пространством на экране смартфона было решено сделать кнопку возвращения на верх в виде полоски высотой в 20px прикрепленную к нижней границе экрана.
Кризис идентичности пикселя
5 мин
Перевод

Пиксель всегда был наименьшей единицей в цифровом дизайне. Это невидимая величина измерения для дизайнеров. Фраза «пиксель пиксель пиксель» была принята в помощь принт-дизайнерам, чтобы те могли понимать концепт фиксированной плотности экрана. Веб-дизайнеры в свою очередь приняли пиксели взамен точкам.
Сравнение блейд-серверных платформ HP, IBM, Cisco и Hitachi, часть вторая: сетевая инфраструктура, управление, особенности серверов, сервис и доля рынка
7 мин

Вторая часть поста получилась более описательной, без лобовых столкновений и таблиц. Воедино сведены данные по сетевой инфраструктуре блейд-платформ, возможностям и особенностям управления, любопытным особенностям конкретных моделей, сервисным возможностям и долям рынка каждого из представленных производителей.
132 сервера в стойке или как уплотниться и не лопнуть
5 мин

Два года назад я впервые рассказал в блоге о серверах DELL, которые мы используем в своей работе. Пришла пора рассказать о новом оборудовании, за это время многое изменилось. Пост долго не хотел писаться, фотографии успели запылиться, но лучше поздно, чем никогда.
В этом посте я расскажу о новых серверах DELL PowerEdge серии C (С – от Cloud), а также о том, как благодаря новому оборудованию мы удвоили емкость нашей площадки в ДЦ и при этом сохранили затраты на эксплуатацию на прежнем уровне.
Алгоритм моделирования многомерного массива данных, распределенных по нормальному закону
4 мин
При разработке или исследовании готовых алгоритмов часто требуется определить качество их работы. Использовать для этой цели данные из реальных источников не всегда возможно, так как их свойства зачастую неизвестны и потому нельзя спрогнозировать результат выполнения исследуемых алгоритмов. В таком случае применяется моделирование данных по одному из хорошо известных законов распределения. Применяя исследуемый алгоритм к модельным данным, можно заранее предположить, каким окажется результат его выполнения. Если он окажется удовлетворительным, можно попробовать применить его и к реальным данным. Естественно, что это относится только к непараметрическим алгоритмам, то есть не зависящим от закона распределения данных.
Чаще всего используется моделирование данных, распределённых по нормальному закону. К сожалению, MS Excel и распространённые статистические пакетаы (SPSS, Statistica) позволяют моделировать только одномерные статистические распределения. Конечно, можно составить многомерное распределение из нескольких одномерных, но только в том случае, если переменные независимы. Если же нужно исследовать данные с зависящими друг от друга переменными, придётся писать программу.
Чаще всего используется моделирование данных, распределённых по нормальному закону. К сожалению, MS Excel и распространённые статистические пакетаы (SPSS, Statistica) позволяют моделировать только одномерные статистические распределения. Конечно, можно составить многомерное распределение из нескольких одномерных, но только в том случае, если переменные независимы. Если же нужно исследовать данные с зависящими друг от друга переменными, придётся писать программу.
Алгоритм параллельного поиска максимальных, общих подстрок в двух строках, и его имплементация на C++ (C++11)
4 мин
Решил написать статью про алгоритм параллельного поиска максимально возможных пересечений двух строк. К написанию этой статьи меня побудило два желания:
- Поделиться со всеми интересным алгоритмом и его реализацией на С++ (стандарт С++11);
- Узнать, есть ли у данного алгоритма название и/или формальное описание;
Визуализация данных
1 мин
Привет!
Ребята с ресурса Data Visualization собрали несколько очень интересных решений для представления данных:
Datavisualization.ch Selected Tools
Решения представляют собой диаграммы, карты и графики. Идеи реализованы как на стандартных, так и на неизвестных библиотеках. Иногда используются простые технологии, а результат получается очень впечатляющим.
Datavisualization.ch является одним из ведущих ресурсов в интернете, рассказывающих о визуализации данных и инфографике. На сайте обсуждаются и исследуются интересные и инновационные идеи в этих областях.
Ребята с ресурса Data Visualization собрали несколько очень интересных решений для представления данных:
Datavisualization.ch Selected Tools
Решения представляют собой диаграммы, карты и графики. Идеи реализованы как на стандартных, так и на неизвестных библиотеках. Иногда используются простые технологии, а результат получается очень впечатляющим.
Datavisualization.ch является одним из ведущих ресурсов в интернете, рассказывающих о визуализации данных и инфографике. На сайте обсуждаются и исследуются интересные и инновационные идеи в этих областях.
Кроссбраузерное отражение элементов на CSS3
3 мин

На сегодняшний день уже существуют box-reflect и mask-image, которые позволяют создавать отражение элементов, но данные свойства доступны только в Safari и Chrome, да и работают не так как хотелось бы. Поэтому я хочу рассказать Вам как реализовать кроссбраузерное отражение на CSS.
Локализация точки в выпуклом многоугольнике
4 мин
Туториал
 Листая страницы хаба «Алгоритмы», наткнулся на топик, посвященный решению задачи локализации точки в многоугольнике: задан многоугольник (замкнутая ломаная линия без самопересечений), требуется определить — находится ли заданная точка A внутри этого многоугольника или нет. В одном из последних комментариев к топику было высказано недоумение, какое отношение такая чисто математическая задача имеет к теории алгоритмов. Имеет-имеет, причем самое непосредственное. Задача локализации является классической задачей вычислительной геометрии (не путать с компьютерной графикой). В качестве разминки предлагается взглянуть на картинку справа, на которой изображен многоугольник типа кривой Пеано (источник [1]), и попытаться ответить на вопрос — красная точка
Листая страницы хаба «Алгоритмы», наткнулся на топик, посвященный решению задачи локализации точки в многоугольнике: задан многоугольник (замкнутая ломаная линия без самопересечений), требуется определить — находится ли заданная точка A внутри этого многоугольника или нет. В одном из последних комментариев к топику было высказано недоумение, какое отношение такая чисто математическая задача имеет к теории алгоритмов. Имеет-имеет, причем самое непосредственное. Задача локализации является классической задачей вычислительной геометрии (не путать с компьютерной графикой). В качестве разминки предлагается взглянуть на картинку справа, на которой изображен многоугольник типа кривой Пеано (источник [1]), и попытаться ответить на вопрос — красная точка Архитектура Pinterest – 18 миллионов посетителей, 10-кратный прирост, 12 сотрудников, 410 ТБ данных
2 мин
Перевод
 История Pinterest очень похожа на Instagram. Феноменальный рост, огромное количество пользователей и хранимых данных, при этом поразительно мало сотрудников. А еще все в облаке.
История Pinterest очень похожа на Instagram. Феноменальный рост, огромное количество пользователей и хранимых данных, при этом поразительно мало сотрудников. А еще все в облаке.Действительно, ни Pinterest ни Instagram не сделали больших научных или технологических открытий, но это скорее является следствием простоты использования облачных технологий, нежели признаком заката эры инноваций в Кремниевой Долине (Золотой век Кремниевой долины окончен, и мы танцуем на её могиле – прим. переводчика). Цифры в заголовке и оценки стоимости этих компании настолько велики, что нам кажется, будто бы за ними стоит некий вид технологической революции, обеспечивающей их бурный рост. Однако, эта революция гораздо более искусна – она показывает, насколько легко добиться столь быстрого роста, если вы способны реализовать хорошую идею. Привыкайте. Теперь это норма.
SASS против LESS
6 мин
Перевод
«Какой препроцессорный язык стоит использовать для CSS?» является очень актуальным вопросом в последнее время. Несколько раз меня спрашивали об этом лично, и казалось бы, каждые пару дней этот вопрос поднимался в сети. Очень приятно что беседа перешла из темы о плюсах и минусах препроцессинга к обсуждению какой же язык является лучшим. За дело!
Если быть кратким: SASS.
Немного развернутый ответ: SASS лучше по всем пунктам, но если вы уже счастливы с LESS — это круто, по крайней мере вы уже упростили себе жизнь используя препроцессинг.
Развернутый ответ: ниже
Если быть кратким: SASS.
Немного развернутый ответ: SASS лучше по всем пунктам, но если вы уже счастливы с LESS — это круто, по крайней мере вы уже упростили себе жизнь используя препроцессинг.
Развернутый ответ: ниже
Команда Microsoft Research побила мировой рекорд по сортировке
2 мин
 На сайте sortbenchmark.org ежегодно проводятся конкурсы по сортировке больших наборов данных. Один из видов соревнований — minute sort, в котором необходимо за минуту прочитать с диска и сортировать как можно большее число записей и сохранить результат в файл. Конкурс проходит в двух категориях — Indy, без ограничений на используемое железо, и Daytona — должны использоваться только обычные компьютеры “из магазина”.
На сайте sortbenchmark.org ежегодно проводятся конкурсы по сортировке больших наборов данных. Один из видов соревнований — minute sort, в котором необходимо за минуту прочитать с диска и сортировать как можно большее число записей и сохранить результат в файл. Конкурс проходит в двух категориях — Indy, без ограничений на используемое железо, и Daytona — должны использоваться только обычные компьютеры “из магазина”.Команде Microsoft Research удалось многократно превысить державшийся с 2009 года рекорд Yahoo в категории Daytona. Их кластер, состоящий из 1033 дисков на 250 машинах, справился с 1401 гигабайтом данных. Это почти втрое лучше результата Yahoo (500 гигабайт), при том, что кластер Yahoo был почти в шесть раз больше (5624 диска на 1406 машинах). Более того, майкрософтовский кластер побил и прошлогодний рекорд в категории Indy (1353 гигабайта).
Как найти девушку за 250 микросекунд
4 мин
В отличие от Европы и Америки в России к сайтам знакомств преобладает осторожное отношение. Однако, надежда нажать на волшебную кнопочку и найти себе любовь не гаснет в сердцах многих. И мы должны эту надежду оправдывать. Конечно, сразу найти идеально подходящую “половинку” мы не обещаем, но предложить десятки, сотни или в отдельных случаях тысячи вариантов, отвечающих именно вашим запросам, просто обязаны. Что и делаем, причем очень быстро.
Средний поиск по базе из 11 миллионов анкет, имеющих от 4 до 30 параметров каждая, занимает у нас в среднем 3.5 милисекунды. И при этом кроме поиска демон-серчер «Мамбы» выполняет следующие, в том числе не вполне традиционные задачи:
Несмотря на то, что наш поиск с самого начала разрабатывался собственными силами, время от времени возникали мысли использовать что-то уже известное, обкатанное и гарантированно эффективное. Ну, а если мы задумываемся о поиске, первым в голову приходит Sphinx.
Средний поиск по базе из 11 миллионов анкет, имеющих от 4 до 30 параметров каждая, занимает у нас в среднем 3.5 милисекунды. И при этом кроме поиска демон-серчер «Мамбы» выполняет следующие, в том числе не вполне традиционные задачи:
- для каждой конкретной анкеты выдает ее место в поиске (каждый пользователь, заходя в свою анкету, видит сообщение «Вы находитесь на N месте в поиске»)
- выдает конкретную анкету из списка по первичному ключу
- производит непосредственный поиск анкеты по заданным параметрам
Несмотря на то, что наш поиск с самого начала разрабатывался собственными силами, время от времени возникали мысли использовать что-то уже известное, обкатанное и гарантированно эффективное. Ну, а если мы задумываемся о поиске, первым в голову приходит Sphinx.