Comments 195
Прочитайте пожалуйста статью о том как вести бизнес в России — ту часть, что про сервера.
А так сочувствую коллеге…
Если клиенты российские, да ещё и персональные данные, то вообще без вариантов
Вполне с вариантами. По ФЗ можно и за пределами держать при условии копии в пределах РФ.
Кушайте, не обляпайтесь.
Апричом tyt «Россия»?
Мягко говоря, наоборот. Никакого облака, Очень Ценный сайт на шаред-хостинге без внешних бэкапов.
Айхор же как раз больше по VDS и выделенным сервакам, они не так сильно на шаред заточены были.
amarao (смею предположить) имел в виду, что облако — подразумевает разные регионы, репликацию, failover, наконец.
А шаред он там, или прям целый выделенный VDS — никакого значения не имеет, все равно это как пентиум три под столом.
Но тут каждой задаче свой инструмент, хочешь максимальной КОНТРОЛИРУЕМОЙ доступности — строй себе сам, хочешь экономии — отдавай в аутсорс, верь красивым обещаниям но потом не плач (или изначально закладывай риски в проект).
Скажите, люди, которые теряют сайты и множественные посещения важных клиентов, они головой думали?
Как насчёт cloud native с декларативной инфраструктурой, которая в единицы (десятки) минут разворачивается на любом IaaS?
Не слышали? Ищите IT-персонал, который такое может сделать. не можете? Ну, вы знаете, куда надо уходить с рынка после потери всех полимеров.
cloud native приложения работают с cloud как с коммодити, а не как со священным граалем. Это означает, что приложение воспроизводится из гита как на aws, так и на openstack, так и на пачке бареметаллов у которых есть плагин для терраформа.
В зависимости от бюджета, либо из холодного ежемесячного бэкапа, либо из горячего off-site ежечасового бэкапа, либо там настроена cross-site replication и данные уже готовы обслуживать клиента.
Если же радиус бэкапа стремится к бесконечности (ака "никогда"), то и time to recover тоже стремится к бесконечности. Как говорят местные, avrio mitavrio (tomorrow, my friend, tomorrow).
этот бакап должен быть, и его кто-то должен временами проверять (да и хранить у себя), поэтому совсем без админа не получится. Так что бакап должен быть, лежать отдельно и проверять его должен квалифицированный админ.
Ну, "квалифицированный админ" — это требование к качеству. В принципе, можно иметь бэкап и без квалифицированного админа. Разумеется, для кастомных решений нужен "квалифицированный", но коммодитизацию никто не отменял. Тот же 'dropbox backup' покроет такое количество случаев для микрохостинга, что в принципе, "не квалифицированный админ" справится не хуже. А для восстановления можно и подрядчика привлечь.
А много у нас cloud native приложений, чтобы вот взять и бизнес на них делать в россии?
Тут даже альтернативы битриксу нет и альтернатива 1с существует только для нанокомпаний.
(я не троллинга ради, самому надо).
Как насчёт cloud native с декларативной инфраструктурой, которая в единицы (десятки) минут разворачивается на любом IaaS?
А данные эта тайная чудо-техника нинзя тоже разливает? Все серьёзные сервисы требуют хранения некислого состояния. Я больше чем уверен, что разлить своё приложение где угодно автор сможет прямо сейчас (ну прям сейчас не интересно, оно уже поднялось), а вот наладить репликацию баз на другой сайт — великая наука…
Согласен, что нужно уметь поднять бизнес-критичное приложение достаточно быстро. НО, вот рассказы про облако, как серебряную пулю, или священный оберег, который сам по себе гарантирует все блага 21 века — бред сумасшедшего. У VPS есть примерно предсказуемая производительность и строго предсказуемая стоимость сервиса. У облака, в общем, всё нормально с ресурсами (хотя Яндекс народ научил не расслабляться, да и другие факапили), но фиг предскажешь стоимость, особенно при множестве сервисов и под нагрузкой.
Мне трудно оперировать "стоимостью vps'а" в контексте бизнес приложений. Условно, представьте себе, что у вас приложение размазано на пять регионов: 1 aws, 1 gce, 1 do, N серверов у провайдера бареметалл, и, допустим, 1 в alicloud. Если один из регионов факапится, то в зависимости от жирности приложения: а) автоматически отрабатывает bgp эникаст и умерший регион перестаёт (не)обслуживать клиентов за несколько десятков минут (пока оно там расползётся по всем быгыпам — это медленнее, чем фантазируют вендоры), либо, б) кто-то ручками в DNS'е убирает A запись и уныло смотрит на цифру 7200 в настройках пару часов (в реальности до суток усилиями плохих провайдеров).
По поводу репликации данных. Серебрянной пули для этого нет — разные данные требуют разного подхода к репликации. Вероятнее всего, для транзакционных БД нельзя получить одновременно полный fault tolerance при разумной latency операций. Для многих других типов данных (например, допускающих eventual consistency и небольшую потерю) — вполне возможно.
для транзакционных БД нельзя получить одновременно полный fault tolerance при разумной latency операций
Средствами БД — невозможно, но если приложение хоть немного готово поспособствовать — вполне возможно. Запись идет через FIFO очередь, и при отказе мастера менеджер очереди приостанавливает операции, пока slave не возтмет управление.
… при разумной latency операций. Если у вас latency большое, то чтобы узнать, что слейв жив, нужно время. чтобы отправить туда данные и получить подтверждение, нужно время. Это и есть latency, цена за redundancy. Вот если можно чуть-чуть подобосраться в специальных ситуациях и потерять последние N секунд работы, то wb с backpressure очень хорош. Если данные eventually consistent, и это устраивает, то можно заваливать числом (всякие replication slaves вокруг).
А вот если нужна настоящая ACID, то мы получаем CAP и увы.
Я не понимаю, почему при наличие backpressure и eventually consistent данных (спасибо за это уточнение, я подразумевал его, но не озвучил, да, мы работаем с вариантом EventLog’а) — мы будем зависеть от latency. В смысле, если речь не идет про очень специфический случай «highdump», когда нужно записывать терабайты в секунду, или настоящий real-time.
То, что общается с внешним миром просто буферизует данные (да, например replication slaves) и спокойно ждет подтверждения от slave. Я не вижу, как тут нарушается ACID. Может быть, что-то упускаю.
Смотрите, есть данные для которых понятно как мержить изменения (лог — отличный пример, отсортировали по таймстапму и порядок восстановлен), а есть данные для которых это невозможно. Если нам нужно сделать, например, банковскую транзакцию, то мы не можем её сделать, не заблокировав средства и не проверив возможность операции (что подразумевает консистентность данных тут и сейчас).
Если данные мягкие — то можно много чудес делать. Если ACID — то, увы, CAP и всё. Напоминаю, что в рамках CAP единственный метод иметь все три свойства — это иметь все ноды в crashed состоянии.
есть данные для которых это невозможно
Кофе мне, что ли, еще испить?
что подразумевает консистентность данных тут и сейчас
У нас, грубо говоря, база инкрементна, и консистентна в любой момент времени. Вся бизнес логика на конечных автоматах.
Отвалился мастер. Мы откатили все запущенные на тот момент транзакции и начали буферизовать запросы, вотэверитминз. Подключился slave failover. Воркеры начали разбирать очередь и применять изменения. Конкуретность решается автоматами: не наш черед — перешли в конец очереди. Мы так пережили уже два отказа мастера.
Да, если одну, грубо говоря, строку в RDBMS по дизайну могут менять сразу из пяти разных мест — это не вариант, но тут вопросы, скорее, к архитектуре.
Если у вас после отвала мастера всё встало пока слейв не ожил, поздравляю, вы из CAP выбрали CP (в хорошем смысле слова). 'A' подразумевает, что ноды продолжают работать если у вас часть нод сдохла. Вы можете выбрать CA, в этом случае можно получить split brain.
Смотрите, вы говорите, "по дизайну могут менять сразу из пяти мест" — если у нас network partitioning (и локация осталась с 2 слейвами из 5 нод) — она работает или падает? Если падает, это CP, если продолжает херачить в кластер из 2 нод — это CA. Ну или всякая экзотика в районе AP, но я даже не знаю какими свойствами обладают AP СУБД.
А, я понял, наконец: вы подозреваете, что я слыхом не слыхивал про CAP, а я по умолчанию считаю, что CP — это единственный вариант для финтеха, и рассказываю, исходя из того, что об этом мы договорились :)
Но я настаиваю: оно не встало при отказе мастера. Мы продолжаем принимать запросы и адекватно на них отвечаем (типа, 201 :). network split приводит ровно к тому же: мы считаем, что консенсуса нет и переходим в режим буферизации.
Смотрите: вот пользователь ввёл пин-код, нажал "ввод". Он хочет получить свою карамельную селёдку. Желательно "сейчас".
А у вас нет связи со тремя из четырёх слейвов. Вы буфферизируете операцию, это хорошо. А дальше-то?
На чеке машинки что написано будет? timeout, accepted или rejected?
Я там выше описал сценарий:
Отвалился мастер. Мы откатили все запущенные на тот момент транзакции [...]
Timeout / Rejected. И эта операция буферизована не будет.
для транзакционных БД нельзя получить одновременно полный fault tolerance при разумной latency операций cредствами БД — невозможно, но если приложение хоть немного готово поспособствовать — вполне возможно.
Запись идет через FIFO очередь, и при отказе мастера менеджер очереди приостанавливает операции, пока slave не возтмет управление.
Скажите, где именно fault tolerance в timeout/rejected на чеке?
Если вы не банк то в чеке можно писать offline, а потом доливать, и получить свою дозу убытков/бюрократии если не повезёт, если вы банк то всё сложнее…
p.s. личное мнение, что нам повезло что МПС появились задолго до быстрого интернета почти в любой точке мира :)
Вы уверены что вы про Малый и микробизнес (средний по принятому в стране делению маловероятно будет висеть на 1 хостера либо его бизнес не будет независим от вэба на 99% в перспективе пары месяцев)
Давайте все-таки определимся. Если для бизнеса не критично встать колом на пару дней — тогда бэкап — самое оно, никто не спорит. Оптимизация расходов, то-се.
Но если вдруг бизнесу почему-то важно быть онлайн 24/7, то или облако в разных регионах, или извините. Даже три часа простоя — для многих не вариант, а если вариант — то и два дня можно потерпеть. Тут все просто же.
Я нигде не утверждал, что всем важно быть онлайн 24/7. Я озвучил дихотомию. Конечно, это дороже. Я ровно это и говорил: надо выбрать, за что платить: за 24/7 деньгами, или за минус два часа прибылью, именно так.
Бизнес очень быстро соглашается с тем что даунтайм в пару часов раз в год это фигня.
Зависит от того, какой бизнес. На какой-то конференции недавно был доклад change.org, они гордились тем, что на их нагрузке теряют менее полпроцента реквестов. У нас в финтехе — иногда один реквест потерял — и бизнесу хана.
Карта не работает — это не про 24/7. Транзакция началась и не закончилась — я про это.
У нас иногда случаются транзакции на €100M. Там за два часа только на курсе может полтора миллиона влегкую набежать, особенно с эзотерическими валютами. Это не катастрофа, но дешевле ее избегать, особенно учитывая, что транзакций может быть сто, или тысяча.
Если для бизнеса не критично встать колом на пару дней — тогда бэкап — самое оноНу какие «пару дней»? 10-гиговый бэкап (архив файлов, дамп базы) разворачивается на VDS-ке за 10 минут.
IP запасной VDS-ки можно прописать в DNS (round-robin).
Вы неправильно понимаете о чём я говорю. cloud native говорит, что приложение срало на том, где его запускают. Оно сконфигурируется и работает в любой среде — и в cloud, и на бареметалл.
… что такое обычный сайт? Вот, например, habr.com — обычный сайт? SO? github?
Если на пару часов приляжет любой из вышеозвученных — катастрофы не случится. Ну на реддите оживление будет — и все.
Есть еще варианты, когда blackout в 10 секунд — не вариант.
Если blackout в 10 секунд не вариант, у меня для вас плохие новости. Вы верите, что магистральный оператор никогда не флапнет bgp? А если флапнет, то 10 секунд вы не отделаетесь. И не надо про резервирование каналов, bgp отрабатывает большие аварии куда дольше, чем за 10 секунд.
Не про 10 сек. но всё же, есть несколько вариантов "аварий"
- Лежат и конкуренты и мы — ну главное не крайние.
- Лежим только мы, но мы сделали всё возможное и заключили договор с "лучшим на рынке" а они упали… — плохо но можно не нести прямые убытки
- Лежим только мы потому что сэкономили и это явно проверяется, но по бумагам это не наша авария — всё плохо, нужны показательные наказания по итогам.
- Сами накосячили, — худший вариант.
Это для нас звучит странно не делать бэкапы или хранить их рядом с продакшен сервером, а для владельца бизнеса это оптимизация расходов. А то что у него весь бизнес это по сути эти самые данные он не думает.
Банковское обслуживание тоже сплошные расходы. Почему бы кеш не хранить прямо в кабинете бухгалтера на первом этаже? Ну и что, что там выручка компании за два месяца.
Таки вы не поверите, но и такое бывало:)
Все верно, а если учесть что затраты на админа, бэкапы и репликацую данных порой достигают половины от прибыли, то и думать не будет.
например вот этот https://duma-murman.ru/
Айтишники не делали бэкапы или хранили их на том же сервере — искренне психую и надеюсь, что это для всех станет отличным уроком. Друзья, храните бэкапы на другом сервере или у себя. Это ваши деньги и нервы.
Это то, что любой айтишник должен знать с пелёнок. На любом хостинге может произойти останов сервера вплоть до потери данных. Даже в AWS были факапы и падения, не говоря про других. Неоднократно бывали случаи, когда хостер случайно стирал данные всех своих клиентов.
Надеюсь на разрешение ситуации, но господа, делайте бекапы, лучше всего — в другом географическом регионе.
Гром давно не гремел. А, лишние хлопоты — по распределённым бекапам с разными провайдерами, разной географией и юрисдикцией, это колоссальные расходы для представителей МБ и СБ. Ресурсов у них и без того мало. Риски то малы и «абстрактны» (особенно для тех собственников кто далёк от T), а издержки вот они — конкретны. Поэтому на воду и не дуют.
Из положительного:
— тех кого задело, теперь будут дуть даже на холодную воду из крана (там где-то сбой, и теперь она горячая).
— Тех кого не задело, но в курсе происшествия — что-то да предпримут. Ну или край — появятся доп аргументы для руководства / собственников.
Из печального:
— (правильно) бекапы сделают всё равно не все. (не всем по карману). И, история рано или поздно повторится. Сколько раз об этом не кричи и не предупреждай.
Гром давно не гремел.весной гремел:
18 марта MySpace потерял музыку..
17 мая Яндекс удалил часть виртуальных машин в своем облаке
у того же айхора первый «захват» был в феврале
Для малого бизнеса у которого объёмы разумные (ну, бывают малые бизнесы с сотней петабайт специализированных jpg, да...), есть масса копеечных вариантов бэкапа — вплоть до пары копий в google drive и dropbox на частный аккаунт владельца бизнеса.
Я не могу понять — что деньги охранять все знают, а что данные — "ну, это же сложно..."
Айтишники не делали бэкапыУчим простую считалочку «3-2-1»: имей 3 копии данных, на 2 географически разнесенных площадках, 1 копию — на другом типе носителя. Чем меньше выполняется это эмпирическое правило, тем выше шанс не восстановиться из резервной копии.
К этому стоит добавить, что управление рисками тоже ни кто не отменял.
realitsm.ru/2015/11/cobit5_for_risk_major_risks и realitsm.ru/2015/08/risk_management_refs
Областью значительных рисков авторы также назвали невыполнение обязательств подрядчиками.
Учим простую считалочку «3-2-1»: имей 3 копии данных, на 2 географически разнесенных площадках, 1 копию — на другом типе носителя.
Да хотя бы 1 копию где-нибудь локально у себя. Уже намного лучше, чем ноль.
Даже рядовые пользователи это понемногу осознают. Недавно закрылся (насколько я понимаю, без предупредения) популярный у определенной аудитории сервис BeOn и который день в интернетах стоит мощный плач «а как же нам вытащить содержимое наших дневничков». Знаю людей, которые даже отдали тысячи рублей неким «хакерам», которые обещают взломать сервер и слить базу, но, разумеется эти «хакеры» мгновенно исчезают после получения оплаты. Хинт владельцу сервиса: можно ж ещё и навариться на своих бывших пользователях, раз уж их не жалко (судя по тому, что серверы потушили без предупреждения), продав им их же контент.
имей 3 копии данных, на 2 географически разнесенных площадках, 1 копию — на другом типе носителя
Скажи, а что понимать под «другим типом носителя» в твоем предложении???
Давай предположим, что основной сайт крутиться на VPS, скажем, в Голандии. Бэкапы делаются на AWS в Штаты. Причем, оба провайдера дают SATA/NVME винты. Что может быть другим типом носителя? Скажем, локальная копия на внешний HDD, но так у моих провайдеров на VPS-ках примрено такие-же винты, разница только в способе подключения, но не типе носителя… Может быть, писать бэкапы на магнутную ленту??? Печатать их на бумагу??? Так бред же, имхо.
Думаю, что правило направлено на минимизацию потери данных в случае электрической неисправности или вирусной активности направленной на один тип носителя. Например, бывали же истории, когда неисправным блоком питания палили подряд пару жестких дисков.
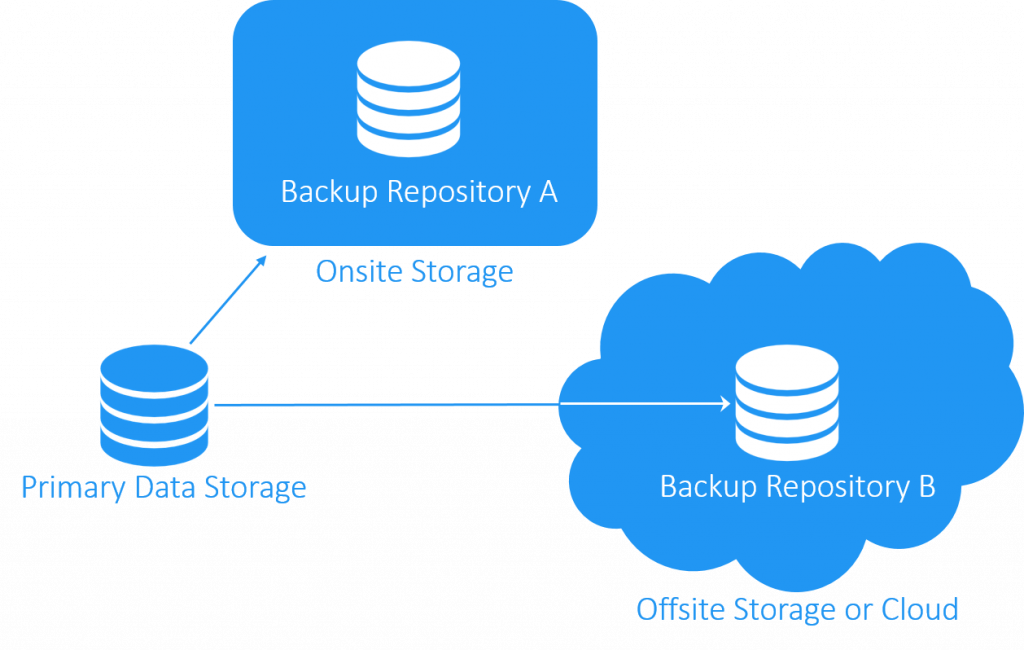
Предполагаю что под «другим типом носителя» понимается то, что не следует держать на одном хранилище (диске/дисковом массиве/контроллере/устройстве), так как оно может быть неисправно/сломаться и повредить данные. Например сбойный контроллер может попортить данные даже на RAID 1.
(Прошу прощения, не удержался) Видимо, теперь "Айхор" надо будет писать по-английски как iWhore...
Может там клиенты не на сервис а на площадь?
Вроде включили же вчера вечером. Я сегодня смог зайти бэкапы сделать, качнуть все. Из панели все глухо, сайт не завелся, но по ssh норм зашёл. Повезло, что проект делал изначально с расчетом на любой тип сбоя, в том числе потерю данных, бд конечно нужна была, но не на столько. А заказчик даже не понял, что произошло, просто сайт не работал 20 часов, и клиенты жаловались.
Извините, но я не вижу тут аналогии с Рамблером, или тем более, делом Голунова, после которого появилось это Я/МЫ. Проблема в деле Рамблера — это использование силовиков, чтобы оказать давление на человека (как и в случае с Дуровым, например). Если бы Рамблер выяснял отношения исключительно в суде, тряся стопками бумаг, никаких претензий к нему бы не было.
К вам, как я понимаю, с ночными обысками никто не приходил, вещи не перетряхивал, счета не арестовывал, пакетики не подбрасывал, уголовных дел не заводил. Как вы себя можете ставить на одну ступеньку с Сысоевым? Купите уже себе аккаунт на другом хостинге вместо того, чтобы тут жаловаться. И выходите иногда на улицу, а то фраза "кошмар, который случился наяву" вызывает только смех.
Что касается Айхора, то он реально был любим многими, поддержка отличная была. То есть это не вот чтобы проблемный лоукостер…
То есть в любой момент мы можем зависеть от срача 2-5 человек
Добро пожаловать в реальный мир.
из-за конфликта 4 взрослых мужиков с признаками инфантилизма и истерии
Когда люди вкладываются в проекты, они рассчитывают на награду. Если вместо награды всё теряется и рушится – многие станут вести себя как угодно, если это поможет изменить ситуацию в свою пользу. К тому же нужно учитывать, что:
а) вложения (сил, времени, материальные) в таких случаях обычно очень значительные, и возможности у этих людей тоже больше, чем «написать в спортлото», и потому, боюсь, нас никто и не спросит, что мы думаем об их поведении;
б) разногласия по-прежнему решаются криком и боданиями; «цивилизованные способы решения конфликтов» в конкурентной среде рынка без серьёзных регуляторов (каковые даже если и есть, то состоят из тех же «мужиков») не работают, забудьте этот благостный гуманистический бред.
Короче говоря, поздравим тех, кто стал 100500-ым членом человечества, получившим «важный жизненный урок». Урок, который совершенно забывают преподать в «официальных» системах образования и воспитания, а преподают, к стыду и печали за эту цивилизацию, лишь в уголовной и некоторых других специфических средах.
А главные правила, на самом деле, просты до безобразия:
1) если вы являетесь членом какого-либо сообщества, то вас всегда доят «чужие» и частично «свои»;
2) если у вас «свой маленький бизнес», то вас всегда доят все.
Вспоминается похожая история с МакХост и Оверсан-Меркурий почти десятилетней давности. Там тоже разошлись во мнениях несколько человек, когда-то партнеров. И выключили рубильник в ДЦ.
2. Хоститься надо в Европе
3. На Хабре было сравнение, по которому Айхорн просто с разгромным счетом продул всем
habr.com/ru/post/472454 и habr.com/ru/post/446464
Хоститься надо в Европе152-ФЗ иногда мешает это делать.
и что дальше?
Заливаем бэкап на доступный хостинг, работаем дальше.
Даже если нет бэкапа — через реверс-прокси на самом лайтовом доступном VPS возвращаете сайт онлайн, спокойно переезжаете.
Если так на воду дуть и всего бояться, то лучше на улицу не выходить — вдруг машина переедет или метеоритом голову пробъет :)
Восстановление из бэкапов хорошо, когда есть абсолютно актуальный бэкап, только вот это вряд ли реально для сильно посещаемых сайтов. А, когда, скажем, разворачиваешь где-то еженедельный бэкап на 100-200 гигов и потом ещё тратишь кучу времени на добычу и дозаливку инфы с последнего бэкапа до аварии, это бывает тяжеловато, хоть и деваться особо некуда. Считаю, реплика, например, БД на slave в другом ДЦ надёжнее, если за ней следить.
Естественно каждому владельцу надо самому решать когда и как делать бэкапы и обеспечивать сохранность и доступность своих данных, исходя из того чем они управляют.
Тарифы были вкусные, опции тоже. Отзывы шикарные, рейтинги высокие.
Если тут нельзя — напишите в личку (me@shachneff.ru), пожалуйста, что есть подобное в РФ кроме айхора (но не первый дедик, у меня там 2 года был сервер, сбегаю, цены стали неконкурентные, ДЦ Tier2)?
Мы 20 лет работаем, и отзывов у нас почти нет. Отзывы пишут когда что-то плохо. Вы много отзывов пишите?
В чатах очень много фейков, ложной информации и троллинга (не путать с юмором). Это неуместно в ситуации, когда у людей, не побоюсь этого слова, беда.
Так троллинг тогда и хорош, когда у людей, не побоюсь этого слова, беда. Самый смак именно в такие моменты. Много еды, много полыхания и БОЛИ. Это и есть троллинг (не путать с юмором).
Основатели Айхора предупреждали за сутки о возможности подобного развития событий в группе ВК и Телеграм: vk.com/wall-40099160_12968
Кто поленился настроить автоматические бэкапы (как я), мог сделать это вручную.
После февральских аналогичных событий включил оповещения от Айхора.
(Самые громкие вопли от тех, у кого там оказались действительно критические данные без бэкапов и без заранее предусмотренной возможности развернуть зеркало.)
Тем более это уже третий «звоночек» за этот год. С февраля ситуация не изменилась. Помещение ЦОД как было в аренде у мутной фирмы, так и осталось. Приличные долги у хостера, как были так и остались. Амбиции «рэкитиров» как были, так никуда и не делись.
Я — клиент, у них есть моя почта, почему уведомление не пришло на неё? Как вообще могла возникнуть мысль для подобного рода уведомлений использовать соцсеть (которой у клиента может и не быть) и мессенджер, который вроде как вообще запрещён?
Кто-то послушал совета, кто-то не успел, пришлось помогать с бэкапами, восстановлением. Часто траблы возникали, когда база данных находится в переходном состоянии myht.ru/question/21321289-baza-dannyh-nahoditsya-v-perehodnom-sostoyanii Но больше всего меня бомбит от официальной позиции айхора.
Я перенесла оттуда проект еще после событий в конце февраля, почитала серч и стало понятно что ситуация мутная.
mouse cloud, selectel, aws, яндекс.облако + айхор теперь. А мы все еще храним бекапы в пределах одного хостера…
Hetzner— известны истории когда диски там дохли, а хостер даже «oops» не говорил, типа как так и надо
А это был аукционный сервер, или обычный дедик (если да — то из какой линейки)? В первом случае это всегда лотерея.
Ну и к слову, пользуюсь дедиками на хетцнере 2 года — каких-то критических косяков замечено не было. Были всякие мелочи, но все решалось быстро и проблем не доставило.
Да и предоставляют по 2 диска на сервер (программный RAID1 при установке ОС штатным установщиком, за дополнительную стоимость можно взять аппаратный), так что даже если в процессе работы один из дисков «отъедет» — не страшно, можно заменить, но было бы всё же лучше, чтобы Хецнер отлавливал поломки дисков, а не клиенты.
Это просто такой уровень правовой культуры в стране, увы— не все клиенты читают договор и SLA. Как правило, объем претензий, в случае проблем, лимитирован стоимостью оказываемых услуг. Что то большее может обеспечить страховка. Кто то пытался у нас ввести страхование данных, простоев и т п, но видимо народ не повелся и услуга заглохла. Как результат, бороться за «3 копейки» никто не хочет — овчинка выделки не стоит.
Я не буду писать что у меня было на сервере ценное. Думаю каждый может такую историю рассказать.
Но приехал я сегодня в Москву с твердым настроем — захожу в офис и… (устраиваю физическое насилие) вот прям с любым руководителем, которого я там застану. Даже понимая, что вечер может в полиции закончиться, я шел туда с твердым намерением. Думаю морально многие из вас меня бы поняли.
Из-за каких-то спорящих дебилов я теряю деньги. И мне без разницы кто там директор и у кого какая доля. Я шел с твердым намерением пи… ть любого, кто будет в кабинете руководителя!
Сначала я приехал в 8 утра в их типа «офис» (который у метро Сокольники)
Там мне охрана на входе сказала, что «тут клиенты недовольные приходили уже несколько раз». Эти же сторожа мне сказали, что «тут только компьютеры стоят и техник раз в неделю приходит, а начальство все в другом офисе, адрес не знаем»
Ближе к вечеру я до их «техноцентра» добрался. Там вообще засада — большая территория, но без приглашения не попасть. Нужно, чтобы пропуск заказали. А меня то явно там никто не ждал.
Что-то мне подсказывает, что реально они по первому адресу, просто сторожа их по доброте душевной отмазали. Но видимо видя мой настрой и то, что я не скрывал намерений найти их и…, возможно этим «собственникам» или кто там у них передали. Возможно и не я один сегодня приходил.
Одно дело в инете геройствовать и разборки устраивать, а совсем другое дело общаться с разъяренными клиентами. А я был в ярости! Не знаю повлияло ли это, но вечером на их и мою радость — заработало и я смог бэкапы сделать.
(про наше «авось» лекций читать не надо, сам знаю, что дурак. Бэкапы были, но месяц давность)
Так вот:
1. Мне все равно у кого там какая доля и кто там прав, а кто виноват. Шли бы вы все на… айхор со своими разборками. Уже в другом месте заказал сервак (не буду писать где, чтобы не было рекламой)
2. Если бы я кого-то из вас сегодня физически застал, то у этого «кого-то» бы видимо вечер в больнице закончился, а у меня видимо в ментовке. Так что наверное хорошо, что не застал! И им хорошо и для меня тоже.
3. И я думаю, что я не один такой «умный», кто обе стороны шлет на… айхор и уходит. Так что скоро будете дырку от бублика делить! И вот ни сколько не жалко.
4. Я бы может написал спасибо тому, кто «врубил рубильник», но что-то мне подсказывает, что это тот же, что его и вырубил! И пусть радуется, что я сейчас не рядом с ним, а то бы тоже ему пару рубильников вырубил.
ЗЫ: Простите за эмоции, но все как есть! Перед НГ вместо своих вопросов, решаю хрень какую-то из-за зажравшихся дебилов.
Всем удачных бэкапов и переездов.
Юристы, подправьте если где не прав.
Материальный ущерб есть в договоре, максимум — заплатят за день-два простоя (сколько там, 10 или 20 руб?).
Моральный? — нет его, вы что физическую боль испытали? Подтвердить ее медицинскими справками сможете? Хотя бы чек на корвалол приложите тем же числом.
Репутационный — это вообще непонятно что, конвертируйте в материальный с
доказательствами что потеряли столько-то репутации в денежном эквиваленте и после снова почитайте про материальный ущерб и упущенную прибыль в своем договоре.
В общем, стабильно стребовать можно только возврат денег за неоказанные услуги + услуги адвоката, причем в судебном порядке, в порядке очереди и приоритета требования.
Интересно, а сколько народу вообще задумывается о рисках, не говоря уже о финансовой оценке?
Я понимаю девушек с микробизнесом вконтакте, они обычно не знают что такое VPS, им это не надо. Но люди, ведь, осознанно разворачивали виртуалки, создавали себе инфраструктуру, инстинкт самосохранения-то где?
Меня вообще бесстрашие соотечественников очень впечатляет, не зависимо от сферы жизни и страны пребывания…
Поверьте мне, подобное «бесстрашие» часто бывает и с гражданами других стран.
К чему эти понты про «бесстрашие». Юзал ihor больше 3 лет, и особых вопросов к нему небыло. Ну, а высокий ценник никак не гарантирует отсутствие факапов, особенно в России. Так как в другой стране, любитель вырубать рубильники, уже сидел бы на лавочке и давал объяснения следователям.
p.s. Судя по недавнему прошлому, бункер в странах ЕС тоже не идеальная защита от людей в форме.
И вообще такие заявления довольно смешны в наших странах, где страховка считается просто разводом на деньги. А в случае какого-то стихийного бедствия все ждут потом на коленях перед властями, чтобы денег дали. Так и тут, для многих открытие, что за сайт нужно платить постоянно, а тут еще и за бекап. Вы им скажите еще, что бекапы нужно регулярно проверять на восстановление :)
Про виртуалке и как это происходит:
Был у компании магазин на shared хостинге, сначала всё было хорошо, но потом то ресурсов не хватит то что о отвалится, поддерживалось всё каким-то студентом "free lancer-ом", тут подвернулся знакомый который взялся помочь с сайтом (когда очередной студент исчез), у него оказался знакомый который предложил взять vds и поддержать по принципу ресурсы пополам с меня поддержка os), всё стало работать "хорошо", но время идёт, у знакомых всё меньше и меньше свободного времени и они всё дальше и дальше от уровня "поддержки" всё вроде как работает, бизнес немного вырос но потом его постепенно начали съедать крупные игроки, свободных денег у него нет, так и живёт.
Выходит что тем кто "осознано разворачивал" уже не интересно, а времени нет, каких-то прямо рисков на них нет (за рюмкой чая уже доносили проблему до владельцу, но все мы люди разные, бывают и оптимисты), так оно и живёт без зеркал и онлайн бэкапов и прочей "катастрофоустойчивости"...
Я почувствовал проблему эту — когда отвалился opennet.ru
Хоть я и параноик и перестраховщик, всё равно не один раз в жизни влипал в чёрт-знает какие ситуации.
Удачи вам! Всё получится!
А компания iWhore пусть горит в аду в месте её безумными владельцами.
а вообще сегодня облака есть. отправил код в репо, оттуда он вылился в облако. сломался контейнер — создал на лету другой (возможно даже автоматом) и в него залил код из репо. база переключилась на реплику и все вот это вот. крякнул один хостер — развернул инстанс во втором. даунтайм от нуля до получаса.
Берёшь мега железку с SSD по копеечным ценам. У домашнего интернет провайдера покупаешь IP за 100 рублей. На железке поднимаешь веб сервер и всё необходимое. Ставишь её поближе к домашнему телевизору и вуаля! Домашний кинотеатр+игровая приставка+сервер 24\7 всегда на глазах и под присмотром.
Платить никуда не надо… трафик дома безлимит. Ну а если электричество кто выключит, то уже есть железная возможность поскандалить и разобраться самому.
profit!
Все винят зажравшихся. А ничего если человек вкладывал в проект финансы и силы, а на деле его захотели кинуть. Больниство бы так и поступило
сообщество ненавидит их всех — вряд ли мы сунемся в проект, где встретим фамилии этих участников передела (не упоминаю, не хочу)
Зря. Если всё так, как вы говорите, то главный толк от вашего поста (кроме напоминания о важности бэкапов) — это предупредить людей, чтобы они знали, с кем им следует быть осторожнее. А так вы просто позволяете реальным, как вы сами утверждаете, виновникам произошедшего прятаться за именем компании. Если так — то зачем вообще вы тогда это написали?
в серверах то особых активов нет, если все клиенты разбегутся
я например продлевать не собираюсь
Панель управления открывается, а сайт что то не очень ((
У кого как?
Я/МЫ не Айхор-хостинг. Или как плюнуть в лицо отрасли