
Entity Framework (EF) — это удобный фреймворк для работы .NET-приложения с базой данных. По сути, это такая удобная абстракция над БД, которая сама пишет за разработчика оптимальные (ну, почти) SQL-запросы прямо из высокоуровневых LINQ-конструкций. Одной из киллер-фич фреймворка является возможность относительно легко сменить СУБД приложения на какую-нибудь другую. Предположим, разочаровались вы в MySQL или, наоборот, хотите сменить MSSQL на что-то менее дорогое — пожалуйста, EF как абстракция над СУБД в теории может это предоставить, так сказать, by design.
Проблема в том, что в мире бизнес-разработки СУБД меняют лишь по очень большой нужде, а потому редко кто уже сталкивался с данной фичей EF на практике, но вот мне такая возможность выпала. Поэтому я решил написать небольшой гайд, как это выглядит в реальности, чтобы у вас была возможность оценить применимость данной фичи, если вдруг это понадобится.
В этой статье я описываю достаточно быстрый способ перейти на другую базу данных, если вы используете EF, но есть ряд оговорок.
Я пишу про «небесшовный» переход. Бесшовный переход предполагает, что приложение умеет ходить одновременно в две БД, а плюс EF как раз в том, чтобы одну реализацию абстракции подменить на другую. То есть придётся или писать много кода для поддержки двух реализаций одновременно, или пересаживаться на новую БД «быстро, решительно». Рассказываю, как это быстро и решительно сделать наименее болезненно и с возможностью отката в моменте.
Приложение должно использовать «чистый» EF, то есть никаких низкоуровневых заигрываний с SQL, только LINQ-конструкции. Если вы используете какие-то внешние отчёты, например, через Redash, то это придётся переписывать руками, и статья этот вопрос не освещает.
Я описываю именно переезд с базы Microsoft SQL на MySQL и именно в таком направлении. Предположу, что с другими СУБД эта статья тоже будет более-менее применима, но индивидуальные нюансы каждой БД и другой тулинг могут серьёзно поменять детали процесса.
Общий план действий
План перехода состоит из следующих этапов:
Учим приложение работать с новой базой, подключаем новый коннектор и разбираемся с тонкостями настройки.
Переводим какой-нибудь самый простой домен приложения на рельсы новой базы данных, проверяем, что данные правильно записываются, а затем правильно читаются.
Готовим скрипты переноса данных из одной БД в другую.
Релизим, получаем фидбэк, фиксим проблемы.
Пункты 2, 3 и 4 повторяем для всех частей приложения.
Учим приложение работать с новой базой
Тут всё очень просто. Я подключил NuGet-пакет с MySQL-коннектором, поменял инициализацию DbContext'а в Startup.cs, чтобы он использовал новый коннектор.
Было
services.AddDbContextPool<TDbContext>(
options => options.UseSqlServer(dbConnection));Стало
services.AddDbContextPool<TDbContext>(
options => options.UseMySql(mysqlConnection));Ещё немного поменял настройки маппинга сущности на таблицу в БД, убрав из маппинга schema, т.к. В MySQL должна быть одна база (schema) на всё.
Всё чуть сложнее, если вы храните в базе GUID. У MySQL нет специального типа данных под GUID, но она может хранить его как binary(16), или вообще строкой. Управляется это настройкой подключения, а конкретно опцией GUID Format. У меня после перехода на MySQL изменилась сортировка по GUID, потому что, скорее всего, я не совсем правильно выбрал тип хранения, так что если вам по каким-то причинам важно сохранить сортировку по GUID, то отнеситесь к этой настройке внимательно.
И, внезапно, со стороны кода приложения больше ничего не нужно.
Миграция данных
Очень вероятно, работа с данными займёт у вас больше всего времени в рамках перехода на другую СУБД. Из-за разного тулинга некоторые вещи придётся соединять достаточно нетривиально.
Так как сразу предполагается, что данные придётся «хачить», то лучше полагайтесь на консольные утилиты — с ними гораздо проще влиять на ввод-вывод и делать на основе этого скрипты. Если таблиц в базе много, то написать скрипты просто критически важно. Для работы с Microsoft SQL я использовал утилиту bcp из стандартной обвязки сервера, но также её можно поставить и отдельно. А для MySQL я нашёл также официальную утилиту mysqlsh.
Пайплайн переливки данных выглядит следующим образом: данные дампятся на рабочую машину через bcp в некий csv-like формат, а затем этот файл заливается через mysqlsh на целевую базу MySQL. Для mysqlsh при этом пишется довольно объёмная команда для импорта, по сути являющаяся скриптом, потому что может содержать различные условия и даже некоторую логику.
Скриптинг для mysqlsh
Я решил посвятить этому аспекту отдельный абзац, потому что именно благодаря широким возможностям по скриптингу в mysqlsh данные удалось перенести достаточно быстро и без особых проблем.
Итак, mysqlsh имеет внутри себя целых три оболочки: для классического SQL, а также JS и Python. SQL нам трогать не надо, я через него разве что таблички чистил после неудачной переливки, а вот JS-интерпретатор в вопросах импорта данных оказался очень полезным инструментом. В нём содержится несколько встроенных специальных команд, конкретно под наши нужды применяется utils.importTable, синтаксис которого вот такой:
util.importTable('path/to/file', {
schema: 'schemaname',
table: 'tablename',
fieldsTerminatedBy: '|-|',
linesTerminatedBy: '\n-/-\n',
columns: [1,2,3],
decodeColumns: {
"Id": "UUID_TO_BIN(@1)",
"ColumnName": "@2",
"AnotherColumnName": "@3",
}
});С названием схемы и таблицы всё должно быть очевидно: fieldsTerminatedBy — это делимитер между столбцами, linesTerminatedBy — соответственно, делимитер между строками. Каждое значение в columns — это название колонки в целевой таблице, в которую будет импортирован столбец из файла согласно порядку, указанному в columns.
Но почему там цифры? А цифра — это что-то типа названия переменной, чтобы можно было уже в секции decodeColumns как-то переопределить значение. В приведённом примере первая колонка заменяется на переменную 1 (число может быть произвольным, но это обязательно должно быть число), а в секции decodeColumns уже указывается, что к значению из первой колонки применяется функция UUID_TO_BIN, и полученный результат вставляется в колонку Id.
Делимитеры
Итак, bcp дампит данные во что-то типа csv. Но csv-формат предполагает, что значения разделены запятой, а каждое значение обрамлено в кавычки. То есть кавычки в рамках чистого csv — это небезопасный символ, который надо экранировать, если он встретится в данных. Но bcp экранировать не умеет (или я не нашёл как), поэтому от кавычек следует отказаться, а значения разделять некой последовательностью символов, которая в ваших данных встретиться не может.
У меня данные в базе частично представляли из себя текст статей прямо вместе с HTML-разметкой, потому специальных символов в данных, прямо скажем, хватало. В итоге я остановился на разделителе |-| — выглядит понятно и нигде в моих данных не встречается. Для разделения строк использовал конструкцию \n-/-\n, где \n — это перевод каретки. Скрипт для дампа выглядит как-то так:
bcp schemaname.tablename out /path/to/file -S server -U user -P password -d dbname -c -t '|-|' -r '\n-/-\n'NULL
Bcp работает с NULL немного не так, как это делает SQL. NULL в файле выгрузки превращается в пустое значение, а пустая строка превращается в специальный символ Nul (он же 0x0). А вот mysqlsh работает как SQL, то есть пустое значение интерпретирует как пустую строку, а символ Nul — в общем-то, как символ Nul. Потому для правильной заливки дампа пришлось написать оверрайд для каждой колонки со строковым типом данных:
decodeColumns: {
"ColumnName": "IF(@1='@','',IF(@1='',NULL,@1))"
}К сожалению, mysqlsh никак не хотел принимать конструкцию вида IF(@1=0x0,'',...), поэтому пришлось воспользоваться старым добрым sed и заменить в дампе символ 0x0 на нормально воспринимаемую mysqlsh собачку (@).
sed -i 's/\x0/@/g' /path/to/fileПотом оказалось, что похожая проблема есть у всех nullable типов данных, потому что вместо ожидаемого базой NULL приходит пустая строка и ломает импорт. Для этого пришлось написать ещё пару оверрайдов, но с ними код скрипта стал совершенно нечитаемым:
decodeColumns: {
"StringColumn": "IF(@1='@','',IF(@1='',NULL,@1))",
"NullableUUID": "UUID_TO_BIN(IF(@2 = '',NULL,@2))",
"AnotherNullable": "IF(@3='',NULL,@3)",
}Тут я решил, что не зря же эта оболочка, по сути, интерпретатор JS, а значит, можно всё красиво обернуть в функции:
function string(param){return `IF(${param}='@','',IF(${param}='',NULL,${param}))`}
function uuid_nullable(param){return `UUID_TO_BIN(IF(${param} = '',NULL,${param}))`}
function nullable(param){return `IF(${param}='',NULL,${param})`}
...
decodeColumns: {
"StringColumn": string("@1"),
"NullableUUID": uuid_nullable("@2"),
"AnotherNullable": nullable("@3"),
}Так ошибиться при составлении скрипта стало намного сложнее.
Тип rowversion
Кроме GUID мне попался ещё один тип данных, которого нет в MySQL — это rowversion. EF при составлении миграции для создания таблицы в MySQL предложил использовать для этого тип timestamp. Вот только проблема в том, что rowversion со временем никак не связан, а потому напрямую в timestamp никак не транслируется.
К счастью, особой функциональной нагрузки этот тип не несёт, он просто не позволяет перезаписать данные, если за время твоих изменений они были модифицированы. Так что rowversion можно сконвертировать в произвольный timestamp, не переживая, что он может быть сильно в прошлом или сильно в будущем, потому что коду не важно, «когда» этот timestamp, главное, чтобы он оставался тем же самым во время чтения и во время обновления. Потому я сделал ещё одну функцию для оверрайда:
function row_version(param){return `FROM_UNIXTIME(IF(${param} = '',NULL,${param}))`}Итого
Чтобы перелить данные для одной таблицы, нужно:
Сделать скрипт для создания дампа конкретной таблицы через bcp.
Прогнать дамп через sed, чтобы заменить символ 0x0.
Сделать скрипт импорта для mysqlsh:
взять шаблон, вставить в него имя базы, таблицы и файла дампа, а также проставить делимитеры;
вставить в массив columns значения по количеству столбцов в таблице;
для каждой колонки сделать оверрайд, выбрав нужную функцию. Если оверрайд не нужен, то написать
"Column": "@{номер столбца}";не перепутать нумерацию колонок и оверрайдов.
Протестировать.
Самое неудобное — это, конечно, назначение циферок колонкам. Но переменные для оверрайда не могут содержать буквы, а так их можно было бы назвать как-то более соответствующе их назначению. Поэтому нужно стараться сделать весь остальной скрипт хорошо читаемым, ну и тщательно проверять результат.
Релиз
Теперь, когда код написан, а скрипты переливки проверены, нужно выкатить изменения на прод. Вот так выглядит алгоритм упомянутого выше «небесшовного» релиза:
Тёмной ночью выкладывается новая версия приложения, которая работает с MySQL. Таблицы создаются мигратором прямо в рамках этого деплоя и на момент выкладки абсолютно пусты. С момента окончания деплоя можно считать, что данные находятся в некотором зафиксированном состоянии, потому что доступа к старой базе у приложения больше нет, а в новой пока нет данных.
Данные из старой БД сливаются в некоторое промежуточное хранилище, где подготавливаются для заливки. Тут я просто использовал свою рабочую машину — для баз размером в несколько гигабайт это более чем достаточно..
Данные заливаются в новую базу. Они уже подготовлены и заливка протестирована — всё должно пройти без ошибок.
Если всё же возникает ошибка, которую не удаётся починить на ходу, то система просто откатывается на предыдущее состояние, где она работала со старой базой. Можно спокойно провести работу над ошибками и попробовать снова следующей ночью.
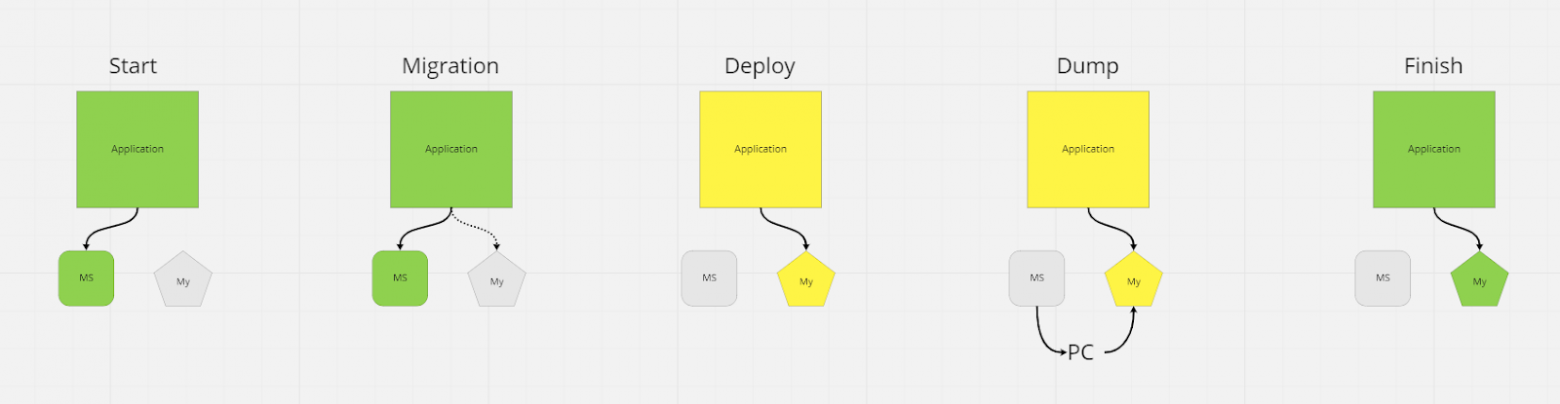
Обновлять приложение, особенно если оно большое, лучше небольшими частями. Я выкатывал за раз по одному DbContext'у, причём начинал с тех, где меньше всего цена ошибки. О некоторых ошибках может стать известно через несколько дней, потому лучше не спешить.
Выводы
Как я уже говорил в начале статьи, не ко всем приложениям, использующим EF, применим такой алгоритм перехода на другую БД. База должна быть небольшой, нагрузка — такой, чтобы можно было позволить себе 10-15 минутный даунтайм, причём несколько раз в рамках всего перехода. Но зато при соблюдении этих условий переезд на другую БД становится вполне тривиальной задачей.
Самое сложное в переходе на другую БД — это перенос данных, а самое сложное в переносе данных — проверка скриптов. Была даже идея сделать скрипт, генерирующий скрипты импорта, но отлаживал бы я его явно дольше, чем потратил времени на весь переезд. Потому выбрал путь хорошо читаемых скриптов и их внимательной проверки.
Удалось ли подтвердить наличие у EF киллер-фичи по смене БД? Я считаю, что удалось. Переезд выполнялся ровно одним разработчиком, и за две недели было перенесено 90% приложения (потом внезапно наступил отпуск и итоговый результат по времени уже не выглядит так красиво). При этом в приложении изменилось какое-то смехотворное число строк кода, и ни строки не изменилось в бизнес-логике. Думаю, что разработчики EF могут по праву гордиться своим продуктом. А если бы существовал cross-DB тулинг для переливки данных, можно было бы менять БД как перчатки. :)
