Hello, Habr! My name is Roman. Today I would like to share a story of how we at Innopolis University developed a test stand and a service for Acronis Active Restore system, which will soon become part of the company’s product range. Those interested to know how the University builds its relationship with industrial partners are welcome to click the «Read More» button.

Acronis started the development of the Active Restore in-house, but being Innopolis University students, we participated in this process as an academic and industrial project. Daulet Tumbayev, my supervisor (and now colleague), has already discussed the project idea and architecture in his post. Today my story is about how we prepared the service on the Innopolis side.
It all started in summer when we were informed that during our first term we would have a visit from IT companies: they were to offer us their ideas for practical work. In December 2018, we were presented with 15 various projects, and by the end of the month, we had the priorities sorted out and got an idea of what we liked best.
All undergraduates filled out a form, where they had to choose four projects in which they wanted to participate. The choice had to be motivated: why me and why those projects. For example, I stated that I had experience in system programming and C/C++ development. Most importantly, the project allowed me to further develop my skills and to continue growing.
Two weeks later, we got our assignments, and our work on the projects started in the beginning of the second term. The team was assembled. At our first meeting, we assessed each other's strengths and weaknesses, and defined roles.
During the first two weeks, we had to launch the process. We established contacts with the customer, formalized the project requirements, launched the iterative process, and set up the working environment.
By the way, our collaboration with the customer intensified when we started to take elective courses. The thing is, that Acronis experts are teaching a few elective courses at the Innopolis University (and others). Alexei Kostyushko, the leading developer of the Kernel team, is a regular lecturer on two courses: Reverse Engineering and Windows Kernel Architecture and Drivers. As far as I know,system programming and multithreaded computing courses are planned for the future. Most importantly, all of those courses are built to help the students carry out their industrial projects. They significantly enhance your understanding of the subject matter thus facilitating your work on the project.
That allowed us to start more «brightly» than other teams, and interaction with Acronis became stronger. Alexei Kostyushko was our Product Owner sharing with us the necessary expertise in the domain. His elective courses enhanced our hard skills significantly, and prepared us well to perform our task.
For all teams, the first month was the most challenging. Everyone was lost, and nobody knew what to start with. Should we write the documentation first or plunge straight into coding? Comments received from our University supervisors and mentors often contradicted those made by the company representatives.
When things settled down (at least, in my head), it became clear that the University mentors helped us build relationships within the team and prepare documentation. However, the real breakthrough point was Daulet’s visit in March. We just sat down and spent our weekend working on the project. That was the moment when we reconceived the project, «hit the reset button», re-prioritized the tasks, and rushed forward. We understood what we needed to launch the experiment (discussed below) and to develop the service. Since then, our general understanding has transformed into a clear plan. We actually started coding, and in 2 weeks, we developed the first version of the test stand, which included virtual machines, necessary services, and the code for automating the experiment and collecting data.
It should be noted that, along with working on our industrial project, we also attended the academic courses, which enabled us to build the right architecture for our projects and to organize Quality Management. At first, these activities had consumed 70 to 90% of our weekly time, but those time investments later proved to be necessary to avoid issues during development. The University’s goal was to teach us to properly organize the development process, while companies, as customers, were mostly interested in the result. This certainly added some commotion but helped us blend our theoretical knowledge with practical skills. We were motivated by the reasonably high complexity and workload, and that resulted in a successful project.
Initially, two people in our team engaged in the development, one person was charged with the documentation, and another one plunged into the environment setup. However, later three other bachelors joined us, and we formed a well-knit team. The University decided to launch a trial industrial project for third-year students. Expanding the team from four to seven people significantly accelerated the process, as our bachelors could easily perform development-related tasks. Ekaterina Levchenko helped us with Python code and batch scripts for the test stand. Ansat Abirov and Ruslan Kim acted as developers; they selected and optimized algorithms.
We kept this format of working until the end of May when the experiment setup was completed. For the bachelors, that was the end of the industrial project. Two of them started their internships with Acronis and continued working with us. Therefore, after the end of May, we were working as a single team of six people.
We had the third term ahead; at Innopolis, it is free from academic activities. We only had two elective courses, while the rest of our time was dedicated to the industrial project. It was during the third term that our work on the service intensified. The development process was established and ongoing and we regularly submitted demos and reports. We were working like that for 1.5 months and, by the end of July, the development part of our work was practically finished.
At the start, we defined the requirements to the service, which had to adequately liaise with the file system mini-filter driver (to learn what it is, read here) and thought through its architecture. Aiming to simplify further support of our code, we envisaged a module approach right from the start. Our service comprised several managers, agents and handlers, and even before the coding started, we had ensured the possibility of working simultaneously.
However, after we discussed the architecture at a meeting with Acronis people, it was decided to first carry out the experiment, and then turn to the service itself. As a result, the development only took 2.5 months. The rest of the time was dedicated to conducting the experiment in order to find the minimum set of files, which would be enough to run Windows. In a real system, this set of files is generated by the driver; however, we decided to find it heuristically using the bisection method, in order to test the driver's performance.
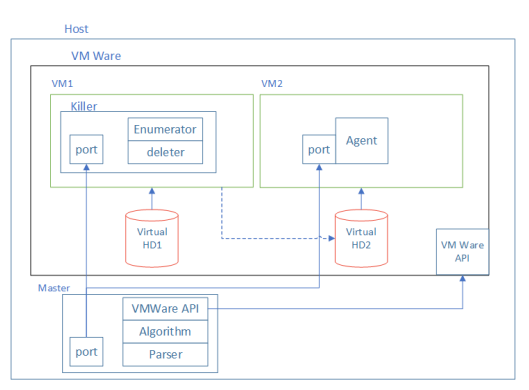
The experiment stand
To achieve that, we assembled a stand scripted in Python, comprising two virtual machines. One of them ran Linux, while the other loaded Windows. Two disks were configured for them: Virtual HD1 and Virtual HD2. Both disks were linked to VM1, which ran Linux. On the HD1 of that VM, we installed a Killer application, which «damaged» HD2. «Damage» means deleting some files from the disk. HD2 was the boot disk for VM2 running Windows. Once the disk was «damaged», we tried to start VM2. If we managed to do that, it meant that the files deleted from the disk were not critical for booting.
In order to automate that process, we tried to use a preliminary elaborated approach, rather than deleting files randomly. The algorithm consisted of three steps:
We decided to start with modeling the algorithm functioning. Suppose, there are 1,000,000 files in the file system. In this case, the search of critical files was the most efficient when the number of critical files was around 15% of the total.
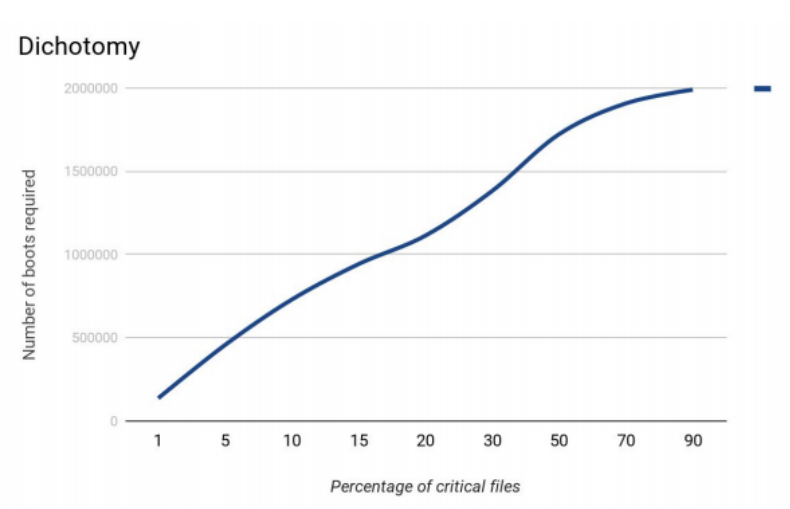
Bisection method.
At first, we had a great deal of problems with our experiment. In two to three weeks, the test stand was ready. Another one to 1.5 months were spent debugging, writing more code, and using various kinds of tricks to make the stand work.
The most challenging thing was to find a bug related to caсhing disk operations. The experiment was running for two days and produced quite optimistic results, which exceeded those of the simulations manifold. However, the test for critical files failed, the system did not start. It turned out that in case of a forced shutdown of the virtual machine, the delete operations cached by the file system were never executed. Consequently, the disk was not completely erased. That entailed the algorithm producing wrong results, and it took us a couple of days of intensive thinking to puzzle it out.
At a certain point, we noted that if the algorithm was running for a long time, it «dug» into one of the file system segments, trying to delete the same files (hoping for a new result). This happened when, having selected a bad interval for deletion, the algorithm was stuck in the areas where the majority of files were critical. At that moment, we decided to add the file list reshuffling, that is, the file list was rebuilt in a few iterations. This helped us to «pull» the algorithm out of such sticking.
When everything was ready, we set those two VMs to run for three days. There were about 600 iterations made, of which over 20 successful bootings. It became clear that the experiment might be launched to run for a long time and on more powerful machines, in order to find the optimal set of files to boot Windows. The work of the algorithm could also be distributed among several machines to further accelerate this process.
In our case, apart from Windows, the disk only contained Python and our service. It took us three days to reduce the number of files from 70,000 to 50,000. The file list shrank by only 28%, but it became clear that our approach works and allows determining the minimal set of files necessary to boot the OS.
Let us have a look at the service structure. The main module of the service is the sequence manager. Since we receive the file list from the driver, we need to recover files following this list. Therefore, we created our prioritized sequence.

We have a list of files to recover one after another. In case of new access requests, urgently needed files will be prioritized for recovery. Therefore, the files that the user actually needs right now are placed in the head of the sequence, while those that will probably be needed in the future, are put in its end. However, if the user works intensively, it may lead to a «sequence of out-of-sequence objects», and a list of files being recovered right now. In addition, the search operation was to be applied to all those sequences at once. Unfortunately, we were unable to implement a sequence, which would set several priorities for the files, and at the same time support the search option and change priorities «on the go». We did not want to fit into the existing data frameworks; therefore, we had to create our own one, and set it up for working.

Our service will first communicate with the driver elaborated by Daulet, and after that, with the components responsible for restoring the files. Therefore, we started with creating a small emulator of the recovery system, which would be able to retrieve files from a removable disk, in order to restore them and test the service.
Two working modes were envisaged: the normal mode and the recovery mode. In the normal mode, the driver sends us a list of files affected at the OS launch. Then, as the system functions, the driver monitors all operations and files and sends notifications to our service. The service then makes changes to the list of files. In the recovery mode, the driver notifies the service of the necessity to restore the system. The service makes a sequence of files, launches software agents that request backup files, and starts the recovery process.
Once the service was ready and tested, we were left with one last project-related activity. We needed to update and streamline all artefacts that we had accumulated, and to present our results to the customer and to the University. For the company, it was another step towards the implementation of the project, while for the University, it was our final thesis.
Based on the presentation results, the students received job offers. In a few weeks, I will start my career with Acronis. The project results brought the idea that the service performance could be enhanced by lowering it to the Native Windows Application level. That will be discussed in our next article.
Acronis started the development of the Active Restore in-house, but being Innopolis University students, we participated in this process as an academic and industrial project. Daulet Tumbayev, my supervisor (and now colleague), has already discussed the project idea and architecture in his post. Today my story is about how we prepared the service on the Innopolis side.
It all started in summer when we were informed that during our first term we would have a visit from IT companies: they were to offer us their ideas for practical work. In December 2018, we were presented with 15 various projects, and by the end of the month, we had the priorities sorted out and got an idea of what we liked best.
All undergraduates filled out a form, where they had to choose four projects in which they wanted to participate. The choice had to be motivated: why me and why those projects. For example, I stated that I had experience in system programming and C/C++ development. Most importantly, the project allowed me to further develop my skills and to continue growing.
Two weeks later, we got our assignments, and our work on the projects started in the beginning of the second term. The team was assembled. At our first meeting, we assessed each other's strengths and weaknesses, and defined roles.
- Roman Rybkin, Python/C++ developer.
- Eugene Ishutin, Python/C++ developer responsible for the company contacts.
- Anastasia Rodionova, Python/C++ developer responsible for writing documentation.
- Brandon Acosta, environment setup, preparing the stand for experiments and testing.
During the first two weeks, we had to launch the process. We established contacts with the customer, formalized the project requirements, launched the iterative process, and set up the working environment.
By the way, our collaboration with the customer intensified when we started to take elective courses. The thing is, that Acronis experts are teaching a few elective courses at the Innopolis University (and others). Alexei Kostyushko, the leading developer of the Kernel team, is a regular lecturer on two courses: Reverse Engineering and Windows Kernel Architecture and Drivers. As far as I know,system programming and multithreaded computing courses are planned for the future. Most importantly, all of those courses are built to help the students carry out their industrial projects. They significantly enhance your understanding of the subject matter thus facilitating your work on the project.
That allowed us to start more «brightly» than other teams, and interaction with Acronis became stronger. Alexei Kostyushko was our Product Owner sharing with us the necessary expertise in the domain. His elective courses enhanced our hard skills significantly, and prepared us well to perform our task.
From Reflections to the Project
For all teams, the first month was the most challenging. Everyone was lost, and nobody knew what to start with. Should we write the documentation first or plunge straight into coding? Comments received from our University supervisors and mentors often contradicted those made by the company representatives.
When things settled down (at least, in my head), it became clear that the University mentors helped us build relationships within the team and prepare documentation. However, the real breakthrough point was Daulet’s visit in March. We just sat down and spent our weekend working on the project. That was the moment when we reconceived the project, «hit the reset button», re-prioritized the tasks, and rushed forward. We understood what we needed to launch the experiment (discussed below) and to develop the service. Since then, our general understanding has transformed into a clear plan. We actually started coding, and in 2 weeks, we developed the first version of the test stand, which included virtual machines, necessary services, and the code for automating the experiment and collecting data.
It should be noted that, along with working on our industrial project, we also attended the academic courses, which enabled us to build the right architecture for our projects and to organize Quality Management. At first, these activities had consumed 70 to 90% of our weekly time, but those time investments later proved to be necessary to avoid issues during development. The University’s goal was to teach us to properly organize the development process, while companies, as customers, were mostly interested in the result. This certainly added some commotion but helped us blend our theoretical knowledge with practical skills. We were motivated by the reasonably high complexity and workload, and that resulted in a successful project.
Initially, two people in our team engaged in the development, one person was charged with the documentation, and another one plunged into the environment setup. However, later three other bachelors joined us, and we formed a well-knit team. The University decided to launch a trial industrial project for third-year students. Expanding the team from four to seven people significantly accelerated the process, as our bachelors could easily perform development-related tasks. Ekaterina Levchenko helped us with Python code and batch scripts for the test stand. Ansat Abirov and Ruslan Kim acted as developers; they selected and optimized algorithms.
We kept this format of working until the end of May when the experiment setup was completed. For the bachelors, that was the end of the industrial project. Two of them started their internships with Acronis and continued working with us. Therefore, after the end of May, we were working as a single team of six people.
We had the third term ahead; at Innopolis, it is free from academic activities. We only had two elective courses, while the rest of our time was dedicated to the industrial project. It was during the third term that our work on the service intensified. The development process was established and ongoing and we regularly submitted demos and reports. We were working like that for 1.5 months and, by the end of July, the development part of our work was practically finished.
Technical Details
At the start, we defined the requirements to the service, which had to adequately liaise with the file system mini-filter driver (to learn what it is, read here) and thought through its architecture. Aiming to simplify further support of our code, we envisaged a module approach right from the start. Our service comprised several managers, agents and handlers, and even before the coding started, we had ensured the possibility of working simultaneously.
However, after we discussed the architecture at a meeting with Acronis people, it was decided to first carry out the experiment, and then turn to the service itself. As a result, the development only took 2.5 months. The rest of the time was dedicated to conducting the experiment in order to find the minimum set of files, which would be enough to run Windows. In a real system, this set of files is generated by the driver; however, we decided to find it heuristically using the bisection method, in order to test the driver's performance.
The experiment stand
To achieve that, we assembled a stand scripted in Python, comprising two virtual machines. One of them ran Linux, while the other loaded Windows. Two disks were configured for them: Virtual HD1 and Virtual HD2. Both disks were linked to VM1, which ran Linux. On the HD1 of that VM, we installed a Killer application, which «damaged» HD2. «Damage» means deleting some files from the disk. HD2 was the boot disk for VM2 running Windows. Once the disk was «damaged», we tried to start VM2. If we managed to do that, it meant that the files deleted from the disk were not critical for booting.
In order to automate that process, we tried to use a preliminary elaborated approach, rather than deleting files randomly. The algorithm consisted of three steps:
- Split the file list in two halves.
- Delete files in one of the two halves.
- Try to boot the system. If the system started, add the deleted files to the «unnecessary» list. Otherwise, go back to step 1.
We decided to start with modeling the algorithm functioning. Suppose, there are 1,000,000 files in the file system. In this case, the search of critical files was the most efficient when the number of critical files was around 15% of the total.
Bisection method.
At first, we had a great deal of problems with our experiment. In two to three weeks, the test stand was ready. Another one to 1.5 months were spent debugging, writing more code, and using various kinds of tricks to make the stand work.
The most challenging thing was to find a bug related to caсhing disk operations. The experiment was running for two days and produced quite optimistic results, which exceeded those of the simulations manifold. However, the test for critical files failed, the system did not start. It turned out that in case of a forced shutdown of the virtual machine, the delete operations cached by the file system were never executed. Consequently, the disk was not completely erased. That entailed the algorithm producing wrong results, and it took us a couple of days of intensive thinking to puzzle it out.
At a certain point, we noted that if the algorithm was running for a long time, it «dug» into one of the file system segments, trying to delete the same files (hoping for a new result). This happened when, having selected a bad interval for deletion, the algorithm was stuck in the areas where the majority of files were critical. At that moment, we decided to add the file list reshuffling, that is, the file list was rebuilt in a few iterations. This helped us to «pull» the algorithm out of such sticking.
When everything was ready, we set those two VMs to run for three days. There were about 600 iterations made, of which over 20 successful bootings. It became clear that the experiment might be launched to run for a long time and on more powerful machines, in order to find the optimal set of files to boot Windows. The work of the algorithm could also be distributed among several machines to further accelerate this process.
In our case, apart from Windows, the disk only contained Python and our service. It took us three days to reduce the number of files from 70,000 to 50,000. The file list shrank by only 28%, but it became clear that our approach works and allows determining the minimal set of files necessary to boot the OS.
The Service Structure
Let us have a look at the service structure. The main module of the service is the sequence manager. Since we receive the file list from the driver, we need to recover files following this list. Therefore, we created our prioritized sequence.
We have a list of files to recover one after another. In case of new access requests, urgently needed files will be prioritized for recovery. Therefore, the files that the user actually needs right now are placed in the head of the sequence, while those that will probably be needed in the future, are put in its end. However, if the user works intensively, it may lead to a «sequence of out-of-sequence objects», and a list of files being recovered right now. In addition, the search operation was to be applied to all those sequences at once. Unfortunately, we were unable to implement a sequence, which would set several priorities for the files, and at the same time support the search option and change priorities «on the go». We did not want to fit into the existing data frameworks; therefore, we had to create our own one, and set it up for working.
Our service will first communicate with the driver elaborated by Daulet, and after that, with the components responsible for restoring the files. Therefore, we started with creating a small emulator of the recovery system, which would be able to retrieve files from a removable disk, in order to restore them and test the service.
Two working modes were envisaged: the normal mode and the recovery mode. In the normal mode, the driver sends us a list of files affected at the OS launch. Then, as the system functions, the driver monitors all operations and files and sends notifications to our service. The service then makes changes to the list of files. In the recovery mode, the driver notifies the service of the necessity to restore the system. The service makes a sequence of files, launches software agents that request backup files, and starts the recovery process.
Final Thesis, Job Offer and New Projects
Once the service was ready and tested, we were left with one last project-related activity. We needed to update and streamline all artefacts that we had accumulated, and to present our results to the customer and to the University. For the company, it was another step towards the implementation of the project, while for the University, it was our final thesis.
Based on the presentation results, the students received job offers. In a few weeks, I will start my career with Acronis. The project results brought the idea that the service performance could be enhanced by lowering it to the Native Windows Application level. That will be discussed in our next article.
