Comments 141
Лично я догадывался, что такими вот обученными моделями компьютерное зрение не получить. Но польза же есть от этих моделей. Это как с нейросетями — вряд ли можно воспроизвести человеческий мозг с их помощью, но это не мешает использовать концепт с пользой. Ну и отрицательный результат — тоже результат, все хорошо (:
Спасибо за материал, интересно.
Спасибо за материал, интересно.
Определенно, я не предлагаю их все щас немедленно запретить и сжечь) Мне просто иногда кажется, что всю эту энергию, которые люди тратят на то, чтобы отхватить еще полпроцента в классифицирующем соревновании, да в правильных целях бы — и может, к человеческому мозгу бы подобрались на пару шагов поближе)
Что-то должно быть по-другому. Наши алгоритмы должны уметь определять пространственное положение объекта, и повернутый набок диван все-таки опознавать как диван
Артём, здравствуйте, я поздновато набрёл на вашу статью. Но лучше поздно. чем никогда.
Я пришёл к тем же выводам про необходимость пересмотра подхода к сильному ИИ.
Правда другими методами. О чём в свою очередь написал заметку.
habr.com/ru/post/438932
Интересует Ваше профессиональное мнение по этому поводу.
Похоже — с пляжом. (верхнюю картинку я корежил в рамках эксперимента)
_______________________________________________________________________________

_______________________________________________________________________________

_______________________________________________________________________________
_______________________________________________________________________________
_______________________________________________________________________________
_______________________________________________________________________________


потрясающая статья! А есть ли алгоритмы, не основанные на разфигачивании картинки на набор признаков?
Номинально — в общем, скорее нет. Vision as feature detection — это такой очень общий подход, связанный с тем, что в наши глаза попадает много всякого ненужного с точки зрения информационной энтропии (куча однородного фона, не менее однородные всякие пятна и т.д.), и при этом мы, как животные в не самой безопасной среде, должны уметь быстро на все это реагировать и замечать важное (еду, хищников). Отсюда естественным образом вытекает идея фич — в поле зрения должны быть какие-то небольшие, но важные куски, и именно их наше зрение будет скорее всего замечать. И, как предполагается, строить распознавание оно потом тоже будет на них.
Другое дело, что сверточные сети пользуются не просто набором признаков — а набором локальных и инвариантных (то есть им все равно, где они находятся) признаков. Вообще традиционно считается, что это очень хорошо — так мы можем успешно бороться со всякими сдвигами картинки по горизонтали и вертикали, которые вообще ее толком не изменяют. Но, к сожалению, последствия бывают и вот такие.
Насчет других алгоритмов:
— та самая статья Хинтона про transforming autoencoders, и было еще его выступление на ютубе на эту тему.
— штука под названием one-shot learning, которую я все хотел включить в пост, но которая не поместилась.
P.S. Вы правда работаете в Blue Brain Project? Потрясающе, напишите пост про то, как оно там?)
Другое дело, что сверточные сети пользуются не просто набором признаков — а набором локальных и инвариантных (то есть им все равно, где они находятся) признаков. Вообще традиционно считается, что это очень хорошо — так мы можем успешно бороться со всякими сдвигами картинки по горизонтали и вертикали, которые вообще ее толком не изменяют. Но, к сожалению, последствия бывают и вот такие.
Насчет других алгоритмов:
— та самая статья Хинтона про transforming autoencoders, и было еще его выступление на ютубе на эту тему.
— штука под названием one-shot learning, которую я все хотел включить в пост, но которая не поместилась.
P.S. Вы правда работаете в Blue Brain Project? Потрясающе, напишите пост про то, как оно там?)
Ну собственно из последнего по transforming autoencoding: arxiv.org/abs/1505.01596
Хоть и построено на нелюбимых Хинтономdisastrous CNN, но результат все равно впечатляет.
Смею предположить, что сеть натренированная таким способом на приличном количестве материала сумела бы отличить диван. Хоть это и чистая спекуляция с моей стороны. =)
Хоть и построено на нелюбимых Хинтоном
Смею предположить, что сеть натренированная таким способом на приличном количестве материала сумела бы отличить диван. Хоть это и чистая спекуляция с моей стороны. =)
Ух ты, здорово. Спасибо, обязательно почитаю.
Кстати да, движение может быть ключом к освоению афинных преобразований (параллельный перенос, повороты, масштабирование). Мозгу без шансов понять, что нейрон А и нейрон Б реагируют на одну и ту же кошку в разных частях поля зрения, если не пронаблюдает плавное перемещение. В этом случае нейроны вдоль пути следования кошки свяжутся по хеббовскому правилу, и дадут начало инвариантной кошке.
А свёрточные сети кроме экономии нейронов дают ещё и чит, позволяющий освоить параллельный перенос на халяву. Не распознают повёрнутое изображение? А не их вина что мы делаем свёртку только по координатам, но не по поворотам картинки.
А свёрточные сети кроме экономии нейронов дают ещё и чит, позволяющий освоить параллельный перенос на халяву. Не распознают повёрнутое изображение? А не их вина что мы делаем свёртку только по координатам, но не по поворотам картинки.
Я поздно подтянулся. Но все-же вставлю свои 5 копеек.
У вас вырисовывается 2 проблемы.
1. CNN работают только с локальными фичами и они не могут отличить «кошку леопардовой расцветки» от «дивана леопардовой расцветки»
Да. CNN работают только с локальными фичами. By design.
Но. Эти локальные фичи можно очень легко превратить в глобальные используя вместе или по отдельности
а) пирамиды
(если на картинке 100x100 будет леопард крупным планом и мы будем идти маской 5x5 — мы не сможем отличить леопарда от дивана, т/к/ мы будем сосредоточены на локальных фичах.) но пирамидируюя эту картинку — вуаля — сможем
б) так называемые superpixels когда мы можем детектить сразу несколько обьектов на сцене(в них я пока еще не разбирался)
Собственно вот как это решает тот же LeCun и компания
2. Для обучения CNN нужно большое количество реальных примеров.
Я бы сказал, это не обязательно так. Как следует из того же one shot learning. Но если классы будут слишком близки, то, к сожалению без реальных примеров их не разделить(допустим вы хотите классифицировать цифру 5 написанную одним человеком в один класс, а другим человеком — в другой класс. И, скормив системе одну единственную цифру 5 и приказав «фантазируй», она не сможет правильно классифицировать цифры. Но это же верно и для людей.
У вас вырисовывается 2 проблемы.
1. CNN работают только с локальными фичами и они не могут отличить «кошку леопардовой расцветки» от «дивана леопардовой расцветки»
Да. CNN работают только с локальными фичами. By design.
Но. Эти локальные фичи можно очень легко превратить в глобальные используя вместе или по отдельности
а) пирамиды
(если на картинке 100x100 будет леопард крупным планом и мы будем идти маской 5x5 — мы не сможем отличить леопарда от дивана, т/к/ мы будем сосредоточены на локальных фичах.) но пирамидируюя эту картинку — вуаля — сможем
б) так называемые superpixels когда мы можем детектить сразу несколько обьектов на сцене(в них я пока еще не разбирался)
Собственно вот как это решает тот же LeCun и компания
2. Для обучения CNN нужно большое количество реальных примеров.
Я бы сказал, это не обязательно так. Как следует из того же one shot learning. Но если классы будут слишком близки, то, к сожалению без реальных примеров их не разделить(допустим вы хотите классифицировать цифру 5 написанную одним человеком в один класс, а другим человеком — в другой класс. И, скормив системе одну единственную цифру 5 и приказав «фантазируй», она не сможет правильно классифицировать цифры. Но это же верно и для людей.
> Вспомните первые классы школы, когда вы учились писать цифры.
> Каждому из учеников тогда приносили по увесистой книге…
> Хм. Говорите, все было совсем не так?
Не совсем так, но близко к этому. Только вместо увесистой книги был видеоряд продолжительностью 40*2*5*4*9/60=240 часов (за год, в 1 классе), в котором эти цифры постоянно мелькали. И это не считая предшествовавшего видеоряда продолжительностью лет в 5 или 7, в котором эти цифры постоянно мелькали в различной обстановке, под различными ракурсами, в различном написании, а рядом почти всегда был эксперт, управлявший распознаванием (бабушка, например).
Конечно, при таком масштабном процессе обучения я буду распознавать леопарда лучше, чем новорождённая сеть, которую 20 минут кормили статическими картинками из Интернетов.
Покажите ваш леопёрдовый диван мальчику из Ботсваны. Ставлю один доллар против одного рубля, что мальчик сбежит в ужасе.
> Каждому из учеников тогда приносили по увесистой книге…
> Хм. Говорите, все было совсем не так?
Не совсем так, но близко к этому. Только вместо увесистой книги был видеоряд продолжительностью 40*2*5*4*9/60=240 часов (за год, в 1 классе), в котором эти цифры постоянно мелькали. И это не считая предшествовавшего видеоряда продолжительностью лет в 5 или 7, в котором эти цифры постоянно мелькали в различной обстановке, под различными ракурсами, в различном написании, а рядом почти всегда был эксперт, управлявший распознаванием (бабушка, например).
Конечно, при таком масштабном процессе обучения я буду распознавать леопарда лучше, чем новорождённая сеть, которую 20 минут кормили статическими картинками из Интернетов.
Покажите ваш леопёрдовый диван мальчику из Ботсваны. Ставлю один доллар против одного рубля, что мальчик сбежит в ужасе.
Напротив — мальчик из Ботсваны прекрасно знает как выглядят леопарды, поэтому не примет за леопарда то, что им не является.
Мальчик из Ботсваны как-то прожил на земле свои семь лет, потому что научился не попадаться в лапы к леопарду. Чтобы не попадаться леопарду, нужно уметь быстро обнаруживать леопарда в подобном пейзаже:

(леопард тут правда есть)
А после обнаружения в поле зрения куска леопардовой шкуры нужно очень быстро бежать (быстрее другого мальчика, по крайней мере), поэтому я и не ставлю на ботсванийца.
(леопард тут правда есть)
А после обнаружения в поле зрения куска леопардовой шкуры нужно очень быстро бежать (быстрее другого мальчика, по крайней мере), поэтому я и не ставлю на ботсванийца.
При таком размере, можно особо не торопиться, думаю у мальчика есть месяцев 8-10, до того момента как барсенок такого размера будет представлять опасность.


М-да, до мальчика из Ботсваны мне далеко. Я, конечно, «котика» нашёл, но поздно, он бы меня уже ел…

Диван было бы заметно сразу!!!
> Чтобы не попадаться леопарду, нужно уметь быстро обнаруживать леопарда в подобном пейзаже
У леопарда (в данном случае снежного барса) специальный маскировочный рисунок шкуры. Плюс кошачьи хорошо умеют подкрадываться: они плавно двигаются когда жертва отвернулась и застывают, когда на них смотрят. Этот эффект можно увидеть тут: www.youtube.com/watch?v=fzzjgBAaWZw
Поэтому жертва засекает кошку только в последний момент по звуку и движению, когда она прыгает. Поэтому кошачьи по всему миру — превосходные охотники.
> после обнаружения в поле зрения куска леопардовой шкуры нужно очень быстро бежать
Если бежать от леопарда, это спровоцирует атаку. Вы способны убежать от леопарда? А если угрожающе пойти в сторону леопарда, это может его обескуражить. Для леопарда будет действовать правило: дают — бери, бьют — беги.
У леопарда (в данном случае снежного барса) специальный маскировочный рисунок шкуры. Плюс кошачьи хорошо умеют подкрадываться: они плавно двигаются когда жертва отвернулась и застывают, когда на них смотрят. Этот эффект можно увидеть тут: www.youtube.com/watch?v=fzzjgBAaWZw
Поэтому жертва засекает кошку только в последний момент по звуку и движению, когда она прыгает. Поэтому кошачьи по всему миру — превосходные охотники.
> после обнаружения в поле зрения куска леопардовой шкуры нужно очень быстро бежать
Если бежать от леопарда, это спровоцирует атаку. Вы способны убежать от леопарда? А если угрожающе пойти в сторону леопарда, это может его обескуражить. Для леопарда будет действовать правило: дают — бери, бьют — беги.
Ну я почему и написал про «бежать быстрее другого мальчика» :-)
Просто мысль об обнаружении леопарда наивна. Он весь насквозь создан так, чтобы жертва его не обнаружила раньше времени. В противном случае он бы помер с голоду.
Для козла эта задача, безусловно, нерешаема. А вот для человека — я не уверен.
Так или иначе, для гипотетического утрированного примера это не очень существенно.
Так или иначе, для гипотетического утрированного примера это не очень существенно.
Задача решаема, если вдумчиво вглядываться в картинку, которая составляет только ограниченный сектор обзора. И то не все находят. А в реальном времени контролировать 360 градусов вокруг себя нереально. Или надо ходить стадом, смотреть в несколько глаз и надеяться, что под леопардом хрустнет ветка или камень упадёт.
Что-то логика наоборот же должна работать, нет? Мальчик из Ботсваны видел леопардов чаще, чем мы, и должен иметь более подробную модель в голове) Это мы с вами как раз, как жители суровой северной страны, должны в ужасе отпрыгивать от экрана.
Зато мальчик из Ботсваны не видел диванов. Окей, диван не будет шевелиться, так что мальчик не будет убегать от мёртвого леопарда. Но как можно опознать диван, если ты его в жизни ни разу не видал?
А так ли вы уверены в своей способности распознавать мебель? Вот вам дизайнерский диван:

Давайте теперь покрасим его в леопарда, и я тогда посмотрю, как вы его будете идентифицировать.
А так ли вы уверены в своей способности распознавать мебель? Вот вам дизайнерский диван:
Давайте теперь покрасим его в леопарда, и я тогда посмотрю, как вы его будете идентифицировать.
Собственно, я не очень понял суть аргумента) Никто же не спорит, что не видев ни разу в жизни чего-то, его сложно опознать. Мой пойнт был вот в чем — такое субъективное ощущение, что нам с вами, похоже, достаточно увидеть это самое что-то всего несколько раз, чтобы включить его в мысленную распознавательную базу знаний. Все-таки не то чтобы вы учились писать рукописные цифры целый год, медленно увеличивая свой скилл с каждым днем и только к концу первого класса достигая более-менее уверенности. Мы, опять-таки, обладаем чертовски быстрыми способостями запомнить какую-то новую, совершенно незнакомую раньше вещь. Вот, например — буду надеяться, что вы не смотрели Вавилон-5 — корабль ворлонов.
А что вот это такое? Это тоже корабль ворлонов.
Немного измененный, с поправкой на графику, с другой стороны, но все-таки ощутимо он. Откуда вы это узнали? Вы же явно не провели последний год, изучая и рассматривая чертежи фантастических космических кораблей (а если все-таки да, то мой аргумент уничтожен).
Скрытый текст
А что вот это такое? Это тоже корабль ворлонов.
Скрытый текст
Немного измененный, с поправкой на графику, с другой стороны, но все-таки ощутимо он. Откуда вы это узнали? Вы же явно не провели последний год, изучая и рассматривая чертежи фантастических космических кораблей (а если все-таки да, то мой аргумент уничтожен).
> нам с вами, похоже, достаточно увидеть
> это самое что-то всего несколько раз
Совершенно верно, но сколько именно раз?
Если честно, я не вижу особого сходства между двумя кораблями ворлонов. Благодаря накопленному за время просмотра запасу обучения я худо-бедно признаю космический корабль на первом снимке (потому что за ним находится глобус в темноте, а я привык, что неопознанная хренотень на фоне глобуса в темноте — это обычно космический корабль), хотя даже при этом штуковина больше напоминает спутник. На втором снимке с тем же успехом может быть подводная лодка или там какая-нибудь доисторическая медуза.
Как вам вот это? Напоминает космический корабль, не правда ли? Даже слегка похож на ворлонов:

Вот только это не он :-)
> Мы, опять-таки, обладаем чертовски быстрыми
> способостями запомнить какую-то новую,
> совершенно незнакомую раньше вещь.
Так вот мой пойнт в том, что мы при этом зачастую ошибаемся. И система распознавания тоже может запоминать что-то достаточно быстро и при этом потом иногда ошибаться (как пресловутый автофокус на айфоне). Но чем больше обучения — тем меньше вероятность ошибки. Только вот 5-10 лет обучения свёрточной сети никто не даст.
> это самое что-то всего несколько раз
Совершенно верно, но сколько именно раз?
Если честно, я не вижу особого сходства между двумя кораблями ворлонов. Благодаря накопленному за время просмотра запасу обучения я худо-бедно признаю космический корабль на первом снимке (потому что за ним находится глобус в темноте, а я привык, что неопознанная хренотень на фоне глобуса в темноте — это обычно космический корабль), хотя даже при этом штуковина больше напоминает спутник. На втором снимке с тем же успехом может быть подводная лодка или там какая-нибудь доисторическая медуза.
Как вам вот это? Напоминает космический корабль, не правда ли? Даже слегка похож на ворлонов:
Вот только это не он :-)
> Мы, опять-таки, обладаем чертовски быстрыми
> способостями запомнить какую-то новую,
> совершенно незнакомую раньше вещь.
Так вот мой пойнт в том, что мы при этом зачастую ошибаемся. И система распознавания тоже может запоминать что-то достаточно быстро и при этом потом иногда ошибаться (как пресловутый автофокус на айфоне). Но чем больше обучения — тем меньше вероятность ошибки. Только вот 5-10 лет обучения свёрточной сети никто не даст.
Тем не менее, у нас имеется огромный запас базового материала в виде «кораблей в космосе» «фона из звезд и планет» и просто «фантастических кораблей» разных видов, чтобы сходу реконструировать вероятную форму предмета используя только одно изображение.
А ещё у нас есть контекст. Человек показывает космический корабль, и собирается показать что-то ещё для сравнения. С какой вероятностью это тоже будет космический корабль? С какой вероятностью это будет космический корабль схожего класса?
Я, например, ждал, что на второй фотке тоже будет корабль ворлонов. А если б ждал медузу — её бы с большой вероятностью и увидел.
Именно поэтому, кстати, с фото в принципе сложнее, чем с видео. Например, кусок леопардового паттерна должен с большей вероятностью классифицироваться как леопард, если перед этим показывали саванну, и как диван — если перед этим показывали стол и стул.
Я, например, ждал, что на второй фотке тоже будет корабль ворлонов. А если б ждал медузу — её бы с большой вероятностью и увидел.
Именно поэтому, кстати, с фото в принципе сложнее, чем с видео. Например, кусок леопардового паттерна должен с большей вероятностью классифицироваться как леопард, если перед этим показывали саванну, и как диван — если перед этим показывали стол и стул.
Я вам больше скажу — новорожденный младенец начнет плакать и уплозать от человека в маске леопарда. Это генетически вшитая программа одного из наиболее страшых врагов приматов. Кушали они наших предков активно. Именно поэтому предупреждающие надписи делают черным шрифтом по желтому фону, так как инстинкт требует немедленно все бросить и рассмотреть подозрительный объект.
Вы, как врач, должны понимать, что новорожденный младенец не умеет ползать.
Так, уважаемый Meklon и написал, что младенец будет не уползать, а уплозать. Что это такое, я, правда, не знаю.
Выручили) Хорошо, согласен. Смысл в негативной реакции на такую окраску. Максимальное внимание и желание убраться в безопасное место, где тебя не будут жрать.
Видимо, уплозание это такое зачаточное уползание, при котором попытки уползти предпринимаются (взмахи руками и ногами) и хорошо заметны, а результат (перемещение тела в пространстве) — не очень… :)
Я как отец двоих детей это подтвердить могу) ну ошибся с формулировкой. Смысл в реакции, несмотря на отсутствие обучения такому образу. Младшему показывал. Начинал плакать и искать маму. Больше решил не повторять.
Так может он бы любой маски испугался. Контрольный эксперимент с маской Дарт Вейдера проводили? :)
Решил не издеваться над ребёнком) свой же) на утробное рычание голодного гуля начинает активно радоваться и махать руками. Я за него переживаю)
Он у вас не седоволосый?)
Нет) но я начинаю что-то подозревать…
Только не повторяй опыт с крысой и железной рельсой с кувалдой.
Ха. Ты еще не видел. как мой старший пересказывает игры. Представляю, как в детском саду воспримут. Угадаешь игру по описанию?
«Денёк — светло. Ночь — темно, зомби бить-убивать»
«Денёк — светло. Ночь — темно, зомби бить-убивать»
This war of mine
Майнкрафт же.
Я помню как лет в 10 дворовому другу, который компьютер то в глаза не видел рассказывал про Half Life.
Я помню как лет в 10 дворовому другу, который компьютер то в глаза не видел рассказывал про Half Life.
Вообще таких игр много, но я ставлю на Alan Wake.
где-то читал, что новорожденные ничего не боятся, кроме неожиданных громких звуков и потери опоры(физической)
Можно пруф? Я понимаю, что есть некоторые простые зашитые рефлексы(например сосательный), но насчет маски леопарда первый раз слышу
Гугл за три секунды подсказал:
nt2.shu.ru:9500/natscien/psihogen/lectures/lecture02/text.asp
Дети любят качели — это наследие брахиации у приматов. Дети боятся темноты — наши предки были дневными животными, ночь для них была полна опасностей. Дети пугаются маски леопарда — два желтых горящих кружка с черными зрачками: это был один из самых опасных хищников.
Страшные образы в мультфильмах, сказках, в играх — это игровое узнавание хищников и других опасностей, проверка врожденных реакций на них. Если эти образы мы им не даем, они их сами придумывают.
Хотите более профильно — 1.5 миллиона ссылок вам в помощь.
nt2.shu.ru:9500/natscien/psihogen/lectures/lecture02/text.asp
Дети любят качели — это наследие брахиации у приматов. Дети боятся темноты — наши предки были дневными животными, ночь для них была полна опасностей. Дети пугаются маски леопарда — два желтых горящих кружка с черными зрачками: это был один из самых опасных хищников.
Страшные образы в мультфильмах, сказках, в играх — это игровое узнавание хищников и других опасностей, проверка врожденных реакций на них. Если эти образы мы им не даем, они их сами придумывают.
Хотите более профильно — 1.5 миллиона ссылок вам в помощь.
Я выше книгу привёл хорошую.
А как ведут себя новорожденные сильно веснушчатых родителей — кричат мама и уползают прочь? )
Хотите, я подсуну диван вам?
Какой формы эта машина?

А вот это вообще что такое, если забыть про надпись сверху картинки?

Конечо, посмотрев на них в движении, вы легко сможете опознать и машину, и корабль. А вот по набору статических картинок — не факт.
Какой формы эта машина?
А вот это вообще что такое, если забыть про надпись сверху картинки?
Конечо, посмотрев на них в движении, вы легко сможете опознать и машину, и корабль. А вот по набору статических картинок — не факт.
именно поэтому и развивается мультимодальное обучение, такие модели как раз и моделируют все сенсоры человека, для них ваша фраза о том что, посмотрев на движение мы сразу поймем что это, тоже актуальна
или вот гляньте на мультимодальную модель объединяющую сверточную и рекуррентную сеть
ИИ
или вот гляньте на мультимодальную модель объединяющую сверточную и рекуррентную сеть
Deep RNN + CNN
>Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика?
Я думал лет с 5-7 все знают, как их отличать по рисунку
Гепард — сплошные пятка
Леопард — О пятна
Ягуар — О пятна с точкой внутри
PS: не считая иных отличий конечно
Я думал лет с 5-7 все знают, как их отличать по рисунку
Гепард — сплошные пятка
Леопард — О пятна
Ягуар — О пятна с точкой внутри
PS: не считая иных отличий конечно
Тут нужно было вставить опрос, конечно)
Вам, видимо, повезло с родителями или воспитателями в детском саду, если они вам это объяснил в 5-7 лет.
Мальчик из Ботсваны?
Я их отличаю по морде и пропорциям тела. И по окружающей картине. Если кто-то возлежит на ветке акации, то наверное это леопард. А если несколько кошек сидят на пригорке и всматриваются вдаль — это наверное гепарды.
Disclaimer: я мало знаю про машинное обучение. Но хочу поделиться мыслями.
Есть такая книжка В. Турчина «Кибернетический подход к эволюции», которая перевернула мое мировоззрение однажды. Там есть глава (это оригинальный сайт, кодировка CP1251) про зрение. В ней утверждается, что понятия типа «пятно», «линия», «край», «общий фон освещения» распознаются еще в сетчатке глаза. В мозг поступают уже вот такие понятия, а не точки по отдельности. На следующем уровне из пятен, линий и краев (и, возможно, сигналов в форме базовых понятий от других органов чувств) формируются новые понятия типа «угроза», «добыча», «движущийся объект», «направление» итд. Потом еще один уровень, еще и еще.
Эти уровни и классификаторы формировались в процессе эволюции, а не в процессе обучения — поэтому у нас врожденные понятия прямых, точек, краев. И я думаю, что либо надо копировать природные классификаторы, либо использовать генетические алгоритмы для их построения. Пока компьютеры не научатся распознавать края и пятна и скармливать их на вход следующим уровням, людей они не опередят.
Есть такая книжка В. Турчина «Кибернетический подход к эволюции», которая перевернула мое мировоззрение однажды. Там есть глава (это оригинальный сайт, кодировка CP1251) про зрение. В ней утверждается, что понятия типа «пятно», «линия», «край», «общий фон освещения» распознаются еще в сетчатке глаза. В мозг поступают уже вот такие понятия, а не точки по отдельности. На следующем уровне из пятен, линий и краев (и, возможно, сигналов в форме базовых понятий от других органов чувств) формируются новые понятия типа «угроза», «добыча», «движущийся объект», «направление» итд. Потом еще один уровень, еще и еще.
Эти уровни и классификаторы формировались в процессе эволюции, а не в процессе обучения — поэтому у нас врожденные понятия прямых, точек, краев. И я думаю, что либо надо копировать природные классификаторы, либо использовать генетические алгоритмы для их построения. Пока компьютеры не научатся распознавать края и пятна и скармливать их на вход следующим уровням, людей они не опередят.
Но работа над краями-то довольно неплохая делалась.
Алгоритмы Кенни и Собеля выдают сравнительно правдоподобную картинку.
Алгоритмы Кенни и Собеля выдают сравнительно правдоподобную картинку.
Это, в общем, прямо-таки foundations of visual neuroscience, да) Проблема-то в том, куда дальше двигаться. Края и линии мы научились довольно неплохо определять — под рукой куча всяких методов, стоит одно OpenCV открыть. Но что делать дальше? Как из этих линий сложить тот самый диван или того самого котика?
Я бы предложил из линий складывать кружочки и замкнутые контуры. А по вложенности замкнутых контуров уже можно определить котика. Ну и слегка по форме. Палка-палка-огуречик — все знают, что это )
С детства не понимал этот стих (и раздражался на него за это :). Если из двух точек и запятой ещё можно сделать рожицу, пусть и кривую, то палка-палка-огуречик — это, например, овальное зеркало на двух ножках или спортивный снаряд «козёл» в профиль (хотя это уже палка-огуречик-палка), но никак не человечек-по-умолчанию.
Ну только не в сетчатке, конечно, а в колонках зрительной коры мозга, то есть, в самых первых слоях. Собственно сама концепция свёрточных сетей именно так и работает. Каждая свёртка это составляет как бы один из типов нейронов расположеных в колонке. То есть если из каждой свёртки взять по нейрону и поместить их в один блок как раз колонка как в мозге и получится.
Но у мозга начиная, если не ошибаюсь, сло я стретьего колонки заканчиваются, и начинается сложно организованная зрительная кора, к тому же наделённая обратной связью — двигающая глазное яблоко. А вот у подавляющего большинства свёрточных сетей Этой гораздо более хитрой системы нет.
Именно поэтому свёрточные сети очень хорошо справляются с тем, чем занмаются колонки — распознованием текстур и выделением границ, но почти неспособны к тому, что делает дальнейшая более сложно работающая кора — не могут развернуть картинку на 90 градусов или сказать где именно искажения в текстуре выдают на картинке руку или там ногу, к примеру.
Но у мозга начиная, если не ошибаюсь, сло я стретьего колонки заканчиваются, и начинается сложно организованная зрительная кора, к тому же наделённая обратной связью — двигающая глазное яблоко. А вот у подавляющего большинства свёрточных сетей Этой гораздо более хитрой системы нет.
Именно поэтому свёрточные сети очень хорошо справляются с тем, чем занмаются колонки — распознованием текстур и выделением границ, но почти неспособны к тому, что делает дальнейшая более сложно работающая кора — не могут развернуть картинку на 90 градусов или сказать где именно искажения в текстуре выдают на картинке руку или там ногу, к примеру.
не могут развернуть картинку на 90 градусовчеловек тоже, например, плохо распознает перевернутые лица, так что скорее всего дело в обучающей выборке, хотя, конечно еще существует мысленное вращение
Дело, конечно, в обучающей выборке. Но не только в ней. Возьмите типичную сеть и накормите её Обычными диванами. Вделите ключевые синапсы, принимающие участие в решении, ну или нейроны хотя бы. Потом возьмите сеть и предложите её кроме предыдущей последовательности ещё и повёрнутые диваны. После чего повторите выделение ключевых синапсов. Ставлю бутылку коньяка, что большая часть синапсов будет другая. То есть ваша сеть научится распознавать не разворот, а отдельно распознавать обычные диваны и отдельно развёрнутые. Не всегда, конечно. Можно в архитектуру сети заложить разворачивающую подсеть, но делать это придётся руками.
Это я к тому что у современных алгоритмов обучения крайне слабые возможности по формированию обобщений высокого уровня.
Кроме того, даже если вы предложите своей сети на вход мульён картинок диванов развёрнутых на самые резные углы Сеть может не справиться, с поиском ключевого признака развёрнутого дивана, потому как на вход сети данные поступают в крайне неудобной для анализа форме. Сеть, например, не может сама без учителя, пользуясь только рекурентными связями отцентровать картинку по приметному признаку, по ножке дивана, например. Задачу распознавания это сильно упрощает, и человеком делается двиганием глаза, эволюционно научившегося делать эту операцию легко.
Конечно, нейронная сеть, пользуясь только несколькими дополнительными слоями может научиться делать центровку самостоятельно используя только штатными возможностями, Но что-то мне подсказывает, что научить сеть этому будет посложнее, чем распознавать леопардов. И Желательно в отдельном учебном цикле с последующим трансфером.
Это я к тому что у современных алгоритмов обучения крайне слабые возможности по формированию обобщений высокого уровня.
Кроме того, даже если вы предложите своей сети на вход мульён картинок диванов развёрнутых на самые резные углы Сеть может не справиться, с поиском ключевого признака развёрнутого дивана, потому как на вход сети данные поступают в крайне неудобной для анализа форме. Сеть, например, не может сама без учителя, пользуясь только рекурентными связями отцентровать картинку по приметному признаку, по ножке дивана, например. Задачу распознавания это сильно упрощает, и человеком делается двиганием глаза, эволюционно научившегося делать эту операцию легко.
Конечно, нейронная сеть, пользуясь только несколькими дополнительными слоями может научиться делать центровку самостоятельно используя только штатными возможностями, Но что-то мне подсказывает, что научить сеть этому будет посложнее, чем распознавать леопардов. И Желательно в отдельном учебном цикле с последующим трансфером.
Вполне возможно, что на уровне «распознающих кластеров в зрительном центре» машина и может уже распознавать лучше человека.
Вопрос же в более высокоуровневых признаках.
Скажем, «бога» мы никогда не видели, но узнаём его на картинах и в архитектуре. Причём очень разных богов — христианского, языческих, фэнтезийных. Скажем, «бог» (как концепт), кажется, вообще не зависит от внешнего вида, может быть антропоморфным, аниморфным, объектоморфным, или вообще аморфным.
Думаю, у человека качество распознавания «бога» будет не очень большим, я бы (пальцем в небо) сказал, процентов 50, однако важно, что мы настоящего живого образца никогда не видели.
Вопрос же в более высокоуровневых признаках.
Скажем, «бога» мы никогда не видели, но узнаём его на картинах и в архитектуре. Причём очень разных богов — христианского, языческих, фэнтезийных. Скажем, «бог» (как концепт), кажется, вообще не зависит от внешнего вида, может быть антропоморфным, аниморфным, объектоморфным, или вообще аморфным.
Думаю, у человека качество распознавания «бога» будет не очень большим, я бы (пальцем в небо) сказал, процентов 50, однако важно, что мы настоящего живого образца никогда не видели.
Картинки картинками, а знаете какое мракобесие царит сейчас в алгоритмах диагностики болезней по симптомам?
Общался с парой десятков разработчиков — ни один не понимает важности понимания скрытого патологического процесса, более того, они его отрицают, все как один рассчитывая справиться тупо набором симптомов.
Общался с парой десятков разработчиков — ни один не понимает важности понимания скрытого патологического процесса, более того, они его отрицают, все как один рассчитывая справиться тупо набором симптомов.
Они должны уметь обучаться быстро, всего на нескольких примерах — как мы с вами — и не требовать при этом мультиклассовой выборки, а извлекать нужные признаки из объектов самих по себе.
это в точности то, что проповедует Хинтон, и вероятно нужно стремиться к глубоким моделям не супервайзд, а ансупервайзд — что то типа такого
но сегодня так получается, что практические задачи решают именно модели обученные по меткам, потому так много о них говорят; тут как то Видальди приезжал в яндекс и у него там спросили, а не предобучал ли он свои сети, тот даже переспросил типа «что что делал?», потом сказал, что нет, это типа к Хинтону, а мы занимаемся практикой компьютерного зрения; так же стоит отметить, что и сам Хинтон в гугле занимается (судя по публикациям гугла с его именем) именно обучением с учителем, просто потому, что это на сегодня лучше всего решает поставленные задачи
имхо нужно сверточные сети рассматривать как очень крутой фича экстрактор, а эти признаки уже использовать можно где угодно
меня кстати очень опечалило когда я в своей задаче (поиск похожих картинок) увидел ошибки, когда такая картинка распознавалась как бидон молока

но оказалось что все работает отлично, и скудность классов (1000 в старом имаджнете) не сильно влияет на производительность, ведь какая разница как модель будет называть «эти белые штуки»: бидоны с молоком или зубы, главное то что они действительно похожи, и в скрытом пространстве имеют похожие координаты
так же не стоит забывать, что вероятность которую вам выдала сеть — это результат работы специфичных слоев (последние полносвязные с софтмаксом), а интерес представляет именно скрытое представление изображения, в которое входят различные фичи, где есть признаки и зубов и губ и кожи, и если бы в датасете были бы классы «женская улыбка» то все было бы ок
transfer learning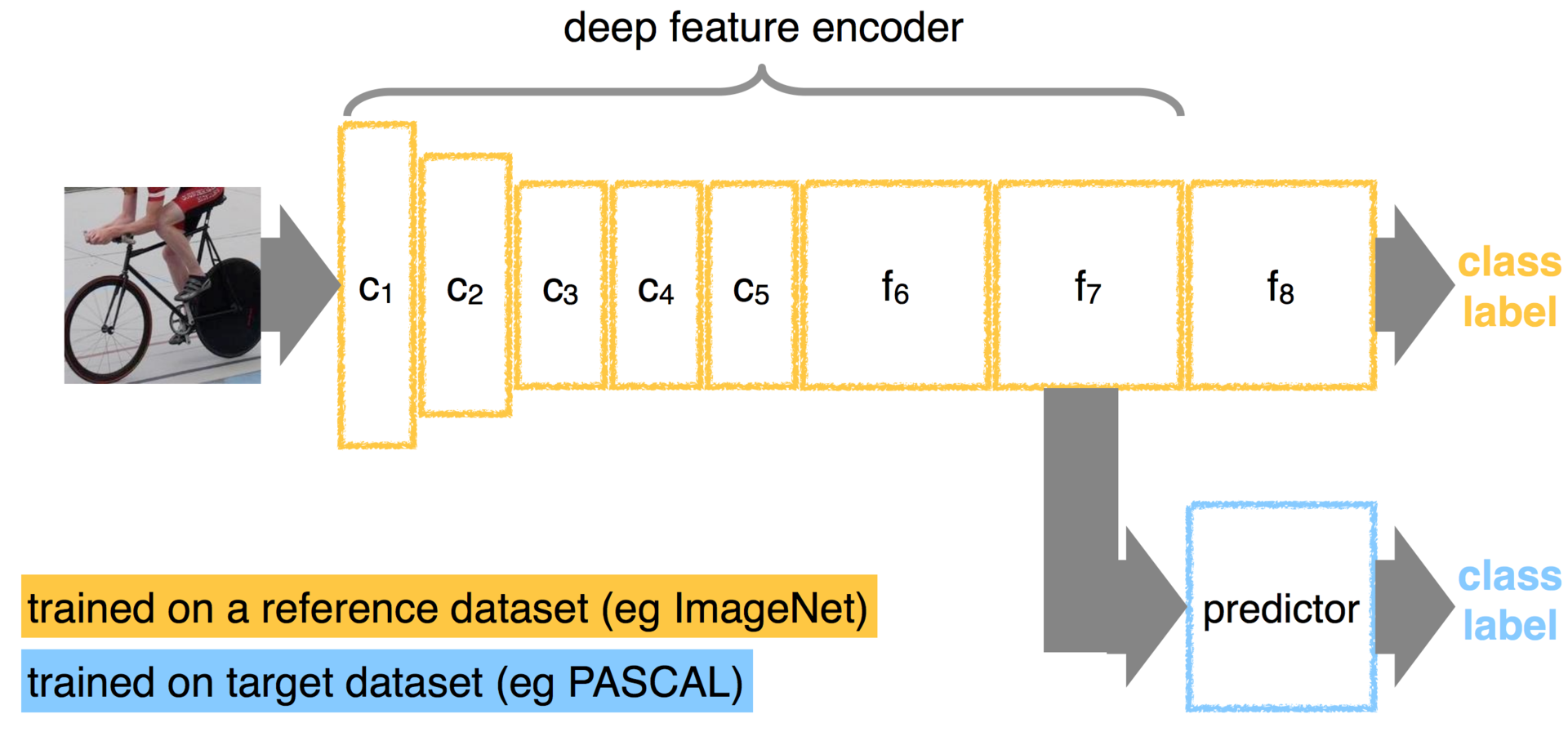
я для кодирования использовал смесь супервайзд и ансупервайзд, отрезал кусок VGG сети, справа приделал к нему глубокий автоенкодер и дообучил в режиме ансупервайзд, в итоге картинки отлично были закодированы бинарным вектором
CNN + Deep AutoEncoder
кстати имаджнетов же есть две версии, старая на 1000 классов и новая на 22000 классов, это колосальная работа которая подводит нас к улучшению качества работы сверточных сетей, которые в будущем будут составной частью большой мультимодальной системы
Читал ваш пост, он крут)
Очень похоже, что все так и есть, да. Ансупервайзд выглядит каким-то более возвышенным и интересным, но что с ним делать для практических задач — непонятно. С другой стороны, CNN можно вставить в гуглопоиск по картинкам, и в этих задачах один лишний бидон молока — не такая уж и проблема.
Очень похоже, что все так и есть, да. Ансупервайзд выглядит каким-то более возвышенным и интересным, но что с ним делать для практических задач — непонятно. С другой стороны, CNN можно вставить в гуглопоиск по картинкам, и в этих задачах один лишний бидон молока — не такая уж и проблема.
По поводу скрытого представления — в конечном итоге-то проблема растет оттуда все равно. В вашем случае представление не увидело какой-нибудь «изящной дугообразной формы» улыбки (вместо этого представив его просто белой округлой фиговиной), а в моем — проигнорировало форму леопарда, оставив от него ковер)
так а проблема в модели или в недостатке данных?
вот рецепт Эндрю Нг для дип лернинга например
можно сразу возразить — а ведь мы с вами живем и смотрим вокруг, у нас нет имаджнета на 22000 классов под рукой и мы не обучаемся с учителем, мы выделяем общие признаки, потом в детстве спрашиваем у мамки, типа а чо это такое побежало хвостатое и пушистое с когтями и миучит, а она говорит, что это кошка (приписала метку совокупности фич)
такой аргумент абсолютно верен, но есть люди которые считают что реально обучение это не чисто супервайзд, и не чисто ансупервайзд, они ввели понятие active learning
можно выделить два режима, когда алгоритм сам уточняет иногда у учителя «я тут не уверен в картинке одной, проставь метку поточнее», а иногда он сам обучается на том что уже выучил, например Хинтоновский псевдо лейбелинг использовался в решении победителя соревнования по планктонам — если алгоритм был сильно уверен в какой то неразмеченной картинке, то он ее добавлял в трейн сет
кстати годный тролинг Хинтона его коллегой
вот рецепт Эндрю Нг для дип лернинга например
универсальный алгоритм для всего
можно сразу возразить — а ведь мы с вами живем и смотрим вокруг, у нас нет имаджнета на 22000 классов под рукой и мы не обучаемся с учителем, мы выделяем общие признаки, потом в детстве спрашиваем у мамки, типа а чо это такое побежало хвостатое и пушистое с когтями и миучит, а она говорит, что это кошка (приписала метку совокупности фич)
такой аргумент абсолютно верен, но есть люди которые считают что реально обучение это не чисто супервайзд, и не чисто ансупервайзд, они ввели понятие active learning
можно выделить два режима, когда алгоритм сам уточняет иногда у учителя «я тут не уверен в картинке одной, проставь метку поточнее», а иногда он сам обучается на том что уже выучил, например Хинтоновский псевдо лейбелинг использовался в решении победителя соревнования по планктонам — если алгоритм был сильно уверен в какой то неразмеченной картинке, то он ее добавлял в трейн сет
кстати годный тролинг Хинтона его коллегой
забыл ссылку дать еще на один аргумент того что ансупервайзд — это круто, но пока рынок не такой
Природа удивительна, самые умные, не могут сделать дебила.
Меня впечатлил новый сервис от гугла — photos.google.com
Залил я туда значит картинку порша по запросам — порш, sport car, 911, porsche нашел именно ее. Так же гугл уже не раз демонстрировал определение того, что же происходит на картинке. Допустим танцы или кот сидит на диване
Залил я туда значит картинку порша по запросам — порш, sport car, 911, porsche нашел именно ее. Так же гугл уже не раз демонстрировал определение того, что же происходит на картинке. Допустим танцы или кот сидит на диване
кот сидит на диванеЛеопардовом? :D
Кстати, что характерно: такой вот результат выдал гугл на многострадальный диван. И я в общем-то с ним согласен.
goo.gl/WKq5Lc
Спасибо за статью Уникально и интересно.
В защиту подхода к сетям, как к миксерам — запихаем туда разного и пусть сами разгребают, скажу, что получить высокоуровневые устойчивые признаки (а-ля структура расцветки) такими мизерными трудозатратами — дорогого стоит. просто не надо доверять нейронной сети принятие окончательного решения — нужно самим обрабатывать полученные поля признаков более высокоуровенывыми подходами — которые учитывают не только статистику, но и онтологическую картину мира.
В защиту подхода к сетям, как к миксерам — запихаем туда разного и пусть сами разгребают, скажу, что получить высокоуровневые устойчивые признаки (а-ля структура расцветки) такими мизерными трудозатратами — дорогого стоит. просто не надо доверять нейронной сети принятие окончательного решения — нужно самим обрабатывать полученные поля признаков более высокоуровенывыми подходами — которые учитывают не только статистику, но и онтологическую картину мира.
Полностью согласен про ImageNet. Вы очень точно сформулировали, что творилось у меня в голове) соревнование превращается в вещь в себе, в проверку, у кого больше денег на кластер из GPU. Буду теперь давать на эту статью ссылку всем некомпетентным товарищам.
Проблема похоже в том, что люди учаться воспринимать и симулировать 3хмерное пространство с детства, соответственно для правильного определения дивана как дивана ии должен преобразовать 2хмер в 3хмерные объекты и каждый из них определить. Пример с картинкой барсенка показывает именно подобный поиск людьми. Мы не можем найти камуфляж, но можем найти несоответствие пейзажа, в движении это еще проще, т.к.есть с чем сравнить.
Не думаю что роботам под силу преобразовывать в 3д и определять модель также быстро как людям. Не сейчас. Для этого надо очень много памяти и операций.
Не думаю что роботам под силу преобразовывать в 3д и определять модель также быстро как людям. Не сейчас. Для этого надо очень много памяти и операций.
Тот же диван надо преобразовать в трехмер, понять что в БД нет 100% результата, определить его как параллелипипед, преобразовать его для выравнивания пока не переопределить его (сначала на 90 градусов, затем меньший процент и так далее и т.п.) со 100% значением. И при этом все равно он сможет сделать ошибку, как и человек. Потому что параллельно ии должен знать что текстура не соответствует другим объектам, соответственно только диван может иметь такую структуру
Мне кажется, что, разглядывая картинку с леопардом, я поступаю следующим образом: классифицирую морду, туловище, ноги, хвост и текстуру (ещё пластику, если это не картинка, а видеоряд). Собираю из этих признаков (не обязательно всех) класс «леопард». А если мне нужна «3д-модель» в голове, я вспоминаю, что леопарды, как правило, примерно симметричны, и воображаю, как он бы выглядел с другой стороны. Если леопард в той позе, в которой симметрия работает — всё ок. А если нет, то без знания леопардовой анатомии я уже 3д-модель не составлю.
Т.е. для задачи «узнать леопарда» 3д-модель в голове не обязательна.
Т.е. для задачи «узнать леопарда» 3д-модель в голове не обязательна.
Это, кстати, довольно практичный подход, потому что лапы, хвост, туловище и морда — классы, которые я могу использовать для распознавания и других крупных кошек. А если класс «морда» разложить на составляющие, то выясниться, что 95% его «подклассов» можно использовать для распознавания кошек вообще. Допускаю также существование в своей голове классов «морда в профиль», «морда в анфас», «морда в 3/4».
Вспомните первые классы школы, когда вы учились писать цифры.
Каждому из учеников тогда приносили по увесистой книге с названием «MNIST database», где на сотнях страниц были выписаны шестьдесят тысяч цифр, все — различными почерками и стилями, жирным шрифтом и едва заметным курсивом.
Статья не помечена как перевод, поэтому мне странно это предложение. Не было такого ни у меня, ни у кого из моих друзей. Где же вы учились?
ой ли… Сначала ребёнок пару лет учится компенсирвоать повороты, изменения масштабов и освещённости, различать детали, и только потом его начинают учить символам, писанным на доске. За других не скажу, но я в детстве, видимо, редко смотрел в зеркало, и сейчас мне трудно определить время на цифровых часах, отражающихся в зеркале. Сотни раз путал 5 с 2, сотни раз осознавал это и корректировал себя, и всё равно путаю. Так что, не факт, не факт.
А часто ли вообще вам (или любому другому человеку) встречается задача определения отраженных в зеркале 7-сегментных цифр?
Перевёрнутые встречаются часто. Проекционные часы светят на потолок, и когда лежишь на спине, они видны в одной ориентации, а когда лежишь на животе и поднимаешь голову, чтобы узнать время — то в другой. Если к этому добавить плохое зрение, то нейронная сеть справляется с очень большим трудом.
Отражения в зеркале (или в окне, или в экране монитора...) встречаются реже, но попадались неоднократно. Особенно трудно их распознавать, когда это отражение от горизонтальной поверхности (блестящего стола).
Отражения в зеркале (или в окне, или в экране монитора...) встречаются реже, но попадались неоднократно. Особенно трудно их распознавать, когда это отражение от горизонтальной поверхности (блестящего стола).
С цифрами 2 и 5 на цифровом табло такая проблема: у нас не только есть отдельные нейроны для распознавания каждой из этих цифр, они ещё и тормозят друг-друга для повышения качества. То есть процесс распознавания динамический и по мере поступления информации понемногу активируется сразу несколько нейронов, для каждой из цифр, но тот, который даёт больший отклик начинает тормозить остальные, пока система не придёт в устойчивое состояние.
Поэтому мы на подсознательном уровне не можем обучить зеркально отражённые 2 и 5, даже если сознательно понимаем, что цифры перевёрнуты. Просто на зеркально отражённую 5 сразу даёт огромный отклик нейрон, распознающий 2 и тормозит все попытки нейрона, распознающего 5, активироваться.
Если бы мы смотрели на отражённые цифры чаще, то связи между нейронами 2 и 5, возможно, перенастроились бы так, чтобы они не тормозили друг друга, а сам процесс различения этих цифр тратил бы немного больше ресурсов.
Поэтому мы на подсознательном уровне не можем обучить зеркально отражённые 2 и 5, даже если сознательно понимаем, что цифры перевёрнуты. Просто на зеркально отражённую 5 сразу даёт огромный отклик нейрон, распознающий 2 и тормозит все попытки нейрона, распознающего 5, активироваться.
Если бы мы смотрели на отражённые цифры чаще, то связи между нейронами 2 и 5, возможно, перенастроились бы так, чтобы они не тормозили друг друга, а сам процесс различения этих цифр тратил бы немного больше ресурсов.
Лично мне очевидно, что аналогичная сверточная сеть у меня в мозгу есть. И именно она отвечает за быстрое распознавание. Однако помимо этой сети есть еще уровень сознательного распознавания, который выступает учителем для сверточной сети и fallback-ом на случай ее фейла. Именно поэтому чтение перевернутого текста или какого-нибудь вычурного шрифта такое медленное: сверточная сеть не справляется и приходится задействовать сознательный уровень. Соответственно, обучение детей цифрам происходит следующим образом: правильному набору кружочков и палочек обучается сознательная часть, а потом, на куче реальных примеров, уже обучает сверточную сеть. Еще есть известный прикол с неважностью порядка букв внутри слова — сеть не использует конкретное положение символа для распознавания.
А насчет леопардового дивана, далеко не факт, что человек не определит его леопардом, будучи поставленным в условия невозможности задействования сознательной части (показывать картинку на доли секунды и требовать быстро нажать соответствующую кнопку).
А насчет леопардового дивана, далеко не факт, что человек не определит его леопардом, будучи поставленным в условия невозможности задействования сознательной части (показывать картинку на доли секунды и требовать быстро нажать соответствующую кнопку).
Нейронные сети однозначно тупиковая ветвь на пути к AI
То что леопардовый диван ближе к диванам чем к леопардам — это достаточно субъективная человеческая точка зрения. Мы для этого используем метаинформацию, отсутствующую у сети при обучении (типа, леопарды живут в Африке, а диваны — в гостиной и не живут).
habrahabr.ru/post/259191/#comment_8462681
Как раз писал про контекст. Эту метаинформацию, как мне кажется, нетрудно выделить, если использовать не картинку, а именно зрение (видео + «движение камеры»): осмотрели комнату — увидели диван, осмотрели саванну — увидели леопарда.
Как раз писал про контекст. Эту метаинформацию, как мне кажется, нетрудно выделить, если использовать не картинку, а именно зрение (видео + «движение камеры»): осмотрели комнату — увидели диван, осмотрели саванну — увидели леопарда.
По итогам написанного, вопрос. Есть одна девушка

Можно ли с помощью сверточной сети или какой-либо другой современной технологии определить, где у девушки ноги?
Можно ли с помощью сверточной сети или какой-либо другой современной технологии определить, где у девушки ноги?
Снизу?
Использовал устройство появившееся ещё в 1987 году — себя. =\
Использовал устройство появившееся ещё в 1987 году — себя. =\
Разумно. Но всегда ли ноги — это «то, что снизу»?

У нас с вами нет проблем с определением местоположения ног у кого-то из изображенных здесь. Тем не менее, можно ли с помощью современных технологий искусственного интеллекта разработать программу, определяющую, где у силуэта ноги?
У нас с вами нет проблем с определением местоположения ног у кого-то из изображенных здесь. Тем не менее, можно ли с помощью современных технологий искусственного интеллекта разработать программу, определяющую, где у силуэта ноги?
можно, конечно. Набор обучающих записей из миллиона размеченных образцов предоставите?
Из http://theinstitute.ieee.org/technology-focus/technology-topic/the-motion-tech-behind-kinect779:
To do this, the researchers uploaded more than a million images of different people in different positions. To teach the system how to recognize body parts, the team used a computer graphics algorithm to render color-coded images representing the different body parts. They eventually created a machine learning algorithm that could analyze each pixel in an image and determine which limb it was.
Из http://theinstitute.ieee.org/technology-focus/technology-topic/the-motion-tech-behind-kinect779:
To do this, the researchers uploaded more than a million images of different people in different positions. To teach the system how to recognize body parts, the team used a computer graphics algorithm to render color-coded images representing the different body parts. They eventually created a machine learning algorithm that could analyze each pixel in an image and determine which limb it was.
Разве Кинекту не требуются для работы показания трех камер, включая инфракрасную?

Полагаю, вы не понимаете сути поставленной задачи. Требуется разметить части тела по изображению, не содержащему вообще никакое непосредственной информации о форме тела, кроме контура. Думаю, не требует объяснений, почему эта задача на порядок сложнее, чем то, что демонстрирует нам Kinect.
Суть сверточной сети в распознавании картинки по множественным локальным признакам. Безошибочно распознать ступню ноги или другую часть тела, рассматривая её отдельно от остального невозможно, учитывая, что она может быть частично закрыта. Единственным способом разметить силуэт становится некий его анализ с учетом познаний о механическом устройстве объекта, породившего силуэт. Однако, прямой перебор возможных «поз» модели с порождением от каждой позы набора проекций и сравнения их с исходной очевидно неэффективен. Задача вычисления положения известного трехмерного объекта по его тени сложна даже для простых объектов, не отягощенных механикой, в данном случае эта сложность увеличивается многократно. Тем не менее, восприятие человека успешно справляется с этой задачей за доли секунды.
Предположим, мы создали обучающую базу из миллионов силуэтов с нанесенной структурой скелета, а так же разработали механическую модель человеческого тела. При условии этого, сможем ли мы решить поставленную задачу? Какие подходы к решению будут эффективны?
Полагаю, вы не понимаете сути поставленной задачи. Требуется разметить части тела по изображению, не содержащему вообще никакое непосредственной информации о форме тела, кроме контура. Думаю, не требует объяснений, почему эта задача на порядок сложнее, чем то, что демонстрирует нам Kinect.
Суть сверточной сети в распознавании картинки по множественным локальным признакам. Безошибочно распознать ступню ноги или другую часть тела, рассматривая её отдельно от остального невозможно, учитывая, что она может быть частично закрыта. Единственным способом разметить силуэт становится некий его анализ с учетом познаний о механическом устройстве объекта, породившего силуэт. Однако, прямой перебор возможных «поз» модели с порождением от каждой позы набора проекций и сравнения их с исходной очевидно неэффективен. Задача вычисления положения известного трехмерного объекта по его тени сложна даже для простых объектов, не отягощенных механикой, в данном случае эта сложность увеличивается многократно. Тем не менее, восприятие человека успешно справляется с этой задачей за доли секунды.
Предположим, мы создали обучающую базу из миллионов силуэтов с нанесенной структурой скелета, а так же разработали механическую модель человеческого тела. При условии этого, сможем ли мы решить поставленную задачу? Какие подходы к решению будут эффективны?
Я не понимаю, что значит «решить» задачу. Можно «решить задачу с каким-то качеством».
Например, Kinect использует данные 3d-сенсора для увеличения качества, но не использует зависимости между кадрами. Один кадр из 60 или даже 5 кадров из 60 могут показывать какую-нибудь чушь — и это задача приложения к этому адаптироваться.
Человек, в свою очередь, использует зависимости между кадрами — чтобы увеличить качество (прогнозирование положения конечностей и центра масс, и усреднение результатов по времени).
Тем не менее, я уверен, что CNN решит задачу с неплохим качеством — не менее 90%.
Как минимум, вы могли бы просто искать ноги и руки на картинке.
Против CNN — только низкая мощность компьютера в подобных задачах по сравнению с человеком, но в данной задаче не так уж много надо мощности.
Например, Kinect использует данные 3d-сенсора для увеличения качества, но не использует зависимости между кадрами. Один кадр из 60 или даже 5 кадров из 60 могут показывать какую-нибудь чушь — и это задача приложения к этому адаптироваться.
Человек, в свою очередь, использует зависимости между кадрами — чтобы увеличить качество (прогнозирование положения конечностей и центра масс, и усреднение результатов по времени).
Тем не менее, я уверен, что CNN решит задачу с неплохим качеством — не менее 90%.
Как минимум, вы могли бы просто искать ноги и руки на картинке.
Против CNN — только низкая мощность компьютера в подобных задачах по сравнению с человеком, но в данной задаче не так уж много надо мощности.
Ищем голову, потом по скелету спускаемся до ног?
Глаз делает так. Можно ли формализовать, не очень понятно.
Поизучав картинки пристально, понял, что быстрее распознаю позы, в которых чаще видел людей (фото и видео считаются).
+1 в пользу гипотезы о классах «морда леопарда в профиль», «морда леопарда в анфас», «морда леопарда в 3/4».
Покажите такую же картинку с силуэтами летучей мыши в разных позах. Думаю, определять, где у неё ноги, станет заметно труднее.
Ладно силуэты. Мы у персонажей xkcd позы без труда определяем :)
+1 в пользу гипотезы о классах «морда леопарда в профиль», «морда леопарда в анфас», «морда леопарда в 3/4».
Покажите такую же картинку с силуэтами летучей мыши в разных позах. Думаю, определять, где у неё ноги, станет заметно труднее.
Ладно силуэты. Мы у персонажей xkcd позы без труда определяем :)
Ладно силуэты. Мы у персонажей xkcd позы без труда определяем
Ну почему же "даже/ладно" ?
Предположу ровно обратное. Что предельно упрощённые образы, как в xkcd, это те самые "платоновские идеи", которые кристаллизовались где-то в глубине наших "нейронных сетей", что это и есть в максимально выразимом в физическом мире виде те самые "правила" наработанные внутри. Очищенные и рафинированные. И поэтому они как раз должны легко восприниматься, а не трудно.
Хм… но вроде бы очевидно, что искусственный интеллект не получить количественно. Тут нужен качественный скачок. А обучение на картинках это количество. И просто так в качество оно не перейдёт.
Это ж прям карго культ получается со стороны человечества — попытка имитировать интеллект без знаний о его работе. Ну или при недостаточном знании. Специалисты по мозгам пока очень далеки от полного описания их работы…
Это ж прям карго культ получается со стороны человечества — попытка имитировать интеллект без знаний о его работе. Ну или при недостаточном знании. Специалисты по мозгам пока очень далеки от полного описания их работы…
Рассчёт на то, что сеть сделает обобщения. Мало кто понимает как и какие обобщения сеть делает, но она их делает и это вселяет оптимизм. В тех кто не понимает как именно она их делает. Автор всего лишь показал это «как» людям, которые надеялись на магию.
Безусловно обучение на количестве картинок безнадёжно, но большинство людей ещё этого не понимают. Хотя казалось бы очевидно, если вы хотите чтобы сеть разделала кошек по поведению и окружению — предложите ей картинки на которых кошки отличаются в основном поведением и окружением. И вас уверяю, она научится понимать, что гепарды не сидят на деревьях, а леопарды в саванне. Но это ж трудоёмко, а уже размеченые базы картинок есть, давайте на них тренероваться. Результат как бы предсказуем.
И это не отменяет того факта, что у людей всё сильно сложнее, и ребёнок, даже если ему предъявляешь соответствующие примеры до определённого момента не делает из них выводов, пока не включается очередной шаг программы и он не начинает в этих примерах искать смысл. Можно предположить, что такая «программа развёртывания» нужна только для ускорение и упрощения, но и даже без неё результат предсказуем.
Безусловно обучение на количестве картинок безнадёжно, но большинство людей ещё этого не понимают. Хотя казалось бы очевидно, если вы хотите чтобы сеть разделала кошек по поведению и окружению — предложите ей картинки на которых кошки отличаются в основном поведением и окружением. И вас уверяю, она научится понимать, что гепарды не сидят на деревьях, а леопарды в саванне. Но это ж трудоёмко, а уже размеченые базы картинок есть, давайте на них тренероваться. Результат как бы предсказуем.
И это не отменяет того факта, что у людей всё сильно сложнее, и ребёнок, даже если ему предъявляешь соответствующие примеры до определённого момента не делает из них выводов, пока не включается очередной шаг программы и он не начинает в этих примерах искать смысл. Можно предположить, что такая «программа развёртывания» нужна только для ускорение и упрощения, но и даже без неё результат предсказуем.
Вот, кстати, из нового: arxiv.org/abs/1501.02876
Там в разделе 5.5 трансформируют тестовые картинки.
Там в разделе 5.5 трансформируют тестовые картинки.
Попробуйте быстро пролистывать вперемешку картинки с леопардами и леопардовыми диванами и смотреть на них краем глаза. Скорее всего вы скажете, что на картинках что-то леопардовое, то есть главный признак, на которой тратится минимум мозговой активности будет как раз соответствующий узор. А дальше вероятно идет более сложный мыслительный процесс — морда, лапы есть — значит леопард, квадратный — значит диван.
Куда пропал автор статьи, кто знает?
В 2018 году появилась работа, исследующая преимущество нейросети к использованию текстуры объекта вместо формы.
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness ( openreview.net/forum?id=Bygh9j09KX, arxiv.org/abs/1811.12231 )
Да, выяснилось, что, действительно, в спорных ситуациях нейросеть предпочитает опираться на текстуру объекта, но формы она тоже хорошо выучивает, не хуже человека.
Научились обучать нейросети без этого смещения к текстуре, теперь леопардовый диван успешно распознается как диван. Профит!
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness ( openreview.net/forum?id=Bygh9j09KX, arxiv.org/abs/1811.12231 )
Да, выяснилось, что, действительно, в спорных ситуациях нейросеть предпочитает опираться на текстуру объекта, но формы она тоже хорошо выучивает, не хуже человека.
Научились обучать нейросети без этого смещения к текстуре, теперь леопардовый диван успешно распознается как диван. Профит!
Использовать распознование по текстуре как предобучение распознованию по форме? Идея прикольная. :)
Нужная оговорка — преимущественное использование текстуры СВЁРТОЧНОЙ нейросетью. Да, сейчас приличные результаты дают только свёрточные сети, но без это оговорки все не являющиеся упёртыми професионалами будут думать, что это свойство сети вообще, а не свойство того, что в соревнованиях на неподвижных фотках выигрывают сети со свёрточными первыми слоями.
Нужная оговорка — преимущественное использование текстуры СВЁРТОЧНОЙ нейросетью. Да, сейчас приличные результаты дают только свёрточные сети, но без это оговорки все не являющиеся упёртыми професионалами будут думать, что это свойство сети вообще, а не свойство того, что в соревнованиях на неподвижных фотках выигрывают сети со свёрточными первыми слоями.
Не, не так: не давать сети учиться по текстуре, подменяя текстуры объектов на другие случайные текстуры по маске объекта. Тогда она начинает больше опираться на форму.
Но это проблема в том числе и ImageNet-а, он слишком лёгкий, и текстуры для нейросети во многих случаях достаточно. Почему тогда ей не использовать текстуры, раз это проще всего?
Про свёрточную нейросеть я не понял смысла твоего комментария. Ты можешь Fully-Connected слоями эмулировать свёрточные слои, просто она будет гораздо медленнее работать. Поэтому она тоже скорее всего будет иметь тот же bias к текстурам, вот только авторы данной конкретной работы это не проверяли. В общем, я не вижу никаких оснований считать, что это свойство именно свёрточной сети.
Но это проблема в том числе и ImageNet-а, он слишком лёгкий, и текстуры для нейросети во многих случаях достаточно. Почему тогда ей не использовать текстуры, раз это проще всего?
Про свёрточную нейросеть я не понял смысла твоего комментария. Ты можешь Fully-Connected слоями эмулировать свёрточные слои, просто она будет гораздо медленнее работать. Поэтому она тоже скорее всего будет иметь тот же bias к текстурам, вот только авторы данной конкретной работы это не проверяли. В общем, я не вижу никаких оснований считать, что это свойство именно свёрточной сети.
Sign up to leave a comment.
Внезапный диван леопардовой расцветки