Недавно возникла задача получения чистого текста из различных форматов документооборота — будь-то документы Microsoft Word или PDF. Задача была выполнена даже с чуть более широким списком возможных входных данных. Итак, этой статьёй я открываю список публикаций о чтении текста из следующих типов файлов: DOC, DOCX, RTF, ODT и PDF — с помощью PHP без использования сторонних утилит.
Для начала отвечу на вполне разумный вопрос: «Зачем это, собственно, надо?» Правильно, чистый текст, полученный из, к примеру, документа Word представляет собой достаточно перемешанную кашу. Но этого «бардака» вполне достаточно для построения, например, индекса для поиска по обширному хранилищу офисных документов.
Другой вполне разумный вопрос: «Почему не использовать сторонние утилиты, например, antiword или xpdf, ну или в крайнем случае OLE под Windows?» Таковы уж были поставленные условия, да и OLE работает люто-бешено медленно, даже если задачу можно решить с помощью этой технологии.
Сегодня, в качестве «затравки», я расскажу о достаточно простых для поставленной задачи форматах — это Office Open XML, больше известный как DOCX от Microsoft и OpenDocument Format, он же ODT от ODF Aliance.
Для начала заглянем вовнутрь парочки файлов и увидим буквально следующее (сзади docx, спереди odt):
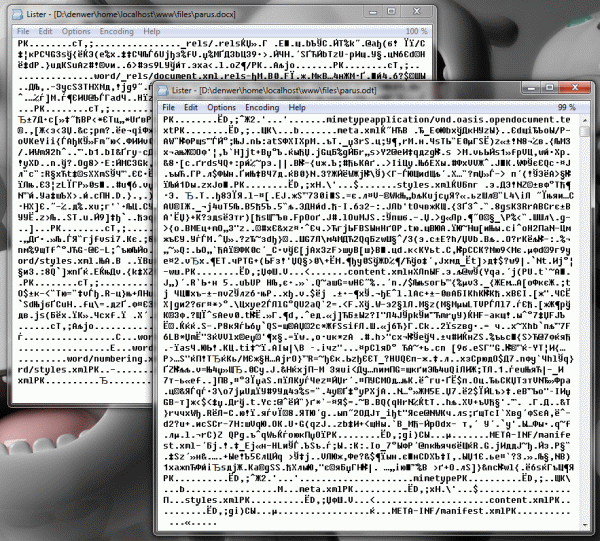
Самое важное, что мы здесь видим, это первые два символа

Итак, нужные нам файлы с данными — это content.xml в ODT и word/document.xml в DOCX. Чтобы прочитать текстовые данные из них напишем несложный код:
Отмечу, что данный код является лишь заготовкой для решения задач чтения текста. После череды статей под лозунгом «Текст любой ценой», я постараюсь описать принципы и реализацию чтения форматированного текста.
По теме:В следующий раз я расскажу о чтении текста из PDF без помощи xpdf. Более сложной, но вполне посильной для PHP задачи.
Для начала отвечу на вполне разумный вопрос: «Зачем это, собственно, надо?» Правильно, чистый текст, полученный из, к примеру, документа Word представляет собой достаточно перемешанную кашу. Но этого «бардака» вполне достаточно для построения, например, индекса для поиска по обширному хранилищу офисных документов.
Другой вполне разумный вопрос: «Почему не использовать сторонние утилиты, например, antiword или xpdf, ну или в крайнем случае OLE под Windows?» Таковы уж были поставленные условия, да и OLE работает люто-бешено медленно, даже если задачу можно решить с помощью этой технологии.
Сегодня, в качестве «затравки», я расскажу о достаточно простых для поставленной задачи форматах — это Office Open XML, больше известный как DOCX от Microsoft и OpenDocument Format, он же ODT от ODF Aliance.
Для начала заглянем вовнутрь парочки файлов и увидим буквально следующее (сзади docx, спереди odt):
Самое важное, что мы здесь видим, это первые два символа
PK в начале данных. Это значит, что оба файла представляют собой переименованный в .docx/.odt zip-архив. Открываем, например, по Ctrl+PageDown в Total Commander и лицезреем вполне приемлемую структуру (слева odt, справа docx):Итак, нужные нам файлы с данными — это content.xml в ODT и word/document.xml в DOCX. Чтобы прочитать текстовые данные из них напишем несложный код:
Всего каких-то 30 строк, и мы получаем текстовые данные из файла. Код работает под PHP 5.2+ и требует
- function odt2text($filename) {
- return getTextFromZippedXML($filename, "content.xml");
- }
- function docx2text($filename) {
- return getTextFromZippedXML($filename, "word/document.xml");
- }
- function getTextFromZippedXML($archiveFile, $contentFile) {
- // Создаёт "реинкарнацию" zip-архива...
- $zip = new ZipArchive;
- // И пытаемся открыть переданный zip-файл
- if ($zip->open($archiveFile)) {
- // В случае успеха ищем в архиве файл с данными
- if (($index = $zip->locateName($contentFile)) !== false) {
- // Если находим, то читаем его в строку
- $content = $zip->getFromIndex($index);
- // Закрываем zip-архив, он нам больше не нужен
- $zip->close();
- // После этого подгружаем все entity и по возможности include'ы других файлов
- // Проглатываем ошибки и предупреждения
- $xml = DOMDocument::loadXML($content, LIBXML_NOENT | LIBXML_XINCLUDE | LIBXML_NOERROR | LIBXML_NOWARNING);
- // После чего возвращаем данные без XML-тегов форматирования
- return strip_tags($xml->saveXML());
- }
- $zip->close();
- }
- // Если что-то пошло не так, возвращаем пустую строку
- return "";
- }
php_zip.dll под Windows или ключика --enable-zip под Linux. При отсутствии возможности использования ZipArchive (старая версия PHP или отсутствие библиотек) вполне может сгодиться библиотека PclZip, реализующая чтение zip-файлов без соответствующих средств в системе.Отмечу, что данный код является лишь заготовкой для решения задач чтения текста. После череды статей под лозунгом «Текст любой ценой», я постараюсь описать принципы и реализацию чтения форматированного текста.
По теме:В следующий раз я расскажу о чтении текста из PDF без помощи xpdf. Более сложной, но вполне посильной для PHP задачи.
