Comments 127
Unicode все больше напоминает какую-то немыслимое нагромождение вещей, относящихся по сути к разным уровням абстракции.
Хотя всего-то — таблица символов. Должна быть таблица символов — если делать по уму.
Зачем вообще было делать возможность прикручивать всякие надстрочные символы к любой букве? Тогда бы уж и математическую нотацию поддержали, всякие верхние/нижние индексы, подчеркивания/надчеркивания/перечеркивания/обводку, многоэтажные дроби и корни и прочее.
Только тогда это был бы уже не Unicode, а полноценный язык разметки. А это совсем не то, ради чего создавался Unicode. ИМХО конечно.
Хотя всего-то — таблица символов. Должна быть таблица символов — если делать по уму.
Зачем вообще было делать возможность прикручивать всякие надстрочные символы к любой букве? Тогда бы уж и математическую нотацию поддержали, всякие верхние/нижние индексы, подчеркивания/надчеркивания/перечеркивания/обводку, многоэтажные дроби и корни и прочее.
Только тогда это был бы уже не Unicode, а полноценный язык разметки. А это совсем не то, ради чего создавался Unicode. ИМХО конечно.
Зачем вообще было делать возможность прикручивать всякие надстрочные символы к любой букве?
Как обозначить символ ударения в строке? Сдублировать все возможные символы с этим символом? Думаю что не сто́ит.
А как обозначить верхний индекс (x в степени n)? Дублировать все цифры и буквы всех алфавитов еще два раза (для верхнего и нижнего индексов)?
Чем ударение концептуально отличается от индекса?
Чем ударение концептуально отличается от индекса?
Цифры-то есть: x¹, x², x³…
Ну в реальном применении цифры без букв малополезны. Хотя-бы латинский алфавит напрашивается… но где в таком случае остановиться? Допустим, корень — это символ √ и надчеркивание над всеми символами подкоренного выражения. Вроде сделать несложно — по аналогии с ударением ввести верхнюю черту над символом (а может такая уже и есть). Но дальше пойдут вложенные корни. Их как?
Латинский алфивит у Unicode есть почти весь (нет почему-то только буквы q): ᵃ ᵇ ᶜ ᵈ ᵉ ᶠ ᵍ ʰ ⁱ ʲ ᵏ ˡ ᵐ ⁿ ᵒ ᵖ ʳ ˢ ᵗ ᵘ ᵛ ʷ ˣ ʸ ᶻ.
Что включать, а что нет — над этим очень долго думают, да. Понятно что всё это — некоторый компромисс, но как бы понятно, что как минимум IPA поддерживать нужно — оттуда всё и идёт.
Что включать, а что нет — над этим очень долго думают, да. Понятно что всё это — некоторый компромисс, но как бы понятно, что как минимум IPA поддерживать нужно — оттуда всё и идёт.
Частицы бы, ли, же пишутся через пробел! Как можно так косячить в такой перфекционистской дискуссии?
И сколько этих «всех возможных» символов могут иметь ударение? 6 гласных в латинице, 10 в кириллице, еще несколько (не знаю точное количество) в греческом. Умножаем на два для прописных букв. Итого аж меньше 50. При овер миллионе кодопоинтов в текущей версии стандарта.
Как надо было делать правильно: для каждого языка свой набор символов, даже если внешне они совпадают. То есть кодопоинт немецкой А должен отличаться от английской А (так же как он сейчас отличается от кодопоинта русской А). Тогда для каждого конкретного языка можно однозначно было бы определить коллацию (алфавитный порядок и таблицу подстановок при поиске и сравнении). В которой, например, русские символы и, И, й, Й все приводились бы к И для целей сравнения, как это и должно быть по правилам конкретно русского языка. При этом для украинского языка коллация была бы другой. Потому что она и есть другая. Если бы кодопоинт русской И отличался от кодопоинта украинской И, всё работало бы «из коробки». Но сейчас программисты должны явно указывать, какую коллацию нужно использовать — вот только 99% слыхом про все эти заморочки не слыхивали.
Как надо было делать правильно: для каждого языка свой набор символов, даже если внешне они совпадают. То есть кодопоинт немецкой А должен отличаться от английской А (так же как он сейчас отличается от кодопоинта русской А). Тогда для каждого конкретного языка можно однозначно было бы определить коллацию (алфавитный порядок и таблицу подстановок при поиске и сравнении). В которой, например, русские символы и, И, й, Й все приводились бы к И для целей сравнения, как это и должно быть по правилам конкретно русского языка. При этом для украинского языка коллация была бы другой. Потому что она и есть другая. Если бы кодопоинт русской И отличался от кодопоинта украинской И, всё работало бы «из коробки». Но сейчас программисты должны явно указывать, какую коллацию нужно использовать — вот только 99% слыхом про все эти заморочки не слыхивали.
Угу, вот только тогда немцам пришлось бы иметь две раскладки на компьютере, если бы они захотели набирать текст и на английском, и на немецком, и не забывать переключаться между ними. При том, что все буквы английского алфавита содержаться в немецком, никто в своем уме этим заморачиваться бы не стал. Таким образом, мы получим гору текста на английском, которую англичане могут прочитать, но по которой не работает поиск. Точно так же поиск с включенной немецкой раскладкой не работал бы по тексту, набранному в английской, что с точки зрения пользователя (которому пофиг на проблемы программистов) — баг.
Хочу только добавить, что идея разделить кириллические и латинские символы пришла в голову разработчикам тоже не сразу. На какой-нибудь БЭСМ-6 они были слиты «де юре», на ЕС ЭВМ они были слиты «де факто», но уже на СМках их разнесли. То есть это просто оказалось удобнее. Французы же и немцы ничего такого даже не пытались сделать, то есть им этого было не нужно.
Всё это случилось задолго до появления Unicode 1.0.
Всё это случилось задолго до появления Unicode 1.0.
На эту тему есть интересная заметка в преамбуле стандарта юникода.
Хотя общеизвестно, что европейские алфавиты унаследованы друг от друга (греческий породил два потомка — латиницу и кириллицу) и многие буквы в них совпадают, тем не менее, в лингвистике принято считать их разными алфавитами. В том числе из-за сложившихся культурных отличий в начертании некоторых «совпадающих» букв (например, α — a — а. Обратите внимание на разницу в начертании латинской и кириллической «a» в одном и том же шрифте).
А вот на востоке всё наоборот, совпадающие иероглифы не дублируются для разных языков.
Хотя общеизвестно, что европейские алфавиты унаследованы друг от друга (греческий породил два потомка — латиницу и кириллицу) и многие буквы в них совпадают, тем не менее, в лингвистике принято считать их разными алфавитами. В том числе из-за сложившихся культурных отличий в начертании некоторых «совпадающих» букв (например, α — a — а. Обратите внимание на разницу в начертании латинской и кириллической «a» в одном и том же шрифте).
А вот на востоке всё наоборот, совпадающие иероглифы не дублируются для разных языков.
А вот на востоке всё наоборот, совпадающие иероглифы не дублируются для разных языков.Там всё хуже. Изначально там попытались объединить якобы одинаковые иероглифы, чтобы вписаться в 65536 символов. Что в результате привело к страшной путанице, которую «разрулили» через одно место. А уж что они сделали с флагами — это вообще ни в сказке сказать, ни пером описать.
P.S. Особенно радует что Unicode 8.0 в том месте, где должны описываться эти самые флаги ссылается на github. В раздел «Google Internationalization». А если завтра github обанкротится или Гугл перестанет этой темой интересоваться, то что — всё? Уже никто и никогда не сможет быть уверен, что он правильно реализует стандарт?
А что там с законодательным запрещением некоторых последовательностей символов?
Это я про emoji и вариации на тему компоновки: MAN+MAN+HEART и типа того…
Это я про emoji и вариации на тему компоновки: MAN+MAN+HEART и типа того…
Не скажу за немцев, но во многих латино-алфавитных странах раскладок действительно две, английская и родная с местными спецсимволами (умляутами и т.п.).
Определение языка по словарю никто не отменял, да.
Определение языка по словарю никто не отменял, да.
вот только тогда немцам пришлось бы иметь две раскладки на компьютере, если бы они захотели набирать текст и на английском, и на немецком, и не забывать переключаться между ними
ШОК! У немцев и так две раскладки :)
В русском языке «И» и «Й» все-же разные буквы (как и буквы «Е» и «Ё»). То что у буквы есть какие-то элементы не связанные с ней непрерывными линиями, не значит что эти элементы нужно выделять в отдельные символы, и в дальнейшем лепить любой другой букве. Ударение — ладно, соглашусь, это отдельный символ. Может быть в каких-то специальных случаях нужен отдельный символ " ̆ ", но использовать его для конструирования существующих букв неверно.
И, если возвращаться к исходной проблеме, ошибка в том что кто-то прилепил к букве «И» верхний элемент, получив таким образом визуально другую букву.
Я могу аналогично сделать букву «Ы» из мягкого знака и латинской L: «Ьl». Но зачем?
И, если возвращаться к исходной проблеме, ошибка в том что кто-то прилепил к букве «И» верхний элемент, получив таким образом визуально другую букву.
Я могу аналогично сделать букву «Ы» из мягкого знака и латинской L: «Ьl». Но зачем?
То что у буквы есть какие-то элементы не связанные с ней непрерывными линиями, не значит что эти элементы нужно выделять в отдельные символы, и в дальнейшем лепить любой другой букве.Конечно нет! Только вот беда: кратка (да, это русское слово) — это какой-то там элемент, а отдельная сущность. И может ставиться не только над «и», но и на «у» (в белорусском — получается "ў"), над «а» и «е» (в чувашском — получаются "ӑ" и "ӗ"), а в старославянских текстах могла употребляться ещё и над "ѵ", «ю» и другими буквами. Наиболее распространённые комбинации имеют отдельные юникодные символы, но на всякие «А҃» и " А҉" букв не напасёшься.
Я могу аналогично сделать букву «Ы» из мягкого знака и латинской L: «Ьl». Но зачем?Именно: незачем. Потому что знак «ы» логически на две сущности не разделяется. А вот «и» краткое (вы хоть на название-то обратите внимание, да?) — разделяется.
А вот «и» краткое (вы хоть на название-то обратите внимание, да?) — разделяется.
«И» и Й" это две разные буквы. Название буквы тут вообще не при чем.
Надстрочные элементы как таковые могут быть отдельными сущностями и использоваться в каких-то особых случаях (то же ударение или еще что-то) — но это не делает букву «Й» состоящей из двух символов. Иначе эта «кратка» занимала бы отдельное место в алфавите, чего не наблюдается.
Иначе эта «кратка» занимала бы отдельное место в алфавите, чего не наблюдается.Конечно не наблюдается! Какой же идиот диакритику в список букв заносит?
Надстрочные элементы как таковые могут быть отдельными сущностями и использоваться в каких-то особых случаях (то же ударение или еще что-то) — но это не делает букву «Й» состоящей из двух символов.Разумеется. Её делает состоящей из двух элементов тот простой факт, что в 35-буквенном русском алфавите её нет. А использовался он вовсе не так и давно — меньше ста лет назад.
Если вы считаете что Unicode призван обслуживать ваши личные потребности, то вы ошибаетесь. Мир, он, как бы, не вчера родился и в нём есть много вещей, про которые вы ничего не знаете — но это не значит, что они никому не нужны. Для ваших личных потребностей, я уверен, сгодился бы вариант и без римских цифр и без многих других чудес.
По вашему же, получается, в Unicode должна отсутствовать полноценная буква современного алфавита только потому, что она образована модификатором.А вот этого я не говорил. Более того, совершенно очевидно, что там отдельная буква «й» обязана присутствовать — хотя, возможно, как compatibility character. Просто потому что всякие странные кодировки типа ДКОИ-8 её содержат. А вот нужно ли считать канонической записью «й» или «й» — это уже большой вопрос. Как уже было замечено MacOS скорее склоняется в первому варианту, Windows — ко второму, и у тех и у других есть доводы «за» и «против».
По поводу того что может «складываться» и «раскладываться» в своё время много копий сломали, но сейчас-то всё уже давно устаканилось, канонические таблицы как бы всем доступны, так что неясно почему этот вопрос всё ещё возникает. Написано что «й» может «расколадываться» — значит раскладиывается. Не написано, что «щ» и/или "ꚗ" могут раскладываться — значит не раскладываются. Чего шуметь-то?
«Й» достойна быть самостоятельным элементом Unicode уже хотя бы по тому, что это не просто «И» краткая (которой гораздо ближе символ «i»), а по природе своей отдельный звук имеющий совершенно иную природу произношения: «и» — гласный звук, «й» — согласный. «И» и «Й» не чередуются в корнях слов, в отличае от «е» и «ё», которые в этом смысле — суть одно и тоже.
Её делает состоящей из двух элементов тот простой факт, что в 35-буквенном русском алфавите её нет. А использовался он вовсе не так и давно — меньше ста лет назад.
Буква й пришла в русское светское письмо из церковнославянского грубо говоря при Никоне. А исчезла по повелению Петра I, отменившего все надстрочные знаки. Через небольшое время кратка восстановилась, но й отдельной буквой не считалась. И только большевики объявили её снова отдельной буквой.
>А вот «и» краткое (вы хоть на название-то обратите внимание, да?) — разделяется.
Тогда почему в алфавите она присутствует как самостоятельная буква? В немецком гласные с умляутом — это именно обычные гласные с умляутом, их нет в алфавите.
Тогда почему в алфавите она присутствует как самостоятельная буква? В немецком гласные с умляутом — это именно обычные гласные с умляутом, их нет в алфавите.
Буквы И и Й разные, но по факту взаимозаменяемые. Любителями андройда, например. Хотя это и безграмотно, но в южных губерниях общепринято.
А вот точки над Ё даже по правилам ставятся только в том случае, если их наличие/отсутствие влияет на смысл. В случае все/всё, например, или в именах собственных.
А вот точки над Ё даже по правилам ставятся только в том случае, если их наличие/отсутствие влияет на смысл. В случае все/всё, например, или в именах собственных.
Дело даже не в любителях «андройдов». Как я уже писал: дело в том, что ещё каких-то 100 лет назад буквы «й» не существовало, а знак " ̆" можно было ставить не только над «и». А поскольку Unicode должен позволять набирать не только современные тексты и будет странно если он будет совместим с древнешумерскими текстам, но не будет поддерживать старославянские, то и имеем то, что имеем — всякие чудеса типа ꙝ҇…
Малограмотные граждане без проблем заменяют на «и краткую» и безударное «е».
Взаимозаменяемыми от этого «и», «й» и «е» не становятся.
Взаимозаменяемыми от этого «и», «й» и «е» не становятся.
Да плевать, много или мало в этом грамоты.
Гуманитарии они вообще люди такие, оторванные от реальности.
Вот допустим, у вас интернет-магазин телефонов.
И вот вы анализируете логи поиска и выясняете, что 3% посетителей ищут [нокия андройд]. И дальше вы можете или искать по правилам юникода, или по правилам сложившейся практики.
Ну, если вы владелец магазина, вы, конечно, можете удовлетвориться осознанием собственного грамматического превосходства над этими убогими.
Но если вы всего-лишь разработчик, то, с точки зрения владельца, вы допустили баг, который снизил его доходы с поиска по сайту на 3%. И он имеет полное право вычесть убытки из вашей зарплаты.
Шутки шутками, но битрикс, который требует mbstring.func_overload=2 на этапе установки, многократно окупается уже за счёт этого — относительно джумлы и ворпресса, где в плагинах сплошь и рядом тупорылые вызовы однобайтовых строковых функций.
Гуманитарии они вообще люди такие, оторванные от реальности.
Вот допустим, у вас интернет-магазин телефонов.
И вот вы анализируете логи поиска и выясняете, что 3% посетителей ищут [нокия андройд]. И дальше вы можете или искать по правилам юникода, или по правилам сложившейся практики.
Ну, если вы владелец магазина, вы, конечно, можете удовлетвориться осознанием собственного грамматического превосходства над этими убогими.
Но если вы всего-лишь разработчик, то, с точки зрения владельца, вы допустили баг, который снизил его доходы с поиска по сайту на 3%. И он имеет полное право вычесть убытки из вашей зарплаты.
Шутки шутками, но битрикс, который требует mbstring.func_overload=2 на этапе установки, многократно окупается уже за счёт этого — относительно джумлы и ворпресса, где в плагинах сплошь и рядом тупорылые вызовы однобайтовых строковых функций.
И он имеет полное право вычесть убытки из вашей зарплаты.
Интересная позиция. Этот гипотетический владелец магазина и прибылью наверно с программистами делится тогда, раз считает допустимым убытки с них вычитать?
Ну, в мире эльфов и единорогов — может быть, кто-то действительно и делится.
В том несовершенном мире, который дан нам Господом в объективных ощущениях и строчках ТК — работодатель вправе лишать премии (которая может достигать 40% от зарплаты) за умеренно-некачественное исполнение служебных обязанностей. А вот вопрос начисления плюшек почти всецело отдан на откуп договору между фирмой и сотрудником.
В том несовершенном мире, который дан нам Господом в объективных ощущениях и строчках ТК — работодатель вправе лишать премии (которая может достигать 40% от зарплаты) за умеренно-некачественное исполнение служебных обязанностей. А вот вопрос начисления плюшек почти всецело отдан на откуп договору между фирмой и сотрудником.
Согласитесь, что «лишать премии за умеренно-некачественное исполнение служебных обязанностей» и «и он имеет полное право вычесть убытки из вашей зарплаты» это таки сасем чут-чут разные вещи, да?
Принцип приватизации прибылей и национализация убытков не в России придуман, но почему-то в других странах это считается злом, с которым хотя бы теоретически борются и которое скрываются за всякими хитрыми словесами, а вот в России работодатели как-то даже не понимают почему кому-то этот подход может не нравится. То есть такое ощущение, что они искренне не понимают, что слова «у нас договор сорвался, денег нет» ну никак не могут быть оправданием для «мы тебе только половину зарплату выплатим».
Я, правда, сам это больше десяти лет назад наблюдал (просто прекратив общаться с российскими работодателями), но мои знакомые говорят, что за эти десять лет ничего толком не изменилось…
Принцип приватизации прибылей и национализация убытков не в России придуман, но почему-то в других странах это считается злом, с которым хотя бы теоретически борются и которое скрываются за всякими хитрыми словесами, а вот в России работодатели как-то даже не понимают почему кому-то этот подход может не нравится. То есть такое ощущение, что они искренне не понимают, что слова «у нас договор сорвался, денег нет» ну никак не могут быть оправданием для «мы тебе только половину зарплату выплатим».
Я, правда, сам это больше десяти лет назад наблюдал (просто прекратив общаться с российскими работодателями), но мои знакомые говорят, что за эти десять лет ничего толком не изменилось…
Взаимозаменяемые? А в каких губерниях говорят «йрйдйи» вместо «иридий»?
То что у буквы есть какие-то элементы не связанные с ней непрерывными линиями, не значит что эти элементы нужно выделять в отдельные символы
Ы стоит в стороне и понимающе кивает.
И сколько этих «всех возможных» символов могут иметь ударение?100500, как бы. Лингвистика — интересная наука, но для того, чтобы возможность как-то записывать слова языков, не имеющих письменности требуется изрядно ухищряться.
Плюс все вариации всех гласных из всех языков — с бреве, умляутами и так далее. Плюс заглавные тоже.
Насколько помню, в юникоде есть как буквы с ударением одним codepoint, так и дополнительный codepoint ударения.
А каким браузером и шрифтом вы пользуетесь?
Firefox, Liberation Sans. Такая же проблема под Windows 7 с IE 11 на Meduza, например (у них там PFRegalTextPro-RegularB).
meduza.io/news/2015/06/11/v-gosdumu-vnesen-zakonoproekt-ob-ispolnenii-gimna-rossii-v-shkolah
meduza.io/news/2015/06/11/v-gosdumu-vnesen-zakonoproekt-ob-ispolnenii-gimna-rossii-v-shkolah
del
Буква «й», которую я ввожу с клавиатуры, и котороую просите скопировать вы — разные. Определено экспериментально и при помощи шрифта.
Я всегда думал, может быть наивно, что «и с краткою» вместо однобуквенного «й» вставляет какой-то макосный софт.
Потому что я видел этот символ часто во блогозаписях одного блоггера, о котором достоверно известно, что человек этот — пользователь «Эппл».
Неужели тут всё же не «Эппл», а «Гугл» повинен?
Потому что я видел этот символ часто во блогозаписях одного блоггера, о котором достоверно известно, что человек этот — пользователь «Эппл».
Неужели тут всё же не «Эппл», а «Гугл» повинен?
Вот, честно говоря, полностью не уверен. На маках мы получали нормальную «й», но в интернете я действительно находил сообщения, что на маках такое есть. Правда, они все были старые, лет 5 назад, возможно, что-то поменялось в новых версиях.
А можно ссылку?
От маководов не раз получал zip-архивы, где вместо «й» в имени файла была комбинация «и» и кратки. Так что что-то у яблок не так, как на windows в этом плане.
На маке файловая система (HFS+) использует decomposed unicode, на форточках (например NTFS) — composed. (А на линуксе — как повезет, можно получить обе сразу).
Иногда получаются проблемы — архивы, синхронизация файлов, вот это все. В svn с этим долго боролись в свое время.
Иногда получаются проблемы — архивы, синхронизация файлов, вот это все. В svn с этим долго боролись в свое время.
А на линуксе — как повезет, можно получить обе сразуНа линуксе самый простой и «естественный» подход к именованию файлов. Имя файла — это любая последовательность байт в которой нет символов '/' и '\0'. Что здорово упрощает ядро, но приводит к куче проблем в других местах.
>вот вам фокус: скопируйте ее (букву «й») в блокнот, поставьте курсор в конец буквы и нажмите backspace. Магия, отвал башки просто!
У меня ubuntu, а что не так, объясните? заинтриговали…
У меня ubuntu, а что не так, объясните? заинтриговали…
Не работает, башка (знак краткости) не убирается, буква не превращается в обычное «и»? Что за браузер? Может, особенность IME? В убунту какой, ibus?
Я тоже попробовал, gedit, Ubuntu 15.04. Буква удаляется полностью. ibus выключен.
Я вас не понял
> Не работает, башка (знак краткости) не убирается, буква не превращается в обычное «и»?
я просто попробовал в gedit, и всё норм.
>Что за браузер? Может, особенность IME? В убунту какой, ibus?
мне интересно как это в windows происходит на примере блокнота и не понимаю причём здесь браузер.
> Не работает, башка (знак краткости) не убирается, буква не превращается в обычное «и»?
я просто попробовал в gedit, и всё норм.
>Что за браузер? Может, особенность IME? В убунту какой, ibus?
мне интересно как это в windows происходит на примере блокнота и не понимаю причём здесь браузер.
А, я думал, вы в браузере в поле «ответ» копируете. У меня KDE4, выглядит это так:
a.1339.cf/mbyzyb.webm
a.1339.cf/mbyzyb.webm
mac os x yosemite. не работает.
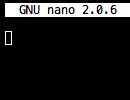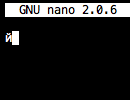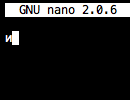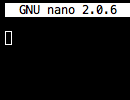

тогда используйте gedit
уже 3 недели мне не приходилось смотреть на уползший умляут
Вот честно — ни разу такого явления не видел.
Вообще если быть дотошным, то эта галочка над й — не умляут, а «кратка» или «бреве» — так по крайней мере википедия утверждает.
А умляуты — они в основном только в немецком встречаются.
Кстати, об умляутах — я уже много лет время от времени вообще смотрю вот на такое:

И еще долго буду смотреть, потому что многим просто не приходит в голову, что кто-то может в Германии включить кириллицу для неюникодных приложений (да, я в курсе про applocale). Хотя казалось бы — юникод уже почти четверть века существует.
Я настолько привык к этим «цffnen» и «schlieЯen», что даже и не замечаю уже — как будто так и надо. А у вас — «галочка уползла», понимаешь…
Вообще если быть дотошным, то эта галочка над й — не умляут, а «кратка» или «бреве» — так по крайней мере википедия утверждает.Спасибо, исправил.
Эх, я как-то с японской локалью сидел, тоже насмотрелся на C:¥Program Files¥
Так там локаль, наверное, японская с SHIFT JIS установлена, только у нее такая особенность
ru.wikipedia.org/wiki/Shift_JIS
ru.wikipedia.org/wiki/Shift_JIS
подобная статья уже была на Хабре. В ней было рассказано все то же самое, примеры с браузерами приводились, причем даже тесты в разных.
Сам в первый раз встретился с подобным не в теории на Ютубе. Скачал ролик, копипастом с ютуба назвал его, а потом натравил на него видеоредактор, а тот не смог файл открыть. Начал я пытаться этот ролик открыть разным ПО до тех пор, пока один не открыл его с такой ошибкой, какая мне помогла вспомнить статью из начала коммента — имя файла исказилось в последней позиции (там тоже должна была быть «й»). Проверил — так и есть: на ютубе в названии фигурировал комбинирующий бреве.
Сам в первый раз встретился с подобным не в теории на Ютубе. Скачал ролик, копипастом с ютуба назвал его, а потом натравил на него видеоредактор, а тот не смог файл открыть. Начал я пытаться этот ролик открыть разным ПО до тех пор, пока один не открыл его с такой ошибкой, какая мне помогла вспомнить статью из начала коммента — имя файла исказилось в последней позиции (там тоже должна была быть «й»). Проверил — так и есть: на ютубе в названии фигурировал комбинирующий бреве.
Хм, если найдете, линканите, пожалуйста. Я не нашел, когда искал.
news.shamcode.ru/blog/sanitize-this-i-search-that автор удален, поэтому статья исчезла — в избранном кусочек текста нашел и загуглил
вот еще подробная статья на эту тематику: habrahabr.ru/post/45489
вот еще подробная статья на эту тематику: habrahabr.ru/post/45489
Спасибо, хорошая статья и информативные комментарии. Обидно, что автора удалили.
Автор я; удалить меня не так просто, но с тех пор все такие статьи пишутся исключительно на английском и выкладываются в места, где нет воинствующей русскоязычной школоты.
По мотивам этой заметки я тогда написал и более-менее полновесную библиотеку для руби, которая умеет композицию и декомпозицию, up-case и down-case, и так далее. Работает с современной версией описаний юникода от консорциума. Если надо — пожалуйста: github.com/mudasobwa/forkforge
По мотивам этой заметки я тогда написал и более-менее полновесную библиотеку для руби, которая умеет композицию и декомпозицию, up-case и down-case, и так далее. Работает с современной версией описаний юникода от консорциума. Если надо — пожалуйста: github.com/mudasobwa/forkforge
Когда я написал комментарий про косяк с «отображением» этой буквы, где-то тут же, меня просто проигнорировали. Мне встречалось такое поведение только на хабре/гике.
Как пишут любители повыпендриваться: «ьi»
А̴̓͗̊͊͗̾̓͆͋͂ͧͥ̐ͭͩ҉̦̠͕͉̗̫̞̀ ̶̘͔̭̟̘͚̬̙̫̥͓͉̭͖͉̟̰̻̠́̂ͦ̿̽̚͜͠е̵̛̮̖̻͕̹̦̟̖̔̆̆̏ͤ̑́͘͝щ͖̖͚̯̖͉̳̪͉̠̝̤͔̠͚̊ͬ͆͂̃͂̇̿ͦͪ̉̋̀̕͢͟͡ё̵̡̛͈̘͚̲̪̼͇ͥ̍ͥ̉ͫ̄̃ͩͭ̓̆ͧ̿̓ͦ͆̌͠͞ͅ ̧̧̢̞̹̟̜̼̮̠̤͍̮̤̱̗͓͛̒̔ͭ̿̒͗ͮ̓̐̒̿͘͜м̺̜͕͉̻̲̝̞͕͙̘̫̉̍͌ͩ͛̀͜оͣ͐̒̓̈͗̏̍ͬͨͨ̑ͮ̌͏̵͚̳̮̦ж̵̸̸ͩ͋̾̉͗̊ͭ̑͌͛̐ͩ͏̩̤͔̰̦͜н̶̑ͥ̿͛̌҉̀҉͖̜̰̲̟̭̪̮̳о̶̱̗̻̲͇͎̩̺͋̇̈́̔͂ͣͩ̍͑ͪ͆̉ͮ̓̅ͮ̒ͨ͢͟͟ ̷̷͉͍͙̔ͭͥ͊̇͊͗̽̒̐ͦ̃ͭ̆ͫ̚̚͠ͅв̢̢̛̩̺̭̻̻̟̳̭̭̘̝̉͗ͯ̚͜ͅсͬ̌͑ͣ̿̅̑ͥ̈́̔̌ͤ̚͞͏͕̬͉͈̰̹͇̪̹̠́́п̶͙̘̜̝̫̻̬͙̟̠̬̠̬̟̣̥̙̣͋̎̋̽͐̈́̑ͮ̅ͯ̐ͮͨͯ̓̚̕о̴͚̜̫͈̮̰̳̀̆̂̊ͬ̀̈́͗͂̐ͧ̂̀ͫ̍͘͜м͗̅͂͐̓̔͊̃ͨ͊͐ͪ̇̂ͥ̒̃͆҉͞͏̨̘͈̲͈̩̟͇̼̦̟̥̗͍̫̟̮н̵̡̟͍͓͕̪̯̱ͩ̅̉͌ͬͦ̇͋̍̎͊͛̇̾̏͊ͧ̚̕и̧̞̼̺̤̹̹͇͉̣̬̩̜̘̲̥̮̫̯̟͂̈̋̑ͭ̈̂͆ͦ̂̑͛ͭ͢т̶̧̧͉͙͍͖̗̦̖̝̥ͮͥ̓̆ͭ̏̉̄̐̚ь̙̲̰̦̪̜̩̻͓͇̰̳̙̗͛ͩͪ̃͑ͬͫͬ̀ͪ͋̈́̋ͫ̓̋́́̚ ̷̮͇̻̦̱̣͕̰̜͎̖̩̜̈̃̃̄̎̆̀ͦ͊͂̊̌̽͆ͤ͆Z̧̞̹͚͕̖̣̝͕ͥͦ̂͋͐̈̈̋̀̍̎̌̑͛̀̓́̌͜Ẳ̴̶͈̰̼͉̬̮͔̝͓̭̟͇̮̣̖̳̰͊̑ͤͪ̀̓̓̽͡L̨̨ͤ͂ͭ͒ͭ́͢҉̶͙͕̩̯̙̙͕̠͙̳͙̲̳̫͍̖͓̭Ǵ̨̛̟̪̦̣͔͔͈͉̤ͨ͗̐̒̓̒͛̂̋̈O̶ͥͫ̒̒ͩ̌̋ͦ̈́ͦ̓̄̽̈́̎́̚͝͏̬͙̣̞
Вы очень
суровы
На какой системе смотрите, интересно?
Артефактов нет
Arch Linux, KDE, chrome 43. В консоли хрома другие артефакты (например, нет черточек вокруг А). То что отрендерилось содержит 32 разлоичных глифа из Arial, 11 из DejaVu Sans и 11 из Liberation Mono. В общем, поддержка такого юникода у меня в шрифтах — так себе.
Ubuntu 15.04, yandex browsr.
Ubuntu 12.04, Gnome, Google Chrome 43 — вижу квадратики вместо некоторых диакритических знаков.
Win 7, FireFox
Судя по количеству символов, которое я вижу:
(тоже firefox, как и у GAS_85, но amd64 Gentoo linux), у вас либо жуткие артефакты, либо зарезана информация.
Все браузеры с “полноценными” движками (gecko, blink, qtwebkit, presto) отображают этот комментарий одинаково, “консольные” браузеры с урезанными движками показывают что‐то непонятно.
Скрытый текст
(тоже firefox, как и у GAS_85, но amd64 Gentoo linux), у вас либо жуткие артефакты, либо зарезана информация.
Там же, chromium
Там же, старая Opera
Все браузеры с “полноценными” движками (gecko, blink, qtwebkit, presto) отображают этот комментарий одинаково, “консольные” браузеры с урезанными движками показывают что‐то непонятно.

>смотреть на уползшую кратка.
Слово-то склоняется. «Кратку»!
Слово-то склоняется. «Кратку»!
Первый раз столкнулся с уехавшей краткой именно на Маке, так что привычно виню скорее его, чем Google Docs.
Раньше этим еще грешил Adobe Acrobat. Например при копировании из него в Word, «й» вставлялась как 2 отдельных символа, причем Word тогда некорректно это обрабатывал и знак «кратка» съезжал. Приходилось постоянно за этим следить, особенно во всяких курсовых и прочем, где могли придраться.
Если кратка уползает, то это по большей части вина определенного шрифта.
Попробуйте в том же блокноте с текстом с этой «й» «поиграться шрифтами».
Много интересного можно увидеть.
Попробуйте в том же блокноте с текстом с этой «й» «поиграться шрифтами».
Много интересного можно увидеть.
Йопт!
Внимание!!! Найдена «ё» (CYRILLIC SMALL LETTER IE + COMBINING DIAERESIS) в большом количестве!
habrahabr.ru/company/yandex/blog/250753
Написал автору публикации, может сможет вспомнить, какая ОС и софт использовался.
habrahabr.ru/company/yandex/blog/250753
Написал автору публикации, может сможет вспомнить, какая ОС и софт использовался.
Я тут всрпомнил, что когда-то обращал внимание на «красивенькие» кавычки в каком-то топике. И нашёл, и бинго! Буква й там составная! Человек использовал некий iA Writer. Кстати, в топике по вашей ссылке тоже такие кавычки есть.
Видимо, вот это: iA Writer. Есть для MacOS, iOS и Android. Интересно, зараза свойственна конретному редактору или это свойство какой-то библиотеки которую они применяют и есть другие приложения с такими же свойствами.
На их сайте в справке интересная информация тут. Похоже, эти замены делает таки OSX.
Хм, там нет составных й.
Мда… недавно боролся с неразрывным пробелом в тексте отчаянно, а тут оказывается еще интереснее всё.
Проблема в полный рост в статье на Lenta.ru (проявляется в Firefox 40 и IE 11). В браузерах на основе Chromium (например, Opera 30 и Яндекс.Браузер) не проявляется, и поиск по странице работает корректно.
Линукс, FF, mousepad — все композитные символы рисуются нормально и удаляются за единый бэкспейс.
У картинки с заголовком статьи на хабре тоже кратка уезжает:
twitter.com/ValdikSS/status/1151201065800519681
twitter.com/ValdikSS/status/1151201065800519681
Исправили, похоже.
Хабр читают, поди.
Я им отправил сообщение об этой проблеме 16 числа. Быстро исправили. Кеш картинки в твиттере уже истек, теперь там кратка не уезжает.
Что такое кратка?
Кра́тка (ранее кра́ткая); также бре́ве (лат. breve «короткое»), бре́вис, дуга́ — один из[1] кириллических и латинских надстрочных чашеобразных диакритических знаков; заимствована из древнегреческой письменности, где означала краткость гласных. В типографике различаются кириллическое бреве и латинское бреве: как правило, первое имеет утолщения по краям, второе — в середине
Буквально нарвался на такую проблему. Была база, которая работала и с MSSQL, и с PostgresSQL. И таблица нормализации словаря по отдельным словам. В таблице словаре было слово «русский» два раза, один раз нормальное одиночное й, в другом два символа сама буква и глиф. Расчет был, что два слова разные и будут ловить каждое свой случай. В итоге MSSQL их принимал за разные слова и работал нормально, а Постгрес считал за одно и при JOIN значение в запросе двоились и цифры начинали сильно расходиться
тут даже претензия не в том, что работает так, или так, а в том, что в разных системах по разному поддерживается обработка таких символов. и если не знать и заранее не забиваться на конкретную СУБД, то могут быть такие неожиданности :(
тут даже претензия не в том, что работает так, или так, а в том, что в разных системах по разному поддерживается обработка таких символов. и если не знать и заранее не забиваться на конкретную СУБД, то могут быть такие неожиданности :(
Sign up to leave a comment.
«Й» вам не «и» краткое! О важности нормализации Unicode