Comments 87
Настроил deepseek coder с применением ollama, и подключил к vscode с помощью continue. Ну и дополнительно ollama webui запустил. Очень удобно, хотя, возможно, есть интерфейс и получше, но оно и так работает.
не подскажете краткую инструкцию?
Ну, как-то так. Тут всё через докер, можно и нативно поставить, но я с этим не заморачивался.
Установить дрова для nvidia cuda и докер. Нужно, чтобы из контейнеров докера был доступ к видеокарте, т.е. команда типа
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmarkвыводила информацию о видеокарте.Клонировать ollama-webui. Там есть docker-compose.yml с необходимой минимальной настройкой. Разве что порты у сервиса ollama раскомментировать. Также можно добавить локальную папку в volume у ollama, например так.
- ./ollama_models/:/modelsПригодится, если будете дорабатывать существующие нейронки заменой системного промпта, например.Выполнить
docker compose up -d. Должен заработать ollama-webui наhttp://localhost:3000/Библиотека уже готовых моделей тут. Инструкция по ollama конкретно есть в репозитории. Для deepseek coder нужно выбрать подходящий тэг и пуллить командой типа
docker exec ollama ollama pull deepseek-coder:6.7b-instruct-q8_0. После чего в webui можно будет поспрашивать по коду. Правда, лично у меня на линуксе из webui конкретно эта нейронка не может выгружать слои в видеопамять. Собственно, почему 1й пункт этой инструкции со ссылкой под винду - я так и не разобрался, из-за чего так.Для режима копилота в VScode: в папке
./ollama_modelsсоздать modelfile - текстовый файл с удобным именем и содержимым типа
FROM deepseek-coder:6.7b-instruct-q8_0docker exec ollama ollama create deepseeker-copilot-f /models/modelfileЭто, возможно, лишнее, но мне кажется, Continue не очень корректно отрабатывает разные теги у нейронок в ollama, он вообще выдаёт ошибку за использование неправильной нейронки в конфиге.Установить расширение Continue. После начальной настройки в файле в папке пользователя\.continue\config.json добавить в модели свою нейронку и сохранить.
,
{
"title": "DeepSeeker Copilot",
"provider": "ollama",
"model": "deepseeker-copilot",
"api_base": "http://localhost:11434"
}Выбрать DeepSeeker Copilot из нейронок и развлекаться. Кстати, через расширение DeepSeek Coder работает с выгрузкой в видеокарту и в линуксе, так что, вероятно, проблема всё-таки со стороны именно webui у меня.
огромное большое спасибо
И тогда я еще от себя отпишу, я до коммента все нативно поставил
ставим расширение https://marketplace.visualstudio.com/items?itemName=Continue.continue
Ставим ollama https://github.com/jmorganca/ollama
curl https://ollama.ai/install.sh | shДобавляем DeepSeek https://github.com/jmorganca/ollama/issues/1040#issuecomment-1818147154 в этом комменте инструкция
Добавляем в
~/.continue/config.jsonв"models": [ ... ]
{
"title": "deepcoder",
"provider": "ollama",
"model": "deepseek-7B",
"api_base": "http://localhost:11434"
}
Стартуем оламу
ollama run deepseek-7BВ расширении выбираем deepseek
устанавливал вчера, может что-то пропустил, по памяти написал
в 5 пункте опечатка в командеdocker exec ollama ollama create deepseeker-copilot -f /models/modelfile
Ребят, извиняюсь за тупость, глупость и невежество, но вопрос такой. У меня ноутбук Ryzen-5, 16Gb, Nvidia 1650 4Gb под линуксом. Скажите, существуют в природе какие-нибудь нейросетки, которым будет достаточно такого железа ??? Производительность не интересует от слова совсем. Пусть хоть час работает. Интересна в первую очередь (а может быть и исключительно) генерация картинок. И даже более специализированно - генерация арта для игр. Хочу освоить это дело.
У меня на i5, 8гб озу, gtx 1650 4гб, stable diffusion 1.4 крутится с web-ui
Видюха ни о чём, но можешь обсчитывать на проце, и час это наверное слишком оптимистично. В общем я бы поберёг нервы.
У deepseek coder есть разные варианты, какая-нибудь вариация из 1.7b может запуститься с использованием видеокарты. Но работает так себе, судя по запросу накодить змейку. Не знаю, будет ли вообще какая-то выгода от запуска нейронки на такой видеокарте, но можно попробовать и 6.7b варианты, с нагрузкой на CPU, ОЗУ может и хватит. Правда, и на моём i7-8700k оно было ощутимо медленнее, чем на видеокарте rtx 4070. Запускаю максимально уместившуюся в 12 гигов видеопамяти 6.7b-instruct-q8_0, но там есть варианты полегче.
Не заметил, что интересует генерация картинок, их я особо не пробовал пока.
А какое железо нужно, чтоб 33B запустить?
Нашёл сайт для таких расчётов.

На очень хорошей скорости - любая 24 Гб видеокарта (exlama2, GPTQ: 50 - токенов в секунду). На так себе скорости - 32 Гб RAM (llamacpp, GGUF формат)
Посмотрите в сторону https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
На 5 рязани работает у меня, конечно генерация не пару секунд на картинку, но потерпеть иногда можно.
Посмотри на последние драйвера на свою карту. Нвидиа выкатили прикол что бы карта могла брать недостающую память из оперативки. Она будет медленней чем родная память карты раз в 10 но расширение прям большое может быть. Я поставил эти драв на свою 3060. Когда память забивается, автоматом идёт наполнение озу
Все из этой статьи должно работать. Я запускал и на слабее компьютеры и работало более/менее.
Вы можете использовать любые 7B или 13B gguf сетки на процессоре, уровень квантизации подберете экспериментально. Часть слоев можно будет скинуть даже на эту видеокарту. В text-generation-webui есть поддержка старых nvidia.
А стоп. Не увидел что вам для картинок - тогда модели на базе Stable Diffusion 1.5
Схожее железо, но 24ГБ RAM. Comfui просто прелесть, SD1.5 крутит хорошо. В зависимости от сэмплера 1.5-5 с/итерацию. Может даже в SSD-1B, но без лор
Stable Diffusion исправно работает и генерирует за 20-30 секунд с разрешением 1024х1024px, у меня видеокарта Nvidia GTX 1080Ti на 4GB. Запускаю с параметрами --medvram --xformers.
Производительность не интересует от слова совсем
Это только кажется. Когда столкнётесь со всякими нейронеточностями, захочется рисовать за меньшее время побольше вариантов. На вашем железе за час сделаете 30 картинок максимум. И это очень мало, учитывая, какой бред оно порой генерирует.
Увы, для генерации картинок железо слабовато. Да и не вижу смысла пытаться запускать локально, когда есть google colab.
А есть что-то, что может распознавать текст как ChatGPT? ChatGPT даже рукописный распознает, хотя и с ошибками.
Такой вопрос. Мне бы хотелось иметь возможность залезть внутрь подобной проги и посмотреть, как она работает -- типа поставить точку остановки, разобраться с параметрами и т.д. Цель -- понять, как можно было бы модифицировать код под свои задачи. Например, сделать анализатор текстов, заточенный на определенную область науки. Я знаю, что сетку надо натренировать на каком-то пуле текстов. Но, с моей точки зрения, это просто приведет к тому, что она будет выдавать последовательнсти слов, имеющиеся в этих текстах. А я хочу большего -- например, чтобы сетка могла выяснить, что ей не хватает какой-то инфы, и могла залезть в Сеть и поискать ее. Для этого надо хорошо знать, что и где добавть в коде или поменять. Может, кто-нибудь подскажет, какая из open-source сеток позволяет подобный апгрейд и с чего бы стоило начать подобную работу? В идеале мне бы хотелось работать под Visual Studio или Code, т.к. все время работаю под Виндой.
Топаешь сюда, клонируешь, настраиваешь свою среду разработки, там cmake (я в eclipse настраивал, отладка работала), там поддерживается тьма тьмущая открытых сетей, читай, ищи готовые примеры и finetune на huggingface (будь готов к десяткам гигабайт на каждую), для работы потребуют сравнимое количество RAM (есть начальная поддержка gpu, причем даже если ее не хватает чуть чуть)
Например, сделать анализатор текстов, заточенный на определенную область науки.
а вот тут тебе исходники и отладка не помогут. Нейронные сети работают так что внутрь залезть практически невозможно (но попытки есть), можно попытаться дообучить/переобучить- finetuning, можно попробовать поработать с запросами (точнее с весами входов) - peft и в любом случае это требует оборудования (gpu к сожалению пока только nvidia) с оперативной памятью, в которую помещается все веса выбранной тобой сети (количество параметров умножить на 2 плюс еще несколько гигабайтов, лучше больше) и еще сложнее, подготовленных датасетов обучающих данных под твою задачу (именно на этом и на том как именно их используют современные языковые модели улучшают)
p.s.
gpt сети работают в общем так (на самом деле там сложнее, есть еще понятие состояние но по исходникам моих знаний в этом разобраться не хватает) - текст преобразуется в токены, затем входные токены записываются в контекстное окно (оно всегда одного размера), остальное место заполняется условными нулями, и это окно подается как вход на нейронную сеть (каждому токену соответствует свой вектор чисел, именно эти числа и идут на вход), нейронная сеть в данном случае последовательность (кстати там не просто линейная последовательность а граф) операций над матрицами и векторами (произведения, нормализация и т.п.) пример сеть llama34b это ~700 шагов, на выходе получается вектор (размерность количество всех возможных токенов) вероятности следующего токена после введенных на старте... по некоторому алгоритму (в который ты уже можешь залезть и поменять) выбирается токен (например с максимальной вероятностью - это temp=0, или случайный из топ N токенов с максимальной вероятностью,...), он выводится пользователю (декодируется обратно в текст) и подсовывается как следующий в контекстное окно (если достигли конца, то по какому то алгоритму, который ты тоже можешь контролировать, все или часть окна сдвигается в начало, удаляя старый токен) и процесс повторяется до тех пор, пока не будет прерван пользователем, или условием в программе или финишным токеном.
Ты можешь вмешаться в алгоритмы выбора следующего токена, алгоритм детектирования окончания генерации, и алгоритм сдвига контекстного окна при его переполнении (например чтобы твой стартовый промпт остался нетронутым).
llama.cpp проект непрерывно дорабатывается и улучшается, в него внедряется космическими темпами все самое интересное, например сейчас пилится ускорение вычислений за счет того что следующий токен скорее всего будет в той же 'области знаний' что и предыдущий (это видно при генерации по вероятностям) и многие вычисления внутри операций над матрицами можно взять из предыдущего шага... вроде говорят что можно ускорить 10-40кратно! генерацию. Но чтобы такие изменения делать, нужно быть в теме на очень глубоком уровне
Для базовой теории (с созданием простенькой сетки разбора почерка), рекомендую прочитать "Создаем нейронную сеть" Тарик Рашид (пример). Большая часть книги - это математические основы, но они дают базу для понимая происходящих процессов
https://lmstudio.ai/ - самый простой и удобный способ найти, скачать и запустить чат модель под win lin mac, есть и готовые промт темплейты, и встроенный api сервер совместимый с openai форматом. text-generation-webui все же сложнее в установке и освоении, зато gptq формат моделей поддерживает, который работает быстрее на nvidia, lmstudio пока не могет
Ребят, извините не могу ответить всем. Тут и так крыша потихоньку едет от плотного погружения в vulkan. ОГРОМНОЕ ВСЕМ СПАСИБИЩЩЕ И РЕСПЕКТИЩЩЕ ! Дали мне хотя бы отправную точку, откуда начинать искать. Надеюсь всё получится.
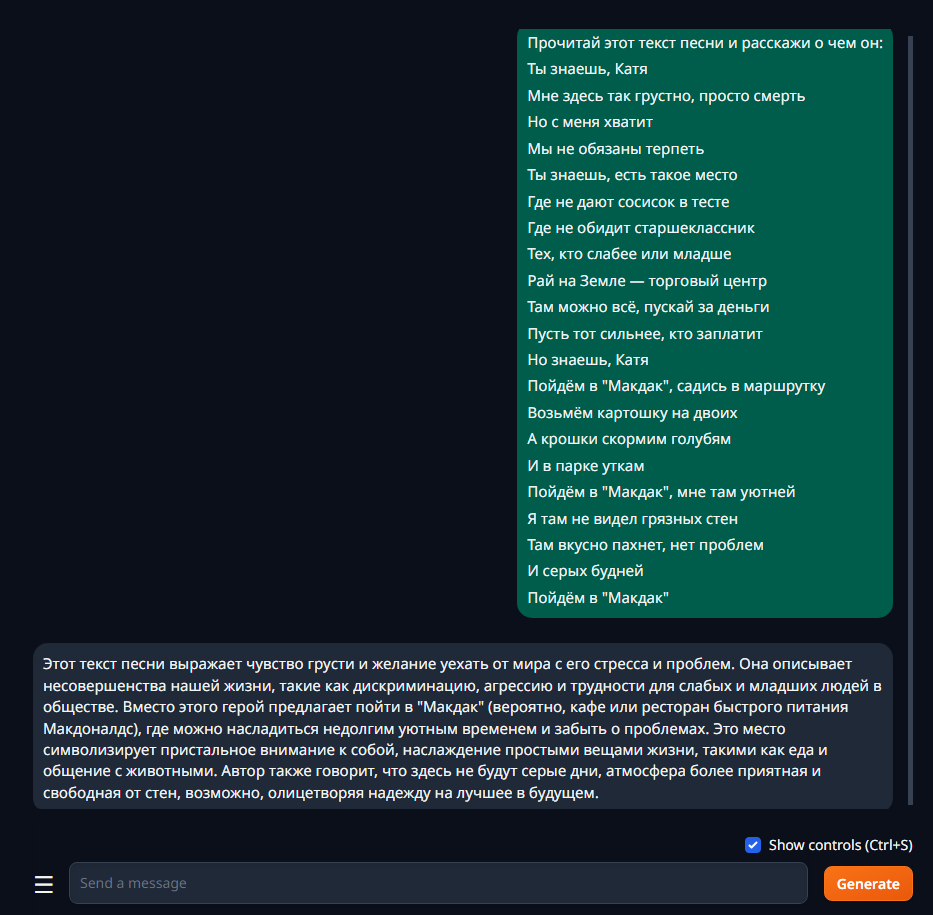
На КПДВ в ответе ИИ - опечатка в названии группы. ИИ тоже по клавиатуре промахивается?
Требуется 14гб памяти или после квантования до 5 bit всего 5гб, что для модели уровня ChatGPT-3.5 хороший результат.
вот только после квантования она станет вообще-то хуже
Ну не факт
тогда в чем логика не квантовать?)) https://habr.com/ru/articles/764598/ тут имеется табличка и чуть подробней про все расписано, и есть вопросы насчет накапливающейся ошибки, т.е. просто так взять скажем 30% вряд ли можно. Ах да, есть же Open LLM Leaderboard, так что и обсуждать нечего
Ну и насчет сравнений с chatgpt: бенчмарки судя по всему открыты и есть подгон под них со стороны участников, кроме chatgpt
для дообучения нужна не квантованная. а так конечно со стороны квантование странно выглядит из 16 бит оставляем только 4-5 и она не сильно проигрывает в качестве.
У кого-нибудь получилось запустить модели через koboldcpp?
Ну у меня получилось всё, что пробовал. Считаю, что это лучший софт для чат-моделей, на голову лучше oobaboga.
Я использую koboldcpp-rocm, что, кстати, по-моему, является единственной опцией для владельцев AMD на Windows.
У меня например. Единственное - схемы с 2 GPU работают с некоторыми приколами если видеопамяти и так на пределе, надо либо подбирать распределение по картам (а там НЕ учитывается похоже место под контекст) либо не трогать в драйверах system memory fallback (или вообще его включить).
Большое спасибо за статью. Извиняюсь, если глупые вопросы, но эти модели можно дергать по API? И как ситуация с цензурой?
В ридми опенчата написано, что можно по апи.
Once started, the server listens at localhost:18888 for requests and is compatible with the OpenAI ChatCompletion API specifications. Please refer to the example request below for reference. Additionally, you can use the OpenChat Web UI for a user-friendly experience.
у почти каждого клиента есть OpenAI-compatible апи сервер, список клиентов тут:
https://huggingface.co/TheBloke/deepseek-coder-33B-instruct-GGUF#about-gguf
по поводу цензуры у deepseek не указано, openchat тоже еще не смотрел. zephyr и mistral не цензурят:
https://huggingface.co/HuggingFaceH4/zephyr-7b-beta#bias-risks-and-limitations
https://huggingface.co/mistralai/Mistral-7B-v0.1#notice
спасибо за статью, про deepseek не знал, интересная модель, до этого крутил mistral и zephyr сначала на LM Studio, потом с text-generation-webui поднял сервис на k8s. памяти на рабочей машине для deepseek coder 33b вроде должно хватить, попробую повторить подвиг первого комметатора :)
Спасибо за наводку на OpenChat. Действительно, лучше себя показывает чем Мистраль, которую использовал до этого.
Все хорошо, а как теперь запустить API чат вот с этим openchat_3.5-q5_K_M.gguf как сервис, что-бы делать запросы по restapi ? :)
на huggingface ниже описания gguf есть список клиентов:
https://huggingface.co/TheBloke/deepseek-coder-33B-instruct-GGUF#about-gguf
они почти все поднимают кроме веб морды с чатом еще и OpenAI-compatible апи сервер
Gpt4All скачайте. Там и менеджер удобный, и встроенный чат, и возможность запустить сервер с OpenAI API.
Кто-нибудь тут пробовал DeepSeek Coder в реальной разработке? Меня, в основном, интересуют подходы к его "затачиванию" на конкретный проект. Как "скормить" ему ~пару сотен MB исходников кодовой базы "с повышающим коэффициентом", чтобы он генерил не абстрактный код, а, например, использовал API библиотек, применяемых в проекте? Файнтюнить? Как? Подсовывать всё в промпт? Есть хорошо работающие примеры?
Imho для (до-)обучения нужно железо помощнее. Для тренировки ChatGpt3 OpenAI использовала
> 285,000 CPU cores, 10,000 GPUs and 400 gigabits per second of network connectivity for each GPU server,
Одна NVidia A100 стоит порядка 20к евро. Большие компании строят кластеры из тысяч таких плат. А сколько это еще электричества потребляет! В аренду можно взять виртуальный сервер с мощными GPU специально для тренировки модели. Видел цены порядка €3-6 за час работы (https://www.oracle.com/cloud/compute/gpu/) А уже натренированную сеть можно гонять локально на более слабом железе. Конкретных рецептов для вашей задачи еще не встречал. У меня на работе исследуют подобную возможность, но пока общедоступных для других команд результатов еще нет. Лучше поискать такое на Reddit (https://www.reddit.com/r/LocalLLaMA/ например) Там и народу побольше и доступность хорошего железа получше.
Кстати DeepSeek-Coder readme содержит инструкцию как до-обучить модель, как готовить правильно данные - https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/README.md#5-how-to-fine-tune-deepseek-coder
Не совсем по статье, просто общий вопрос. Если мне хочется, чтобы контекст общения запоминался постоянно, не для каждой новой сессии? Как пример, дать какую-то инфу о себе, чтобы нейросеть её помнила, не объясняя каждый раз заново. Как я понимаю, это даже не про дообучение модели, а про сохранение контекста. На ум приходят идеи, как это программно закостылить в виде БД, которая подтягивается в каждую сессию. Но не хочется изобретать велосипед, может есть готовые решения?
Надо сказать, что какой-то результат есть. Вот мои эксперименты с OpenChat:
Первая попытка с «говорящими этикетами»
Я:
Что делает этот код. Какие входные параметры? Как работает код?
Для чего используется рекурсия? Проиграй этот код для входных значений: EAX = 321, ECX = 16, EDI = 1000h
num2str:
cmp eax,ecx
jb .less_than_radix
xor edx,edx
div ecx
push edx
call num2str
pop eax
.less_than_radix:
cmp al, 10
sbb al, 69h
das
stosb
ret
OpenChat:
Этот код преобразует десятичное число, заданное в регистрах EAX в строковое представление в регистре EDI. Рекурсия используется для преобразования числа в строку до тех пор, пока число не станет меньше радикса (в данном случае 16).
Входные параметры:
EAX - десятичное число, которое нужно преобразовать в строку.
ECX - радикс (количество символов в числе).
EDI - адрес начала строкового буфера, в который будет записано строковое представление числа.
Код работает следующим образом:
Сравнивается значение EAX с ECX. Если EAX меньше ECX, выполняется переход к метке .less_than_radix.
Если EAX больше или равно ECX, выполняется деление EAX на ECX с помощью инструкции DIV и результат деления записывается в регистр EDX.
Затем EDX push-ается на стек, и вызывается сама функция num2str с переходом к метке .less_than_radix.
После вызова функции num2str, выполняется pop эксклюзивного адреса EAX, чтобы вернуть значение EDX с стека.
Метка .less_than_radix выполняет следующие действия:
a. Сравнивается значение AL (нижший байт EAX) с 10. Если AL меньше 10, выполняется сдвиг вправо AL на 1 и записывается результат в AL.
b. Затем выполняется сравнение AL и 69h (105 в десятичной системе счисления). Если AL больше 105, выполняется сдвиг влево AL на 1 и записывается результат в AL.
c. Записывается в строковый буфер EDI значение AL.
d. Увеличивается адрес EDI на 1.
Функция num2str заканчивает свою работу, когда EAX станет меньше ECX.
Выполнение кода для входных значений EAX = 321, ECX = 16, EDI = 1000h:
Сравнение EAX и ECX дает false, поэтому переход к метке .less_than_radix.
Сравнение AL и 10 дает false, поэтому переход к метке .less_than_radix.
Запись в строковый буфер EDI значения AL (32) и увеличение адреса EDI на 1.
Сравнение AL и 10 дает false, поэтому переход к метке .less_than_radix.
Запись в строковый буфер EDI значения AL (2) и увеличение адреса EDI на 1.
Сравнение AL и 10 дает false, поэтому переход к метке .less_than_radix.
Запись в строковый буфер EDI значения AL (1) и увеличение адреса EDI на 1.
Теперь EAX стало меньше ECX, поэтому функция num2str заканчивает свою работу.
После выполнения кода в строковом буфере EDI будет записано "321".
Стоит изменить наименование этикетов, и понимание улетучивается:
Вторая попытка с «абстрактными этикетами»
Я:
Что делает этот код. Какие входные параметры? Как работает код?
Для чего используется рекурсия? Проиграй этот код для входных значений: EAX = 321, ECX = 16, EDI = 1000h
start:
cmp eax,ecx
jb .less
xor edx,edx
div ecx
push edx
call start
pop eax
.less:
cmp al, 10
sbb al, 69h
das
stosb
ret
OpenChat:
Этот код реализует рекурсивную процедуру, которая выполняет следующие действия:
Сравнивает значения регистров EAX и ECX. Если EAX меньше ECX, то переходит к метке .less.
Если EAX больше или равно ECX, выполняет деление EAX на ECX с помощью инструкции DIV и сохраняет остаток в регистре EDX. Затем вызывает саму себя с помощью инструкции CALL, что означает, что это рекурсивная функция.
После рекурсивного вызова функции, выполняет обратное вызов (RET) с помощью инструкции POP и сохраняет значение EAX в стеке.
Метка .less содержит код, который выполняется, когда EAX меньше ECX. Он сравнивает значение AL (нижших 8 бит EAX) с числом 10. Если AL меньше 10, то выполняет сравнение AL и 69h (105 в десятичной системе счисления) с помощью инструкции SBB (сравнение с установлением знакового флага). Затем выполняет инструкцию DAS (дополнительная сумма), которая меняет местами младшие и старшие байты регистра EDI. Затем выполняет инструкцию STOSB, которая записывает значение AL в память по адресу EDI и увеличивает EDI на 1.
После выполнения метки .less, код возвращается из рекурсивного вызова с помощью инструкции RET.
Входные параметры для этого кода:
EAX - значение, на котором выполняется операция.
ECX - значение, с которым выполняется деление.
EDI - указатель на начало области памяти, в которую будут записываться результаты вычислений.
Рекурсия используется для реализации деления с остатком в этом коде. Благодаря рекурсии, код может легко выполнить деление на число ECX без использования стандартной инструкции DIV.
Тем не менее, результат вполне приемлем. Ведь и не все программисты сразу поймут что это такое и как работает. А нейросетка хоть что-то вменяемое пишет.
Попробовал попросить ее переписать этот код, но без рекурсии. Она знает, что так можно, но так как не понимает рекурсию, то и развернуть ее в цикле не получается.
А как запустить то все это дело именно в режиме таком, который предлагает демо-сайт? Демо впечатляет. Я уже раз 10 перечитал статью, все скачал, а как это запускать не очень врубился. Т.е. модель еще переквантизовать надо, если комп не с 32 гигами озу? Видеокарта то нужна или нет? И экешников нигде нет, а я ж виндузятник. с SD нормально разобрался, и первую ламу одну из - поставил и оно там даже что то работало. А тут? Помогите. Не могу разобраться.
но она ощутимо превосходит Alpaca, Vicuna и прочие открытые модели
Alpaca? Vicuna? Вы из какого года?
Что по сравнению с Zephyr, OpenHermes, Yi?

Попытал openchat с релятивистскими скоростями сначала на русском:

и потом на английском:

после того как подсказал формулу расчета он почти справился) помогла вторая подсказка)

На днях вышла новая модель с новой архитектурой от тех же разработчиков как и Mistral, на основе которой сделана OpenChat - Mixtral 8x7B (https://habr.com/ru/articles/780204/)
Она тяжелее, чем просто 7B модели, но при этом Q4_K_M ощутимо лучше выдает ответы, чем обычные 7B модели:

Спасибо за статью ? А насколько GPU влияет на производительность и скорость обработки при условии среднемощного CPU? А в случае с CPU имеют ли смысл системы Dual-CPU на тех же Xeon (понятное - из ныне бюджетного б/у)? Не столько профцели, сколько просто спортивный интерес
Как подключить к нему свой набор данных (например, архив хабра)?
Если кому вдруг нужно побаловаться, запустил для OpenChat интернет-инстанс с доступом по OpenAI API (у меня куча сеток по нему доступны, а теперь и он тоже)
спасибо, собрал себе сборку на пк, запускается секунд 10, отвечает быстро, потребляет 15гб ram и 8гб vram
gpt4all удобен для локального использования. Но не могу понять, как его заставить слушать не только localhost, чтобы обращаться по API с других машин из ЛВС. Или не мучиться и для работы через API что-то другое использовать?
Также хотел ChatGPT плагин VSCode с ним сопрячь. Но в нем хоть gpt4all и поддерживается, но только модель replit конкретной версии (а у меня скачалась более свежая).
Зоопарк держать не хочется. Хочется что-то одно и для просто Web запросов чата, и для дерганья из python, и для помощи с кодом из VS Code (модели, конечно, разные). Что посоветуете?
Изменить эту строчку, подставив тупо строку с ip адресом
в принципе, если используешь llama.cpp то туда сервер уже встроен, необходимости в запускалке особой нет
Чего-то странное с llava-v1.5-13b-q5_k творится. На картинку с кошкой, где кот прямо посреди, пишет: The image depicts a person standing on top of a hill, overlooking the beautiful ocean view. They are wearing a backpack and seem to be enjoying their outdoor adventure in this picturesque landscape.
А на картинку с бегущей собакой: The image features a white bird with long feathers, likely a heron, standing on top of a branch. It appears to be in a wetland or marshy area, surrounded by water and possibly other wildlife. There are several ducks floating nearby as well, adding to the natural beauty of the scene.
ХЗ, в чём проблема.
А то что на первом скриншоте ИИ группу обозвал "Гражданская ОБНОРА" никого не смутило? ;-)
И написана песня не в 1984 году )
Насколько я понимаю в сетке и так не чтобы содержатcя все данные всего интернета (в файле то на 4-15гб), а уж после квантования вы получаете приблизительные ответы. Надеятся на 100% дат часов и прочего там нет смысла.
Я так понимаю именно квантование приводит к смещениям типа : Оборона- обнора, в слове карапуз 8 букв, хоть усрись (даже если попросить разложить по буквам), и ленин родился в 1780, а борщ оранжевого цвета потому что его варят из свиньи и цветной капусты и его часто едят холодным как салат. (Openchat 3.5 Q4)
Вы правы, но много ли людей на свете знает когда родился ленин, как варить и есть борщ? Тут как раз важно чтобы ии научился осозновать свою ограниченность и давать негативные ответы, когда нет достаточных оснований для позитива. А вот если ии подключить к интернету (хотя бы к википедии), чтобы можно было находить фактический материал и встроить это в логику генерации ответов, не просто отсылка к ресурсу, а построение логических цепочек, то это повысит интеллектуальность сетей и ии шагнет на следующую ступеньку. И такие подвижки уже есть в свежих реализациях
Кажется квантование работает на нейронку по другому - количество параметров в языковых моделях абсурдно высокое (да не важно что за модель, пусть и распознавание изображений), значительно превышает необходимое. Каждый вес не хранит каждый байт, условно там набор критериев, описываемых кривыми, образуемыми условным полиномом, который складывается из них, так вот эти критерии не обязательно (а скорее всего) не такие какими мы могли бы их представить, это не кошечка состоит из ушек хвостика и шерсти, а что то типа шерстинки вот так заглажены, переход цветовых пятен друг в друга описывается таким уравеннием, длина шерстинок в ухе на столько длиннее шерстинок на хвосте и сотни других таких же абсурдно странных параметров, а потом параметров поверх выводов на основе этих параметров и так сотни уровней вложенности.
Эта вложенность определяет критерий как объединение этих параметров особым образом и так, что если какая то часть критериев уже не такая какой была бы если бы мы не ломали сетку квантизацией, уравнение все равно посчитает этот набор критериев - котом, ну может на каких то граничных (для сетки, но не для нас) ситуациях, не кот а хомяк, или пирог,....
В случае с llm-ками, при квантизации, будут повышаться вероятности сгенерировать 'не тот' следующий токен, из может быть и близких к текущей ситуации (т.е. слова все еще верные например, и запятые верно поставлены, но более глубокий смысл уже плохо подходит). Т.е. больше галлюцинаций!
p.s. это значит, хорошие малые llm-ки типа 7b mistral не желательно ломать квантизацией, там каждый следующий потерянный бит информации несет разрушений больше, чем тот же потерянный бит но 70b llama (даже если они будут вести себя на данном домене одинаково)
Я согласен, что квантизация - это зло. Но это не проблема сетки, а технические ограничения пользователей, которые хотят хоть как-то запустить ее. Грубо говоря - нет денег/времени/и пр на жену, поищу девушку на раз, нет денег на экскортницу, поищу что подешевле :-) А другие не готовы жертвовать качеством и ищут спутницу на всю жизнь. Хотел бы я иметь возможность прикупить NVidia A/H100, а может и не одну, но нет у меня лишних €20к и прямо сейчас нет задач адекватным таким расходам.
Локальные нейросети. Аналог ChatGPT-3.5 на домашнем ПК: OpenChat 7B превосходящая 70B, DeepSeek для кода уровня ChatGPT