Comments 199
Если не быть изобретательным программистом, то такой код просто не компилируется:
Error C4308 negative integral constant converted to unsigned type
Интересно, что это правило всё же не работает и для операций с указателями. С ними нет такого поведения.
Результат зависит от разрядности процессора.
При компиляции под 32 bit результатом будет –4, а под 64 bit — –3.
Догадаетесь, почему?
Разность между указателями — ptrdiff_t, это знаковый тип.
Далее: у нас арифметическая операция между ptrdiff_t и uint32_t.
В случае 32-битной архитектуры: ptrdiff_t — это int32_t, преобразуется в беззнаковый, результатом будет uint32_t (беззнаковый тип).
В случае 64-битной архитектуры: ptrdiff_t — это int64_t, второй аргумент преобразуется в знаковый int64_t, результатом будет int64_t (знаковый тип).
Смешивать типы плохо, нужно явно приводить к одному, не просто бездумно, а именно к тому, что хочешь получить. Кастить -4 к беззнаковому в общем случае полная ерунда, поэтому если кастишь, то должен быть точно уверен зачем.
А смешивать типы… ээ Просто не надо так…
Это из серии сдвига 1 влево.
Просто C++ — язык со слабой типизацией, и об этом надо помнить.
А в C#, кстати, подобное поведение невозможно: там int32 op uint32 будет приведено к int64.
А что же будет, если операция над Int64 и UInt64?
В С++ конечно во все места разложили UB, но не то что бы в C# их нет. Например что будет в результате unchecked( Int32.MinValue / -1 )?
А что же будет, если операция над Int64 и UInt64?
Ошибка компиляции: будь добр, сначала сделай явное приведение типов.
Например что будет в результате unchecked( Int32.MinValue / -1 )?
Ну да, вы явно указали директивой unchecked свои намерения.
Ошибка компиляции: будь добр, сначала сделай явное приведение типов.
Да, точно, здесь всё отлично.
Ну да, вы явно указали директивой unchecked свои намерения
Можно не указывать unchecked явно, в C# это поведение по умолчанию, если другое не указано в настройках проекта.
На самом деле если убрать unchecked в такой записи, то просто не скомпилируется. Но если представить что -1 не константа на этапе компиляции, а результат некоторого выражения, то тут хоть явный unchecked, хоть не явный, будет UB.
Например так:
static int GetNum() => -1;
int a = int.MinValue / GetNum();
System.Console.WriteLine(a);либо unspecified, либо implementation-defined.
И это катастрофическая разница — undefined, если я правильно помню, это «стандарт не говорит ничего о поведении программы в этом случае, в зависимости от случайных факторов может происходить всё что угодно». Unspecified — точно не описано, но может быть диапазон вариантов, и для одного кода и окружения результат воспроизводим, implementation-defined — описано, но в документации компилятора/интерпретатора, а не языка.
Всё так, это implementation-defined.
С UB проблема в том что компилятор рассчитывает что их в коде нет, а значит может делать оптимизации исходя из этого и частенько делает что то крайне неочевидное.
И хотя implementation-defined это не тоже самое, но не вижу причин, почему он не может привести к подобным последствиям. Например почему разработчик компилятора не может сказать что это UB.
III.3.31 div – divide values
Exceptions:
Integral operations throw System.ArithmeticException if the result cannot be represented in
the result type. (This can happen if value1 is the smallest representable integer value, and value2
is -1.)
Результат: Unhandled exception. System.OverflowException: Arithmetic operation resulted in an overflow.
Не минусовал, но могу ответить на ваш вызов:
void Print(char *s) {
cout << s + 10;
}Почитайте внимательно сообщение компилятора — в какой строчке происходит ошибка? Это ваш код, это вы допустили ошибку.
Приведенная функция не принимает константные литералы, потому что там нет const — именно это вам компилятор и говорит. Но это совершенно не важно для, собственно, примера прибавления числа к строке. Именно из-за тонкостей работы со строковыми литералами я и не заводил никаких переменных в премере, а обернул его целиком в функцию.
Именно по причине небезопасности подобных штук появились <numeric_limits>, например. Заниматься такой арифметикой при наличии такого зоопарка надо либо с -Werror -Wpedantic, либо при помощи математических библиотек с конвертируемыми юнитами.
Без танцев с явным приведением типов.
Почему без, когда это именно то что помогает избегать проблем? narrowing, signed-unsigned comparison/operations, type overflow и прочее и прочее.
Стоит отметить, что -Wpedantic (а также -Wall и -Wextra) нужного предупреждения не содержит, нужно отдельно включать -Wsign-conversion.
Я что-то не так делаю?
https://godbolt.org/z/s4GaKPEPE
Поменял на x86, результат тот же. Почему оно вообще должно зависеть от архитектуры? У x64 MSVC int 64-битный?
Вы же про первый пример из статьи? Там по стандарту приведение к unsigned int должно быть. Я понимаю, что MSVC не всегда строго следует стандарту, но ptrdiff_t там как-то совсем неоткуда взяться.
Чисто из интереса, можете привести код, который вы собираете, и с какой ошибкой он сваливается?
Сразу хочу усомниться в «полезности» этого онайн-компилятора, раз результат компиляции отличается от реальной студии. Для тестирования перенсоимости кода это сайт явно не походит.
Ну не знаю, мне в своё время вполне успешно удавалось баги MSVC с его помощью локализовывать.
Так то все знают, что у студии своё понимание стандарта и кое что они делают не очень по стандарту… Но тут же речь не о соответствии стандарту, а о проверке того, как это компилируется в студии. Очевидно, что реальная MSVC более достоверна, чем её «эмуляция» на сайте. Интересно, что приведённые мной онлайн-компиляторы этот пример скомпилировали и выполнили, а студия выдаёт ошибку. Я в дебаге компилировал, разумеется.
Compiler Warning (level 2) C4308
Ага, теперь всё более понятно. Такое предупреждение и на godbolt повторяется, если /W2 добавить. И ожидаемо одинаково выглядит на x86 и x64.
Видимо, студия ещё и некоторый аналог -Werror по умолчанию добавляет.
Вообще конечно полезное предупреждение, в gcc и clang тоже было бы не лишним (-Wsign-conversion всё-таки иногда слишком широкое, поэтому по умолчанию и выключено).
Очевидно, что реальная MSVC более достоверна, чем её «эмуляция» на сайте.
Я бы, конечно, проверил в VS, но её как-то совсем неудобно без винды запускать. А godbolt скорее всего виртуалки с вполне реальным MSVC использует.
В проекте студии есть некоторый набор флагов по-умолчанию, включая тот же /W2. Еще и какой-нибудь <windows.h> и прочих windows-специфичных заголовочников включает в область видимости проекта. Попытайся вы собирать каким-нибудь cl.exe из консоли столкнулись бы с тем же, что и на godbolt - без указания флагов предупреждения не видать.
Да, мне стоило сразу уточнить, что в MSVC всё по умолчанию, включая компилятор и собирался проект через IDE, а не в консольном режиме. И стандарным компилятором, ведь ничего же не мешает любой компилятор к IDE поключить.
Сайт заявлен как онлайн-компилятор с возможностью видеть результат компиляции в виде asm кода. Было бы странно, если бы на каждый отдельный запущенный кусок cpp кода приходилось запускать целую IDE, как-то настраивать проект и прочее. Тут и с доставкой самого файла проекта вопрос встаёт и с кастомизацией его параметров. Да и вечный вопрос а какие настройки по-умолчанию накатываются тоже как бы есть - собирая проект не знаешь наверняка как именно собирается проект и чего напихают в финальный бинарь. В этом плане голый компилятор - то что доктор прописал. Максимальный контроль над тем что и как будет собрано. The true way как многие опытные люди говорят. Поэтому сайт не пытается "соответствовать" чьим-то каким-то настройкам где-то в какой-то IDE, а дает смотреть результат нескольких десятков голых компиляторов, среди которых есть и msvc, при помощи единого "консольного" интерфейса. На студии мир не сошёлся.
www.programiz.com/cpp-programming/online-compiler
cpp.sh
взял из выдачи гугла первые три онлайн-компилятора, они тоже "-4" возвращают.
Моя специфика работы подразумевает отсутствие неявных преобразований типов и самовыведений компилятором. Скорее всего будет одна int8_t константа и там по месту будет приводиться явно к нужному типу, через static_cast.
Кастить -4 к беззнаковому в общем случае полная ерунда, поэтому если кастишь, то должен быть точно уверен зачем.
Совершенно верно!
Тут как бы деление с остатком (внезапно это 1), т.е. чтобы из -4 сделать -3 (или 4294967293), нужно по всем правилам добавить тот остаток после умножения, т.е. написать такое:
// (4294967293 / 3 * 3 + 4294967293 % 3) == 4294967293 == -3 (as signed int)
(-3/3u)*3 + (-3%3u)
// ну или кастить собственно до деления:
-3/(signed)3u*3Я вообще не понимаю о чем тут баттхерт и почему вдруг стандарт надо переписать?! Потому что человек вдруг открыл для себя увидел usual arithmetic conversions в действии? Ну ОК тогда.
Есть еще теория компиляторов. Там за такие преобразования сразу с экзамена долой.
Есть еще и другие языки программирования. На них такого поведения не наблюдается.
Хорошо задокументированная бага становится фичей! Многие не видят уже багу, а видят
Во-вторых, если вы хотите получить конкретный ассемблерный код — вам никто не мешает писать его прямо на ассемблере, в т.ч. вставкой в коде на Си/C++.
То, что другие языки не похожи на Си и C++, как раз и мотивирует существование и тех и других.
Компилятор транслирует код из С++ через несколько представлений в код процессора (читай Ассемблера).
Ну да, ну да...
А у Ассемблера правил меньше, но они чёткие и ясные.
То-то все всегда всё пишут на ассемблере. А например какие-нибудь SIMD или псевдоинструкции и подобное ну очень ясные и понятные.
И делить -3 на 3u командой DIV сразу вылезет боком.
Вы удивитесь возможно, но делить можно совсем без DIV инструкций.
Я уж умолчу когда C-код компилится во что-нибудь другое, не нативное, типа LLVM (clang -emit-llvm), не говоря уже про экзотику типа WASM и т.д. и т.п.
Есть еще теория компиляторов. Там за такие преобразования сразу с экзамена долой.
У нас с вами разные профессора по видимому преподавали — мне например объясняли почему так и зачем оно может быть нужно.
А может и вам объясняли да позабылось, эта картинка ничего не напоминает?
Есть еще и другие языки программирования. На них такого поведения не наблюдается.
Правда?!.. Дайте угадаю, вы пришли в С/С++ из так называемых "высокоуровневых" языков?
А по теме если — ну вот при чём тут другие языки? В качестве примера разделите -300001 на 50000 на сях или плюсах и затем на вашем любимом "другом" языке.
// C/С++
-300001/50000 = -6
-300001%50000 = -1
--------------------
-6*50000 + -1 = -300001
// некий другой язык:
-300001/50000 = -7
-300001%50000 = 49999
--------------------
-7*50000 + 49999 = -300001Подсказка — ни то, ни другое не является неправильным, это просто разные подходы (а именно remainder vs. residual arithmetic), и обоим есть соответствующее обоснование в парадигмах конкретного языка.
Хорошо задокументированная бага становится фичей! Многие не видят уже багу, а видят фичу.
Это не бага от слова совсем. Если вы не понимаете зачем это нужно, это не значит, что это сразу внезапно ошибка.
Ну почитайте классику в конце-то концов.
В качестве примера вопрос для "на подумать" — у вас есть две целочисленные переменные фиксированной (что важно), но при этом разной разрядности (ибо одно грубо говоря на 1 бит короче), которые вы делите или умножаете друг на друга… Как наиболее оптимально сделать это без объявления такого действия UB, максимально используя их разрядность (или оставаясь в заданной размерности), при этом согласуя их conversion rank и т.п., чтобы в большем числе случаев результат оказался предсказуемо "хорошим"? (заметьте не математически правильным, ибо это просто нереально при вероятном переполнении)… Другими словами — как оттянуть тот момент переполнения?
Подсказка — ни то, ни другое не является неправильным, это просто разные подходы (а именно remainder vs. residual arithmetic), и обоим есть соответствующее обоснование в парадигмах конкретного языка.
Интересно, какие есть обоснования для первого подхода, кроме того, что его было проще реализовывать в железе n-цать лет назад?
Точно? Там учат получать отрицательные остатки? Я смутно помню определение с числовой осью, где берется ближайшая кратная точка слева и расстояние до нее — остаток. Хотя не исключаю, что последующие знания полей по модулю вытеснили старое определение. И теперь отрицательные остатки кажутся какой-то дикостью.
И теперь отрицательные остатки кажутся какой-то дикостью.
Ну хорошо, -13/4 даёт у вас остаток 3, а 13/-4 даёт остаток -3 — это не дикость? А по F-делению именно так (можете проверить на Питоне).
Тогда уж лучше требовать E-деление ("евклидово"), у которого независимо от знаков делимого и делителя остаток таки всегда неотрицательный. Есть и языки с ним.
13/-4 даёт остаток -3 — это не дикость?
Дикость, конечно. Я же говорю: мне "отрицательные остатки кажутся какой-то дикостью".
И да, евклидово деление было бы лучше всего, но даже F-деление лучше. Оно, по крайней мере, при делении на положительное всегда дает нормальные остатки и математика по вычетам при нем работает без костылей. А остаток от деления на отрицательное — очень редкая операция.
Потому что человек вдруг увидел usual arithmetic conversions в действии?
Даже с 20 годами опыта легко расслабиться и пропустить подобную диверсию где-то в коде, особенно когда это осложнено макрами, шаблонами и прочими факторами, которые сбивают очевидность, рассеивая внимание и делая неочевидными влияющие факторы (где какой тип).
Шутки типа "участие unsigned int приводит к беззнаковой операции, а участие unsigned short — нет, ибо он вначале конвертируется в signed int" ещё усложняют это.
Даже с 20 годами опыта легко расслабиться и пропустить подобную диверсию где-то в коде, особенно когда это осложнено макрами, шаблонами и прочими факторами, которые сбивают очевидность, рассеивая внимание и делая неочевидными влияющие факторы (где какой тип).
Ну да, странно же в языках типа C/C++ с целочисленными типами фиксированной разрядности… где и переполнение точно таким же образом словить можно (вас не смущает например что (char)127+2 == -127?), и несколько "странный" остаток при делении отрицательного на положительное число (см. remainder vs. residual arithmetic) и т.п.
Я стесняюсь спросить а те 20 лет опыта точно в C/C++?
Кроме того ну есть же warnings, тестовое покрытие и т.д.
Шутки типа "участие unsigned int приводит к беззнаковой операции, а участие unsigned short — нет, ибо он вначале конвертируется в signed int" ещё усложняют это.
Ничего оно тут не усложняет — приведение типов к большей разрядности это тоже часть usual arithmetic conversions и это просто тупо — вопрос приоритетов.
вас не смущает например что (char)127+2 == -127
Ну вас не смущает то, что, например, при -funsigned-char (GCC) это будет не -127? Давайте уже говорить про адекватно определённые целые типы.
и несколько "странный" остаток при делении отрицательного на положительное число (см. remainder vs. residual arithmetic)
Я не думаю, что T-деление более странное, чем F-деление. У каждого своя ниша, да. Но по достаточно легко находимым причинам T-деление заметно чаще в железе.
Я стесняюсь спросить а те 20 лет опыта точно в C/C++?
Это был типа намёк такой что нефиг говорить про большой опыт? Это у вас не лучший приём, вообще-то, но отвечу конструктивно: может быть, что и при 20 лет опыта в C и C++ кто-то ни разу не нарывался на такое. Ну вот другого рода задачи у него были. Тут важнее кругозор (который в том числе развивается чтением и обсуждением таких статей, как текущая).
Кроме того ну есть же warnings, тестовое покрытие и т.д.
И вот именно тот кто реально хорошо знает C/C++ знает, что ни ворнинги, ни тесты не помогут против такого, когда компилятору вдруг взбрело в "голову" применить конкретную плюшку UdB или UsB. Я нисколько не претендую на гуру, но это как раз знаю. А вот ваши упоминания тестов и ворнингов начинают смущать...
Ничего оно тут не усложняет — приведение типов к большей разрядности это тоже часть usual arithmetic conversions и это просто тупо — вопрос приоритетов.
Оно уже изначально контринтуитивно. А дальше когда вы пишете, например, шаблон с участием unsigned случая и вдруг оказывается, что ещё надо явно преобразовать типы, которые у́же int, к unsigned, потому что иначе оно будет signed… слишком легко такое пропустить, просто расслабившись.
Давайте уже говорить про адекватно определённые целые типы.
А давайте без давайте не передёргивать — что имелось ввиду я думаю понятно, ну или если хотите замените char на int8_t.
Я не думаю, что T-деление более странное, чем F-деление.
Кавычки на слове "странный" вы старательно не заметили по видимому. Если что это была попытка в сарказм.
ни тесты не помогут против такого, когда компилятору вдруг взбрело в "голову"
И как оно не проявится на тестах? Когда код покрывают тестами, оно должно быть для всех corner case. Если компилятору что то там "взбрело в голову", вплоть до UB, то ваши тесты должны это показать, иначе у вас покрытие как минимум не полное.
Оно уже изначально контринтуитивно.
Нет. Точка.
Оно оправдано и обосновано.
ну или если хотите замените char на int8_t.
Ну хотя бы — уже будет что-то осмысленное.
Если компилятору что то там "взбрело в голову", вплоть до UB, то ваши тесты должны это показать, иначе у вас покрытие как минимум не полное.
Вы это всерьёз? Покажите где-то не в Палате мер и весов (или студенческой работе) полное покрытие — я имею в виду, не все ветки исполнения (это банально и ни о чём), а все возможные случаи входных значений.
(Я уж не вспоминаю, что да, полное покрытие всех путей исполнения часто тоже нереальная задача, и что возможности по оптимизации и инлайнингу часто приводят к решениям, которые не покрываются проверкой модулей-кусочков даже на все значения аргументов.)
Нет. Точка.
Божественный аргумент. Главное, убедительный. :sarcasm:
Оно оправдано и обосновано.
То-то в новых языках массово отказываются от этого трахомудрия...
Проблема еще и в том, что я вначале выучил Ассемблер x86 и очень хорошо его знаю, а потом остальные языки, 6 профессионально и еще больше 20 понимаю и могу кодить. Но Ассемблер собака всё определяет. Почитал теорию компиляторов для практики и опять Ассемблер внёс свое. Что-то новое постоянно протряхивается через Ассемблер. Но какой код не мечтает стать Ассемблером (инструкциями процессора)?
То, что для умножения правила преобразования типов разной знаковости такие же, можно убедиться так:
#include <iostream>
int main() {
int i = 3;
unsigned u = 3;
if (((i * u) / (-3)) == 0) {
std::cout << "unsigned mul" << std::endl;
} else {
std::cout << "signed mul" << std::endl;
}
}
Верно. Операция MUL жёстко привязана к конкретным регистрам (DX:AX), тогда как IMUL может применяться к любым регистрам (но при этом не происходит расширение разрядности).
Но на Си, где тип произведения совпадает с типом множителей, эта разница не влияет.
Так при использовании IMUL старшая половина просто отбрасывается.
Есть, но:
В языке C++ операция умножения предполагает отбрасывание. При перемножении 32-битных чисел результат остаётся 32-битным, а при умножении 64-битных — 64-битным.
Они менее удобны в использовании и потому компиляторы ими не пользуются.
Если нужно перемножить 32-битное число на 64-битное, то компилятор просто преобразует 32-битный аргумент в 64-битный, а не трахается с пересылкой между регистрами.
Единственный сценарий, когда используется MUL/IMUL без отбрасывания — это когда при перемножении 64-битных чисел (стандартный тип с максимальной разрядностью) мы хотим получить 128-битное (разрядность больше максимальной). Но т.к. 128-битное целое не является стандартным типом и задействует интринсики, то под x64 использование MUL/IMUL без отбрасывания для стандартных типов не имеет сценариев для использования.
Также MUL/IMUL без отбрасывания используется при перемножении 64-битных чисел на 32-битной архитектуре. В этом случае в чистом виде эту инструкцию можно увидеть при uint32 × uint32 → uint64, например
unsigned long long mul(unsigned a, unsigned b)
{
return (unsigned long long)a * b;
}A * B = (T-a)*(T-b) = T^2 - T*a - T*b - a*b = T*(T-a-b) + a*b => a*b , здесь
a = abs(A), b = abs(B)При сохранении ответа в той же разрядности, что и A и B, останется только a*b, так как умножение на Т сдвигает результат за пределы разрядности.
Так что умножение знаковых чисел с MUL и беззнаковых IMUL даст правильный результат.
Но деление — НЕТ!
(T-a)/(T-b) = ?
mov dword ptr [rbp - 8], 3 // int i = 3;
mov dword ptr [rbp - 12], 3 // unsigned u = 3;
mov eax, dword ptr [rbp - 8]
imul eax, dword ptr [rbp - 12] // eax = 9
mov ecx, 4294967293
xor edx, edx
div ecx // 9 / 4294967293 = 0
cmp eax, 0
Этот DIV, он такой DIVный!!!
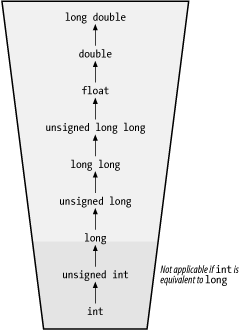
«the unsigned operand is converted to the signed operand's type», разумеется при соблюдении ранга преобразования
Это ничего принципиально не изменит. uint32_t просто будет преобразован в int32_t («при соблюдении ранга преобразования» же) и, скажем, 4294967292u в тех же ILP32/LP64 не начнет волшебным образом делиться нацело на -3 (хотя по наивному рассуждению «должно» — впрочем, оно и при текущих правилах преобразования нацело не делится, просто сейчас будет один остаток, а тогда другой). О, сколько нам открытий чудных готовит просвещения дух, в общем.
Странно, на носу уже с++23 маячит (опять туда напихают непонятно чего), но ни у кого руки не дойдут старое лигаси из стандарта вычистить… Слепое следование сломанному стандарту именно в таких случаях значительно хуже, чем исправление проблемы на уровне компилятора.
Просто этот фикс надо явно внести как новое правило в новый стандарт, которое отменяет старое. Тогда всё становится очевидно и однозначно.
Но, честно говоря, если у кого-то код работал "правильно" именно благодаря этому багу, то тут уже код править надо прежде всего.
А то что в Ассемблере такого и близко нет — это проблемы Ассемблера, хоть С++ и транслируется в него и вынужден следовать правилам Ассемблера.
Это касается не только компиляторов.
Только для C/C++ для слишком многих проблем эта инструкция выглядит как "в случае пожара нажмите кнопку 1 и через 0.5-1с, но не раньше и не позже, кнопку 2 дважды, а теперь на кнопке 1 отбейте лезгинку".
И это ещё хорошо, потому что для большинства UdB она звучит "вы должны не упасть с этого узкого мостика, а как — уже ваше дело", когда другие расширяют мост.
Ну да, когда-то и Empire State Building строили на высоте безо всякой страховки, кидаясь полукилограммовыми заклёпками. И почему сейчас никто так не хочет работать, просто странно… (сарказм, да)
Если язык даёт возможность определить свои типы с правилами в стиле "sqmeter operator*(meter x, meter y)", то принципиальной проблемы уже нет.
База языка, да, работает с безразмерными числами.
За переопределение операторов плюсы тоже критикуют.
Ну да, я видел такое, особенно от сторонников Go. Нефиг, мол, скрывать за простым "+" мегатонны библиотечных действий. А когда я спросил "а как же complex? а если мне вдруг векторы потребуются?" — был ответ "что есть в языке, то есть, а остальное от лукавого". Ну ладно, пусть лукавит… ;)
let m = $operator * (int16, uint16) -> int32) $;
auto product = m (x,y);
Ну да, сделать из языка со слабой типизацией язык с сильной типизацией.
Это когда любое приведение типов (кроме расширяющего) будет являться ошибкой.
Вот только это будет уже другой язык.
Вот только это будет уже другой язык.
В C и C++ давно есть "атрибуты", которые позволяют расширить текущий язык с сохранением всей обратной совместимости.
[[int_arith(checked)]]
int foo(аргументы) {
...
}и все сужения, при которых аргумент непредставим в множестве результата, будут генерировать ошибку (исключение C++).
Осталось провести это в стандарт (ещё 20 лет настойчивого давления).
Надо обязательно втащить это в стандарт? А весь остальной Boost случайно не хотите втащить?
Надо обязательно втащить это в стандарт?
Да. Не должен такой фундаментальный аспект зависеть от внешней библиотеки, тем более что технически это сделать в базе — чрезвычайно дёшево по сравнению с прочими затратами. (Административная воля, да, в разы сложнее.)
А весь остальной Boost случайно не хотите втащить?
Половину или треть — да, вполне. Весь — вряд ли, там много такого, что требуется ну 0.1% от пользователей. Я понимаю ваши попытки сарказма, но они тут откровенно неуместны.
Комитет C++ последовательно придерживается иного подхода.
например в Python: там в стандартной библиотеке есть криптохеши, JSON, base64, XML с XPath, HTTP-сервер и клиент, только чёрта в ступе нет.
Правильная (строго определённая, логичная/предсказуемая, удобная и безопасная) работа стандартных операций над стандартными типами данных, как целые, не имеет ничего общего с перечисленным и должна быть в базе языка.
Комитет C++ последовательно придерживается иного подхода.
Слово "последовательно" здесь, очевидно, является высшей степенью сарказма. На шутку дня ваша реплика определённо удалась.
Это всё надо решать контекстными настройками (как checked/unchecked в C#, но с бо́льшим количеством вариантов), и по умолчанию разрешать расширительные конверсии, но не сжимающие или меняющие границы (как intN<->uintN). И для конверсий с отсутствием значения в выходном множестве давать варианты реакции на неконвертируемые значения (усечение, генерация ошибки, выбор ближайшего...)
Для C/C++ это возможно сделать [[атрибутами]], только надо стандартизовать их. Даже если умолчание останется по-старому, новые возможности помогут качеству кода.
(Вам лично, возможно, я что-то подобное уже писал, тут оставляю для всех.)
Мне не нравится тупость человеческая, и тупое следование явно нелогичным правилам, вместо того, чтобы вносить необходимые корректировки.
Получим 1000000000*3u/3 == -431655765, тогда как сейчас получаем 1000000000.
В каком из двух случаев «тупое следование явно нелогичным правилам»?
Причём во всех случаях неявных преобразований встроенных типов, а не только этом, в первую очередь совсем безумных вроде float->bool
979880163/source.cpp:7:38: warning: implicit conversion changes signedness: 'int' to 'unsigned int' [-Wsign-conversion]
std::cout << "-3/3u*3 = " << int(-3/3u*3) << "\n";
^~~
1 warning generated.При этом -Wall -Wextra -Wpedantic не выдают ничего. (На -Wpedantic иронично конечно надеяться в данном случае)
И главное, предупреждения по умолчанию (!!!), только с помощью хитрых опций — отключать.
В стандарты это включено? А то на одном компиляторе предупредит, а на другом — нет. Вот чем комитет стандартизации должен заниматься.
Не путайте грешное с праведным. Целочисленное переполнение появляется по причине 32-битной переменной, независимо от языка и стандарта.
Хорошо, возьмём воображаемый «исправленный C++», в котором действие над int32_t и uint32_t считается знаковым.
Правильно "исправленный" C++ должен был выдать "у вас типы разной знаковости, унифицируйте", а не "считается знаковым".
Получим 1000000000*3u/3 == -431655765, тогда как сейчас получаем 1000000000.
А если 1000000000*5u/5, то почему-то и сейчас получим 141006540 — вместо генерации ошибки.
В каком из двух случаев «тупое следование явно нелогичным правилам»?
В обоих.
— Раскидай его на троих. Скажи бухгалтеру, пусть посчитает доли, он в ИТ шарит.
Бухгалтер:
#include <iostream>
int main()
{
std::cout << -3/3u;
}1431655764
— Шеф! Ура! Вы в выигрыше! Каждый из учредителей, по расчетам убытков, заработал 1431655764 ляма! Мы СуперМультиБиллионеры! Слава С++! Да здравствует Стандарт!
Странно, на носу уже с++23 маячит (опять туда напихают непонятно чего), но ни у кого руки не дойдут старое лигаси из стандарта вычистить…
Не совсем по теме, но очень близко: туда «напихивают» и кое-что понятное.
Заметил, что это правило почему-то работает только для операции деления, а операция умножения вычисляется правильно.
Нет, конечно, а проверяете вы неправильно https://godbolt.org/z/Pfrjvvbx7. И для деления, и для умножения применяются usual arithmetic conversions.
Я подумал, что что-то в стандарте сломалось и надо срочно это исправить. Написал письмо напрямую в поддержку Стандарта со всеми моими выкладками и предложением поправить это странное правило стандарта пока еще не поздно.
А integral promotions вы поправить не просили? Или просто ещё не натыкались на то, что перемножение двух unsigned short может приводить к неопределённому поведению?
for (size_t i = N; i >= 0; i--)Не-не. Он завершится при физическом уничтожении той машины, на которой он крутится, например. :)
Я имел в виду, что там нет UB, и компилятор обязан превратить этот код в бесконечный цикл.
UB вполне может быть: бесконечный цикл без побочных эффектов.
вроде бы переполнение unsigned типов это implementation defined behaviour (но без overflow), что почти так же плохо как UB. Поправьте, пожалуйста, если я ошибаюсь
§6.2.5: A computation involving unsigned operands can never overflow, because a result that cannot be represented by the resulting unsigned integer type is reduced modulo the number that is one greater than the largest value that can be represented by the resulting type.
хм, судя по этому посту операции над "малыми" unsigned типами все же могут приводить к UB, так как для них арифметические операции не определены
In particular, arithmetic operators do not accept types smaller than int as arguments
Да, эта та штука, которая меня нереально бесит в C++. Почему нельзя использовать ssize_t? Смешивание знаковых и беззнаковых аргументов, да ещё и с неявными преобразованиям, является источником ошибок. Например, в C# и Java индексация — это int, а int op uint — это long. А ulong в Java так вообще нет.
Но на то есть свои причины. Например, производительность и стандарты двоичного представления, которые существуют только для беззнаковых чисел.
Например, в C# и Java индексация — это int, а int op uint — это long. А ulong в Java так вообще нет.
Так в Java и uint нет. Как у вас long получился?
Так в Java и uint нет. Как у вас long получился?
Да, про Java напутал. Я просто на C# пишу, а не на Java.
Просто в C# попытка умножить long на ulong — это ошибка компиляции.
Там все немного хитрее:
In Java SE 8 and later, you can use the int data type to represent an unsigned 32-bit integer, which has a minimum value of 0 and a maximum value of 2^32-1. Use the Integer class to use int data type as an unsigned integer.
Static methods like compareUnsigned, divideUnsigned etc have been added to the Integer class to support the arithmetic operations for unsigned integers.
In Java SE 8 and later, you can use the long data type to represent an unsigned 64-bit long, which has a minimum value of 0 and a maximum value of 2^64-1. Use this data type when you need a range of values wider than those provided by int. The Long class also contains methods like compareUnsigned, divideUnsigned etc to support arithmetic operations for unsigned long.
C# и Java индексация — это int,
Это решение проблемы по методу страуса. "Благодаря" этому индекс массива ограничен 31 битами.
Я более того скажу: в C# по умолчанию ещё и сам размер массива ограничен 2GB (если элемент занимает больше памяти, тогда уменьшается максимальное число элементов).
Вот только я не считаю это проблемой. На практике такие массивы не встречаются, а экономия на разрядности имеет свои преимущества.
А что было бы, если бы мысль сделать индексацию всегда по int пришла бы авторам языка во время 16-битных процессоров?
Вроде как для массивов свыше 2 Гб достаточно ключа в настройках сборки, код менять не надо.
а экономия на разрядности
Однако если нам нужна экономия на разрядности, используем с/с++ а не c#
А что было бы, если бы мысль сделать индексацию всегда по int пришла бы авторам языка во время 16-битных процессоров?
Тогда сейчас бы был не C#, а D#.
А ещё, внезапно, в C++ размер типа int может быть любым. В старые добрые времена int был 16-битным, индексация — тоже 16-битной. Ну и сложные указатели (16-битный сегмент + 16-битное смещение).
А что было бы, если бы мысль сделать индексацию всегда по int пришла бы авторам языка во время 16-битных процессоров?
Было бы точно так же. На 16-битных процессорах int обычно занимает 16 бит. Если ни один массив без жутких хаков не занимает больше 64KB, больше 16 бит на индекс не нужно.
(Я тут пропускаю, что int знаковый, значит, побайтно можно адресовать только половину адресного пространства. Реально на таких процессорах, если адресное пространство единственное, и так мешают код и стек, а если в дополнительных, то можно получить полный размах, но будут проблемы из-за знаковости ptrdiff_t, и при этом много кто не даёт выделять не менее 1/2 размаха. Это отдельная грустная тема.)
Это только с 64 битами появилось, что int у́же адреса. В 16 и 32 они обычно совпадают. (Есть разная экзотика, но речь не о ней?)
for (size_t i = N; i >= UINT_MIN; i--)А этот опасен?:
for (int i = N; i >= INT_MIN; i--)-3/3*3 тестировал. Мне понравилось. И компилятору тоже. А вот -3/3u*3 компилятор плохо переварил, но многим вижу и это понравилось. Вот и не сплю спокойно с тех пор.Кстати, чем тип -3 меньше типа 3?
И делить можно только то, что разрешил Стандарт?
Если бы в заголовке увидел каст результата к int, то даже не зашёл бы. А так — удивился, т.к. не понял, откуда в результате знаковое.
Ан нет, просто написано некорректно для привлечения внимания.
По теме: полезно просматривать флаги предупреждений компилятора, в частности -Wsign-conversion
https://cppinsights.io/s/366d310e
int f(int num) { return -3/3u*3;} ->
int f(int num) {
return static_cast<int>((static_cast<unsigned int>(-3) / 3U) * 3);
}QED.
Мне ответил любезный молодой сотрудник из Стандарта и подтвердил, что мои выкладки правильны, логика на моей стороне, но поведение компиляторов полностью согласуется со Стандартом и само правило менять не будут, так как оно такое древнее, что непонятно кто и когда его ввел (сотрудник сказал, что искал автора, но не нашел) и поэтому его, как святую корову, трогать никто не будет, хотя вроде логично было бы исправить. Ну и милостиво разрешил поведать эту историю миру. О чем и пишу.
Я не автор этого правила, но оно мне кажется совершенно логичным: если я пишу
/3, значит я имею в виду знаковое деление; если я пишу /3u, значит я имею в виду беззнаковое деление.Если, как предлагают «исправить C++», оба этих варианта будут обозначать знаковое деление — то как обозначить беззнаковое? Явным кастом делимого, как в Rust?
3u обозначает знаковое число и не более того. К операции деления это отношения не имеет.
Логичным правилом в случае явно знакового деления было бы приведение обоих операндов к знаковому предоставлению и выдача сообщения об ошибке, если это не возможно из за, например, переполнения.
Я не автор этого правила, но оно мне кажется совершенно логичным: если я пишу /3, значит я имею в виду знаковое деление; если я пишу /3u, значит я имею в виду беззнаковое деление.
Если вы пишете 1000/x, то имеете в виду знаковое деление, а если 1000u/x — то беззнаковое, не так ли?
Чем должна определяться знаковость операции и типа результата — типом делимого, типом делителя, обоими?
Если, как предлагают «исправить C++», оба этих варианта будут обозначать знаковое деление
Предложение, как я понял, было в замене умолчания: после integral promotions, если операнды разной знаковости, то приводятся к знаковому (а сейчас — к беззнаковому). Случай одинаковой знаковости в нём не трогался совсем.
Текущие правила действительно жутковаты — integral promotions сначала, если расширяют, то к int (знаковому), потом приводят к общему с приоритетом на беззнаковость. Это может запутать даже спеца со стажем, если не держать постоянно в голове.
В языках, рождённых 15 лет назад и менее, от этого максимально уходят (уже в Go эти integral promotions устранены).
Если вы пишете 1000/x, то имеете в виду знаковое деление, а если 1000u/x — то беззнаковое, не так ли?
И в нынешнем C++ так и есть. В чём проблема?
Если, как предлагают «исправить C++», оба этих варианта будут обозначать знаковое деление
Предложение, как я понял, было в замене умолчания: после integral promotions, если операнды разной знаковости, то приводятся к знаковому (а сейчас — к беззнаковому).
Дело в том, что после замены умолчания не будет способа обозначить беззнаковое деление.
Дело в том, что после замены умолчания не будет способа обозначить беззнаковое деление.
"Дело в том", что я как раз говорил и говорю, что даже в этом случае остаётся нормальным вариантом, что деление беззнаковое при обоих беззнаковых аргументах. (Ну а я рекомендую вообще запретить неявные конверсии в таком случае.)
И в нынешнем C++ так и есть. В чём проблема?
Прочитайте, пожалуйста, весь посыл моего сообщения, прежде чем комментировать.
«Дело в том», что я как раз говорил и говорю, что даже в этом случае остаётся нормальным вариантом, что деление беззнаковое при обоих беззнаковых аргументах.
Именно об этом я и писал в комментарии, на который вы отвечали: «Явным кастом делимого, как в Rust?»
(Ну а я рекомендую вообще запретить неявные конверсии в таком случае.)
Это уже совсем другое, нежели замена умолчания на противоположное.
Если у запрета умолчания я вижу преимущества и недостатки, то у замены на противоположное — только недостатки.
Andrey2008: есть в PVS Studio тесты, выявляющие нечто подобное?
Пишите на Java ))
Не кидайте помидорами, я — обычный юзер
не сработает ли вдруг не оттестированный кусок кода в какой-то редкой нештатной ситуации
потому что код в первую очередь должен быть хорошо читаемым, тогда и нештатных ситуаций будет меньше.
про тестирование это отдельная тема. в Sony один раз забыли, что год может быть високосным, и у них PSN целый день по всему миру лежал.
Вкину ещё, чтобы пожар не гас:
auto foo() {
uint16_t a = 3;
uint16_t b = 2;
return b - a; // int -1
}
auto bar() {
uint16_t a = 3;
int16_t b = -3;
return b/a; // int -1
}Никаких переполнений и знаковых чисел. Потому что для всех типов меньше int арифметические операции сначала конвертят операнды в int. То есть для маленьких типов всё так, как хочет автор.
Сильная, но не полиморфная система типов может затруднить решение многих алгоритмических задач, как это было отмечено в отношении языка Pascal
Про Паскаль сказано:
Вариантная запись позволяет рассматривать тип данных различным образом в зависимости от указанного варианта.
Да, такой обход был в листингах из "developer documentation manuals Inside Macintosh". Ну так это в явном виде обход сильной типизации с добавлением нескольких строк кода. И только в нескольких редких случаях. Поэтому возражения сторонников слабой типизации не убеждают:
Так же найдутся, кто возразит, что ничего нельзя менять, поздно уже, много кода написано, и если в нём есть костыли, то он рухнет. Новые ошибки, они потом будут, а старые — они святое и уже превратились в знакомые фичи.
Как хорошую подсказку познавательно добавить предупреждение в компилятор когда он применяет это правило из Стандарта: «Signed value is intentionally converted to unsigned value. Sorry for crashing one more airplane. Have a nice flight!» Вот удивимся тогда, как мало мы тестируем и как много нам открытий чудных приносит компилятор друг.
Слабая типизация не должна быть по умолчанию. Сделайте директиву, отключающую типизацию, где это необходимо, а потом включающую. И старый код, после простой доработки, будет совместим с новым стандартом. При этом м.б. найдны баги, и спасено несколько Боингов.
Как минимум это должно быть не директивами, а общей опцией сборки. Типа, ставим всем "режим C99" и чтобы оно не рыпалось.
Менять исходники всего, включая сторонние библиотеки, автогенерируемый код и т.п. — слишком тяжело, не одобрят.
И без этого переход на новый компилятор это очень часто неожиданные баги или отказы компилировать, и прорабатываются годами. А вы предлагаете ещё код менять… а спецов анализировать все древние хаки — кто найдёт?
Боингов еще много летает.Тоскливо…
Логичнее наоборот: «the unsigned operand is converted to the signed operand's type», разумеется при соблюдении ранга преобразования.И чем логичнее, что 4294967295u/2 будет равно 0?
Выражение
-3/3u*3 — беззнаковое, его значение близко к UINT_MAX.Мнение трёх компиляторов по этому поводу — здесь.
Кстати, если использовать list initialization, которое рекомендуется к применению, которое не разрешает преобразование целочисленных типов, если в принимающий тип не влезает итоговое значение, то GCC и Clang выдают предупреждение:
ucast.cpp:4:38: error: constant expression evaluates to 4294967292 which cannot be narrowed to type 'int' [-Wc++11-narrowing]
std::cout << "-3/3u*3 = " << int{-3/3u*3} << std::endl;1) Включайте все проверки компилятора по максимуму.
2) Не смешивайте разные типы в одном выражении.
3) А особенно не смешивайте знаковые и беззнаковые типы.
4) И вообще, не пользуйтесь беззнаковыми типами без крайней необходимости (например, для ьитовых операций). С чего вы взяли, что это тип "по умолчанию?". Послушаем что на этот счёт говорит Страуструп:
ES.102: Use signed types for arithmetic
Reason
Because most arithmetic is assumed to be signed; x - y yields a negative number when y > x except in the rare cases where you really want modulo arithmetic.
Example
Unsigned arithmetic can yield surprising results if you are not expecting it. This is even more true for mixed signed and unsigned arithmetic.
4) И вообще, не пользуйтесь беззнаковыми типами без крайней необходимости
Увы, стандартная библиотека C++ принуждает к использованию беззнаковых типов.
Почему размеры коллекций решили сделать size_t, а не ssize_t — непонятно.
Мы все много раз слышали, что говорит Страуструп. Ответ: нет, это его заявления из категории "это было давно и неправда". Страуструп часто несет чушь по вопросам практического программирования. Не первый раз его ловят на подобных заблуждениях.
На самом деле все с точностью до наоборот: НЕ пользуйтесь знаковыми типами без явной на то необходимости. Подавляющее большинство целочисленных переменных в вашей программе должно быть беззнаковыми.
На самом деле все с точностью до наоборот: НЕ пользуйтесь знаковыми типами без явной на то необходимости. Подавляющее большинство целочисленных переменных в вашей программе должно быть беззнаковыми.
Сильное утверждение.
Тогда почему в Java вообще нет беззнаковых типов?
Вероятно потому что Java пытается обеспечить кроссплатформенность. И существуют платформы, на которых процессор может не поддерживать беззнаковые типы (но это не точно).
В то же время C++ вообще не парится по поводу кроссплатформенности и отдаёт это на откуп программисту.
Беззнаковые типы позволяют делать значительно больше оптимизаций. Особенно это актуально для всяких размеров контейнеров. Например тот же .Net, хотя и имеет все размеры в знаковых типах, внутри системной либы (BCL) часто делает каст к uint только для того что бы JIT мог производить оптимизации (например тут).
Банально value / 2 нельзя заменять на value >> 2, если тип знаковый, JIT ещё доп инструкцию делает, что бы знаковый бит сохранить.
внутри системной либы (BCL) часто делает каст к uint только для того что бы JIT мог производить оптимизации
Нет, в .NET такая оптимизация возможна только по причине того, что размер контейнера ограничен именно знаковым типом (т.е. сумма lo + hi не вызывает переполнения).
В C++ же приходится делать не (lo + hi) / 2, а lo + (hi — lo) / 2. И приводить типы все равно приходится, потому что разность указатель — знаковый тип.
Банально value / 2 нельзя заменять на value >> 2, если тип знаковый, JIT ещё доп инструкцию делает, что бы знаковый бит сохранить.
Не может такого быть. В x86/x64 есть как операция SHR, так и SAR.
Нет, в .NET такая оптимизация возможна только по причине того, что размер контейнера ограничен именно знаковым типом (т.е. сумма lo + hi не вызывает переполнения).
Я про использование uint vs int вообще, а не только про данный конкретный случай. Тут оба трюка используются. Но даже если отбросить возможность каста к uint (как в Java), здесь был бы код lo + (hi - lo >> 2), а не lo + (hi - lo) / 2). А в c++ lower_bound вообще по другому организован (подробности тут)
Этот пример просто вспомнился быстрее всего. Но каст к uint часто используется даже в проверке предусловий, что бы подсказать облегчить JIT-у дальнейшую оптимизацию.
Не может такого быть. В x86/x64 есть как операция SHR, так и SAR.
Очень даже может. Для этого нужно понять что же сделает следующий код (что будет в eax):
mov eax, -1
sar eax, 1или просто const int a = -1 >> 1;
После этого будет ясно, почему JIT генерирует вот такой код (пруф):
mov eax, edx
shr eax, 0x1f
add eax, edx
sar eax, 1P.S.: И да, я знаю что какой-нибудь gcc или clang заиспользуют ASR в этом простом случае, но это всё же немного другое.
в c++ lower_bound вообще по другому организован (подробности тут)
По вашей ссылке это first + (last – first) / 2, причём арифметика знаковая, без всяких приведений.
После этого будет ясно, почему JIT генерирует вот такой код (пруф):
Но ведь ничто не мешает в коде вместо (hi – lo) / 2 написать (hi – lo) >> 1 (для двоичного поиска не принципиально, в какую сторону идёт округление) и получить одну инструкцию.
По вашей ссылке это first + (last – first) / 2, причём арифметика знаковая, без всяких приведений.
А я вот такого кода не вижу. На первой итерации будет выполняться что то похожее, но как минимум вы забыли проверку while (count > 0) в промежутке. И именно благодаря ей, компилятор может гарантировать что count положительный и можно выполнять shr.
Но ведь ничто не мешает в коде вместо (hi – lo) / 2 написать (hi – lo) >> 1 (для двоичного поиска не принципиально, в какую сторону идёт округление) и получить одну инструкцию
С этим никто и не спорит. Руками вы можете написать что угодно. И в Java ровно так и сделали. Но вот компилятор за вас это не напишет. И не сделает ещё кучу оптимизаций, которые мог бы сделать, если бы знал что переменная точно > 0. А беззнаковый тип только это и гарантирует.
Так что использовать беззнаковые типы везде где можно, с точки зрения производительности очень даже оправдано. И Java, в которой нет такой возможности, тут вовсе не причём.
А я вот такого кода не вижу.
Плохо смотрите:
count = std::distance(...) = last — first
count / 2 = (last — first) / 2
std::advance(...) = first + (last — first) / 2
А про count > 0 — действительно, дельное замечание. Вот только в этой реализации есть проблема: std::distance() может оказаться отрицательным из-за переполнения.
Да нет, я смотрю нормально. То что вы расписали я вижу, о чём и указал в предыдущем комментарии.
Только вы упускаете что std::distance() не вызывается внутри цикла. То есть last - first не вычисляются на каждой итерации, как это сделано в Java и .Net. И место что бы допустить столь популярную ошибку (hi + lo) / 2 тут нет.
В любом случае к изначальному вопросу отношения это не имеет.
Вот только в этой реализации есть проблема: std::distance() может оказаться отрицательным из-за переполнения.
И в чём же проблема? Где lower_bound отработает неверно в этом случае?
И место что бы допустить столь популярную ошибку (hi + lo) / 2 тут нет.
Как раз есть. Входные данные: first < last, но при этом last - first < 0. Ну а дальше подумайте, что произойдёт.
А ещё посмотреть на реализации по ссылкам в
See also the implementations in libstdc++ and libc++,
то покажется, что в libc++ всё нормально, а в libstdc++ эта проблема вполне себе имеется.
Вы очень однобоко рассматриваете понятие оптимизаций.
1. Для C/C++, правило «программист позаботился об отсутствии переполнения» для знаковых, по сравнению с «арифметика всегда по модулю 2**N» для беззнаковых, даёт возможность таки делать большое количество оптимизаций вида: x+1>x заменить на true; a+1>b+1 заменить на a>b; и так далее. Для беззнаковых всё это запрещено. Это, конечно, дуболомство стандартизаторов и авторов компиляторов (воспользовавшихся дырой в стандарте), но пока у нас в этих краях другого языка толком нет. Здесь пробегали ссылки, что на некоторых задачах на этих оптимизациях получается 20-30% прирост скорости.
2. Кроме того, это упрощает жизнь программисту — например, делая цикл от N-1 до 0 по убыванию, можно писать while (i>=0), for(i=N-1;i>=0;--i), и другими вариантами. Для беззнаковых придётся применять другие форматы — типа знаменитой идиомы while(i-->0), которая ещё и не в любом языке доступна; цикл с постусловием; и прочие усложнения.
3. Современные компиляторы на некоторой фазе переработки текста выкидывают все исходные int/long/unsigned/etc. и переходят к диапазонам значений. После этого вполне может оказаться, что компилятор вычислил, например, что отрицательных значений не будет, и соответственно выкидывает защиту, как для вашего примера с value/2.
В идеале поэтому вообще не должно быть всяких short/int/long, а должно быть что-то типа «type temperature = new int -273...+451». (В Паскале 1970-го это было поспешно, а сейчас в самый раз.)
> Вероятно потому что Java пытается обеспечить кроссплатформенность. И существуют платформы, на которых процессор может не поддерживать беззнаковые типы
Java на таких не живёт. А вот отсутствие диверсии для кодера при переходе 0 -> -1 может оказаться очень существенной причиной.
> внутри системной либы (BCL) часто делает каст к uint только для того что бы JIT мог производить оптимизации
Это как раз к вопросу о диапазонах значений. В конкретном случае за счёт того, что размер коллекции уже ограничен int.MaxValue (а с чего бы это, если с беззнаковыми якобы лучше???), можно делать такой хак.
для беззнаковых, даёт возможность таки делать большое количество оптимизаций вида: x+1>x заменить на true; a+1>b+1 заменить на a>b;
Это потому что стандарт C++ обозвал переполнение знакового числа — UB. В других языках такого нет, а раз переполняться знаковый тип валидно, то такие оптимизации будут давать неверный результат.
Но даже если смотреть на C++, то если у вас написан код if (x + 1 > x) ..., то выглядит так что не оптимизатор его должен улучшать, а программист, т.к. сам по себе он контринтуитивный и вводящий в заблуждение. В то же время при работе с индексами и размерами приходится постоянно проверять на > 0, что приводит к дополнительному коду (что можно упростить через каст к (uint)).
Это как раз к вопросу о диапазонах значений. В конкретном случае за счёт того, что размер коллекции уже ограничен int.MaxValue (а с чего бы это, если с беззнаковыми якобы лучше???), можно делать такой хак.
Я там ниже уже отвечал на этот вопрос. Пример выбрал не очень удачный, т.к. там 2 хака юзается. Речь была про то что компилятор сам не имеет права заменить / 2 на >> 1 из-за того что тип значимый и что бы явно сказать что мы согласны, приходится к (uint) кастить.
Но на самом деле подобных мест в BCL много. Например тут или тут
Это способ сэкономить на проверке что index > 0. Которой могло бы вообще не быть нужно делать.
Это потому что стандарт C++ обозвал переполнение знакового числа — UB. В других языках такого нет, а раз переполняться знаковый тип валидно, то такие оптимизации будут давать неверный результат.
Да, UB (я предпочитаю писать UdB, потому что есть ещё unspecified behavior). И это имеет свои хорошие стороны как раз за счёт возможности таких оптимизаций. В идеале, IMO, интерпретацию тут надо задавать на контекст (исходный файл, функция, блок).
то если у вас написан код if (x + 1 > x) ..., то выглядит так что не оптимизатор его должен улучшать, а программист, т.к. сам по себе он контринтуитивный и вводящий в заблуждение
Вы пропускаете, что такой код скорее всего не напрямую именно так написан, а возникает как результат обработки компилятором (макры, шаблоны, или тождественная переработка чего-то существующего).
Да даже простейшая замена условия продолжения цикла с x<N на x!=N и наоборот — уже требует логических построений подобного рода (а так как компилятор не человек, то ему заводятся типовые шаблоны подобных проверок, иногда с возможностью проработать на небольшую глубину).
В то же время при работе с индексами и размерами приходится постоянно проверять на > 0, что приводит к дополнительному коду (что можно упростить через каст к (uint)).
Похоже на слабость логики кодогенератора дотнета. Вот я на C пишу:
typedef struct intarr {
int size;
int *values;
} intarr;
void report_error();
int gi(intarr* arr, int index) {
if (arr->size < 0) { __builtin_unreachable(); }
if (index < 0 || index >= arr->size) {
report_error(); return 0;
}
return arr->values[index];
}В ассемблере получается:
gi:
cmpl (%rdi), %esi
jnb .L9 ; <-- это и есть проверка как uint
movq 8(%rdi), %rax
movslq %esi, %rsi
movl (%rax,%rsi,4), %eax
ret
.L9:
subq $8, %rsp
xorl %eax, %eax
call report_error@PLT
xorl %eax, %eax
addq $8, %rsp
retКак видим, он сам эту проверку свернул.
Возможно, да, генератор дотнета сделан из расчёта, что столь тонкие пересчёты границ не потребуются
Я согласен с тем, что если обеспечено index>=0 самим диапазоном значений типа, то вообще не нужно думать о явной проверке, и что для беззнаковых тут есть красивый фокус в сведении к односторонней проверке. Но это 1) частный, хоть и важный, случай, 2) уже упоминал, последствие слабости самой системы типов — в том, что она сводит до стандартных машинных типов и не обеспечивает проверку. Представьте себе, что компилятор давал бы гарантию, что index >= 0 уже во всех точках вызова функции — проверка внутри была бы не нужна.
И то, что в C++20 продавили ssize() для стандартных контейнеров — это в языке-то, где эффективность всегда была хоть немного, но важнее удобства программиста — показывает, что "не всё однозначно" (tm).
Почитайте дискуссию — там ещё много аргументов (в обе стороны). Вот, кстати, по поводу размеров — одна из первых реплик там:
Получается, что большая часть моих кейсов сводится к тому, что естественные ограничения на беззнаковость идут к херам при вычислениях с этими типами. Насколько размер одного контейнера больше второго? Нельзя просто так взять и вычесть! Надо написать if (v1.size() > v2.size())...
:)
Похоже на слабость логики кодогенератора дотнета. Вот я на C пишу:
Ага, и весь хак в этой сточке: if (arr->size < 0) { __builtin_unreachable(); }
Вы явно сказали компилятору что уверены, что такого не будет, а иначе опять же UB. И конечно после этого компилятор может забить на знаковость. Только вот этот хак нужно будет писать по всему коду. В других языках такой опции нет (т.к. UB не в почёте) и поэтому такое написать очевидно нельзя.
А вот если убрать это строку, то компилятор сгенерит идентичный код с 2-мя проверками.
Вы пропускаете, что такой код скорее всего не напрямую именно так написан, а возникает как результат обработки компилятором
Безусловно это так. И подобные оптимизации могут приносить значительный прирост скорости. Но при работе с размерами контейнеров они встречаются существенно реже чем проверки границ.
А если говорить про менеджед языки, то такие проверки требуются вообще во всех функциях работы с размерами контейнера. И везде приходится эти хаки расставлять.
уже упоминал, последствие слабости самой системы типов — в том, что она сводит до стандартных машинных типов и не обеспечивает проверку
Это большая тема для обсуждения, не хочется её трогать. Там и до функциональных языков недалеко. Если коротко, то привязка к машинным типам имеет смысл. Поверх можно что угодно накрутить, хоть и не так эффективно как можно было бы. Тот же Index или Range в .Net.
Почитайте дискуссию — там ещё много аргументов (в обе стороны). Вот, кстати, по поводу размеров — одна из первых реплик там:
Ага, спасибо поглядел. В общем я согласен что с uint бывает неудобно работать. Но со временем вырабатываются паттерны избегать таких подходов. Хотя возможно для новичков это вызывает сильное неудобство, это тоже аргумент.
Ага, и весь хак в этой сточке: if (arr->size < 0) { __builtin_unreachable(); }
Нет. Обратите внимание: я этим дал гарантию на корректность инварианта контейнера (size не может быть отрицательным), но не на index, который таки тут проверяется.
В случае же хака, который вы показываете, этот инвариант предполагается, причём его нарушение приводит как раз к полной обструкции проверки: что будет, если, например, arr->size == -10? Проверка вида (uint)index < (uint)arr->size будет выполняться для любых возможно корректных (>=0) и большинства заведомо некорректных (<0) значений index :)
Вписав компилятору гарантию arr->size >= 0, я, действительно, помогаю ему объединить проверки index>=0 и index<size. В случае показанного вами кода C# это объединение выполнил кодер, вручную.
Только вот этот хак нужно будет писать по всему коду.
Ну в функциях доступа к элементу контейнера — вероятно, да.
Вообще, здесь в C# легаси от Java, которую они изначально скопировали максимально 1:1, включая отсутствие беззнаковых типов.
Кстати, как это я сразу не вспомнил — а почему в переносимом CLR и сейчас беззнаковых нет? Вам наличие беззнаковых не гарантируется (или в последнюю пару лет добавили?) Думаю, поэтому в интерфейсах стандартных классов int, а не uint.
В других языках такой опции нет (т.к. UB не в почёте) и поэтому такое написать очевидно нельзя.
А при чём тут собственно UB? Возможность написать гарантию чего-то от программиста (и компилятору — проверить её) — это как раз высокоуровневая фишка и проявляется обычно тем чаще и легче, чем выше язык (а в языках, где программа доказывается компилятору, это вообще основа), а не в низкоуровневых типа C (и позволяющему это C++).
Безусловно это так. И подобные оптимизации могут приносить значительный прирост скорости. Но при работе с размерами контейнеров они встречаются существенно реже чем проверки границ.
А сама "работа с размерами контейнеров" занимает какую часть кода? Причём именно в таком виде?
У нас базовый контекст всей темы — C++. А в нём, в первую очередь, рекомендуется работать с контейнерами через стандартные функции, которые используют итераторы типа begin(), end(), внутри которых вы не знаете что (беззнаковые индексы, знаковые индексы, указатели — это дело библиотеки). Далее, есть, например, vector::operator[], который без проверки, а есть vector::at(), который с проверкой. Но at() это только если кодер не уверен в индексе. И доля тех явных проверок таким образом падает до очень малой величины… зависит от задачи, конечно, но я пока не видел таких задач, где принципиально нужны беззнаковые.
Это большая тема для обсуждения, не хочется её трогать. Там и до функциональных языков недалеко. Если коротко, то привязка к машинным типам имеет смысл.
Почему сразу функциональные? Можно начать с Ada, где целые рекомендуется задавать диапазонами, а для низкоуровневой возни есть варианты типа "modulo 2**8".
И какой смысл сильной привязки к машинным типам в местах кроме того, где выходим на уровень железа? Что мне даст передача int вместо, условно говоря, int_range<0,999> (а дальше дело ABI определять, в какой тип его сложить)?
Но со временем вырабатываются паттерны избегать таких подходов. Хотя возможно для новичков это вызывает сильное неудобство, это тоже аргумент.
Да. Проблема таки в том, что требуется наработать твёрдую привычку избегать характерной группы неприятностей. Со знаковыми это не нужно — переполнить теми же контейнерами 2**31-1 это надо ну очень постараться даже сейчас...
Нет. Обратите внимание: я этим дал гарантию на корректность инварианта контейнера (size не может быть отрицательным), но не на index, который таки тут проверяется.
Вы сказали компилятору — считай что size не отрицательный. Но на практике это может быть не так. И вот в случае с C++ вы получите UB. А в случае с тем же дотнетом, компилятор вам не поверит (поэтому так сказать и нельзя). А если вы сделаете такой каст к (uint), то он выполнит выполнит 1 проверку вместо 2-х. Но в случае если вы ошибётесь, то получите вполне себе определённое поведение — исключение.
На мой взгляд и то и другое хак. Да, в одном случае — что бы склеить проверку в 1, в другом что бы подсказать сделать это компилятору.
Но и там и там это лишнее действие которое нужно делать.
CLR и сейчас беззнаковых нет? Вам наличие беззнаковых не гарантируется (или в последнюю пару лет добавили?) Думаю, поэтому в интерфейсах стандартных классов int, а не uint.
Не очень понимаю о чём вы. В стандарте CLI они есть. В типах BCL они есть. В C# они есть.
Если речь про методы, помеченные CLSCompatible, то среди них нет не только беззнаковых типов, но например ещё и операторов. Это сделано для того что бы на CLI можно было реализовывать языки, которые не поддерживают беззнаковые типы (например Java) или операторы (например VB.Net).
А коллекции юзают размер в int'ах как раз из-за Java, что бы можно было её поверх заимплементить. Что оказалось, к счастью, никому не нужным.
Что мне даст передача int вместо, условно говоря, int_range<0,999>
Я не понимаю зачем вам int_range<0,999>? Что вы от этого получите? Ограничите бизнес домен? Если так, то это очень слабая конструкция для этого. А как домен чётных чисел задать? А 0-99 кроме 1-цы? И всё что за пределами ограничений ренжа.
По факту для реализации бизнес требований нужны полноценные типы. И вы их можете имплементировать. А вот машинные нужны только для того что бы указывать сколько памяти использовать под тот или иной типа. Ну и минимальный набор правил арифметики.
Но ещё раз, об этом можно много рассуждать и много чего придумать. Не готов сейчас развивать эту тему.
У нас базовый контекст всей темы — C++.
Я как раз отвечал предыдущему комментатору на другой аргумент — что Java отказалась от беззнаковых типов.
Мой поинт в том что беззнаковые типы позволяют делать многие оптимизации при работе с размерами контейнеров. И на примере C#, как языка в котором есть беззнаковые типы, но в качестве размеров контейнеров выбраны именно знаковые, показал что это приводит к костылям при реализации стандартной библиотеки, в угоду оптимизациям.
Всегда бесило "многие так говорят", "все так делают". Когда сталкиваюсь с такими фразами - прям подгорает. Фразы-стопори человечества, которое просто не хочет ничего делать =)
Неясно, зачем надо было создавать сбивающий с толка заголовок. Значение выражения -3 / 3u * 3 во всех компиляторах С и С++ с 32-битным int без исключения равно 4294967292 . Без вариантов. Конкретное значение зависит от ширины типа unsigned intна данной платформе, но никогда и нигде оно не будет отрицательным. Тип выражения -3 / 3u * 3 - всегда unsigned int, без вариантов.
Поэтому о каком -4 разглагольствует автор поста - не ясно. Нет, никакого -4 тут нет и быть не может. Если же вам захотелось рассказать нам, что 4294967292, насильно приведенное к типу int дает -4на платформе с дополнительным кодом... ОК, но ничего заслуживающего отдельного поста в этом нет.
Зачем нужно было устраивать "исследование" того, что открытым тестом написано в спецификации языка - тоже не ясно. Более того, никаких ассемблерных листингов в таких исследования не допускается, ибо они вторичны по отношению к стандарту языка.
Чему равно выражение -3/3u*3 на С++? Не угадаете. Ответ: -4. Приглашаю на небольшое расследование