Comments 114
Утилиты типа R-Studio файлы там находят, но хотелось бы не по отдельности файлы копировать, а прямо из копии сразу всю файловую систему восстановить, если такое возможно.
О, у меня где-то валяется диск, в котором, похоже, что-то случилось с основной копией файловой системы NTFS (при некорректном выключении внешнего контейнера, видимо), но я так понимаю, у неё ещё должны быть ведь копии.
чтобы говорить, что именно пострадало необходимо скрупулезно проанализировать повреждения ключевых структур. В случае NTFS — ключевая структура $MFT. $MFT mirror — это копия первых 4 записей $MFT.
Нет ли какой-то простой утилиты, которая может по этим копиям увидеть сразу все файлы, чтобы потом всё скопировать куда-то?
обратите внимание на то, что написано в разделе про типичные случаи, в частности про повреждение файловой системы. Там даны рекомендации.
Утилиты типа R-Studio файлы там находят, но хотелось бы не по отдельности файлы копировать, а прямо из копии сразу всю файловую систему восстановить, если такое возможно.такое возможно, главный инструмент шестнадцатиричный редактор и глубокое знание структур файловой системы. В большинстве случаев это нецелесообразно, так как работа специалиста и затрачиваемое время на ручные реконструкции обойдется в большинстве случаев дороже стоимости лицензии той же R-Studio.
И настоятельно не рекомендуется искать «быстрые» варианты. Лучше озадачиться безопасностью процесса во избежания дальнейшего кусания собственных локтей.
Как насчёт TestDisk?
Если диск издает пищащие звуки попытки раскрутиться, и не стартует, то кроме вышеприведенных причин, хочу отметить просадку питающего напряжения, (зачастую из-за плохого контакта, окисления разъемов, переходники низкого качества, блок питания не вытягивает.) Причем такая неисправность может быть непостоянной: один раз все нормально запускается, другой раз диск не видит. Или жёсткий диск может нормально работать, но при интенсивных операциях отваливаться и вешать систему.
Удостоверьтесь в исправности вашей тестовой системы, во избежание постановки неверных диагнозов и если не обнаружилось каких-то внешних причин, препятствующих попытке старта, то подключите интерфейсный кабель и кабель питания к соответствующим разъемам и включите БП.
В этой статье будем предполагать, что тестовый ПК совершенно исправен и рассматриваем только проблемы самих жестких дисков и способы их решения.
Нередко дефекты приходятся на метаданные файловой системы. В этих случаях ОС при попытке монтировать поврежденный том надолго замирает. При подключенном проблемном накопителе время загрузки ОС может растянуться на десятки минут. Одна из самых неудачных идей по решению этой проблемы – форматировать проблемный раздел. Вновь созданные метаданные могут записаться корректно, и проблема долгой загрузки ОС будет решена, но задача восстановления данных усложнится, а качество результата восстановления может сильно пострадать.
1-в-1 моя проблема, и я допустил именно такую ошибку. Как бороться с диском, если любые обращения к нему в лучшем случае просто отваливаются по таймауту через сколько то там минут, а в худшем — подвешивают ОС?
1. необходимо отключить процедуры оффлайн-сканирания.
2. оценить состояние каждой из головок.
3. построить карту зонного распределения
4. с малым таймуатом начать поочередное чтение минизон с пропуском оной при первом же обнаружении нестабильности.
5. учитывая, что вы отформатировали раздел, то придется анализировать предполагаемые места расположение старых метаданных, чтобы в первую очередь попытаться добыть из проблемных зон.
если накопитель накопитель зависает напрочь при обращении к дефектам, то в домашних условиях крайне низкая вероятность получить из него образ для дальнейшего анализа. После упорных мучений скорее получить стучащий жесткий диск с горсткой металлических опилок в гермоблоке. Хотя если вы намеренно готовы идти до конца, то можете сканом локализовывать дефекты и пытаться начитывать образ кусками и после собрать все воедино в том же WinHex.
В ОС Windows для этого с правами администратора нужно запустить diskpart и выполнить команду automount disable. Если потенциально проблемный диск ранее подключался к данной ОС, то необходимо удалить параметры монтирования из реестра командой automount scrub. Для вступления данных настроек в силу рекомендована перезагрузка.
Сохранил себе в блокнот, чтобы если что, всегда было под рукой!
Я для снятия образа диска люблю использовать ddrescue — это dd переписанный для копирования информации с проблемных дисков. У него много настроек, например можно после появления первых ошибок чтения, читать диск с конца, и тем самым максимально быстро скопировать 99.9% диска. А потом, к примеру, оставить оставшиеся 0.01% на ночь и довести количество «спасённых» даных до 99.99%
Я помню у меня был диск который намертво вешал систему при загрузке и отваливался при попытке доступа при подключении через USB-адаптер. Загрузка с флешки и считывание с конца с помощью ddrecue позволили скопировать диск целиком, там что-то около 4 килобайт только не прочиталось, ни одного важного файла по факту не пострадало.
Я для снятия образа диска люблю использовать ddrescue — это dd переписанный для копирования информации с проблемных дисков. У него много настроек, например можно после появления первых ошибок чтения, читать диск с конца, и тем самым максимально быстро скопировать 99.9% диска.
К сожалению — это все равно средство для копирования дисков с незначительными проблемами. Диски с дефектами полученными в результате контакта какого-либо из слайдеров с поверхностью пластины как правило имеют совсем не точечные дефекты. А прыжки в конец LBA диапазона на каком-либо Seagate Grenada с дефектами и вовсе могут стать последним, что будет в его жизни.
Я помню у меня был диск который намертво вешал систему при загрузке и отваливался при попытке доступа при подключении через USB-адаптер. Загрузка с флешки и считывание с конца с помощью ddrecue позволили скопировать диск целиком, там что-то около 4 килобайт только не прочиталось, ни одного важного файла по факту не пострадало.Ваш пример весьма наглядно подтверждает незначительность проблемы диска. Достаточно отключить автоматическое монтирование в ОС, чтобы подобные диски не вешали ее намертво при загрузке и далее вычитывать любым удобным средством.
По возможности никогда не стоит читать проблемный диск через USB-SATA мост так как со многими из них можно получить дополнительных ворох проблем.
(Мне как-то удалось прочитать винчестер, который не запускался по обычному SATA, через USB-SATA от внешнего винчестера. Вероятно, сыграла какая-то другая логика в последовательности инициализации).
1. выдача мусора вместо данных.
2. при попытке перезаписи некоторых метаданных возможны записи со сдвигами. (а при монтировании под Windows не так и мало пытается переписать.
Мне как-то удалось прочитать винчестер, который не запускался по обычному SATA,
В статье написано, что нужно отключить автоматическое монтирование и убрать все MountPoints в реестре ОС. Всего лишь две команды в diskpart. После этого ОС не будет автоматически монтировать проблемный накопитель при загрузке и соответственно не будет зависания.
Интересно, но я бы всё-таки сначала делал бы посекторную копию с игнорированием ошибок чтения,
В случае различных копиров различных доступных пользователю утилит можно совсем не сразу заметить дефекты и пропустить немало секунд. В случае некоторых видов дефектов это будет смерть диску. При верификации На графике в первую секунду можно заметить остановку сканирования и обесточить, также можно увидеть многие проблемы в виде полудохлых головок до подхода к реальным дефектам и вовремя остановиться. Заметьте, что в статье написано о том, что этот скан нужно делать не отходя от накопителя.
особенно если данные важны. Как только диск попадает в руки — делай копию.Если данные очень важны, то лучше не переоценивать свои силы.
При обнаружении признаков дефектов еще на этапе просмотра SMART лучше остановиться, особенно с современными дисками. Так как в домашних условия вряд ли вам удастся отключить оффлайн-скан, SMART, процедуры реаллокации, количество повторов чтения дефекта микропрограммой и т.п. Отсутствие всего этого вмешательства на дисках с проблемами серьезнее точечных дефектов создает дополнительные немалые риски из-за которых накопитель может слишком скоропостижно скончаться.
В результате сбоев компонентов ПК, некорректной работы ОС, внезапного обесточивания во время записи на диск, неисправностей жесткого диска могут оказаться поврежденными метаданные файловой системы.
Один раз получил RAW-раздел, воткнув внешний хард в дефектный USB-порт. По SMART всё было хорошо, на физическом уровне диск был здоров, пострадала именно файловая система. Тогда ни одной из платных утилит, включая пресловутую R-Studio, восстановить не смог и смирился с потерей, отформатировав раздел. А уже потом узнал про бесплатную программу TestDisk, которая не раз выручала при аналогичных проблемах, даже когда диск начинал сыпаться. Но я не спец в этом деле, поэтому было бы интересно еще узнать мнение автора статьи и других сведущих в этой области людей о TestDisk и других бесплатных аналогах. Кстати, было бы интересно увидеть в качестве продолжения статью со сравнительным обзором таких утилит, как платных, так и бесплатных
Один раз получил RAW-раздел, воткнув внешний хард в дефектный USB-порт. По SMART всё было хорошо, на физическом уровне диск был здоров, пострадала именно файловая система. Тогда ни одной из платных утилит, включая пресловутую R-Studio, восстановить не смог и смирился с потерей, отформатировав раздел.
В случае проблемных USB коробок можно часто получить запись мусора или сдвинутых данных (сдвиг не кратен размеру сектора) В таких случаях многие утилиты автоматического восстановления бессильны. Требуются ручные правки в шестнадцатеричном редакторе, если конечно есть что исправлять.
восстановить не смог и смирился с потерей, отформатировав раздел.в любом случае метод поиска нужных регулярных выражений помог бы найти вам данные на исправном диске с убитой файловой системой.
А уже потом узнал про бесплатную программу TestDisk, которая не раз выручала при аналогичных проблемах, даже когда диск начинал сыпаться.на текущий момент вы можете говорить лишь об аналогичной симптоматике проблемы. Какая именно проблема была у в вашему случае вы же так и не узнали. Перечисленные возможности TestDisk весьма скромны. Найти удаленный раздел сможет, переписать 4 записи из MFT Mirr в основную копию тоже сможет, попытаться скопировать удаленные файлы без контроля целостности на основание останков метаданных в некоторых файловых системах сможет, скопировать boot NTFS, FAT32 из копии тоже. Как-то очень скромно, чтобы рассматривать это как серьезный инструмент. Скорее утилита для быстрого получения доступа к данным в случаях «если не получилось, то бог с ним».
Кстати, было бы интересно увидеть в качестве продолжения статью со сравнительным обзором таких утилит, как платных, так и бесплатныхучитывая обилие различных средств восстановления со схожим функционалом и возможностями не хватит жизни все проверить на разных случаях, чтобы написать какой-то обзор. Кроме этого нужно учесть, что развитие этого всего ПО не стоит на месте и по мере тестирования на образцах актуальность описания возможностей будет устаревать.
Лучше понимать какие методы можно применить в том или ином случае и как направить утилиту автоматического восстановления в нужное русло.
По моему опыту, ситуации порчи MFT, загрузочных секторов или случайного удаления важных файлов встречаются много чаще, чем физическое повреждение диска или сбой контроллера, поэтому для простых пользователей или выездных мастеров, занимающихся всем подряд, в т.ч. и восстановлением данных, TestDisk или, например, Recuva — это вполне подходящие инструменты.
При этом стоит всегда помнить, что не стоит пытаться лечить перелом прикладыванием подорожника, поэтому ваша статья — просто отличная памятка/инструкция, как определить — можно ли что-то сделать своими силами, или лучше не трогать диск и сразу нести его вам, если данные критичны, или выкидывать, если данные не важны/есть резервная копия.
При этом стоит всегда помнить, что не стоит пытаться лечить перелом прикладыванием подорожника, поэтому ваша статья — просто отличная памятка/инструкция, как определить — можно ли что-то сделать своими силами, или лучше не трогать диск и сразу нести его вам, если данные критичны, или выкидывать, если данные не важны/есть резервная копия.
Именно для этого она и написана, чтобы многие могли уяснить, что можно пытаться делать, а когда лучше не стоит.
По моему опыту, ситуации порчи MFT, загрузочных секторов или случайного удаления важных файлов встречаются много чаще, чем физическое повреждение диска или сбой контроллера, поэтому для простых пользователей или выездных мастеров, занимающихся всем подряд, в т.ч. и восстановлением данных, TestDisk или, например, Recuva — это вполне подходящие инструменты.
Я не говорю, что они совсем негодные инструменты. Но стоит лишь ограничить их применимость исходя из возможного нанесения вреда. К сожалению современные диски очень уж хрупкие устройства.
Починил chkdsk d:\ /F
Но тут я знал, что затупил. И знал, что диск физически исправен
Знаю много случаев, когда людидемонтировали смд при помощи кисточки, или пропарывали плату отвёрткой.
Соглашаясь на следование дальнейшим инструкциями, вы осознаете, что никто кроме вас самих не несет ответственности за возможный выход из строя накопителя и безвозвратную потерю данных. Набор мер направлен на снижение вероятности наступления неблагоприятного исхода, но не страхует от него на 100%.
Так дано ж предупреждение. До начала диагностических мероприятий.
подскажите виндовую прогу, которая по номеру сектора скажет, какому файлу он принадлежит, включая служебные файлы NTFS.
В профессиональных комплексах можно строить цепочки расположения файлов и сортировать их по порядку расположения.
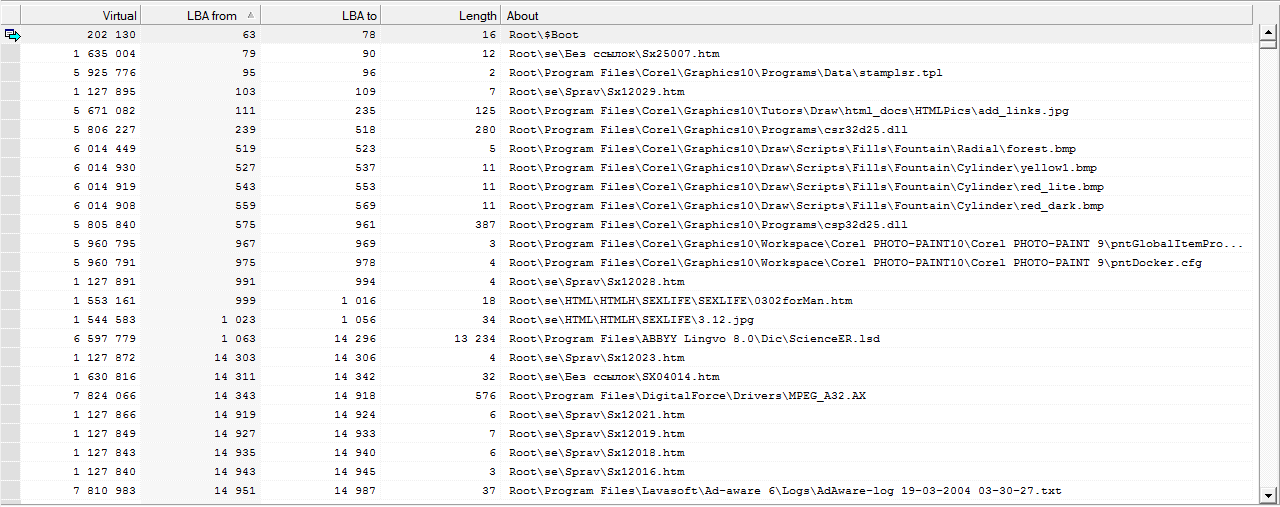
Также профессиональные комплексы позволят построить отчеты со списком не полностью прочитанных файлов и позволят скопировать данные с разделением на битые и не битые.
NFI на сайте Микрософта уже не было, но я где-то нашёл.
спасибо, дружище! это то, что надо. по ссылкам нашел на superuser.com более полный ответ.
Спасибо за статью. Напомнила мне пойти проверить, как делаются бекапы :)
Как организовано хранение важной информации у юриков — ну там есть следы рейдов, или все по старинке — вся критичная инфа хранилась на одном ЖД в бухгалтерии?
А кто чаще являются клиентами — физики потерявшие коллекцию фоток с отпуска или юрики у которых там базы 1Ски? Точнее кто соглашается на услуги, узнав стоимость восстановления данных.
Услугами интересуются и физические и юридические лица. Ценовая политика такова, что многие услуги доступны гражданам с текущим уровнем заработных плат в нашем регионе. После бесплатной диагностики клиент принимает решение о целесообразности получения услуги исходя из ценности своей информации.
Как организовано хранение важной информации у юриков — ну там есть следы рейдов, или все по старинке — вся критичная инфа хранилась на одном ЖД в бухгалтерии?хватает случаев, когда данные не хранились на одном диске, а был RAID массив. Естественно, что нашими клиентами становятся те, кто хранил важные данные в одном экземпляре.
Я как-то читал заметку (может даже тут) о бесполезности RAID-массивов. Суть сводилась к тому что если один диск отправился на небеса, то при попытке восстановления на остальные создается большая нагрузка и высок шанс гибели следующего.
Рассуждать можно по разному.
1. Если имеем отказоустойчивый массив например 1,5, 6 (или комбинированые 10, 50, 60) то в случае отказа одного диска у нас есть шанс скопировать информацию, а далее попытаться восстановить целостность массива посредством ребилда. И все это можно выполнить без остановки сервера. В случае отказа одиночного диска будет и остановка сервера и необходимость восстановления данных.
2. Для обработки некоторых данных требуется быстрая дисковая система. В таких случаях RAID 0 выход. Но надежность в n раз хуже одиночного диска. (где n количество дисков в массиве)
3. Также могут потребоваться хранилища данных более емкие, чем маскимально доступные в продаже диски RAID 0, JBOD позволят вам создать такое хранилище.
Можно подытожить, что польза от RAID массивов есть, главное понимать для чего они и чего от них ожидать.
А если учесть вероятность кодирования данных вирусятиной, то гораздо проще иметь бэкап.наличие RAID массива не освобождает системного администратора от регулярного резервного копирования. Как и не освобождает пользователя, который задумался о сохранности своих данных.
Исключение произошло. Никто не заметил этого и два года работали на одиночном диске не проверяя целостность массива.
Итог закономерен.
Я бы вообще не был так категоричен. RAID0 вообще снижает отказоустойчивость. RAID — это скорее метод построения дисковой подсистемы, решающий определенные задачи пользователя в зависимости от конфигурации. В данном случае я просто обратил внимание, что иногда теория немного проигрывает практике.
Сохранность данных на одном диске равна вероятности его отказа. Сохранность данных на зеркальном массиве равна произведению вероятностей отказа, т.е на порядок выше. Еретичный страйп разумеется выбивается из этой картины, поскольку наоборот снижает вероятность сохранности данных в количество_дисков_в_массиве раз. Но да, вживую я его тоже нигде не видел, особенно при нынешних реалиях когда скорость доступа к схд решается ссд и nvme дисками.
Ну и да, есть сценарии когда бэкап вообще невозможен, а сохранность обеспечивается большим фактором репликации.

В данном случае я просто обратил внимание, что иногда теория немного проигрывает практике.
Если с теоретической частью все хорошо, то она не расходится с практикой. Граждане, имеющие завышение ожиданий от RAID массивов, обычно не в полной мере понимают теорию и влияние внешних факторов.
В результате, после его замены, массив по-живому перестраивался несколько днейВремя перестроения никак не зависит от того, был ли в массиве hot-spare диск, или он уже задействован. Зато оно зависит от приоритета, выставленного задаче перестроения.
Если у меня в полке без spare вылетает диск, то рейд теряет избыточность и мне нужно ехать в ЦОД и менять его. Если spare есть то данные ребилдятся на него и массив продолжает штатно функционировать, а сдохший диск я могу поменять в удобное время при плановом визите в ЦОД.
Вышедший из строя контроллер тоже не должен уносить с собой данные(теряется доступность, а не данные), разумеется надо иметь в зипе такой же. А при двухконтроллерных решениях даже доступность не пострадает
PS за Бэкапами тоже следить надо. Если люди не могут заменить вышедший из строя диск в массиве, навряд ли они следят за тем выполняется ли резервное копирование в принципе. Не говоря уж о проверках разворачиваются ли потом эти бэкапы и их консистентности
А что касается бэкапов — да, был на той работе и такой случай, когда сервер умер, а бэкап базы из zip архива не распаковался. Хотя архивы делались регулярно, но их, конечно же, никто не проверял. То ли место кончилось, то ли что произошло, но свежий архив оказался битым, восстанавливались в итоге из базы месячной давности или что-то типа того.
На ссд, в целом, 5 рейд — вполне приемлемый вариант, но тут очень холиварная территория начинается.
У ssd насколько я понимаю обычно дохнет контроллер,
в подавляющем большинстве случаев он жив. Что с ним может статься. Посудите логически — это же обычный MCU, там ничего не изнашивается так явно, чтобы просто так умирала микросхема.
а он у каждой серии дисков может быть уникальный, поэтому восстановить данные потом бывает проблематично — микросхемы с памятью может и уцелели, но как именно их читать знает только конкретный контроллер.
MCU (контроллер) совершенно не уникален. Да там, есть небольшой boot ROM но его содержимое будет одинаково для огромного количества дисков. Проблемы SSD в подавляющем большинстве случаев кроются либо в NAND памяти, либо в повреждениях модулей служебки записанных в NAND.
Если найдётся подходящий контроллер-донор, то можно и восстановить, но может и не найтись.
в 99% случаев для мертвых SSD нет нужды искать донорский контроллер. Как правило работа в технологических режимах с поиском структур ответственных за трансляцию с дальнейшим чтением «по физике» в порядке установленном найденными и разобранными структурами. Либо для некоторых SSD применим метод распайки на микросхемы, чтение и дальнейший разбор алгоритма (можно посмотреть пример на простой USB flash, в случае SSD все будет несколько сложнее)
Посмотрел ценники на то, что хочется — решил собирать Nas самому, как раз материнка с процессором и памятью дома валяется без дела.
Да здравствует Хабр!
Можно ли считать диск не исправным если нету проблем в работе, но есть потрескивание при его работе, особенно когда торрент выключается.?
З.Ы винты уже довольно старые, Хитачи 2009 и 2012 года)
Забыли написать ещё, что такое жёсткий диск для чего и где находится.
И так уже планируемая коротенькая инструкция раздулась до неприличного размера.
Это ST100LM035. Объем «безумный» показывает всё ПО, работающее с дисками. Некоторое ПО показывает даже отрицательный объем.
Мне тут попался 2.5 HDD от Seagate на 1TB,
Говоря о дисках хорошо бы указывать модель, тогда будет понятно о чем идет речь и какие у предмета разговора могут быть общие проблемы.(Например в случае Seagate ST1000LM035 (семейство Rosewood), ST1000LM014(kahuna), ST1000LM010 (Sentosa) и т.п. )
вдруг стал определяется как 76 петабайт. Такое уже в домашних условиях не решается, возможно даже не решается в принципе.
Важно понять где он стал 76PB. Если в паспорте, то необходимо анализировать его миропрограмму. Если это записался бредовый размер в GPT и оснастка Windows показывает такую емкость, вряд ли это представляет серьезную проблему.
Чтобы работать напрямую с диском и считать паспорт при помощи PC3000 DiskAnalyzer я подключил жесткий к настоящему SATA интерфейсу, но в таком случае из под Windows он виден только в оснастке «Управление дисками», причем как неизвестный неинициализированный диск.
Другое ПО для управления дисками в Windows, включая PC3000 DiskAnalyzer, его таким образом не видит вовсе, его просто нет в списке. В диспетчере устройств он отображается, но вместо его названия он указан как «Неизвестное устройство».
В свойствах диспетчера устройств объём указан 0. Двигатель диска работает, ощущается вращение, никаких посторонних звуков нет, но нет и звуков перемещения головки. Но в начале, во время запуска системы, головка перемещается субъективно абсолютно нормально, без каких-либо зацикливаний, ничем не выделяясь среди других, подключаемых таким же образом 2.5 дисков.
В этих дисках нередко оказывается нечитабельной таблица MediaCache. Симптоматика такова, что накопитель может выйти в готовность и даже отдать сразу паспорт, но на попытки чтения ответит «ABR» (отбоем команды).
В этих случаях, как правило требуется вмешательство в микрокод. Вычитывание обеих копий таблиц и дальнейшая реконструкция. После чего накопитель можно будет вывести в готовность и осторожно приступить к вычитыванию дефектов.
Просто сбросить таблицу и очистить медиакеш не стоит. Так как он работает по принципу: сначала запись в медиакеш, а потом уже накопитель запишет это в основную юзерзону, когда это заблагорассудится сделать его микропрограмме.
В домашних условиях этого сделать не получится.
76 петабайтКстати, 76,861 * 1015 = 0x0111 1111 1111 1111
1) неоднократное включение и «слушание» шума раскрутки диска на предмет плавно нарастающего, а затем «ровного» гула
2) просмотр смарта и тест поверхности викторией с анализом статистики распределения блоков по откликам и «ровности» графика скорости чтения
3) полумесячная\месячная работа (неважно под/без нагрузки)
3) снятие контролера с зачисткой контактов (да — это лишение гарантии)
Один раз мне не понравилось то, как диск раскручивался. Он работал. Но исходя из моего опыта (скажем так, сотня дисков «отслушана») было что-то «не то». Диск был оставлен на неделю в ПК, через три дня успешно загнулся (при включении раскручивался с таким звуком и вибрацией, словно там диски неотбалансированные были) и я его обменял по гарантии. Другой раз диск у меня сдох в процессе теста викторией. Видать не выдержал нагрузки. Тоже заменили.
Ну а зачистка контактов ластиком — я не знаю из чего сейчас эти контакты делают, но не раз видел неслабые окислы прям из магазина! У древнего 40гигового сигейта таких проблем до сих пор не наблюдается! Поэтому зачистка контактов у меня идёт как профилактика раз в 3-4 года.
По поводу использования Windows для восстановления данных: ValdikSS описывал ситуацию, в которой Windows исправляла намеренно некорректные MBR DiskSignature, что ломало работу защиты. https://habr.com/ru/post/304014/
Делает ли Windows это или что-то подобное при отключенном автомонтировании?
Бегло глянул в статью. Как бы на дисках с GPT и с наличием защитной MBR по 0x1B8 обычно нули и windows не порывается заниматься самодеятельностью.

Что касается Acronis то его клонирование дисков часто не является честной посекторной копией. И номер в 0x1B8 в копии зачастую другой. В старых windows это не приводило к отказу загрузки. Для Windows Vista и выше как правило bootmgr вылетает с ошибкой «Status: 0xc000000e Info: The boot selection failed because reqired device is inaccessible»
Попробовал в Windows7, происходит именно так, как описывал ValdikSS:
- Выключил автомонтирование
- В линуксовом fdisk создал MBR с одним пустым разделом и занулил идентификатор MBR (x->i->0)
- Загрузил и выключил Windows
Вместо нуля оказался записан новый идентификатор.
Интересно, как от такого поведения избавиться, сколько ещё подобной самодеятельности делает Windows и не может это повредить и без того дохлому диску?
Подскажите пожалуйста, какая из перечисленных программ способна корректно открыть RAW образ диска, если к нему прилагается лог с поврежденными секторами (большинство которых приходится на $MFT). Лог создан программой ddrescue и при необходимости его можно легко изменить под другой формат.
1. Если живы первые записи MFT или цела MFT mirr то будет достаточно просто сканировать все записи MFT и не сканировать весь раздел, чтобы увидеть возможное древо каталогов.
2. Если первые записи MFT убиты и копия MFT mirr тоже, то потребуется полный скан раздела, чтобы найти все фрагменты MFT и после уже разбирать, что относится к актуальным записям.
можете попробовать R-Studio, DMDE в первом случае просто раскрыть раздел, а во втором с полным сканом.
Для всего этого ПО лог от ddrescue не будет полезен. Полезным он будет лишь на дальнейшем анализе повреждений файлов.
А найти поврежденные файлы среди восстановленных не составило труда. Достаточно было на место поврежденных секторов RAW образа записать произвольный паттерн, после чего обнаружить его среди восстановленных файлов (предварительно убедившись, что этого паттерна нет в образе).
Проблема как раз в том, как заставить R-studio (или другую программу) интерпретировать часть секторов, как физически недоступные.
а смысл? Ведь если в местах пропусков в вашем образе нули или какой-то паттерн, но не куски чужой MFT, то на качество сканирования не повлияет. Если нужные данные не находятся при анализе метаданных, то кроме поиска регулярных выражений по нужным типам файлов вам ничего не светит.
Рекомендую добавить расшифровки и краткие пояснения специфичных терминов/аббревиатур (БМГ, коммутатор-предусилитель, парковочная рампа...) при первом их упоминании. Или ссылку на статью, если уже где-то описывали.
Тем, кто читает ваши статьи не в первый раз, все эти термины уже понятны, а вот остальным требуется пояснение. Как вариант — просто картинку разобранного HDD и стрелочки-подписи. Думаю, большинство хабровчан представляет HDD в разобранном виде, но вот терминология явно будет нова, или могуть быть ошибочные представления.
Еще моменты:
— 3.3v на SATA. В новых энтерпрайзных дисках вывернули наизнанку — наличие 3.3v стопорит накопитель. Пока в массе выглядит как «купил HDD, а он не включается», но возможны и случаи «HDD работал, а переставил — и не запускается»
— процесс восстановления/копирования образа в принципе гораздо лучше делать в Linux (если конечно консоль и dd не пугает, хоть и с гуглежкой), открыв в соседнем окне dmesg -w. Там, где винда зависает наглухо, в лине копирование может вполне успешно продолжаться после таймаута и/или пропуска сбойного места, с возможными подробностями в dmesg. Еще спецэффекты от сбоев сильно зависят от контроллера SATA.
— процесс восстановления/копирования образа в принципе гораздо лучше делать в Linux (если конечно консоль и dd не пугает, хоть и с гуглежкой), открыв в соседнем окне dmesg -w. Там, где винда зависает наглухо, в лине копирование может вполне успешно продолжаться после таймаута и/или пропуска сбойного места, с возможными подробностями в dmesg. Еще спецэффекты от сбоев сильно зависят от контроллера SATA
Весьма спорно, что это лучше. Если диск зависает, то лучше его линейно не читать во избежание получения фактурных пластин с кучей металлической пыли. Кроме этого главная проблема зависаний Windows в попытке монтировать раздел на проблемном накопителе. После отключения этой опции Windows ведет себя более адекватно.
Рекомендую добавить расшифровки и краткие пояснения специфичных терминов/аббревиатур (БМГ, коммутатор-предусилитель, парковочная рампа...) при первом их упоминании. Или ссылку на статью, если уже где-то описывали.добавлю расшифровку аббревиатур в ближайшее свободное время. мое упущение.
Уже несколько раз натыкался на SSD диск, который при заполнении больше ~95% начинает выдавать ошибку чтения блоков. Ошибочных блоков со временем становится все больше и больше. Проблема не исчезает, если свободного места добавить. После клонирования такого диска, сбрасываю его с помощью метода «ssd secure erase» и диск снова как огурчик.
Почему так происходит? И как такого избежать? (была идея создавать раздел не во весь диск, но проверить руки так и не дошли)
Уже несколько раз натыкался на SSD диск, который при заполнении больше ~95% начинает выдавать ошибку чтения блоков. Ошибочных блоков со временем становится все больше и больше. Проблема не исчезает, если свободного места добавить. После клонирования такого диска, сбрасываю его с помощью метода «ssd secure erase» и диск снова как огурчик.
Износ NAND памяти. При полном заполнение в работу вступит почти вся память, в том числе и блоки которые перенесли большое число записей. Просто удаление файлов не обязательно приведет к исключению проблемного блока из транслятора. Security Erase обрабатывается микропрограммой так: очистка NAND и сброс транслятор и по мере заполнения использовать блоки с минимальным числом записей.
И как такого избежать? (была идея создавать раздел не во весь диск, но проверить руки так и не дошли)
Замена SSD. Создавать меньший раздел можно, но все больше и больше будет блоков с проблемными страницами. И все равно проблема начнет проявляться раньше и раньше. А если проблемный блок попадется на служебку (на те же структуры транслятора), то ваш SSD сразу превратится в кирпич после рестарта.
Самостоятельная диагностика жестких дисков и восстановление данных