
Немного о предыдущих статьях этой серии:
В первой части мы обсудили пользовательские сценарии.
Во второй части мы рассмотрели трудности реализации автодополнения с помощью эвристик и пришли к выводу, что нам нужно машинное обучение.
В третьей части мы узнали, какие данные об автодополнении можно собрать из IDE.
Теперь хочется поделиться специфическими проблемами, возникшими у нас при обучении модели, и решениями, которые мы для этих проблем придумали.
В прошлый раз мы остановились на том, что из-за необходимости защищать код пользователей даже от себя самих нам необходимо анонимизировать все собранные данные. Вызову окна автодополнения сопоставляется набор параметров, каждый из которых — либо число, либо перечислимый тип. А вот сам код, на котором пользователь вызвал окно, мы не сохраняем.
Если при сборе данных мы допустим ошибку, нельзя будет просто заглянуть в код и все понять. Нам придется устраивать целое расследование без всякой гарантии успеха.
Пример расследования
Однажды через логи мы заметили группу пользователей, которые очень редко пользуются подсказками автодополнения. От такой частоты ожидаешь распределения, похожего на нормальное, ну, или, возможно, второго пика в нуле (мало ли есть какие-то люди, которые никогда подсказками не пользуются). Но второй пик вблизи нуля никаким здравым смыслом не объяснить. Пришлось разбираться.
А как разбираться?
Эти «странные» пользователи — примерно такие же активные, как и обычные.
Языки программирования они используют тоже разные.
Окно автодополнения у них открывается так же часто, как у других.
Короче, обычные люди. Только почему-то подсказками редко пользуются. Довольно быстро мы выяснили, что у них в IDE, оказывается, сломана сортировка подсказок: значения релевантности верхних позиций в среднем гораздо ниже, чем у обычных пользователей.
Знаете, что выяснилось? У них у всех в настройках стояла галочка:
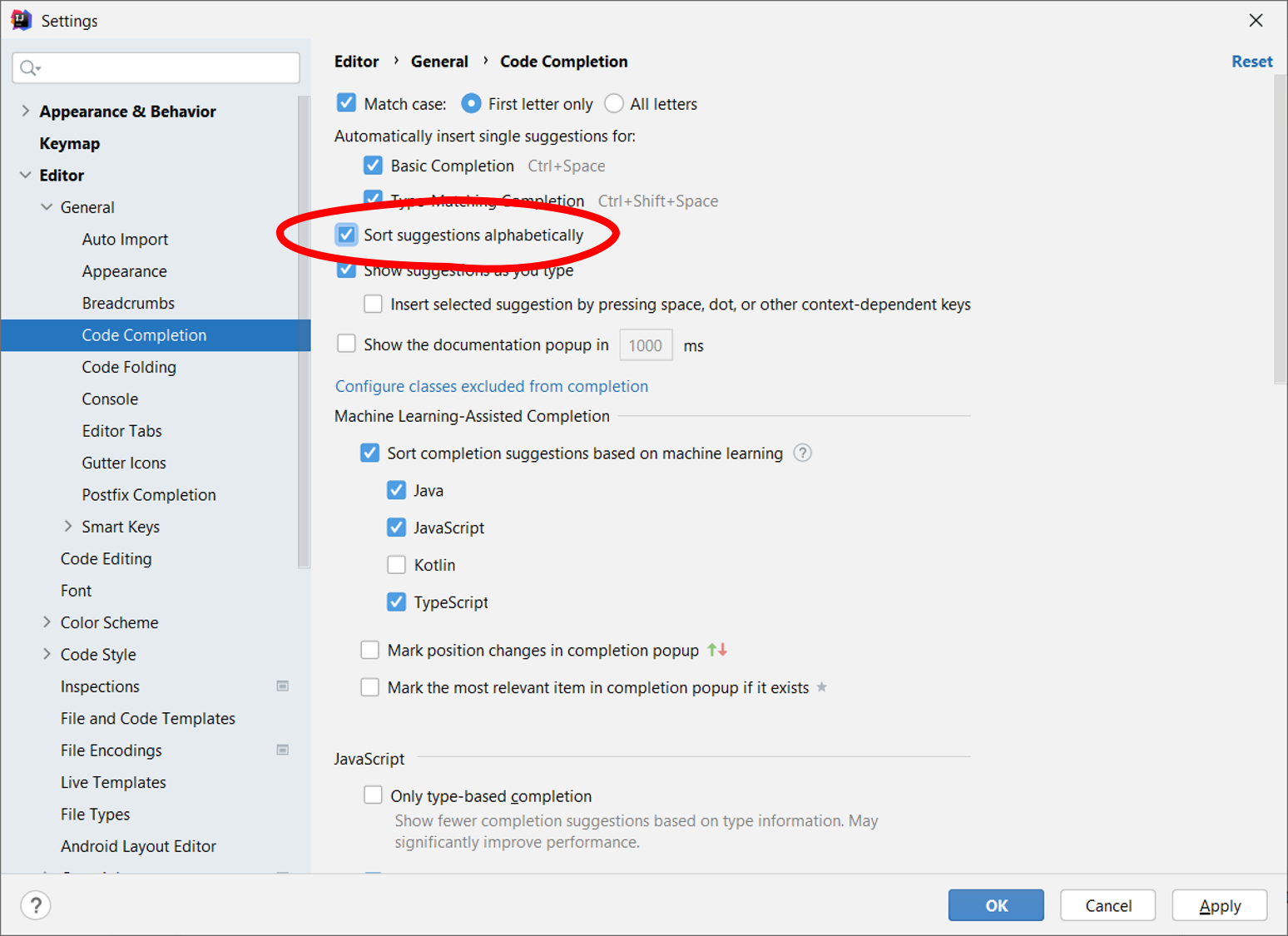
При сортировке по алфавиту объективно лучший результат часто и в экран-то не влезает. Где уж там кликать на него.
Теперь у нас появился еще один параметр перечислимого типа в логах — включена ли у пользователя алфавитная сортировка. Тех, у кого включена, мы отовсюду исключаем: и из датасета для обучения, и из экспериментов.
А если у вас эта галочка тоже включена, не сочтите за труд, расскажите нам в комментах, зачем вы ее включили?
Целевая метрика
Исключение пользователей с алфавитной сортировкой из выборки — единственное, что мы делаем для очистки данных. В остальном все готово, можно начинать обучаться. Прежде всего нужно решить, какой показатель оптимизировать.
У нас было несколько подходов к снаряду.
Средняя позиция верного ответа
В стандартной реализации Random Forest в Scikit-learn есть метрика RMSE (Root Mean Square Error) — среднеквадратическая ошибка. Это была первая метрика, которую мы попробовали. В результате оптимизации RMSE отклонение верного ответа от нулевой позиции действительно уменьшилось (в среднем по больнице).
В нашем случае, увы, это не лучший вариант. Поднимать в ранжировании релевантные результаты хоть на сколько-нибудь — нормальная стратегия, но только если релевантных результатов много. Этим мы отличаемся от поисковой системы.
Представим себе, что мы проводим научное исследование систем автодополнения и задаем в поисковике (Google, Яндекс, Bing, DuckDuckGo) запрос:
[code completion relevance]
В ответ мы можем получить такие результаты на первых позициях:
Статья «Code Completion» с сайта WebStormМы очень любим сайты JetBrains, но в контексте задачи эта статья, к сожалению, нерелевантна. Впрочем, сортировка по релевантности в ней упоминается восемь раз.
Страница на researchgate.net, посвященная исследовательской статье на нужную тему за авторством ученых из университета Дармштадта. Текста самой статьи на странице нет, но есть кнопка, позволяющая запросить его у авторов. Я этой кнопкой ни разу в жизни не пользовался, поэтому не знаю, какая тут конверсия. Не огонь, но лучше чем ничего.
Learning from Examples to Improve Code Completion SystemsА тут нам показывают полный текст той самой статьи, которую мы поленились запросить в предыдущем документе. Это релевантный результат.
На примере этих трех результатов видно, что есть как минимум три разные градации релевантности в веб-поиске (на самом деле обычно используют пять). Также мы видим, что релевантных результатов может быть больше одного. Чтобы улучшить качество, достаточно перетащить на одну позицию вверх любой из двух нижних документов.
Но в случае автодополнения релевантность строго бинарна, а релевантный результат ровно один — имя, которое набирает пользователь.
С точки зрения RMSE правое окно гораздо лучше левого:
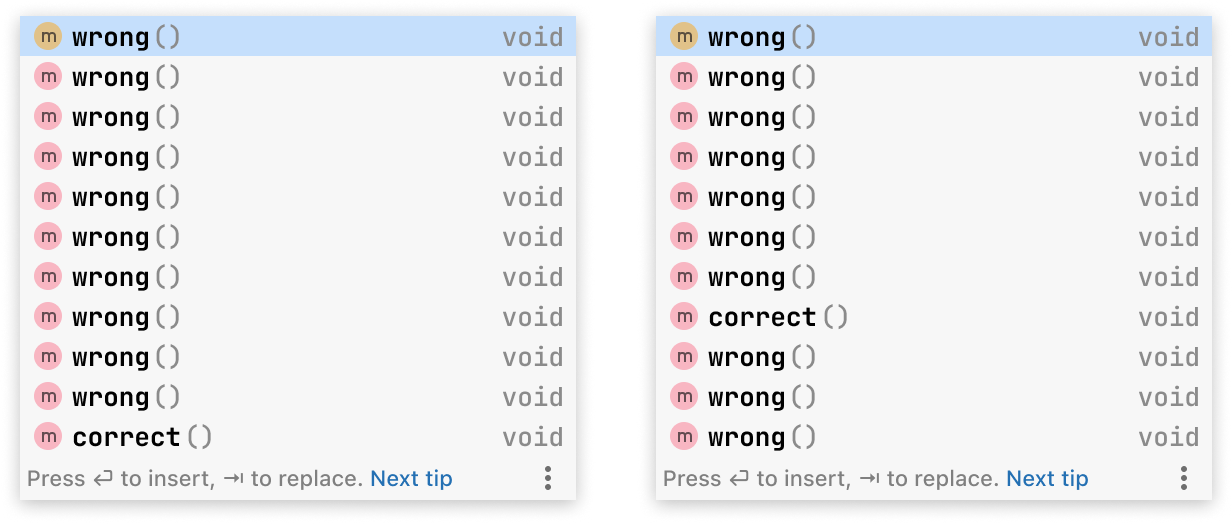
При этом с продуктовой точки зрения они оба плохи. Многие случаи «улучшения» ранжирования, которые мы видели при оптимизации RMSE, были именно такой природы. Если модели удалось поднять правильный результат с сотой позиции на тридцатую, то, хоть формально это и улучшение, но для пользователя — ничего не меняется.
Верный ответ на первой позиции
Нет ли такой метрики, при которой улучшением считается только попадание правильного ответа на самый верх ранжирования?
Random Forest этого по умолчанию не предлагает. Чтобы не писать метрику самим, мы попробовали CatBoost, в котором «из коробки» есть QuerySoftMax. Насколько мы знаем, эта метрика была впервые предложена под именем loss-функции ListNet в статье группы исследователей из Университета Цинхуа, Национального Университета Тайваня и Microsoft Research.
Мы обучили наш комплишен с помощью CatBoost с целевой метрикой QuerySoftMax, и в A/B-тестах его успешность выросла на 10%! Успешными мы считаем те случаи, когда люди выбирают одну из подсказок.
Когда эйфория слегка рассеялась, мы задумались, в чем причина: то ли дело в метрике, то ли CatBoost сам по себе гораздо лучше. Это несложно проверить: RMSE в CatBoost тоже есть. Мы научили формулу на связке CatBoost + RMSE, и эксперимент дал нам те же самые результаты, что и Random Forest. Отсюда мы и заключили, что дело все-таки в метрике.
Выводы
Во-первых, на наших анонимизированных данных без доступа к коду пользователей обучить модель для ранжирования подсказок автодополнения возможно. Вот же она, работает.
Во-вторых, выбор целевой метрики для решения задачи играет ключевую роль. В нашем случае стремление к лучшей метрике сподвигло нас сменить фреймворк для обучения, и это оказалось хорошим решением. В случае задач ранжирования, для которых существует единственный релевантный результат, отлично подходит QuerySoftMax.
Что дальше
У нас есть для вас еще одна статья про автодополнение — последняя. Она касается оценки качества.
Как протестировать окно автодополнения до того, как результат увидят пользователи? Как проводить A/B-тесты на десктопных приложениях? Как получать значимые результаты на выборке из 1000 пользователей? Мы этому всему научились. Скоро соберемся и обо всем расскажем.
